







 本文详细介绍了R语言中的基本操作,包括工作目录的切换、文件列表、变量操作、数据结构(向量、矩阵、数组、数据框和列表)以及因子的处理,同时还涉及R包的安装、卸载和使用,以及获取帮助和数据处理方法。
本文详细介绍了R语言中的基本操作,包括工作目录的切换、文件列表、变量操作、数据结构(向量、矩阵、数组、数据框和列表)以及因子的处理,同时还涉及R包的安装、卸载和使用,以及获取帮助和数据处理方法。
目录
一,基础操作
getwd():显示当前工作目录
> getwd()
[1] "C:/Users/72786/Documents"setwd('E:/RWorkSpace') : 修改当前工作目录地址,注意,此处要使用正斜线
> setwd('D:/RWorkSpace')
> getwd()
[1] "D:/RWorkSpace"list.files() 和 dir() :查看目录下包含的文件
> list.files()
[1] "Call of Duty" "desktop.ini" "KoeiTecmo" "League of Legends"
[5] "My Music" "My Pictures" "My Videos" "NetPowerZIPData"
[9] "OneNote 笔记本" "Rockstar Games" "Sunlogin Files" "WeChat Files"
[13] "自定义 Office 模板"> dir()
[1] "Call of Duty" "desktop.ini" "KoeiTecmo" "League of Legends"
[5] "My Music" "My Pictures" "My Videos" "NetPowerZIPData"
[9] "OneNote 笔记本" "Rockstar Games" "Sunlogin Files" "WeChat Files"
[13] "自定义 Office 模板"x <- 3:表示 x=3
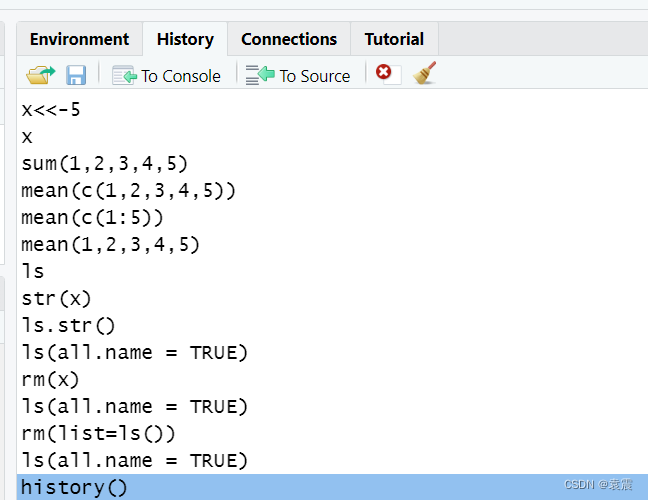
> x<-3
> x
[1] 3x <<- 5 :强制赋值给一个全局变量
> x<<-5
> x
[1] 5sum(1,2,3,4,5) : 求和得15
> sum(1,2,3,4,5)
[1] 15mean(c(1,2,3,4,5)) or mean(c(1:5)):求均值得3,mean(1,2,3,4,5)得到的是1 ,因为mean()是对第一个参数求均值
> mean(c(1,2,3,4,5))
[1] 3
> mean(c(1:5))
[1] 3
> mean(1,2,3,4,5)
[1] 1ls:列出当前工作空间中定义的所有变量
> ls
[1] "a" "age" "array" "b" "c" "d" "dim1" "dim2" "dim3" "myList" "name"
[12] "patientData" "patientId" "x" str(x):列出变量x的详细信息
> str(x)
num 5ls.str():列出当前工作空间中所有变量的详细信息(如值等)
> ls.str()
a : num [1:5] 1 2 3 4 5
b : num [1:5] 2 4 6 8 10
data2 : 'data.frame': 2 obs. of 3 variables:
$ a: chr "1" "2"
$ b: num 2 3
$ c: chr "3" "4"
mydata : 'data.frame': 5 obs. of 2 variables:
$ a: num 1 2 3 4 5
$ b: num 2 4 6 8 10
