









我们在之前数据库的基础篇大致谈过一些事务的隔离级别的内容具体见添加链接描述
为什么事务要隔离
ACID四大特性分别是,atomicity原子性.consistency一致性,isolation隔离性以及durability持久性。
这里为什么需要隔离性,因为在实际工程当中,经常会出现一些问题,这些问题大致是:
脏读
不可重复读
幻读
为了解决上述问题,因此强调隔离性。
事务的四种隔离级别
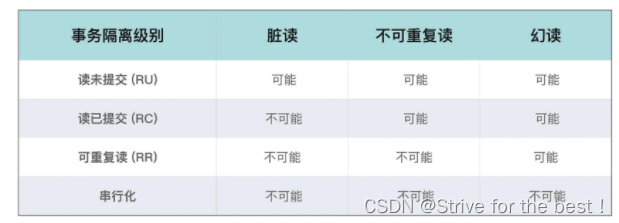
- 读未提交:某事务还未commit,他的改变就能被别的事务看到。这种情况会出现上述三种问题。对锁的要求很低,即读不需要锁,写需要x锁。
- 读已提交:与上述相反,即只有提交了事务之后,其改变才能被别的事务看到。会导致不可重复读&幻读.读需要s锁,写需要x锁。
- 可重复读:指事务执行过程中读到的数据和在启动该事务前看到的总是一致的。需要满足严格的2pl(两阶段提交)
- 可串行化:不仅需要2pl,还需要在事务结束之前EOT,一直保持索引上的s锁

