







前言
最近在学习Java基础知识,LinkedList是Java的一种常见的数据类型,所以我准备针对它做一个笔记,以供自己查阅。笔记将不仅仅局限于LinkedList(基于1.8.0_45),还会对一些Java的知识做一些总结。文章会参照前辈的文章,希望能有所帮助~
概述
在关于Java集合的小抄里是这样描述的:
以双向链表实现。链表无容量限制,但双向链表本身使用了更多空间,每插入一个元素都要构造一个额外的Node对象,也需要额外的链表指针操作。
按下标访问元素-get(i)、set(i,e) 要悲剧的部分遍历链表将指针移动到位 (如果i>数组大小的一半,会从末尾移起)。
插入、删除元素时修改前后节点的指针即可,不再需要复制移动。但还是要部分遍历链表的指针才能移动到下标所指的位置。
只有在链表两头的操作-add()、addFirst()、removeLast()或用iterator()上的remove()倒能省掉指针的移动。
它的定义是
LinkedList is an implementation of {@link List}, backed by a doubly-linked list.
All optional operations including adding, removing, and replacing elements are supported.
All elements are permitted, including null.
中文翻译是:
LinkedList 是List的一个实现,它由双向链表支持。
它支持add,remove和replace操作,并且可以包含null值。
Transient关键字
在LinkedList类一开始,我看到了如下代码:
transient int size = 0;//顺便加一句,这是linkedList的容量,初始化为0在这里就顺便对transient关键字做一个学习。
transient的解释是:Java 语言规范中提到,transient 关键字用来说明指定属性不进行序列化。(当持久化对象时, 可能有一个特殊的对象数据成员, 我们不想用 serialization 机制来保存它。为了在一个特定对象的一个域上关闭serialization, 可以在这个域前加上关键字transient。)
序列化
序列化其实我们在Android上使用过的,它是用来持久化对象的状态。
关于序列化的知识:transient 关键字的作用?
Android中的序列化
Android中的序列化分两种:
- Serializable,要传递的类实现Serializable接口传递对象,
- Parcelable,要传递的类实现Parcelable接口传递对象。
Serializable是Java自带的,而Parcelable是Android加入的。
它们的区别是:Parcelable是将一个完整的对象进行分解,
而分解后的每一部分都是Intent所支持的数据类型。Serializable使用了反射,序列化的过程较慢。Serializable在序列化的时候会产生大量的临时变量,从而引起频繁的GC。Parcelable比Serializable性能高,所以在Android上推荐使用Parcelable(虽然书写稍微麻烦一些)。
上面由一行代码引出了Transient关键字和Android序列化,下面继续对LinkedList进行分析。
Link类
private static final class Link<ET> {
ET data;
Link<ET> previous, next;
Link(ET o, Link<ET> p, Link<ET> n) {
data = o;
previous = p;
next = n;
}
}这里的data指的是用户的数据,previous和next分别指指向前后节点的指针。
构造函数
/**
* Constructs a new empty instance of {@code LinkedList}.
*/
public LinkedList() {
voidLink = new Link<E>(null, null, null);
voidLink.previous = voidLink;
voidLink.next = voidLink;
}
/**
* Constructs a new instance of {@code LinkedList} that holds all of the
* elements contained in the specified {@code collection}. The order of the
* elements in this new {@code LinkedList} will be determined by the
* iteration order of {@code collection}.
*
* @param collection
* the collection of elements to add.