x : num 5ls(all.name = TRUE):ls() 函数不能列出工作目录下的隐藏文件,添加“all.name=TRUE”就可以显示
> ls(all.name = TRUE)
[1] ".Random.seed" "a" "b" "data2" "mydata" "x" rm(x):删除工作空间中不需要的对象,也可以删除多个,用逗号隔开,删除后无法恢复
> rm(x)
> ls(all.name = TRUE)
[1] ".Random.seed" "a" "b" "data2" "mydata" rm (list=ls()):删除工作空间中所有的对象
> rm(list=ls())
> ls(all.name = TRUE)
[1] ".Random.seed"history():列出历史记录,history(10) 列出最近的十条历史记录
save.image():保存工作空间,避免软件异常退出,只会保留数据及绘图函数等。
二,R包安装及使用
install.packages(" R 包名 ") : 注意:安装包,包名要用引号引起来
install.packages ("RColorBrewer")library() :显示库中所有的安装包

library(包名) 或 require(包名):载入R包,这里的包名不需要用引号
R基础包在启动R时就会被加载进来:base、datasets、utils、grDevices、graphics、stats、methods、splines、stats4和tcltk。
help(package=“包名”):列出这个包的帮助文档
library(help="包名):列出包的基础信息
ls("package:包名"):列出R包中所有的函数
data(package="包名"):列出R包中包含的所有数据集
detach("package: 包名"):移除加载的包,非删除,可重新使用require或library加载
remove.package("包名"):删除已安装的包
R包的批量移植,在新设备上克隆R包:
installed.packages():列出当前环境中已安装的R包的所有信息
installed.packages()[,1]:获取到当前环境中已安装的包名
Rpack <- installed.packages()[,1]:将所有R的名字保存到一个文件中
save(Rpack, file="Rpack.Rdata"):保存
load("Rpack.Rdata"):在新设备上加载for (i in Rpack) install.packages():批量安装这些包
三,获取帮助
help.start():获取R的帮助信息
help(函数名) 或 ?函数名:列出某函数的帮助信息,需加载包后再help
??函数名:不需要加载包就可以获取帮助信息
args(函数名):直接在终端中输出函数的参数,快速了解函数的参数而不想查阅详细的文档
example(函数名):获取函数的使用示例
example("hist"):也可以列出绘图示例
demo(graphics):绘图的案例
help(package=包名):查看R安装的某个包的帮助文档
help.search("heatmap"):不知道具体的函数名,模糊查询heatmap相关函数
apropos("sum", mod="function"):列出所有包含sum关键字的函数
RSiteSearch("matlab"):进行网络搜索,使用默认浏览器访问官网,help.search 和 ?? 都只能进行本地的搜索
四,数据集
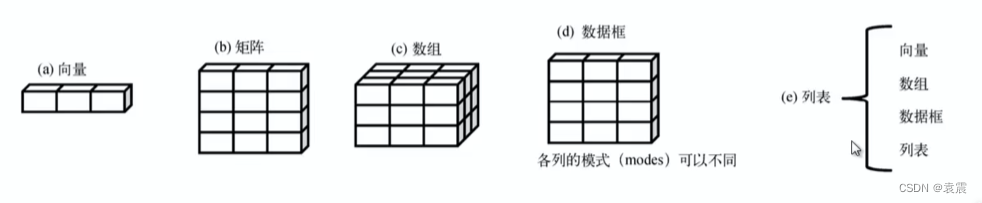
数据集通常是由数据构成的一个矩形数组,行表示记录,列表示属性(字段)

