






搭建单机版的scala和spark以及hadoop
(一).搭建spark
1.解压spark包
tar -axf spark-2.0.0-bin-hadoop2.7.gz -C /usr/local/

2.编写spark-env.sh
cp spark-env.sh.template spark-env.sh
[root@master conf]# vi spark-env.sh
把下列路径加入最后
export JAVA_HOME=/usr/local/src/jdk1.8.0_152 #指定jdk位置如没有需下载
export HADOOP_HOME=/usr/local/src/hadoop #指定hadoop路径
export HADOOP_CONF_DIR=/usr/local/src/hadoop/etc/hadoop #指定hadoop路径
export SPARK_MASTER_IP=master
export SPARK_LOCAL_IP=master
3.启动spark集群
[root@master spark-2.0.0-bin-hadoop2.7]# cd sbin/
[root@master sbin]# ./start-all.sh
4.jps查看是否拥有worker
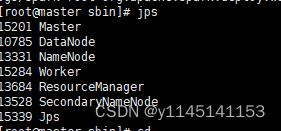
5.使用./bin/spark-shell 命令启动hadoop
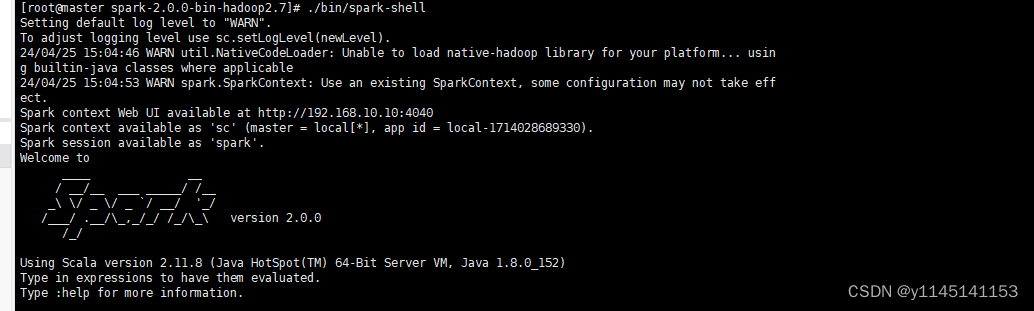
6.在浏览器输入ip地址+8080端口查看
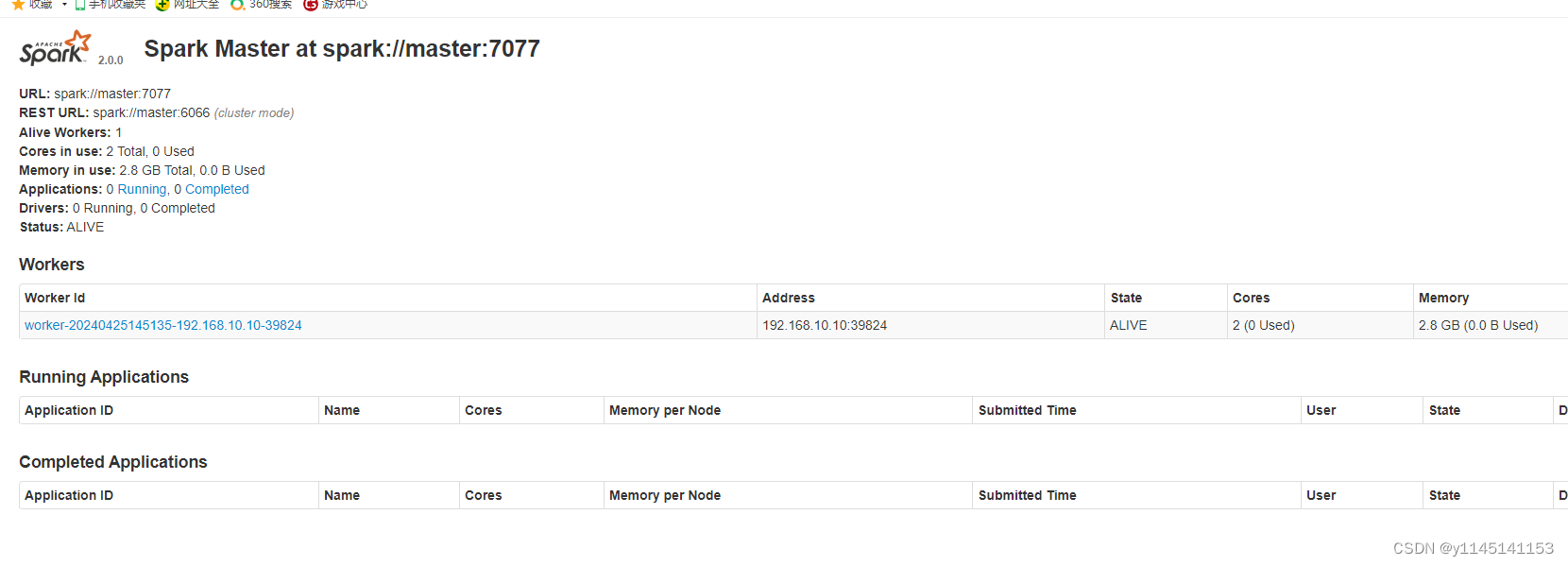
(二).搭建单机版scala
1.解压scala包
tar -axf scala-2.11.8.tgz -C /usr/local/
![]()
2.编写/etc/profile在最下面添加如下路径
export SCALA_HOME=/usr/local/scala-2.11.8 #指定scala路径
export PATH=$PATH:$SCALA_HOME/bin

3.使用source /etc/profile来更新启用scala
4.最后在命令行输入scala即可

(三).hadoop 全分布配置在 Master 节点上安装 Hadoop(需提前穿好三台虚拟机配好IP并关闭防火墙及selinux)
解压tar -zxvf /opt/software/hadoop-2.7.1.tar.gz -C /usr/local/src
mv /usr/local/src/hadoop-2.7.1 /usr/local/src/hadoop
在文件末尾添加以下配置信息
[root@master ~]# vi /etc/profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
ExportHADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使配置的 Hadoop 的环境变量生效
[root@master ~]# su - hadoop
[hadoop@master ~]# source /etc/profile
[hadoop@master ~]# exit
执行以下命令修改 hadoop-env.sh 配置文件
[root@master ~]# cd /usr/local/src/hadoop/etc/hadoop/