*/
public LinkedList(Collection<? extends E> collection) {
this();
addAll(collection);
}第一个函数就是构建一个header(为voidLink),并且它的previous和next都指向自己本身;第二个函数就是把一个Collection类中的所有元素添加到list中去。addAll函数将在后面进行学习。
add函数
@Override
public void add(int location, E object) {
if (location >= 0 && location <= size) {
Link<E> link = voidLink;//voidLink就是常说的header
if (location < (size / 2)) {//如果插入位置位于前半段
for (int i = 0; i <= location; i++) {
link = link.next;
}
} else {//如果插入位置位于后半段
for (int i = size; i > location; i--) {
link = link.previous;
}
}
//通过上面的操作,找出了插入位置的原元素
Link<E> previous = link.previous;
Link<E> newLink = new Link<E>(object, previous, link);
previous.next = newLink;
link.previous = newLink;//这四行代码,把原来的元素后移一位,前面插入新的数据,并且要把前后的next和previous做相应的修改(不明白的话,依旧可以如底下画图来理解)
size++;
modCount++;
} else {
throw new IndexOutOfBoundsException();
}
}
/**
* Adds the specified object at the end of this {@code LinkedList}.
*
* @param object
* the object to add.
* @return always true
*/
@Override
public boolean add(E object) {
return addLastImpl(object);
}
private boolean addLastImpl(E object) {
Link<E> oldLast = voidLink.previous;//voidLink也就是header
Link<E> newLink = new Link<E>(object, oldLast, voidLink);
voidLink.previous = newLink;
oldLast.next = newLink;
size++;//容量加一
modCount++;
return true;
}在这里还要强调一下LinkedList是一个双向循环的链表。
上面的函数分别是add(E object);add(int location, E object);addLastImpl(E object) 。
add(E object)直接调用了addLastImpl(E object)。在addLastImpl(E object)函数里,把header的previous赋值给oldLast;然后新建一个新的Link对象,其中存放的是用户需要加入的数据,并且它的previous赋值为oldLast,next赋值为voidLink的地址;这个时候,把header的previous赋值为新端点的地址,把oldlast的next端点也赋值成为新端点的地址,那么可以说是插入成功了。因为文字略显晦涩,这里我将用图来解释一下:
