






这是导入的word
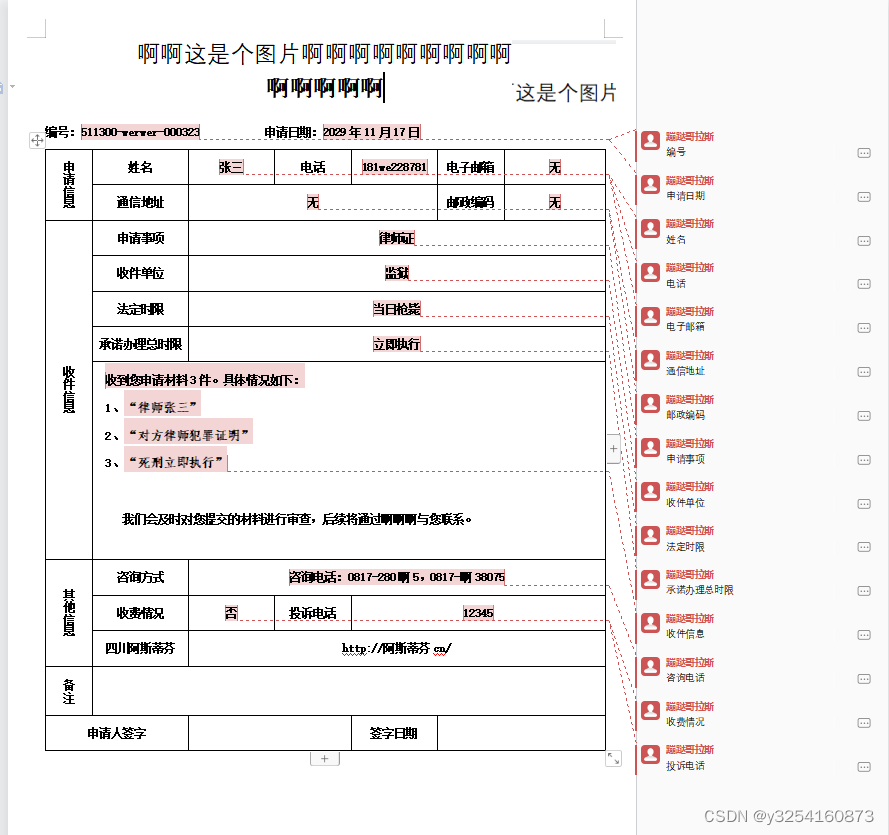
输出效果

pom依赖如下
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j</artifactId>
<version>6.0.1</version>
</dependency>
<dependency>
<groupId>com.documents4j</groupId>
<artifactId>documents4j-local</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>com.documents4j</groupId>
<artifactId>documents4j-transformer-msoffice-word</artifactId>
<version>1.0.3</version>
</dependency>具体代码如下:
package com.ruoyi.dingtalk.datamanage.header.yffService.impl;
import com.documents4j.api.DocumentType;
import com.documents4j.api.IConverter;
import com.documents4j.job.LocalConverter;
import com.ruoyi.dingtalk.datamanage.header.yffService.ServiceYFF;
import lombok.extern.slf4j.Slf4j;
import org.apache.poi.hwpf.extractor.WordExtractor;
import org.apache.poi.xwpf.extractor.XWPFWordExtractor;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.docx4j.Docx4J;
import org.docx4j.TraversalUtil;
import org.docx4j.convert.out.FOSettings;
import org.docx4j.finders.ClassFinder;
import org.docx4j.fonts.IdentityPlusMapper;
import org.docx4j.fonts.Mapper;
import org.docx4j.fonts.PhysicalFont;
import org.docx4j.fonts.PhysicalFonts;
import org.docx4j.jaxb.Context;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.openpackaging.parts.WordprocessingML.MainDocumentPart;
import org.docx4j.wml.*;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import javax.xml.bind.JAXBElement;
import javax.xml.bind.annotation.XmlRootElement;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Objects;
@Service
@Slf4j
public class ServiceYFFImpl implements ServiceYFF {
//"编号:","申请日期:"
// 表格常量标记池
List<String> tableConstantPool = Arrays.asList("电话", "姓名",
"电子邮箱", "通信地址", "承诺办理总时限", "法定时限", "收件单位", "申请事项", "邮政编码",
"签字日期", "申请人签字", "备注", "四川政务服务网", "投诉电话", "收费情况", "咨询方式");
// 临时文件目录
String tempPath = "C:\\Users\\奥特曼-\\Desktop\\";
/**
* @param multipartFile
* @return
* @author afeng
* @action
* 总体思路就是将multipartFile保存为word,再将word读出来进行数据填充,再把填充的word保存回去,最后把word转换为pdf
* 1、判断是不是word文件
* 2、将multipartFile输出成word在处理
* 3、创建对应的word文件
* 4、创建写入流
* 5、讲multipartFile写入进word中
* 6、数据填充
* 7、将word转换成pdf
* 8、删除对应word文件
*/
@Override
public boolean wordToPDFAndAddData(MultipartFile multipartFile) {
// 1、判断是不是word文件
boolean docOrDocx = Objects.requireNonNull(multipartFile.getOriginalFilename()).endsWith(".doc");
if (!Objects.requireNonNull(multipartFile.getOriginalFilename()).endsWith(".docx")
&& !docOrDocx) {