在文件末尾添加以下配置信息
[root@masterhadoop]#vi hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
配置 hdfs-site.xml 文件参数
执行以下命令修改 hdfs-site.xml 配置文件。
[root@master hadoop]# vi hdfs-site.xml
#在文件中<configuration>和</configuration>一对标签之间追加以下配置信息
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
配置 core-site.xml 文件参数
执行以下命令修改 core-site.xml 配置文件。
[root@master hadoop]# vi core-site.xml
#在文件中<configuration>和</configuration>一对标签之间追加以下配置信息
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://主机ip地址:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
</property>
</configuration>
配置 mapred-site.xml
在“/usr/local/src/hadoop/etc/hadoop”目录下有一个 mapred-site.xml.template,
需要修改文件名称,把它重命名为 mapred-site.xml,然后把 mapred-site.xml 文件配置成
如下内容。
执行以下命令修改 mapred-site.xml 配置文件。
#确保在该路径下执行此命令
[root@master hadoop]# cd /usr/local/src/hadoop/etc/hadoop
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
#在文件中<configuration>和</configuration>一对标签之间追加以下配置信息
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
配置 yarn-site.xml
执行以下命令修改 yarn-site.xml 配置文件。
[root@master hadoop]# vi yarn-site.xml
#在文件中<configuration>和</configuration>一对标签之间追加以下配置信息
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
配置 masters 文件
执行以下命令修改 masters 配置文件。
#加入以下配置信息
[root@master hadoop]# vi masters
master 主机 IP 地址
配置 slaves 文件
删除 localhost,加入以下配置信息
[root@master hadoop]# vi slaves
slave1 主机 IP 地址
slave2 主机 IP 地址
新建目录
执行以下命令新建/usr/local/src/hadoop/tmp、/usr/local/src/hadoop/dfs/name、
/usr/local/src/hadoop/dfs/data 三个目录。