因为是笔记,所以我直接使用了自己在草稿纸上画的图:
size为0的时候(初始化):
当size=0的时候,执行如下代码后的结果:
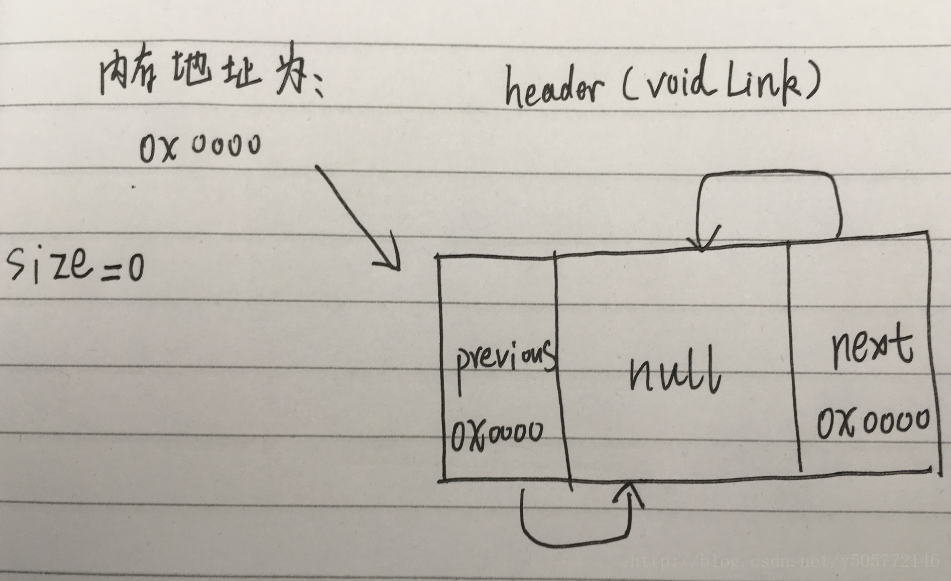
Link<E> oldLast = voidLink.previous;
Link<E> newLink = new Link<E>(object, oldLast, voidLink);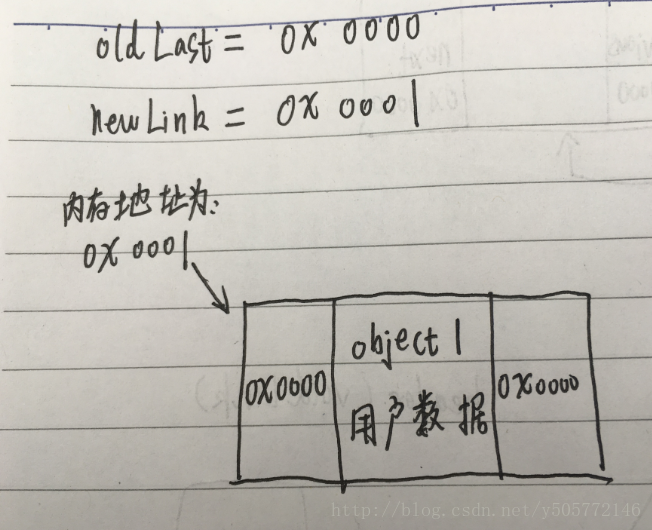
- 继续执行后面两行的代码后:
voidLink.previous = newLink;
oldLast.next = newLink;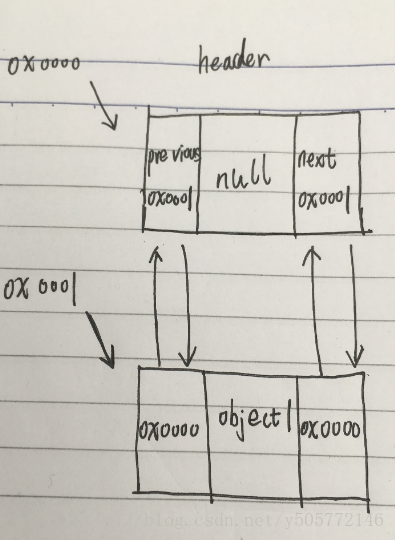
上面两张图指的是size=0到size=1的变化。
- 当size=1到size=2的过程中:
执行如下代码后:
Link<E> oldLast = voidLink.previous;
Link<E> newLink = new Link<E>(object, oldLast, voidLink);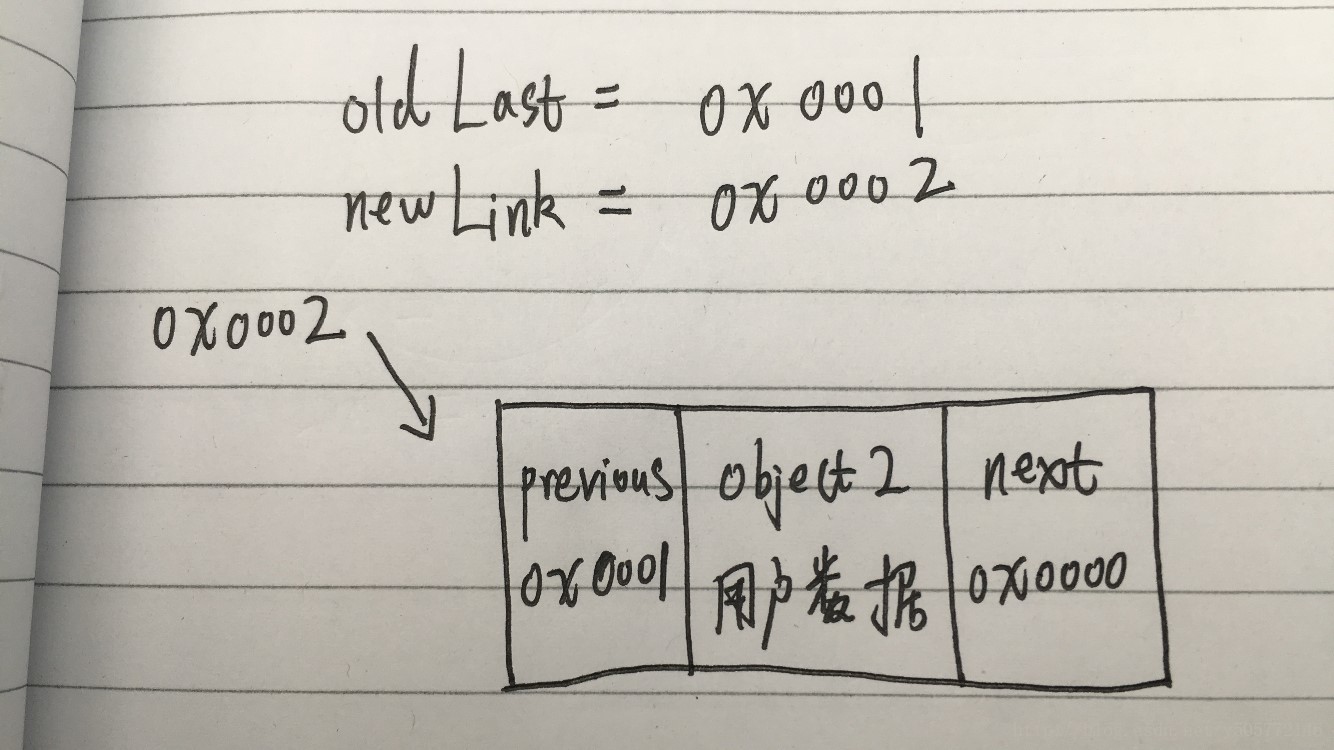
- 接上一个步骤,继续执行如下两行代码后:
voidLink.previous = newLink;
oldLast.next = newLink;就变成了下图:
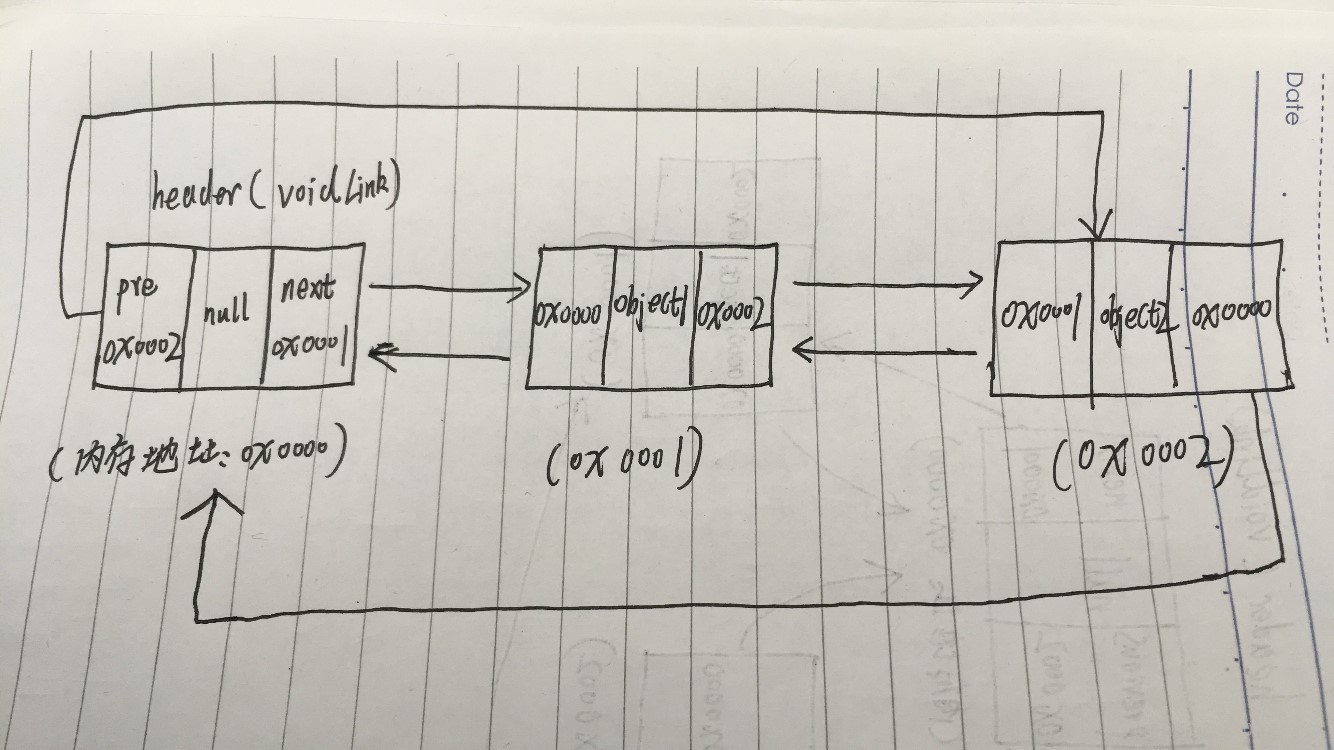
如果继续add的话,应该还是在上图的基础上进行。
add(int location, E object)
然后我们再来看add(int location, E object)函数:
它可以使需要添加的数据插入到链表相应的位置去(在上面的代码中做了相应的注释)。
addAll函数
@Override
public boolean addAll(int location, Collection<? extends E> collection) {
if (location < 0 || location > size) {
throw new IndexOutOfBoundsException();
}
int adding = collection.size();
if (adding == 0) {
return false;
}
Collection<? extends E> elements = (collection == this) ?
new ArrayList<E>(collection) : collection;
Link<E> previous = voidLink;
if (location < (size / 2)) {//同样分情况讨论,看是从前遍历还是从后遍历
for (int i = 0; i < location; i++) {
previous = previous.next;
}
} else {
for (int i = size; i >= location; i--) {
previous = previous.previous;
}
}
Link<E> next = previous.next;