log.info("不是word文件!!");
return false;
}
String filename = multipartFile.getOriginalFilename();
// 如果是doc就给他改下后缀
if(docOrDocx)
filename +="x";
try {
// 2、将multipartFile输出成word在处理
File file = new File(tempPath + filename);
// 3、创建对应的word文件
file.createNewFile();
// 4、创建写入流
FileOutputStream fileOutputStream = new FileOutputStream(file);
// 5、讲multipartFile写入进word中
fileOutputStream.write(multipartFile.getBytes());
// 关闭流
fileOutputStream.close();
// 6、数据填充
readAndWriteParagraph(getWordprocessingMLPackage(file.getPath()),filename);
// 7、将word转换成pdf
wordToPdf(tempPath+filename,tempPath+filename.substring(0, filename.lastIndexOf('.'))+".pdf");
// 8、删除对应word文件
// new File(tempPath+filename).delete();
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* @Author afeng
* @order word转pdf
* @param inPath word路径
* @param outPath pdf路径
* @action
* 将word转为pdf
*
**/
public static void wordToPdf(String inPath, String outPath) {
try {
InputStream docxInputStream = new FileInputStream(inPath);
OutputStream outputStream = new FileOutputStream(outPath);
IConverter converter = LocalConverter.builder().build();
converter.convert(docxInputStream).as(DocumentType.DOCX).to(outputStream).as(DocumentType.PDF).execute();
outputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* @Author afeng
* @order word数据填充
* @param wordprocessingMLPackage word对象
* @param fileName 文件名
* @action
* 1、读取表格内容
* 2、拿到word所有的行
* 3、对编号和申请日期进行数据填充
* 4、获取表格元素
* 5、获取到第一个表格元素,确认这个表格只有一个表格对象
* 6、拿到表格所有的行,从0开始
* 7、对表格的行进行遍历处理
* 7.1、获取到tr 一行元素
* 7.2、获取所有的Tc元素,获取一行的所有列元素
* 7.3、遍历填充表格数据
* 7.3.1、获得具体单元格的对应对象
* 7.3.2、获得具体单元格的对应对象内容的第一行,已经确认要填充数据的行只有一个有换行
* 7.3.3、条件为真,表示后一列的数据需要数据填充,这里直接进行填充
* 7.3.4、有一个内容有多段,单独处理,位置是固定的
* 7.4、将原表格对应行替换
* 8、将原word内的表格替换
* 9、将word保存到本地
*/
public void readAndWriteParagraph(WordprocessingMLPackage wordprocessingMLPackage,String fileName) {
try {
// 1、读取表格内容
MainDocumentPart part = wordprocessingMLPackage.getMainDocumentPart();
// 2、拿到word所有的行
List<Object> list = part.getContent();
// 3、对编号和申请日期进行数据填充
for (int i=0;i<list.size() ;i++) {
if(list.get(i).toString().startsWith("编号")){
list.set(i,part.createParagraphOfText("编号:"+"数据填充!!!编号"
+" 申请日期:"+"数据填充!!!申请日期"));
break;
}
}
// 4、获取表格元素
ClassFinder find = new ClassFinder(Tbl.class);
new TraversalUtil(part.getContent(), find);
// 5、获取到第一个表格元素,确认这个表格只有一个表格对象
Tbl table = (Tbl) find.results.get(0);
// 6、拿到表格所有的行,从0开始
List<Object> trs = table.getContent();
// 7、对表格的行进行遍历处理