R拥有许多用于存储数据的对象类型,包括向量,矩阵,数组,数据框和列表
这些数据结构在存储数据的类型,创建方式,定位和访问其中个别元素的方法等方面有所不同
五,向量
向量是用于存储数值型、字符型或逻辑型数据的一维数组。用函数c来创建向量。
> a <-c(1,2,3,4,5)
> a
[1] 1 2 3 4 5
> b<-c("one","two","three")
> b
[1] "one" "two" "three"
> c<-c(T,T,F,F,F)
> c
[1] TRUE TRUE FALSE FALSE FALSE注意:如果其中一个元素为字符串,其余元素为int类型,则全部转换为字符串类型
访问向量中的某个元素或者某几个元素:
> a[2]
[1] 2
> a[c(1,3,4)]
[1] 1 3 4
> a[1:3]
[1] 1 2 3六,矩阵
矩阵用函数matrix来创建矩阵,nrow 和 ncol 可以省略,但其值必须满足分配条件,否则会报错
?matrix 获取帮助
创建一个矩阵:
> y<-matrix(5:24,nrow =4,ncol = 5)
> y
[,1] [,2] [,3] [,4] [,5]
[1,] 5 9 13 17 21
[2,] 6 10 14 18 22
[3,] 7 11 15 19 23
[4,] 8 12 16 20 24创建一个自定义行和列的矩阵:
> x<-c(1,2,55,33,44,55,66,77,88)
> rnames<-c("R1","R2","R3")
> cnames<-c("C1","C2","C3")
> newMatrix<-matrix(x,nrow=3,ncol=3,byrow=TRUE,dimnames=list(rnames,cnames))
> newMatrix
C1 C2 C3
R1 1 2 55
R2 33 44 55
R3 66 77 88按列来填充的矩阵:
> newMatrix<-matrix(x,nrow=3,ncol=3,dimnames=list(rnames,cnames))
> newMatrix
C1 C2 C3
R1 1 33 66
R2 2 44 77
R3 55 55 88定义一个2行的1到20的矩阵
> x<- matrix(1:20,nrow=2)
> x
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 1 3 5 7 9 11 13 15 17 19
[2,] 2 4 6 8 10 12 14 16 18 20获取矩阵的某个元素
> x[2,1]
[1] 2
获取矩阵的某行或某列
> x[1,]
[1] 1 3 5 7 9 11 13 15 17 19
> x[,2]
[1] 3 4七,数组
array函数创建数组
创建一个3*3*2的三维数组
> array(1:24, c(2,3,4), dimnames=list(dim1, dim2, dim3))
> dim1<-c("A1","A2","A3")
> dim2<-c("B1","B2","B3")
> dim3<-c("C1","C2")
> array<-array(1:18, c(3,3,2), dimnames=list(dim1, dim2, dim3))
> array
, , C1
B1 B2 B3
A1 1 4 7
A2 2 5 8
A3 3 6 9
, , C2
B1 B2 B3
A1 10 13 16
A2 11 14 17
A3 12 15 18获取数组的某个元素
> array[1,1,1]
[1] 1八,数据框
数据框是一种表格形式的数据结构,数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。