for (E e : elements) {
Link<E> newLink = new Link<E>(e, previous, null);
previous.next = newLink;
previous = newLink;
}
previous.next = next;
next.previous = previous;
size += adding;
modCount++;
return true;
}
@Override
public boolean addAll(Collection<? extends E> collection) {
int adding = collection.size();
if (adding == 0) {
return false;
}
Collection<? extends E> elements = (collection == this) ?
new ArrayList<E>(collection) : collection;//如果collection是当前linkedList对象,那么就新建一个Arraylist,否则elements就赋值为collection。
Link<E> previous = voidLink.previous;//赋值为header的previous,previous的值为linkedList的最后一个元素
for (E e : elements) {
Link<E> newLink = new Link<E>(e, previous, null);
previous.next = newLink;
previous = newLink;//在这个循环里,依次把元素添加在linkedList的末尾。
}
previous.next = voidLink;//把最后一个元素的next指向头部的header。
voidLink.previous = previous;//把header的previous指向最后一个元素。这两行构成了新的循环(如之前的图示)。
size += adding;
modCount++;
return true;
}在当前类中重载了两个addAll函数。其中第二个函数同样在构造函数中被调用(如上)。
在上面的代码中做了相应的注释。
set函数
public E set(int location, E object) {
if (location >= 0 && location < size) {
Link<E> link = voidLink;
if (location < (size / 2)) {
for (int i = 0; i <= location; i++) {
link = link.next;
}
} else {
for (int i = size; i > location; i--) {
link = link.previous;
}
}
E result = link.data;
link.data = object;
return result;
}
throw new IndexOutOfBoundsException();
}从代码可以看出,set的时候,同样是分情况讨论的,分为从前遍历和从后遍历两种情况。在set的值,需要对linkedList进行遍历。
get函数
public E get(int location) {
if (location >= 0 && location < size) {
Link<E> link = voidLink;
