







台湾大学李宏毅老师的机器学习课程是一份非常好的ML/DL入门资料,李宏毅老师将课程录像上传到了YouTube,地址:NTUEE ML 2016 。
这篇文章是学习本课程第4-6课所做的笔记和自己的理解。
Lecture 4: Classification: Probabilistic Generative Model
以根据宝可梦各属性值预测其类型为例说明分类问题。
训练数据是若干宝可梦的各属性值及其类型。
1、分类问题不能被视为回归问题
以二类分类为例,离决策边界过远的点“过于正确”造成error很大,从而对决策边界造成影响,导致误分类。
多类分类问题,若把各类的target设成1,2,3……也是有问题的,因为这样做暗含了各类的target是有大小远近关系的。
2、给宝可梦分类的初步想法
假设现在宝可梦只有两类,要预测x属于哪类,若P(C1|x)>0.5则属于第一类,否则属于第二类。
计算P(C1|x)要用到贝叶斯公式,对Generative Model,P(x)=P(x|C1)P(C1)+P(x|C2)P(C2)是可算的,从训练数据中估计P(C1)、P(C2)、P(x|C1)、P(x|C2)这四个值。
P(C1)、P(C2)容易估计,算一下训练数据里两类各占多少就可以了。
要估计P(x|C1)、P(x|C2)就需要做一些假设。
我们假设训练数据中所有的第一类/第二类数据,都是分别从两类对应的高斯分布产生的。
理论上任何参数(
μ,∑
)的高斯分布都可以产生训练数据,只是likelihood不同。
用最大似然的方法可以得出,使得似然函数最大的参数(
μ∗,∑∗
)分别是训练数据中该类数据的平均值和协方差矩阵。
这样就可以求得P(C1|x)了。
在考虑了宝可梦的7种特征的情况下,这样的分类方法在测试集上的正确率只有54%。
3、改进模型
在上面的方法中,
∑
的大小与输入特征的维度的平方成正比。如果两类各自的高斯分布的
∑
不同的话,模型参数太多,容易过拟合。所以让两个
∑
相等,都等于
∑=P(C1)∑1+P(C2)∑2
。
这样做,把准确率从54%提高到了73%。
4、在假设数据分布时,可以用你喜欢的分布。
