







文章目录
1.LIMIT - 分页
基本用法
# 第一种:LIMIT offset, rows
SELECT name
FROM product
LIMIT 0, 10;
# 第二种:LIMIT rows
SELECT name
FROM product
LIMIT 10;
可以省略offset,表示从0开始查询(不过这样子就不是用来实现分页了)
上述两条语句均表示:在查询出的结果当中,从偏移量为0的数据开始,往下截取10条数据。
SQL优化
首先需要说明:使用LIMIT关键字的时候,offset越大,查询效率越低。
以下方的SQL为例(offset为9999)
# 从偏移量为9999的数据开始,往下获取10条数据
SELECT *
FROM product
LIMIT 9999, 10;
实际上该语句查询出了(10000 + 10 = 10010)条数据,根据offset,舍弃了前面的1W条数据
这样的做法效率是非常低的。优化有如下思路:
思路一:通过索引覆盖,第一步先查出10010条数据的id,第二步根据id回表进一步查询。
这样前面的1W条数据就只需要查询出id即可,不再需要回表,大大提升查询效率。
# 通过索引覆盖 + 子查询提升分页查询效率 SELECT name FROM product WHERE id <= ( SELECT id FROM product LIMIT 9999, 1 ) LIMIT 10;
- 子查询表示查询第10000条数据的id(从偏移量为9999的数据开始,往下截取1条数据)
- 由于id通常是自增的,WHERE子句则表示获取id >= 第10000条数据id的10条数据
2.BETWEEN … AND … - 范围查找
# 查询id∈[20,30]的数据
SELECT name
FROM product
WHERE id BETWEEN 20 AND 30;
注意:是闭区间。
3.IN - 在确定的集合内查找
# 在确定的集合内查找
SELECT *
FROM product
WHERE name IN ('奥利奥', '薯片', '泡面');
通常搭配子查询一起使用,如:
# 查询大一所有学生的名字:
# 子查询中根据 grade = '大一' 查出班级id,
# 外查询使用IN,根据子查询的id查出学生名字。
SELECT name
FROM student
WHERE student_class_id IN (
SELECT id
FROM student_class
WHERE grade = '大一';
);
需要注意的是,IN与BETWEEN…AND有所不同:
- IN:其后是一个具象的集合,而不是一个抽象的范围,如:IN (20, 30)表示必须是20或30;
- BETWEEN…AND:对数字字段限定抽象范围,如:**BETWEEN **20 AND 30表示[20, 30]。
在MyBatis中,可以用<foreach>标签来设置IN后面的集合:
假设传入DAO层的列表 idList=[1, 2, 3, 4, 5],那么在mapper.xml中可以这么写:
<select id="listNameById" resultType="Product"> SELECT name FROM product WHERE id IN <foreach collection="idList" item="id" open="(" close=")" separator=","> #{id} </foreach> </select>
- collection:传入列表的形参名;
- item:遍历列表时,取出的元素的引用;
- open:SQL的首部,无脑写 “(” 即可;
- close:SQL的尾部,无脑写 “)” 即可;
- separator:分隔字符串
IN 在MySQL5.5之前,不走索引;MySQL5.5后会根据字段唯一性来决定:
SELECT * FROM user WHERE name IN ("zhangSan", "liSi");走不走索引,需要先判断表中名为"zhangSan"或"liSi"的数据多不多:
- 不多:走索引;
- 多(经测试有可能为30%):全表扫描。
4.AND和OR - AND的优先级高于OR
AND的优先级高于OR,但更加推荐的用法是添加括号。
5.模糊查询 - 通配符与LIKE
通配符规则
注意:通配符如果在开头(‘_bc’、‘%bc’),查询时就不会走索引
