






 本文介绍了Hadoop生态系统的组成部分,如Hive、Pig、HBase等,详细讲解了MapReduce和Spark的计算模型、特点以及它们之间的区别。同时区分了结构化和非结构化数据。最后,通过Linux基础命令实践加深理解。
本文介绍了Hadoop生态系统的组成部分,如Hive、Pig、HBase等,详细讲解了MapReduce和Spark的计算模型、特点以及它们之间的区别。同时区分了结构化和非结构化数据。最后,通过Linux基础命令实践加深理解。
一.Hadoop 生态圈组件介绍
Hadoop的核心组件是HDFS、MapReduce。随着处理任务不同,各种组件相继出现,丰富Hadoop生态圈 根据服务对象和层次分为:数据来源层、数据传输层、数据存储层、资源管理层、数据计算层、任务调度层、业务模型层。
以下是一些常见的 Hadoop 生态圈组件:
-
Hive:Hive 是一个基于 Hadoop 的数据仓库基础设施,它提供了类似于 SQL 的查询语言,使用户能够通过简单的 SQL 查询来处理存储在 Hadoop 上的大数据。
-
Pig:Pig 是一个类似于脚本语言的数据处理工具,它允许用户使用 Pig Latin 这种高级语言来编写数据转换和分析脚本。
-
HBase:HBase 是一个分布式的、面向列的 NoSQL 数据库,它以 Hadoop 分布式文件系统 (HDFS) 为基础,提供了快速读写和实时查询的能力。
-
Sqoop:Sqoop 是一个工具,用于将结构化数据传输到 Hadoop 生态圈中的其他组件,如 Hive 和 HBase。
-
Flume:Flume 是一个分布式的日志收集和聚合系统,用于将事件数据从各种源头收集到 Hadoop 或其他存储系统中。
-
Spark:Spark 是一个用于大规模数据处理和分析的快速和通用的计算引擎,它提供了内存计算、流式处理和机器学习等功能。
-
Storm:Storm 是一个分布式实时计算系统,用于处理大规模的流式数据。
-
ZooKeeper:ZooKeeper 是一个分布式的协调服务,用于管理和协调 Hadoop 生态圈中的各个组件。
这些组件都是 Hadoop 生态圈中非常重要的一部分,它们可以相互配合使用,构建出强大的大数据处理解决方案。
二.重点介绍mapreduce概述
mapreduce是hadoop的计算框架,它与hdfs关系紧密。可以说它的计算思想是基于分布式文件而设计的。MapReduce最早是由Google公司研究提出的一种面向大规模数据处理的并行计算模型和方法。
MapReduce是一种用于处理和生成大规模数据集的编程模型和算法。它最初由Google提出,并成为了Hadoop生态系统的核心组件之一。
MapReduce的核心思想是将一个大任务分解成若干个小任务,并在分布式计算集群上并行处理这些小任务。它包含两个主要阶段:Map阶段和Reduce阶段。
在Map阶段,输入数据集被分割成若干个小的数据块,然后每个数据块被并行处理。在这个阶段,用户需要实现一个Map函数,将输入数据映射成一系列的(key, value)对。Map函数可以是任意的计算逻辑,由用户根据具体的需求自定义。
在Reduce阶段,Map阶段产生的中间结果被合并和排序,并根据指定的规则进行处理。在这个阶段,用户需要实现一个Reduce函数,将相同key的value进行处理和聚合。Reduce函数的输出结果可能是一个新的(key, value)对,或者是单个的值。
MapReduce的优点是能够有效地处理大规模的数据集,并且具有良好的可扩展性和容错性。它可以运行在具有成百上千台机器的分布式计算集群上,并充分利用这些计算资源。
除了Map和Reduce函数,MapReduce还有一些其他的组件和功能,例如数据的划分和排序、任务调度和容错机制等。这些组件和功能由底层的分布式文件系统(如HDFS)和集群管理器(如YARN)来支持。
总而言之,MapReduce是一种用于处理大规模数据集的编程模型和算法,它通过将任务分解并在分布式计算集群上并行处理,提供了高效、可扩展和容错的数据处理能力。
三.重点介绍spark技术特点和概述
Spark是一种快速、通用、可扩展的大数据处理框架,用于在分布式环境中进行大规模数据处理。它具有以下几个技术特点:
-
高速处理:Spark使用内存计算的方式,相比于其他大数据处理框架如Hadoop MapReduce,具有更快的处理速度。Spark将数据存储在内存中,从而避免了磁盘读写的开销,提高了处理效率。
-
易于使用:Spark提供了简单易用的API,支持使用多种编程语言如Java、Scala、Python等进行开发。Spark还提供了交互式的Shell,可以方便地进行实时数据分析和调试。