如,假设特征的各个维度是独立的,得到朴素贝叶斯分类器。或者,对于二值特征,假设其来自于伯努利分布。
5、最后做了一些数学推导:
令
P(C1|x)=σ(z)
(
σ()
表示sigmoid函数),那么在
∑1=∑2=∑
时,
z
可以表示为
所以,在
∑1=∑2=∑
时,分类器有线性边界。
在生成模型中,我们通过估计
N1,N2,μ1,μ2,∑
来得到
w,b
。
Lecture 5: Logistic Regression
比较逻辑回归Logistic Regression与线性回归Linear Regression
上节课说道,
P(C1|x)=σ(z)=σ(w⋅x+b)
。
w,b
取任意值就构成了function set。
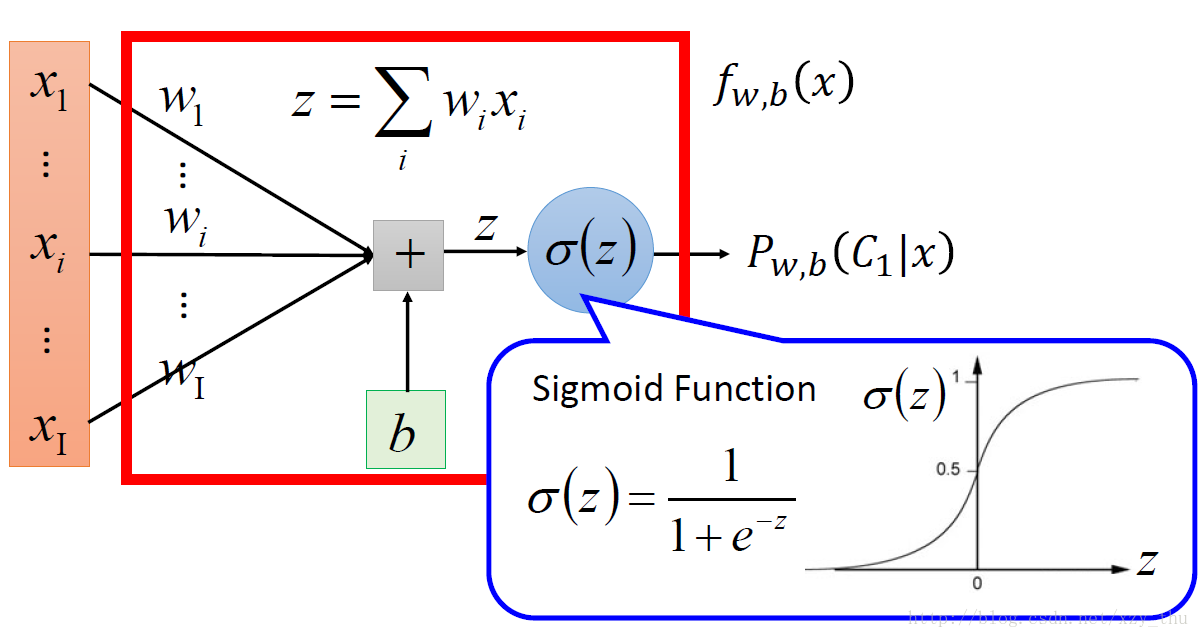
这就得到了逻辑回归Logistic Regression与线性回归Linear Regression在Step 1(选择model)时的区别。

接下来Step 2,评价函数好坏。对训练数据(x1,C1)(x2,C1)(x3,C2)……用
y^=1
表示C1,用
y^=0
表示C2。那么似然函数可以表示为

(第二行等号右侧缺少一个负号)
最大化似然函数即是最小化交叉熵。交叉熵代表两个分布有多接近,若两个分布完全一样则交叉熵等于0。
这样就得到了逻辑回归Logistic Regression与线性回归Linear Regression在Step 2(评价函数好坏)时的区别。

接下来Step 3, find the best function,用梯度下降,得到参数更新公式:
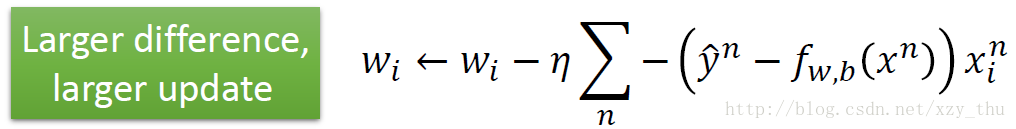
对这一结果的直观理解是:模型结果与目标差距越大,参数更新幅度就越大。
逻辑回归Logistic Regression与线性回归Linear Regression在用梯度下降法更新参数时公式相同。
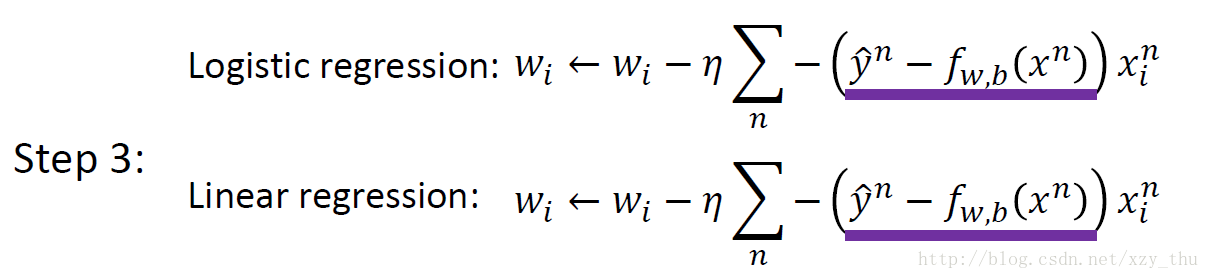
Logistic Regression损失函数的选取
为什么Logistic Regression用交叉熵损失而不用平方误差损失呢?