通配符主要有两种:
- %:匹配任意(包括0)个字符(说白了,可有可无)
- _:匹配一个字符
举个栗子:
- ‘%bcd’:匹配以bcd结尾的;
- ‘abc%’:匹配以abc开头的;
- ‘%bc%’:匹配包括bc的;
- ‘_bcd’:匹配以bcd结尾,且前面有且只有一个字符的;
- ‘abc_’:匹配以abc开头,且后面有且只有一个字符的;
- ‘_bc_’:匹配包含bc,且前后都仅有一个字符的;
- ‘_bc%’:匹配包含bc,且之前仅有一个字符的(之后可以有任意个,包括0个)。
LIKE关键字 - 开启通配符匹配
# 情况1:LIKE后面拼接通配符 - 依照通配符规则开启模糊查询
# 查询所有name以"油炸"开头的商品
SELECT *
FROM product
WHERE name LIKE '油炸%';
# 情况2:LIKE后面没有拼接通配符 - 等价于"="
# 查询name为"薯片"的商品
SELECT *
FROM product
WHERE name LIKE '薯片';
在MyBatis中,若以某关键字进行模糊查询,可以使用CONCAT( )进行拼接:
<select id="listByKey" resultType="Product"> SELECT * FROM product WHERE name LIKE CONCAT(#{key}, '%') </select>这里是将传入的key与’%'拼接,作为新的通配符字符串使用。
6.AS - 起别名
# 为name起别名为product_name
SELECT name AS product_name
FROM product
WHERE id = 1;
若在SELECT中起别名,不可在WHERE中使用别名
以下是错误的SQL语句
SELECT name AS student_name
FROM student
WHERE student_name = ‘张三’;
- SQL的执行顺序:FROM -> WHERE -> SELECT
- 因此在执行WHERE的时候,SELECT还未执行,即别名还不存在,因此不可调用。
注意:联表查询时,应对同名字段起别名
如果某个查询使用了联表查询,而连接的表中有字段名相同的字段,
且恰好使用的是resultMap,则必须要对其中的某一字段名起别名。
<!-- 根据班级id查询学生列表 --> <select id="listByStudentClassId" resultMap="studentMap"> SELECT stuent.id, student.name, studentClass.name AS studentClassName FROM student LEFT JOIN studentClass ON student.studentClassId = studentClass.id </select><!-- 可以看到:学生姓名与班级名称的字段名都是name,此时需要对其中一个字段起别名,封装时使用别名 --> <resultMap id="studentMap" type="student"> <id property="id" column="id"/> <result property="name" column="name"/> <result property="studentClassName" column="studentClassName"/> </resultMap>不可以在resultMap中用"表名.字段名"作为column

7.计算字段函数
7.1.CONCAT( ) - 拼接
可以用在SELECT后,也可以用在WHERE后,用法如下:
# 情况1:用在SELECT后,通常搭配别名使用:
# 查出id为1的数据的name(薯片),
# 将name与"新品 - "进行拼接(新品 - 薯片),
# 最后为新的数据起别名为"new_product_name"并返回。
SELECT CONCAT('新品 - ', name) AS new_product_name
FROM product
WHERE id = 1;
# 情况2:用在WHERE后
SELECT id
FROM product
WHERE name LIKE CONCAT('油炸', '%')
7.2.LTrim( )与Rtrim( ) - 删除左边/右边的所有空格
