






 本文介绍了分类和聚类的基本概念及其区别,重点讲解了聚类的定义、方法和评价标准。聚类是将数据对象按相似性归类,包括基于距离、密度、连通性和概念的相似度度量方法,如K-means和DBSCAN。聚类的好坏可以通过簇内相似度和簇间相似度的比较,以及CH指标等评价准则进行评估。
本文介绍了分类和聚类的基本概念及其区别,重点讲解了聚类的定义、方法和评价标准。聚类是将数据对象按相似性归类,包括基于距离、密度、连通性和概念的相似度度量方法,如K-means和DBSCAN。聚类的好坏可以通过簇内相似度和簇间相似度的比较,以及CH指标等评价准则进行评估。
在初学分类聚类时,对这两个概念不是很了解。随着深入的了解,现有了一些基本的认识。现对聚类进行个人理解上的总结,欢迎大家批评指正。
一、分类和聚类的区别
分类和聚类的概念是比较容易混淆的。
对于分类来说,在对数据集分类时,我们是知道这个数据集是有多少种类的,比如对一个学校的在校大学生进行性别分类,我们会下意识很清楚知道分为“男”,“女”
而对于聚类来说,在对数据集操作时,我们是不知道该数据集包含多少类,我们要做的,是将数据集中相似的数据归纳在一起。比如预测某一学校的在校大学生的好朋友团体,我们不知道大学生和谁玩的好玩的不好,我们通过他们的相似度进行聚类,聚成n个团体,这就是聚类。
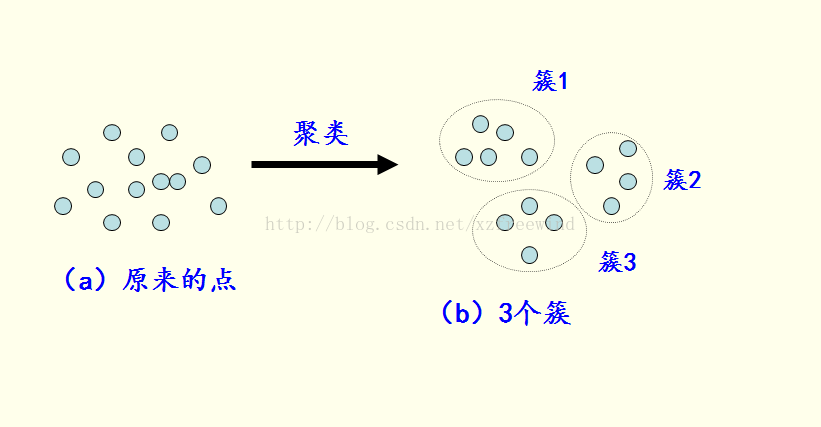
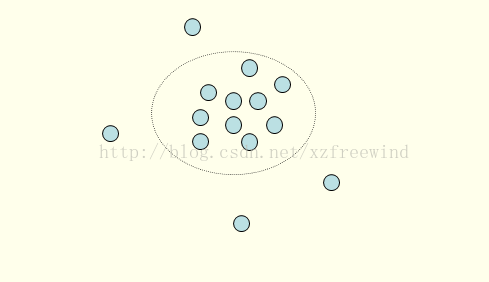
按照李春葆老师的话说,聚类是将数据对象的集合分成相似的对象类的过程。使得同一个簇(或类)中的对象之间具有较高的相似性,而不同簇中的对象具有较高的相异性。如下图所示
二、 聚类的定义
我们这样来对聚类进行定义。聚类可形式描述为:D={o1,o2,…,on}表示n个对象的集合,oi表示第i(i=1,2,…,n)个对象,Cx表示第x(x=1,2,…,k)个簇,CxÍD。用sim(oi,oj)表示对象oi与对象oj之间的相似度。若各簇Cx是刚性聚类结果,则各Cx需满足如下条件:
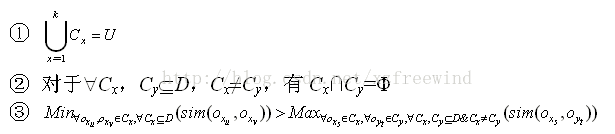
其中,条件①和②表示所有Cx是D的一个划分,条件③表示簇内任何对象的相似度均大于簇间任何对象的相似度。
聚类的整体流程如下:
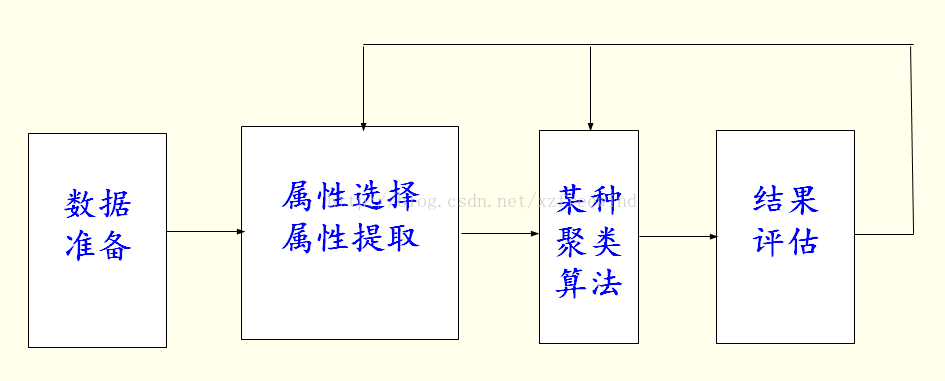
三、聚类的方法
根据定义我们知道,聚类,简单的来说,是通过“臭味相投”的原理来进行选择“战友”的。
那么这个“臭味相投”的原理或准则是什么呢?
前人想出了四种相似度的比对方法,即距离相似度度量、密度相似度度量、连通性相似度度量和概念相似度度量。
3.1距离相似度量
距离相似度度量是指样本间的距离越近,那么这俩样本间的相似度就越高。距离这个词我们可以这么理解,把数据集的每一个特征当做空间上的一个维度,这样就确定了两个点,这两个点间的“连接”直线就可以当做是它们的距离。一般有三种距离度量,曼哈顿距离、欧氏距离、闵可夫斯基距离,这三个距离表示方式都是原始距离的变形,具体形式如下:

因为相似度与距离是反比的关系,因此在确定好距离后可以设计相似函数如下:
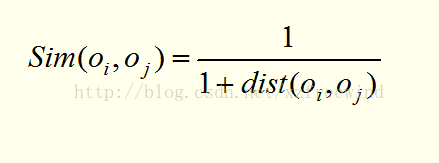
其中,K-means算法就是基于距离的聚类算法
3.2密度相似度度量密度相似度的出发点是 “物以类聚,人以群分”,相同类别的物体往往会“抱团取暖”,也就是说,每个团体都会围在一个圈子里,这个圈子呢,密度会很大,所以就有密度相似度度量这一考察形式。
密度是单位区域内的对象个数。密度相似性度量定义为:
density(Ci,Cj)=|di-dj|
其中di、dj表示簇Ci、Cj的密度。其值越小,表示密度越相近,Ci、Cj相似性越高。这样情况下,簇是对象的稠密区域,被低密度的区域环绕。
其中,DBSCAN就是基于密度的聚类算法
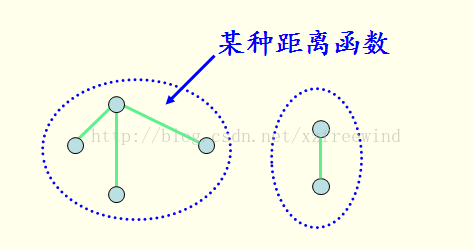
3.3连通性相似度度量
数据集用图表示,图中结点是对象,而边代表对象之间的联系,这种情况下可以使用连通性相似性,将簇定义为图的连通分支,即图中互相连通但不与组外对象连通的对象组。
也就是说,在同一连通分支中的对象之间的相似性度量大于不同连通分支之间对象的相似性度量。
3.4概念相似度度量
若聚类方法是基于对象具有的概念,则需要采用概念相似性度量,共同性质(比如最近邻)越多的对象越相似。簇定义为有某种共同性质的对象的集合。

四、聚类的评定标准
说了这么多聚类算法,我们都知道,聚类算法没有好坏,但聚类之后的结果根据数据集等环境不同有着好坏之分,那么该怎么评价聚类的好坏呢?
一个好的聚类算法产生高质量的簇,即高的簇内相似度和低的簇间相似度。通常估聚类结果质量的准则有内部质量评价准则和外部质量评价准则。比如,我们可以用CH指标来进行评定。CH指标定义如下:
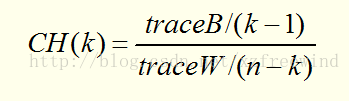
其中:


traceB表示簇间距离,traceW表示簇内距离,CH值越大,则聚类效果越好。















 8356
8356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