如果用平方误差损失,在计算损失函数对参数的微分时会出现如下情况:


说明,在结果 far from target 时,微分很小。
为了更形象的说明问题,将交叉熵损失/平方误差损失与参数之间的关系画出来:
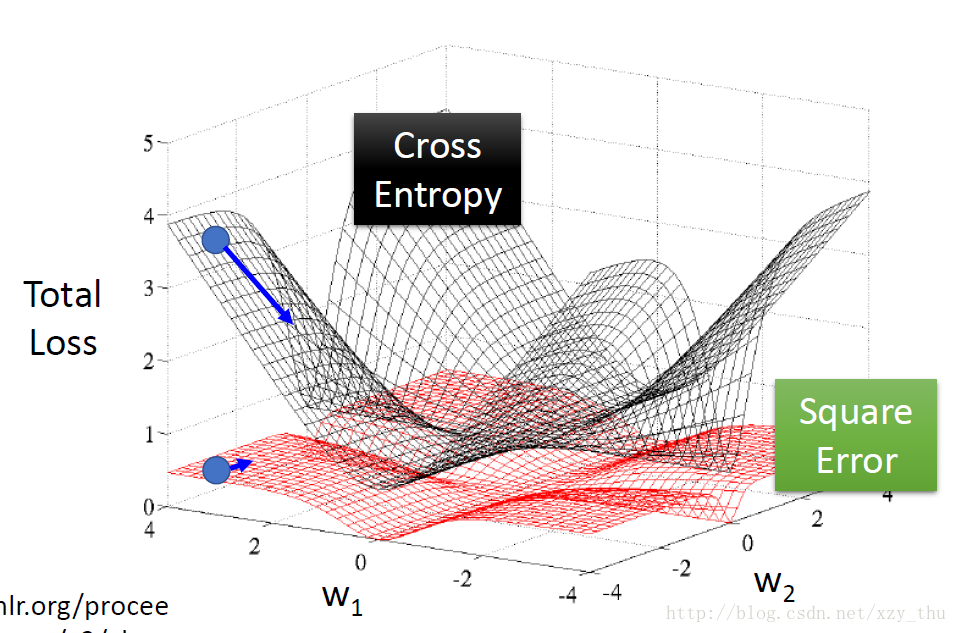
离目标远,cross entropy微分大,square error微分小。
离目标近,cross entropy微分小,square error微分小。
不管离目标远还是近,square error微分都小。所以微分小的时候,不知道离目标远还是近。
用cross entropy可以让training顺利很多。
判别方法 v.s. 生成方法
这节课的判别方法,与上节课的生成方法,模型是一样的,都是
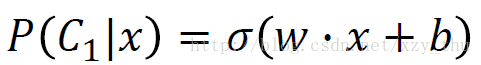
判别方法,通过梯度下降,直接找到
w,b
。
生成方法,通过估计
N1,N2,μ1,μ2,∑
来得到
w,b
。
同样的模型,同样的训练数据,采用两种方法所得结果(
w,b
)不同。因为生成方法对概率分布做了假设。
哪个更好?Discriminative model 常比Generative model表现更好。下面是一个简单例子:

朴素贝叶斯的结果是Class 2。
生成模型在一些情况下相对判别模型是有优势的:
1、训练数据较少时。判别模型的表现受数据量影响较大,而生成模型受数据量影响较小。
2、label有噪声时。生成模型的假设(“脑补”)反而可以把数据中的问题忽视掉。
3、判别模型直接求后验概率,而生成模型将后验概率拆成先验和似然,而先验和似然可能来自不同来源。以语音识别(生成模型)为例,DNN只是其中一部分,还需要从大量文本(不需要语音)中计算一句话说出来的先验概率。
Multi-class Classification
在做Multi-class Classification时,需要softmax。原因可参考Bishop P209-210,或Google “maximum entropy”。
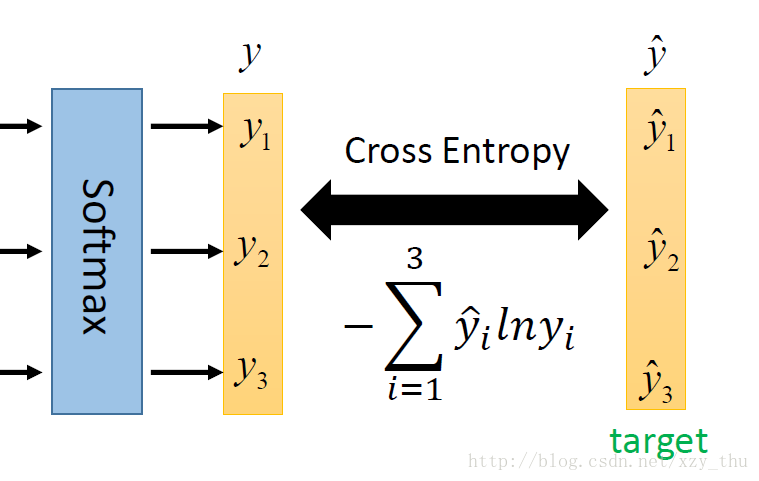
最小化交叉熵,等价于最大化似然函数。
Logistic Regression的局限性
不能表示XOR。(边界是直线。)
解决方法:做feature transformation. (Not always easy to find a good transformation.)