if (location < (size / 2)) {
for (int i = 0; i <= location; i++) {
link = link.next;
}
} else {
for (int i = size; i > location; i--) {
link = link.previous;
}
}
return link.data;
}
throw new IndexOutOfBoundsException();
}get的基本逻辑其实和set很相似。也是进行遍历,然后取值。
remove
public E remove() {
return removeFirstImpl();
}
public E remove(int location) {
if (location >= 0 && location < size) {
Link<E> link = voidLink;
if (location < (size / 2)) {//这个if else代码块在当前类经常被使用到,找出相应location的元素
for (int i = 0; i <= location; i++) {
link = link.next;
}
} else {
for (int i = size; i > location; i--) {
link = link.previous;
}
}
Link<E> previous = link.previous;
Link<E> next = link.next;
previous.next = next;
next.previous = previous;//改变当前location元素的指针指向关系,从而把该元素移出LinkedList
size--;
modCount++;
return link.data;
}
throw new IndexOutOfBoundsException();
}
@Override
public boolean remove(Object object) {
return removeFirstOccurrenceImpl(object);
}从代码可以看出,remove 函数有三个。
第一个remove是不带参数的,它直接调用了removeFirstImpl()函数。
private E removeFirstImpl() {
Link<E> first = voidLink.next;//header的next,当size=0时,next指向header自己;当size>0的时候,next指向LinkedList的第一个元素。
if (first != voidLink) {//size>0时
Link<E> next = first.next;//next赋值为第一个元素的next值,也就是第二个元素(ps:当size=1时,又指向它本身)
voidLink.next = next;//header的next赋值为上面的值
next.previous = voidLink;//第二个元素(或当size=1时,就是header本身)的previous由指向first变为指向header。
//经过上面的操作,把LinkedList的第一个元素移除了。
size--;
modCount++;
return first.data;
}
throw new NoSuchElementException();
}所以remove函数在当前类的作用应该是移除LinkedList的第一个元素。
第二个函数见注释。