拿上述两个事务来举例,头两种相信大家都清楚v值应该是多少。我们来解释一下:
- 可重复读:如果在这种隔离级别下,我们要保证A事务执行期间和执行前看到的数值保持一致。即V1 V2都得是1,V3在结束事务A了之后,是2.
- 可串行化:当B事务想更改值,此时B会被锁住,因为该值被A读走了,一直到事务A提交之后,B才能更改。 所以V1 V2肯定都是1.但是当A再次查询该值时,又会被锁住,直到B提交。此时V3已经是2了。
隔离在数据库中的实现——视图
实现方面,数据库会创建一个视图,访问数值以视图逻辑为准。
即
读未提交级别,直接返回最新值,没有视图概念。
读已提交级别,视图在SQL语句开始执行时创建
可重复度级别,视图在事务启动之前创建,整个事务运行期间都保持这个视图。
可串行化级别,直接用加锁方式避免并行访问。
展开说明一下可重复读是如何实现的。
MySQL实际上在每条记录被更新的同时都会记录一条回滚操作 ,通过回滚操作,可以得到任意状态的值。回滚日志一直被保留,直到没有事务需要这些回滚事务为止。
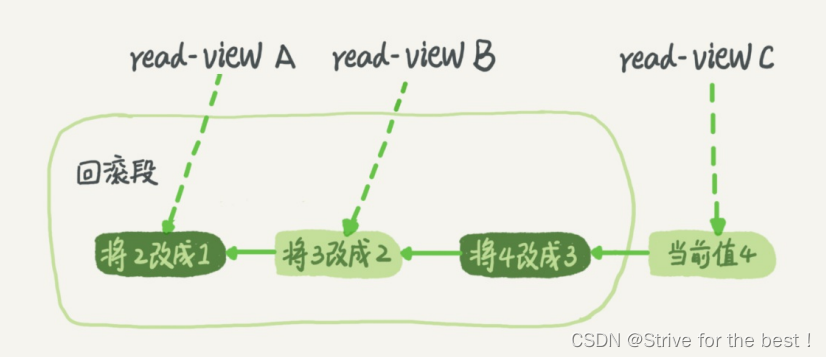
我们看到一个值从1被改到4.但是不同时刻启动事务会得到不同视图,不同值
视图A,只看到了值变成了1。后面以此类推B看见了是2,C看见了现在的值是4.
所以要尽可能避免使用长事务
长事务意味着数据库中,此时会有很老的视图,即牵扯到很大量的回滚日志保留下来,大量空间被占用。除此之外,长事务还占用锁资源。
MySQL的选择——读已提交
这主要是受到Oracle数据库设定的影响。
MVCC实现可重复读
什么场景需要可重复读呢?即希望在事务进行中,即使数据发生变化,也不影响我的结果。
比如你有上个月的账本和这个月的,你在做校对的时候不会关心现在银行有没有人存取钱,因为需要校对的内容已经记在这个月的账本上了,此时此刻银行事务的变化,不会影响你校对。
MVCC,全称 Multi-Version Concurrency Control,多版本并发控制。
最大的作用是帮助我们实现可重复读的同时,避免了读的时候加锁,只有在写的时候才进行加锁,从而提高了系统的性能。核心是通过引入版本或者视图来实现的。
几个前提概念:
- 事务ID:这个好理解,在InnoDB 中是trix_id.
- 隐藏列: 每一行至少包括trix_id列以及roll_pointer列,这就是隐藏列。每一行数据中的 trx_id,代表该行数据是在哪个 trx_id 中被修改的,这样在每个事务中看访问到表中的数据时,我们就可以对比是在当前事务之前的事务里被修改的,还是在之后的事务里被修改的。但只有这个信息是没有用的,毕竟如果我们想要让并发时,一些尚未结束的事务的修改,对当前事务不可见,还得知道在此之前这个数据是什么样的吧?这就是 roll_pointer 的作用了,它指向的更早之前的数据记录,也就是一个指针,指向更早的记录值。
- redo log:用来预写,在宕机未持久化的时候恢复数据
- undo log:记录事务开始的状态,用以事务失败后回滚,除此之外,undo log 的另一大作用就是用于实现 MVCC,我们的 roll_pointer 指向的其实就是 undo log 的记录。通过 roll_pointer 形成了一个类似于单向链表的数据结构,我们称为版本链。所以每次新插入一条数据,除了插入数据本身和申请事务 ID,我们也要记得把 pointer 指向此前数据的 undo_log。MVCC 就是在这样的版本链上,通过事务 ID 和链上不同版本的对比,找到一个合适的可见版本的。快照读就是 MVCC 发挥作用的方式。
- 快照读:在 select 数据的时候,我们会按照一定的规则,而不一定会读出表中最新的数据,有可能从版本链中选择一个合适的版本读出来,就像一个快照一样,我们称为快照读。在 InnoDB 中,默认的、可重复读的事务隔离等级下,使用的 select 都是快照读
- 当前读:读最新值,语句加for update 可能产生幻读。
读视图
在可重复读的隔离性下,MVCC 是如何工作的呢?
核心的可见性保证来自于读视图的建立,本质就是每个事务开始前,会记录下当前仍在活跃也就是开始但未提交的所有事务,保存在一个数组中,我们称为视图数组,然后会根据这个数组,基于一定的规则判断应该读取每个数据的哪个快照。
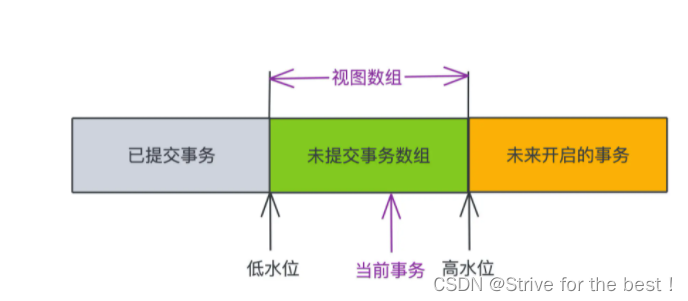
记录视图数组中最小的事务ID——称为低水位。最大的事务ID+1——称为高水位。
规则:
这两个 ID 其实就可以从当前执行的事务的视角,将所有的事务分为三个部分,
- 小于低水位的部分一定是当前事务开始前就已经提交了的部分,是可见的。
- 大于等于高水位的则一定是还未提交的事务,我们一定不可见。
- 中间部分:
- 如果在视图数组中,说明当前事务开始时,这些事务已经开始并活跃(活跃指的是启动了但没有提交),则应该不可见
- 如果不在视图数组中,说明其已经不活跃,这个版本是已提交的事务生成的,可见
记低水位为low_id,高水位为high_id,活跃事务数组为trx_list。
可见的事务IDtrix_id应该满足:trix_id<low_id ||(trix_id<high_id && !trx_list.contains(trix_id))
即,可见事务要么比低水位更低,要么不在活跃事务却比高水位低。
有了这个视图的声明,系统后续发生的更新一定属于不可见的状态,所以是可重复读的。
读视图的规则其实就是根据可见性的约束,在查询数据的时候从版本链从最新往前遍历,直至找到第一个可见的版本返回。
例子:

在事务A之前,id=1的隐藏列事务trix_id是1.
那么事务A启动,由于B最先,A次之,然后是C。所以A申请到trix_id=3.在A的视图数组里,他启动的时候,只有B是活跃的,所以trix_list=[trix_id=2]。
在T4时间
- 事务C的tirx_id是4,大于等于高水位,对于事务A不可见,避免了脏读。
- 事务B在T4还未提交,在T6提交,其属于事务A开始之前就在活跃事务数组中的,所以其对A是不可见的。
因此,事务A在T4 T6读的值是一致的,保证了可重复读。
MVCC总结
MVCC 基于 undo_log 和版本链的乐观控制并发的方式,本质上就是要通过多版本的快照读,在实现隔离性的同时,帮助我们避免读的时候加锁的操作。
当前读
对于更新数据的操作,都是先读后写,读只能读当前值。
更新完了看自己的trix_id是不是最新的,如果是就可以直接用。
事务的可重复读如何实现
核心是一致性读,事务更新数据只能用当前读,如果当前记录被别的行锁占用,就要等待。
读已提交和可重复度的主要区别:
- 可重复读:事务开始时就创建一致性视图,之后事务其他查询都用这一个视图。
- 读已提交:每个语句都要创建新的视图。















 862
862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