希望机器自己找到 transformation:把多个Logistic Regression接起来。
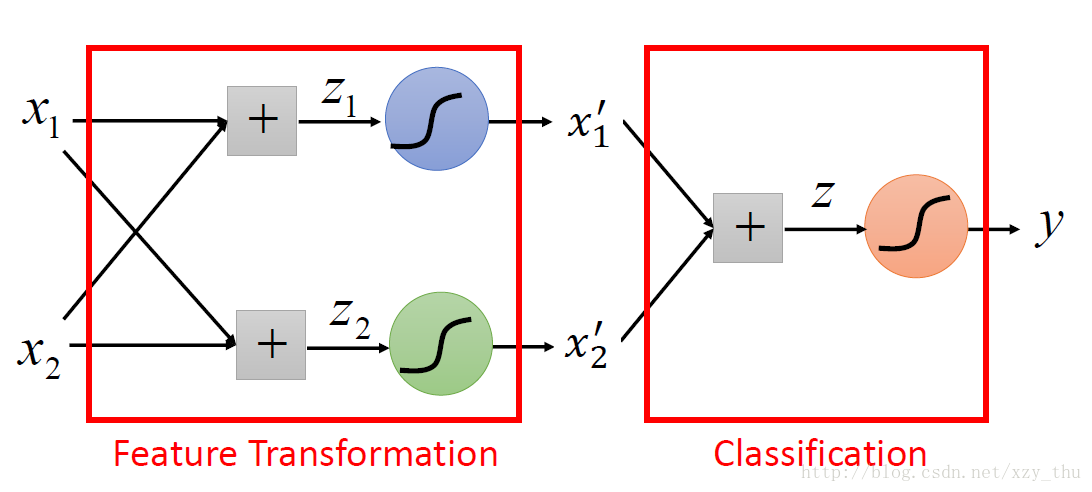
一个Logistic Regression的input可以是其它Logistic Regression的output;一个Logistic Regression的output可以是其它Logistic Regression的input。这样,我们就得到了Neural Network,其中每个Logistic Regression叫做一个Neuron.
Lecture 6: Brief Introduction of Deep Learning
Step 1: function set
Neuron之间采用不同的连接方式,就会得到不同的网络结构。
给定了网络结构,就定义了一个function set。
给定了网络结构并给定了参数,网络就是一个函数:输入输出都是向量。
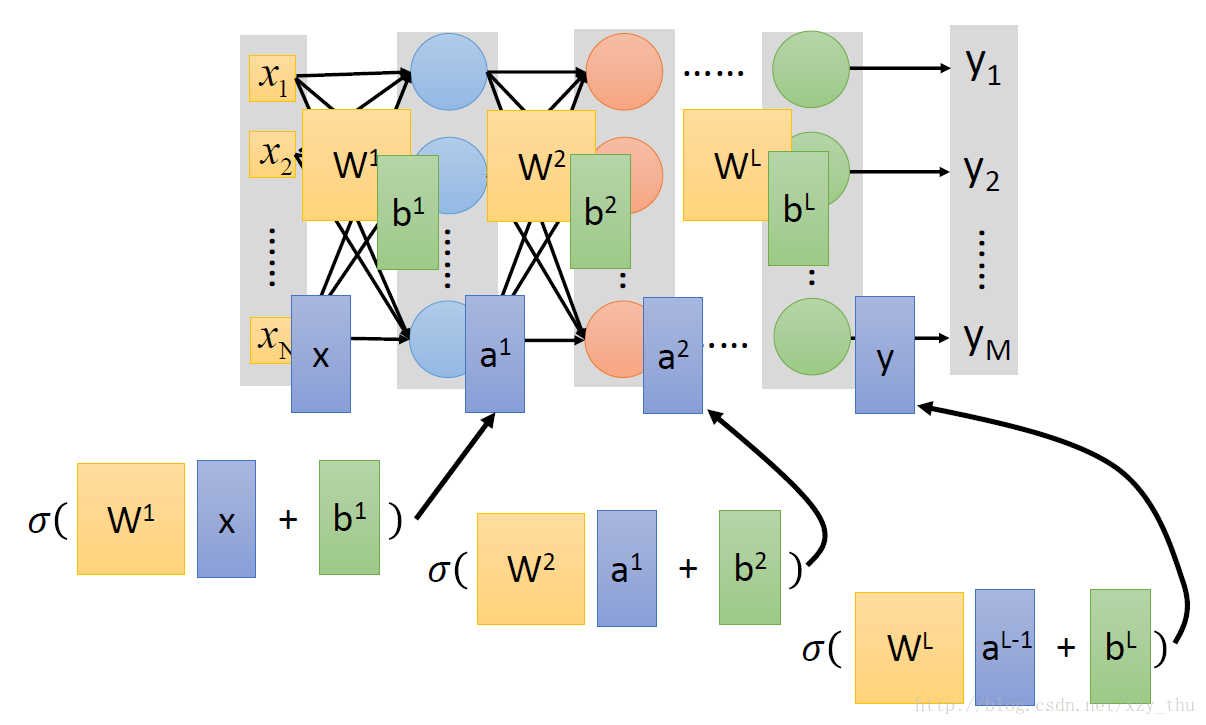

