







引言
自 2017 年被提出以来,Transformer 已经成为 AI 大模型的主流架构,但随着模型规模的扩展和需要处理的序列不断变长,Transformer 的局限性也逐渐凸显。一个很明显的缺陷是:Transformer 模型中自注意力机制的计算量会随着上下文长度的增加呈平方级增长,比如上下文增加 32 倍时,计算量可能会增长 1000 倍,计算效率非常低。
为了克服这些缺陷,研究者们开发出了很多注意力机制的高效变体,但这往往以牺牲其有效性特为代价。到目前为止,这些变体都还没有被证明能在不同领域发挥有效作用。
最近,一项名为「Mamba」的研究似乎打破了这一局面。

在这篇论文中,研究者提出了一种新的架构 ——「选择性状态空间模型( selective state space model)」。它在多个方面改进了先前的工作。
作者表示,「Mamba」在语言建模方面可以媲美甚至击败 Transformer。而且,它可以随上下文长度的增加实现线性扩展,其性能在实际数据中可提高到百万 token 长度序列,并实现 5 倍的推理吞吐量提升。消息一出,人们纷纷点赞,有人表示已经迫不及待想要把它用在大模型上了。
本文也就最近小编看到的一些资料整理一下Mamba的相关内容、发展背景以及核心技术的介绍。
Transformer的二次复杂度
简单理解的话,计算复杂度和序列长度的平方成正比,可以看一个小例子,比如两个相乘的矩阵大小分别为(
) 和(
),矩阵乘法的一种计算方式是使用第一个矩阵的每一行与第二个矩阵的每一列做点乘
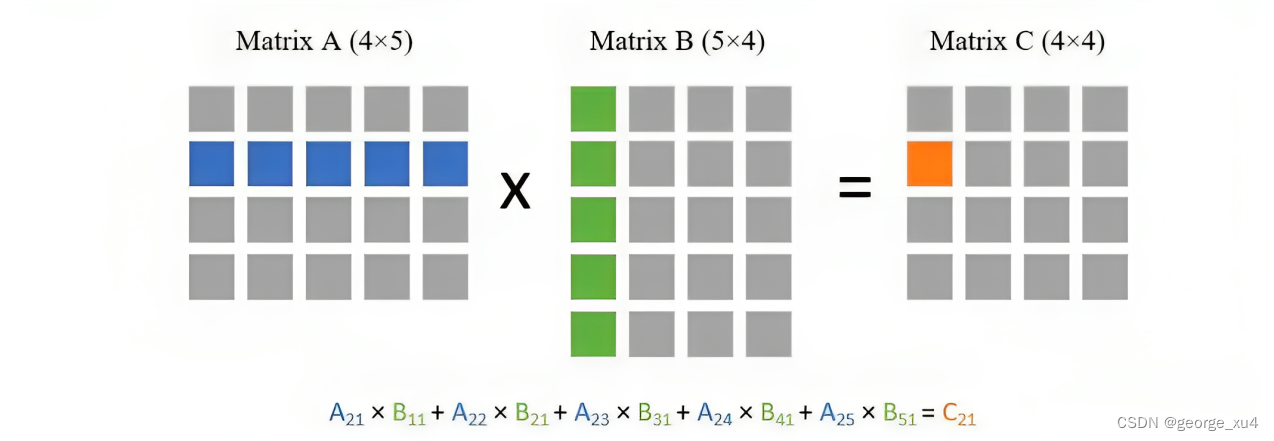
因为我们需要拿第一个矩阵的每一行去与第二个矩阵的每一列做点乘,所以总共就需要次点乘。而每次点乘又需要d次乘法,所以总复杂度就为
精确理解的话,当输入批次大小为b,序列长度为N时, 层transformer模型的计算量为
,d则代表词向量的维度或者隐藏层的维度(隐藏层维度通常等于词向量维度)
正因为现有的ChatGPT等大模型处
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