# 删除字段左边所有的空格
SELECT LTrim(name)
FROM student;
# 删除字段右边所有的空格
SELECT RTrim(name)
FROM student;
7.3.UPPER( ) / LOWER( ) - 转换为大写/小写
# 结果转换成大写
SELECT UPPER(name)
FROM student
WHERE id = 1;
# 结果转换成小写
SELECT LOWER(name)
FROM student
WHERE id = 1;
7.4.算数计算:可以直接在SELECT后的内容进行算数计算
# price为单价,quantity为数量
# 将二者相乘后的结果起别名为总价total_price返回
SELECT id,
name,
(price * quantity) AS total_price
FROM product
WHERE id = 1;
8.聚集函数
基本的聚集函数
| 聚集函数 | 功能 |
|---|---|
| AVG( ) | 返回平均值 |
| COUNT( ) | 返回行数 |
| MAX( ) | 返回最大值 |
| MIN( ) | 返回最小值 |
| SUM( ) | 返回结果中某列之和 |
# 获取商品总数
SELECT SUM(quantity)
FROM product;
DISTINCT( ) - 去重
# 去除重名的商品
SELECT DISTINCT(name)
FROM product;
聚集函数搭配使用
聚集函数并不是只能使用一个,一个SQL可以有多个聚集函数一起使用
# 同时使用多个聚集函数
SELECT COUNT(*) AS num,
MIN(price) AS min_price,
MAX(price) AS max_price,
AVG(price) AS avg_price
FROM product;
9.子查询
作为 WHERE 中 IN 的查询条件
# 查询大一所有学生的名字:
# 子查询中根据 grade = '大一' 查出班级id,
# 外查询使用IN,根据子查询的id查出学生名字。
SELECT name
FROM student
WHERE student_class_id IN (
SELECT id
FROM student_class
WHERE grade = '大一'
);
搭配别名,作为查询结果返回
# 查询出两个字段name、student_class_name
SELECT name,
(SELECT name
FROM student_class) AS student_class_name
FROM student
10.UNION - 并
将多组查询结果合并返回:
# UNION - 将两个查询结果合并
# 查询1
SELECT name
FROM product
WHERE price <= 5
# UNION - 默认去重(UNION UNIQUE)
UNION
# 查询2
SELECT name
FROM product
WHERE id IN (1000, 2000);
- UNION UNIQUE:默认,在查询结果相等时去除重复;
- UNION ALL:不去重展示完整数据。
11.JOIN - 联表查询
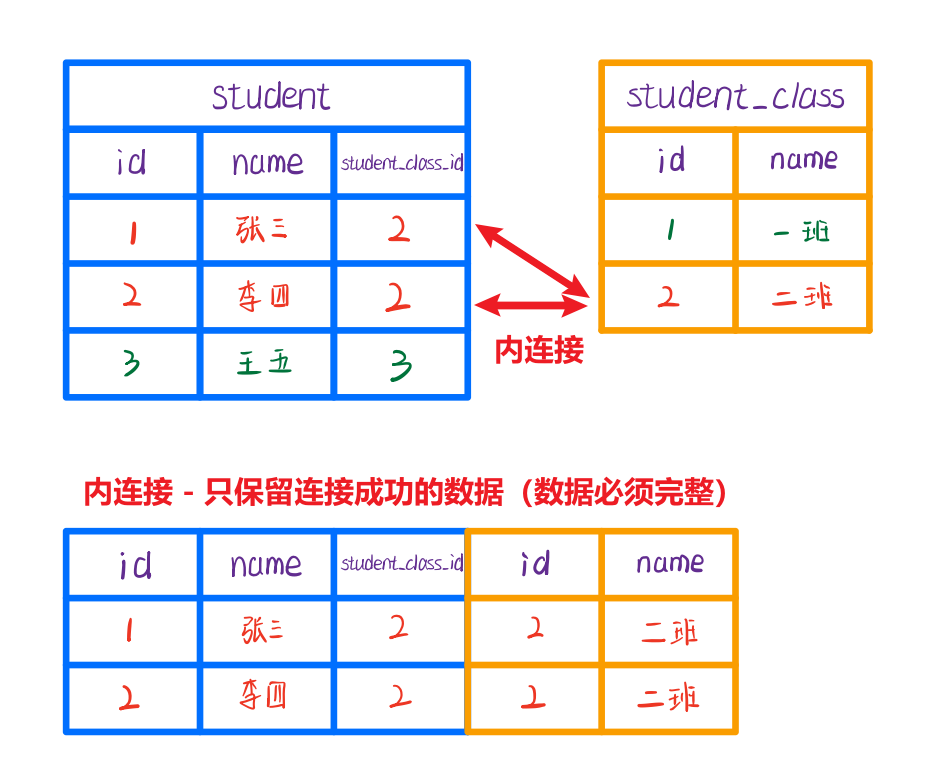
INNER JOIN - 内连接
内连接相当于等值查询。
# 等值查询
SELECT *
FROM student, student_class
WHERE student.student_class_id = student_class.id
# 内连接 - 相当于等值查询
SELECT *
FROM student LEFT JOIN student_class ON student.student_class_id = student_class.id
内连接时,只保留两个表中共有的数据,最终结果必定是完整数据
LEFT JOIN - 左外连接
左外连接的特点是:最终数据量必定与左表一致
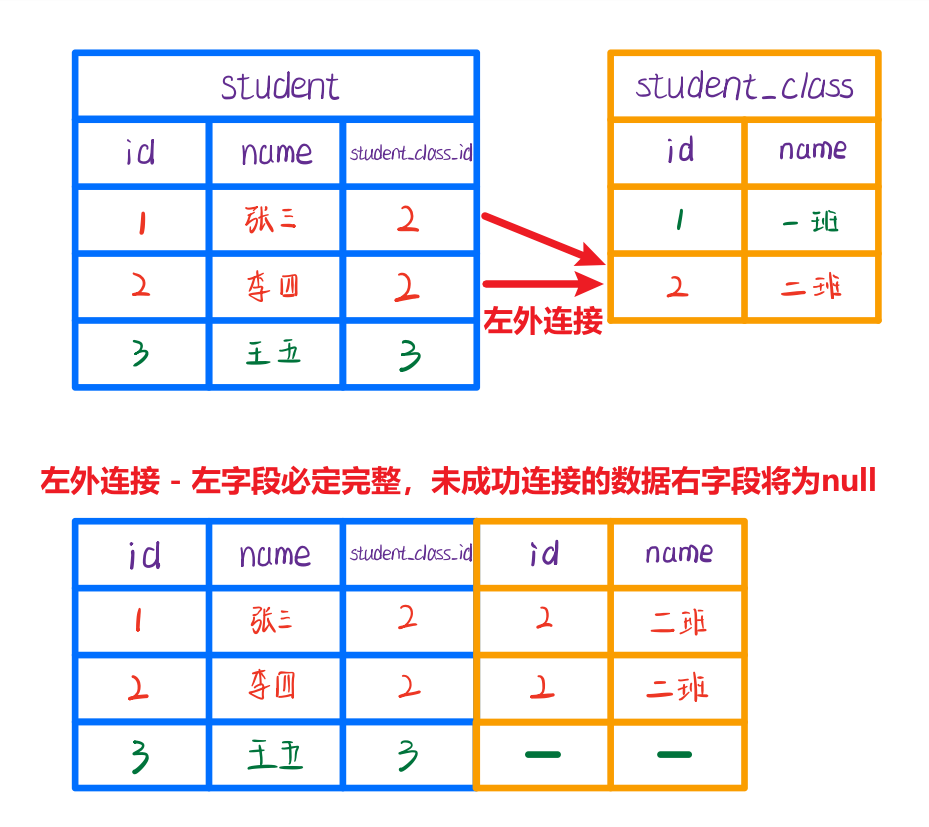
左外连接时,左表中未连接成功的数据也会保留,而右表中未完成连接的字段值为null















 5619
5619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