第三个函数的参数是object元素,而不是索引。通过代码,它直接调用了removeFirstOccurrenceImpl(object)函数:
private boolean removeFirstOccurrenceImpl(Object o) {
Iterator<E> iter = new LinkIterator<E>(this, 0);//LinkIterator迭代器
return removeOneOccurrence(o, iter);
}
private boolean removeOneOccurrence(Object o, Iterator<E> iter) {
while (iter.hasNext()) {//是否存在下一个元素
E element = iter.next();
if (o == null ? element == null : o.equals(element)) {//如果删除的元素是null,如果有元素的值也为null,那么进行remove操作;如果o不是null,就调用equals比较。
iter.remove();
return true;
}
}
return false;
}它借助了迭代器去完成remove操作。迭代器就不再在这里赘述了,它的定义也在LinkedList.java类中。
clear函数
public void clear() {
if (size > 0) {
size = 0;//将size容量置为0
voidLink.next = voidLink;//next指向自己内存地址
voidLink.previous = voidLink;//previous指向自己内存地址
//这里是不是做一个=null操作更好呢?
modCount++;
}
}contains函数
@Override
public boolean contains(Object object) {
Link<E> link = voidLink.next;//voidLink就是header,指向第一个有效元素(size=0的时候,指向自己)
if (object != null) {
while (link != voidLink) {//从头到尾循环一次,到末节点指向自己为止
if (object.equals(link.data)) {
return true;
}
link = link.next;
}
} else {
while (link != voidLink) {
if (link.data == null) {//遍历到第一个元素为null即可
return true;
}
link = link.next;
}
}
return false;
}后面的一些函数应该不是很常用,后面有时间的话会继续更新。
与ArrayList的比较
LinkedList 和 ArrayList 都实现了 List 接口。LinkedList 是基于链表实现的,所以它的插入和删除操作比 ArrayList 更加高效。但其随机访问的效率要比 ArrayList 差。
总结
其实根据每个Java版本实现代码都会有略微不同,如果可以的话,大家应该可以自己实现一个linkedList。所以对LinkedList的学习应该是知道LinkedList的数据结构是双向链表,其余的具体实现都是围绕这个循环的双向链表进行的。















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