[root@master hadoop]# mkdir /usr/local/src/hadoop/tmp
[root@master hadoop]# mkdir /usr/local/src/hadoop/dfs/name -p
[root@master hadoop]# mkdir /usr/local/src/hadoop/dfs/data -p
修改目录权限
执行以下命令修改/usr/local/src/hadoop 目录的权限。
[root@master hadoop]# chown -R hadoop:hadoop /usr/local/src/hadoop/
同步配置文件到 Slave 节点
上 述 配 置 文 件 全 部 配 置 完 成 以 后 , 需 要 执 行 以 下 命 令 把 Master 节 点 上 的
“/usr/local/src/hadoop”文件夹复制到各个 Slave 节点上,并修改文件夹访问权限。
(1)将 Master 上的 Hadoop 安装文件同步到 slave1、slave2。
[root@master hadoop]#cd
[root@master ~]# scp -r /usr/local/src/hadoop/ root@slave1:/usr/local/src/
[root@master ~]# scp -r /usr/local/src/hadoop/ root@slave2:/usr/local/src/
在每个 Slave 节点上配置 Hadoop 的环境变量。
注意:若 slave1,slave2 在/usr/local/src/目录下 jdk1.8.0_152 文件,需返回安装好 Java 环境
[root@slave1~]# vi /etc/profile #文件末尾添加
[root@slave2~]# vi /etc/profile #文件末尾添加
# set java environment
# JAVA_HOME 指向 JAVA 安装目录
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
# 将 JAVA 安装目录加入 PATH 路径
export PATH=$PATH:$JAVA_HOME/bin
# set hadoop environment
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
(3)在每个 Slave 节点上修改/usr/local/src/hadoop 目录的权限。
[root@slave1~]# chown -R hadoop:hadoop /usr/local/src/hadoop/
[root@slave2~]# chown -R hadoop:hadoop /usr/local/src/hadoop/
(4)在每个 Slave 节点上切换到 hadoop 用户。
[root@slave1 ~]#su - hadoop
[root@slave2 ~]#su - hadoop
(5)使每个 Slave 节点上配置的 Hadoop 的环境变量生效。
[hadoop@slave1~]# source /etc/profile
[hadoop@slave2~]# source /etc/profile
NameNode格式化
执行如下命令,格式化 NameNode
[root@master ~]# su – hadoop