数据框实际上是一个列表,列表中的元素是向量,这些向量构成数据框的列,每一列必须具有相同的长度,所以数据框是矩形结构,而且数据框的列必须命名。矩阵与数据框的区别:数据框形状很想矩阵;数据框是比较规则的列表;矩阵必须为同一数据类型;数据框每一列必须为同一类型,每一行可以不同。
创建一个数据框
> patientId<-c(1,2,3,4,5)
> name<-c("张三","李四","周五","李白","杜甫")
> age<-c(18,19,20,21,22)
> patientData<-data.frame(patientId,name,age)
> patientData
patientId name age
1 1 张三 18
2 2 李四 19
3 3 周五 20
4 4 李白 21
5 5 杜甫 22获取前两列
> patientData[1:2]
patientId name
1 1 张三
2 2 李四
3 3 周五
4 4 李白
5 5 杜甫根据列名获取
> patientData[c("patientId","name")]
patientId name
1 1 张三
2 2 李四
3 3 周五
4 4 李白
5 5 杜甫用$获取
> patientData$name
[1] "张三" "李四" "周五" "李白" "杜甫"用attach
> attach(patientData)
> age
[1] 18 19 20 21 22
> name
[1] "张三" "李四" "周五" "李白" "杜甫"
> detach(patientData)九,列表
用list创建列表
> a<-c(1,2,3,4)
> b<-"hello,袁震"
> c<-matrix(1:20,nrow=4)
> d<-list(a,b)
> myList<-list(a,b,c,d)
> myList
[[1]]
[1] 1 2 3 4
[[2]]
[1] "hello,袁震"
[[3]]
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
[[4]]
[[4]][[1]]
[1] 1 2 3 4
[[4]][[2]]
[1] "hello,袁震"
访问元素
> myList[1]
[[1]]
[1] 1 2 3 4
> myList[[1]]
[1] 1 2 3 4
> myList[4]
[[1]]
[[1]][[1]]
[1] 1 2 3 4
[[1]][[2]]
[1] "hello,袁震"
> myList[[4]]
[[1]]
[1] 1 2 3 4
[[2]]
[1] "hello,袁震"
十,因子
变量分类:名义型变量、有序型变量、连续型变量。
在R中,名义型变量和有序型变量被称为因子,这些分类变量的可能值称为一个水平,例如good、better、best都称为一个水平。
这些水平值构成的向量就称为因子。因子本身是向量的集合。
因子的应用:计算频数,独立性检验,相关性检验,方差分析,主成分分析,因子分析
将向量转化为因子
> a<-c(1,2,3,6,7,8,9,5,43,6,7,8,9,0,34,56,89)
> b<-factor(a)
> b
[1] 1 2 3 6 7 8 9 5 43 6 7 8 9 0 34 56 89
Levels: 0 1 2 3 5 6 7 8 9 34 43 56 89输出向量图
> plot(a)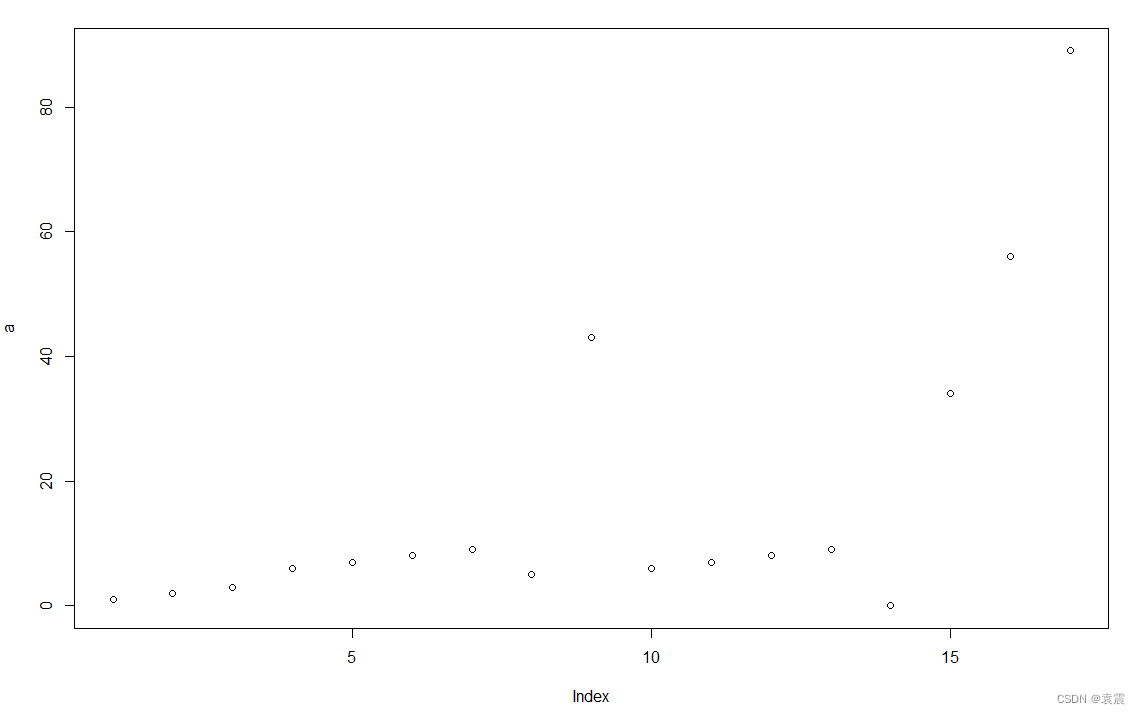
输出因子图
> plot(b) 




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