在output layer之前的部分,可以看做特征提取。output layer是Multi-class Classifier.

Step 2: goodness of function
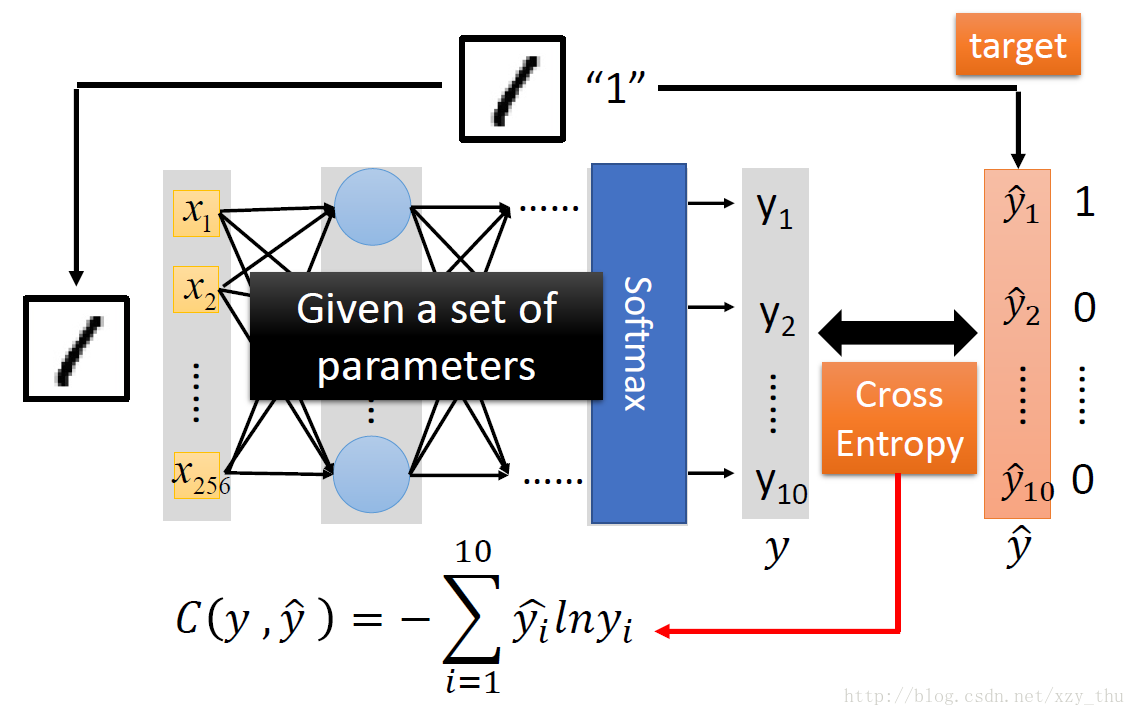
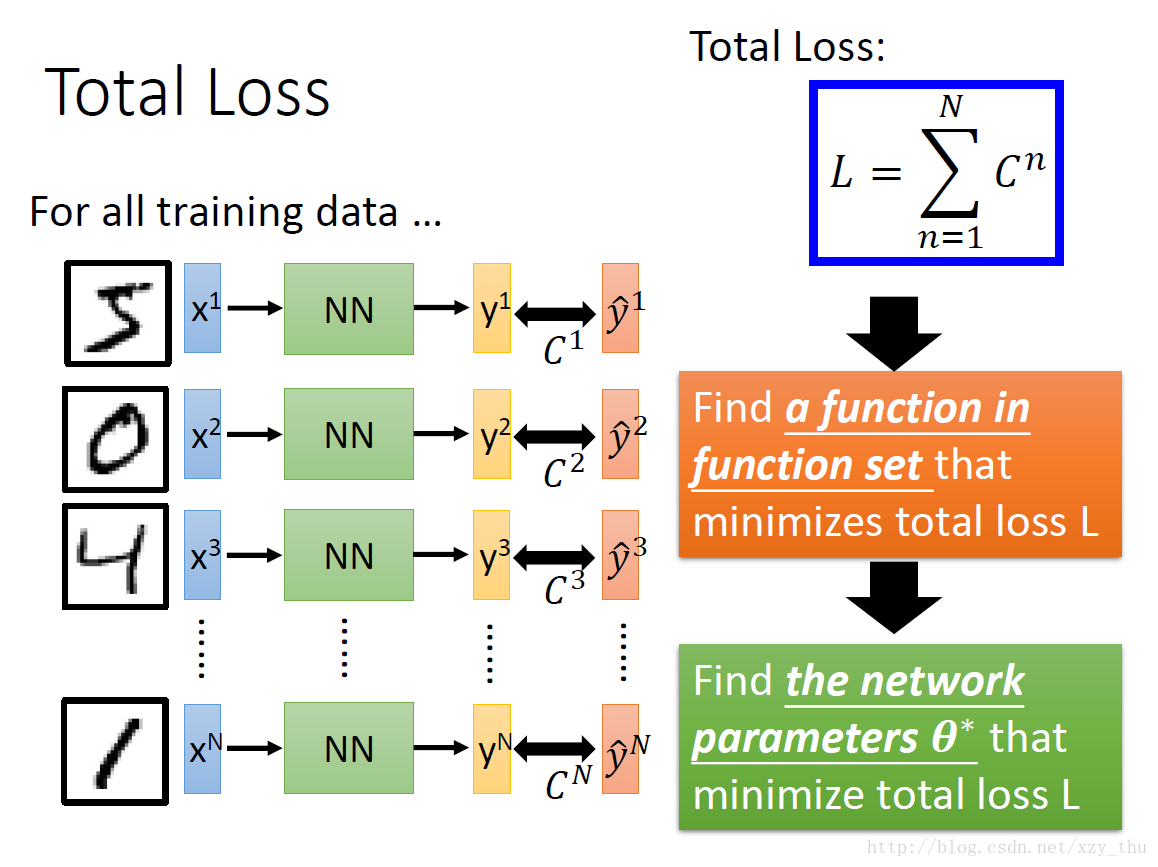
Step 3: pick the best function
Gradient Descent

李宏毅机器学习课程笔记
李宏毅机器学习课程笔记1:Regression、Error、Gradient Descent
李宏毅机器学习课程笔记2:Classification、Logistic Regression、Brief Introduction of Deep Learning
李宏毅机器学习课程笔记3:Backpropagation、”Hello world” of Deep Learning、Tips for Training DNN
李宏毅机器学习课程笔记4:CNN、Why Deep、Semi-supervised
李宏毅机器学习课程笔记5:Unsupervised Learning - Linear Methods、Word Embedding、Neighbor Embedding
李宏毅机器学习课程笔记6:Unsupervised Learning - Auto-encoder、PixelRNN、VAE、GAN
李宏毅机器学习课程笔记7:Transfer Learning、SVM、Structured Learning - Introduction
李宏毅机器学习课程笔记8:Structured Learning - Linear Model、Structured SVM、Sequence Labeling
李宏毅机器学习课程笔记9:Recurrent Neural Network
李宏毅机器学习课程笔记10:Ensemble、Deep Reinforcement Learning















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