[hadoop@master ~]# cd /usr/local/src/hadoop/
[hadoop@master hadoop]$ bin/hdfs namenode –format
执行如下命令,启动 NameNode:
[hadoop@master hadoop]$ hadoop-daemon.sh start namenode
查看 Java 进程
[hadoop@master hadoop]$ jps
步骤一:slave 启动 DataNode
执行如下命令,启动 DataNode:
[hadoop@slave1 hadoop]$ hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop2.7.1/logs/hadoop-hadoop-datanode-master.out
[hadoop@slave2 hadoop]$ hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop2.7.1/logs/hadoop-hadoop-datanode-master.out
[hadoop@slave1 hadoop]$ jps
3557 DataNode
3725 Jps
[hadoop@slave2 hadoop]$ jps
3557 DataNode
3725 Jps
1.4.2.2. 步骤二:启动 SecondaryNameNode
执行如下命令,启动 SecondaryNameNode:
[hadoop@master hadoop]$ hadoop-daemon.sh start secondarynamenode
starting secondarynamenode, logging to /opt/module/hadoop2.7.1/logs/hadoop-hadoop-secondarynamenode-master.out
[hadoop@master hadoop]$ jps
34257 NameNode
34449 SecondaryNameNode
34494 Jps
查看到有 NameNode 和 SecondaryNameNode 两个进程,就表明 HDFS 启动成功。
1.4.2.3. 步骤三:查看 HDFS 数据存放位置:
执行如下命令,查看 Hadoop 工作目录:
[hadoop@master hadoop]$ ll dfs/
总用量 0
drwx------ 3 hadoop hadoop 21 8 月 14 15:26 data
drwxr-xr-x 3 hadoop hadoop 40 8 月 14 14:57 name
[hadoop@master hadoop]$ ll ./tmp/dfs
总用量 0
drwxrwxr-x. 3 hadoop hadoop 21 5 月 2 16:34 namesecondary
用浏览器查看节点状态
在浏览器的地址栏输入http://ip地址:50070,进入页面可以查看NameNode和DataNode
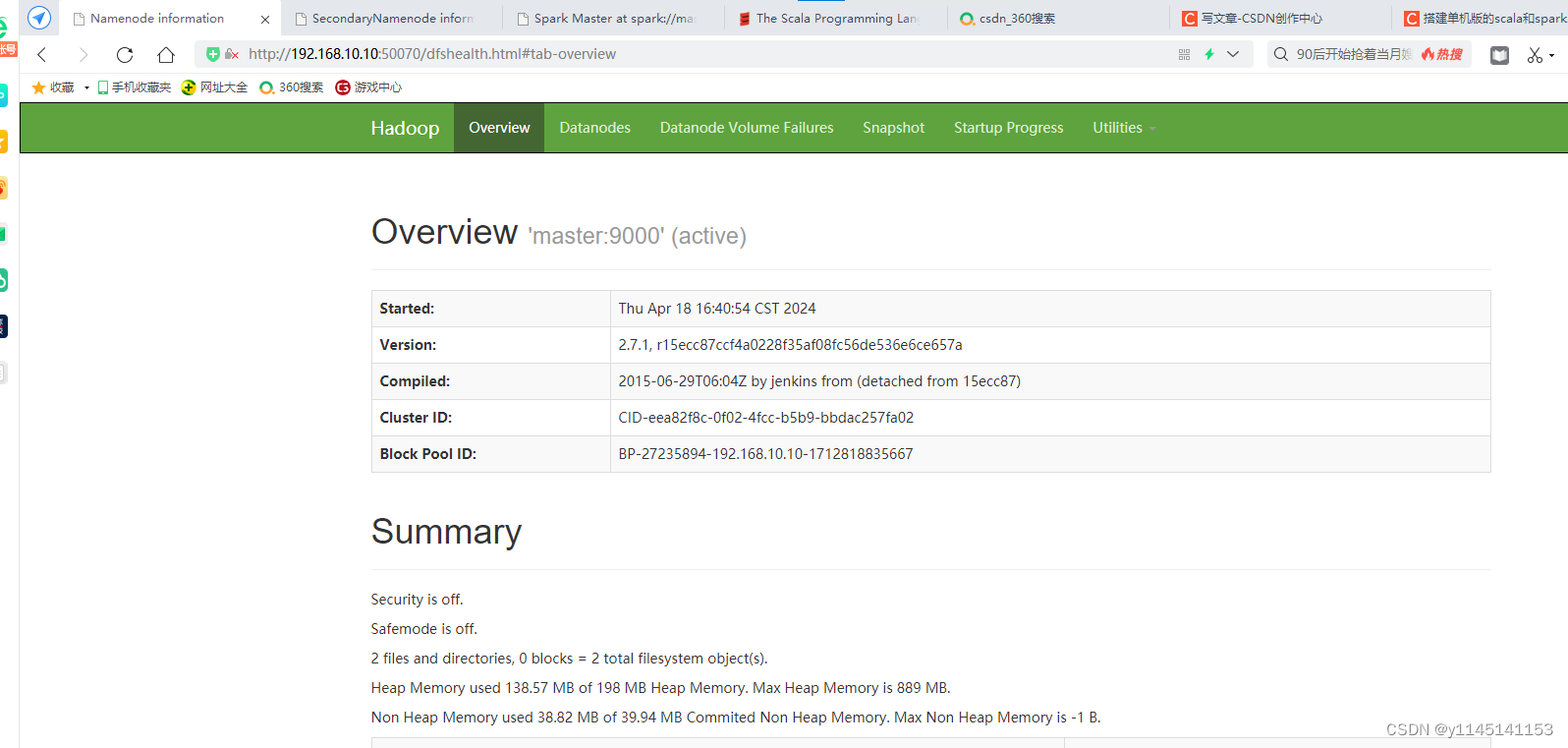
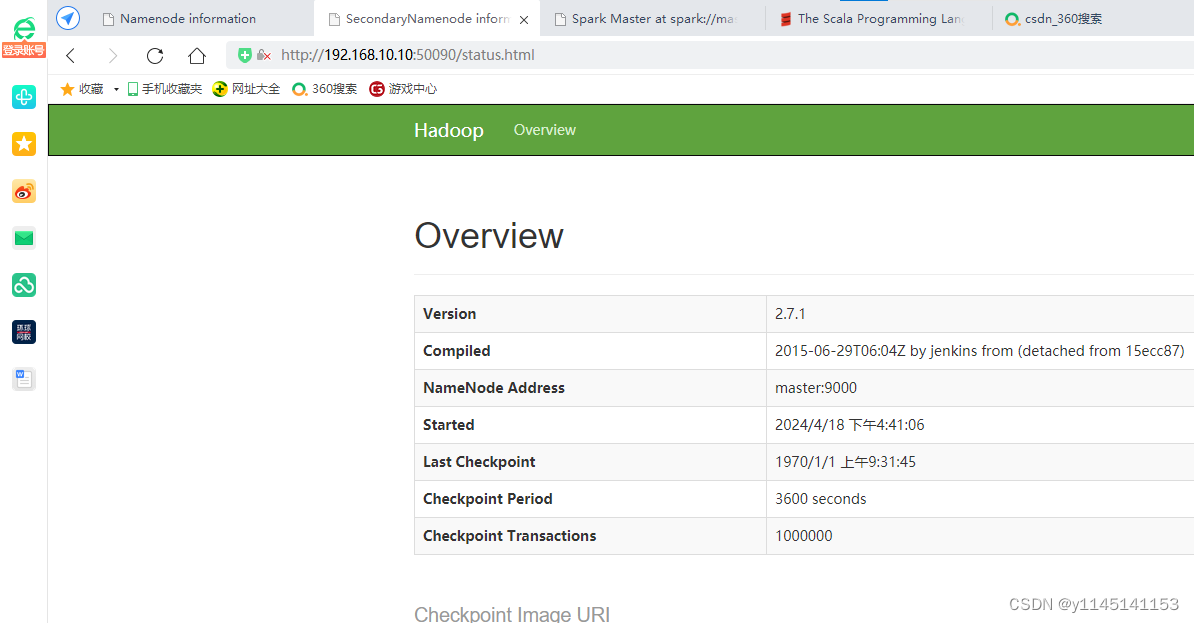
在浏览器的地址栏输入http://ip地址:50090















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