-
强大的生态系统:Spark拥有丰富的生态系统,包括Spark SQL用于结构化数据处理、Spark Streaming用于实时数据处理、MLlib用于机器学习、GraphX用于图计算等。这些组件可以无缝集成,使得在一个Spark应用中可以同时进行多种类型的数据处理。
-
高可靠性和可扩展性:Spark的底层实现基于分布式计算模型,具有高可靠性和可扩展性。Spark可以轻松地在集群中进行扩展,以处理更大规模的数据。
-
内置的优化:Spark内置了多种优化技术,如数据分片、数据本地性调度、内存管理等,使得Spark能够更有效地利用集群资源,提高计算效率。
Spark的概述可以归纳为以下几个方面:
-
数据抽象:Spark提供了一种抽象的数据集,称为弹性分布式数据集(RDD)。RDD是一个可分区、可并行操作的容错容器,可以在内存中存储和操作数据。RDD可以从磁盘文件、Hadoop HDFS、Hive、HBase等数据源中创建,也可以通过转换操作进行衍生和转换。
-
应用模型:Spark支持多种应用模型,包括批处理、交互式查询和实时流处理。Spark可以处理各种数据类型,包括结构化数据、半结构化数据和非结构化数据。
-
执行引擎:Spark的执行引擎负责将用户的应用程序转换为底层的物理执行计划,并将计划分发到集群中的多个节点上执行。Spark的执行引擎采用了一种基于任务的调度模型,将应用程序划分为多个任务,并在集群中并行执行这些任务。
总之,Spark是一种快速、易用、可扩展的大数据处理框架,具有强大的生态系统和内置的优化技术,适用于各种数据处理和分析场景。
四.对比mapreduce和spark的区别
MapReduce和Spark是两种处理大规模数据集的计算模型,它们有一些共同点,也有一些区别。
共同点:
1. 分布式计算:MapReduce和Spark都是基于分布式计算的框架,可以处理大规模的数据集,利用集群中的多台计算机并行执行任务。
2. 可伸缩性:两者都可以自动调整计算资源,以适应不同规模的数据处理需求。
区别:
1. 内存处理:Spark采用了内存计算模型,而MapReduce则是将中间结果写入磁盘。因此,Spark在某些情况下可以比MapReduce更快,尤其是对于迭代算法和交互式查询。
2. 运行模型:MapReduce的运行模型是将数据集分为不同的块,然后针对每个块并行执行map和reduce操作。而Spark则将整个数据集加载到内存中,并在内存中进行操作。
3. 编程模型:MapReduce通常使用Java编程语言进行编程,而Spark可以使用多种编程语言,包括Java、Scala、Python和R等。
4. 支持的操作:MapReduce和Spark都支持map和reduce操作,但Spark还支持其他更高级的操作,如过滤、排序、聚合等,使得编写复杂的数据处理任务更加方便。
总的来说,Spark相对于MapReduce来说更加灵活和高效,尤其适用于需要快速迭代和交互式查询的场景。但对于一些简单的数据处理任务,MapReduce也是一个可行的选择。
五.结构化数据与非结构化数据是什么
结构化数据与非结构化数据是两种不同类型的数据。结构化数据是按照预定的模式和格式组织的数据,可以轻松进行分类、过滤和分析。它通常以表格、数据库或电子表格的形式存在,具有明确的字段和值。常见的结构化数据包括人口统计数据、销售数据、银行交易记录等。
非结构化数据则是没有特定格式或组织方式的数据,通常以自由文本的形式存在。这种数据不容易进行自动处理和分析,因为它没有明确的结构或规则。非结构化数据包括电子邮件、社交媒体帖子、音频和视频文件、乃至于图像和PDF文档等。这些数据通常需要使用自然语言处理、图像识别或计算机视觉等技术来提取有价值的信息。
六.Linux基本命令练习
1.先创建两个用来练习的目录lx1和lx2(命令mkdir)
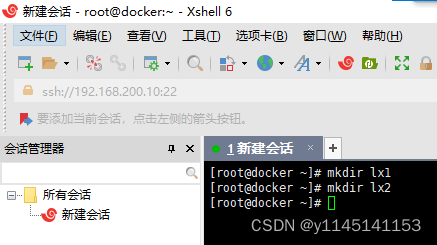
2.查看当前所在位置pwd以及进入目录(命令cd)
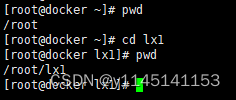
3.创建文件(touch)复制文件(cp)删除文件(rm)移动文件(mv)
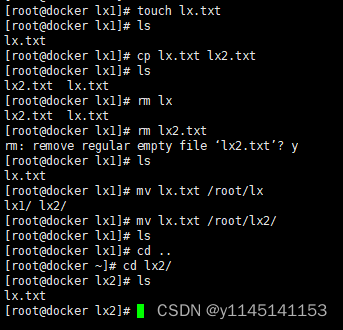
4.编写文件(vi)与查看文件内容(cat)
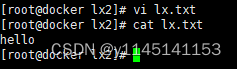
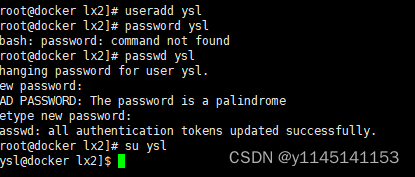
5.创建用户(useradd)以及切换用户(su)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