for (int j = 0;j<trs.size();j++) {
// 7.1、获取到tr 一行元素
Tr tr = (Tr) trs.get(j);
// 7.2、获取所有的Tc元素,获取一行的所有列元素
List<Object> objList = getAllElementFromObject(tr, Tc.class);
// 7.3、遍历填充表格数据
for(int i=0;i<objList.size();i++){
// 7.3.1、获得具体单元格的对应对象
Tc tc = (Tc) objList.get(i);
// 7.3.2、获得具体单元格的对应对象内容的第一行,已经确认要填充数据的行只有一个有换行
String nowString = tc.getContent().get(0).toString();
// 7.3.3、条件为真,表示后一列的数据需要数据填充,这里直接进行填充
if(Objects.nonNull(fixedValue(nowString))){
Tc tcT = (Tc) objList.get(++i);
tcT.getContent().set(0,part.createParagraphOfText("数据填充!!!"+fixedValue(nowString)));
continue;
}
// 7.3.4、有一个内容有多段,单独处理,位置是固定的
if(j==6 && i==1){
for(int k = 0;k<tc.getContent().size();k++){
tc.getContent().set(k,part.createParagraphOfText("数据填充!!!\n\n"+
"我们会及时对您提交的材料进行审查,后续将通过天府通办与您联系。"));
}
}
}
// 7.4、将原表格对应行替换
table.getContent().set(j,tr);
}
// 8、将原word内的表格替换
part.getContent().set(3,table);
// 9、将word保存到本地
wordprocessingMLPackage.save(new File(tempPath+fileName));
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* @param v
* @return
* 看看要不要去数据库拿数据
* 要的话就返回对应字段
*/
public String fixedValue(String v) {
return tableConstantPool.contains(v) ? v : null;
}
/**
* @param obj
* @param toSearch
* @return
* @order 遍历获得单元格对象,将obj对象的所有子对象查出来,并且装成一个list返回回去
*
*/
private static List<Object> getAllElementFromObject(Object obj, Class<?> toSearch) {
List<Object> result = new ArrayList<Object>();
if (obj instanceof JAXBElement)
obj = ((JAXBElement<?>) obj).getValue();
if (obj.getClass().equals(toSearch))
result.add(obj);
else if (obj instanceof ContentAccessor) {
List<?> children = ((ContentAccessor) obj).getContent();
for (Object child : children) {
result.addAll(getAllElementFromObject(child, toSearch));
}
}
return result;
}
/**
* @order 获取文档可操作对象,如果不存在就创建,如果存在就打开
* @param docxPath 文档路径
* @return
*/
static WordprocessingMLPackage getWordprocessingMLPackage(String docxPath) {
WordprocessingMLPackage wordMLPackage = null;
if (new File(docxPath).isFile()) {
try {
wordMLPackage = WordprocessingMLPackage.createPackage();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
File file = new File(docxPath);
if (file.isFile()) {
try {
wordMLPackage = WordprocessingMLPackage.load(file);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
return wordMLPackage;
}
}
参考的博客
【docx4j】docx4j操作docx,实现替换内容、转换pdf、html等操作 - QiaoZhi - 博客园 (cnblogs.com)















 2217
2217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









