






目录
最近在做PowerBI项目,遇到有客户要求不允许使用"合并查询"功能去改变表结构,但是又需要合并查询的情况。
比如我们有两张表:
【销量】
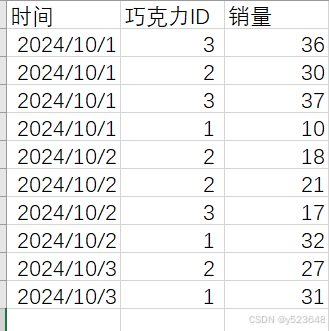
【巧克力】

客户要求在一个矩阵/表格里显示销售数据。
具有相同列名
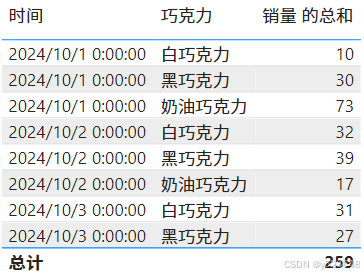
因为两张表有相同的列名【巧克力ID】,所以直接使用NATURALLEFTOUTERJOIN()函数就可以解决。(同类型的函数还有NATURALINNERJOIN(),可以查阅微软的文档NATURALINNERJOIN 函数 (DAX) - DAX | Microsoft Learn)
DAX代码:
表 = SELECTCOLUMNS(
NATURALLEFTOUTERJOIN('销量','巧克力'),
"时间",[时间],
"巧克力",[巧克力名称],
"销量",[销量]
)效果:
列名在关联表里不相同
但是NATURALLEFTOUTERJOIN()函数有一个限制条件是:需要关联表具有相同的列名,而实际情况是,列名可能在两张表里是不同的。
比如,巧克力表里,“巧克力ID”就叫“ID”,这样就无法使用NATURALLEFTOUTERJOIN()函数。
(为了以示区分,我们暂且叫它【巧克力(不同列名)】表)
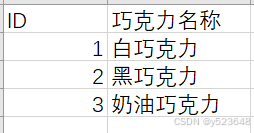
这种情况,我们可以使用CROSSJOIN()函数,先获取两张表的笛卡尔乘积数据:
表_不同列 = CROSSJOIN('销量','巧克力(不同列名)') 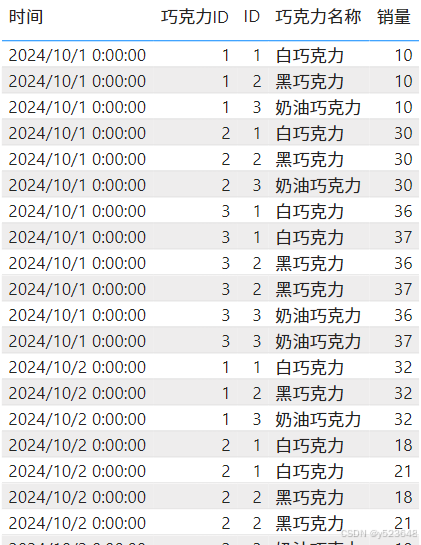
我们仔细观察,它和第一种情况的结果,其不同之处,仅仅只是多包含了 [巧克力ID] 不等于 [ID]的数据行:
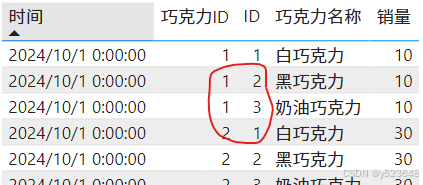
那么我们只需要提取 [巧克力ID] = [ID]的数据行就解决了:
表_不同列 =
SELECTCOLUMNS(FILTER(CROSSJOIN('销量','巧克力(不同列名)'),'巧克力(不同列名)'[ID] = '销量'[巧克力ID]),
"时间",[时间],
"巧克力",[巧克力名称],
"销量",[销量]
)效果:
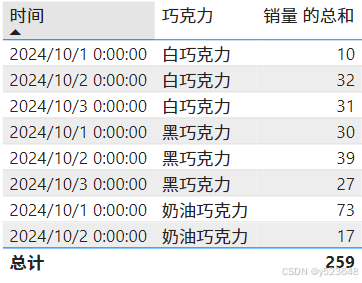
需要注意,CROSSJOIN()函数要求两表不能有相同的列,否则会报错,可以使用SELECTCOLUMNS()函数,对其中一个表的列进行重命名后再CROSSJOIN
和它类似的还有GENERATEALL()
接下来,我们再增加一个表,看是否能继续JOIN:
我们为每款巧克力,添加一个官方的评价表吧:
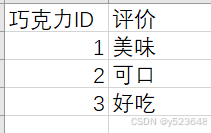
接着,修改 [表] 和 [表_不同列],让它们能显示巧克力的ID:
表 = SELECTCOLUMNS(
NATURALLEFTOUTERJOIN('销量','巧克力'),
"时间",[时间],
"巧克力ID",'销量'[巧克力ID],
"巧克力",[巧克力名称],
"销量",[销量]
)
表_不同列 = SELECTCOLUMNS(
FILTER(
CROSSJOIN('销量','巧克力(不同列名)'),
'巧克力(不同列名)'[ID] = '销量'[巧克力ID]
),
"时间",[时间],
"ID",[巧克力ID],
"巧克力",[巧克力名称],
"销量",[销量]
)再添加一个计算表,JOIN查询[评价]表
表2 = SELECTCOLUMNS(
NATURALLEFTOUTERJOIN('表','评价'),
"时间",[时间],
"销量",[销量],
"巧克力ID",'表'[巧克力ID],
"巧克力",[巧克力],
"评价",[评价]
)会发现提示错误:

[表] 和 [评价]表 都有相同的column [巧克力ID],为什么无法使用NATURALLEFTOUTERJOIN()函数呢。

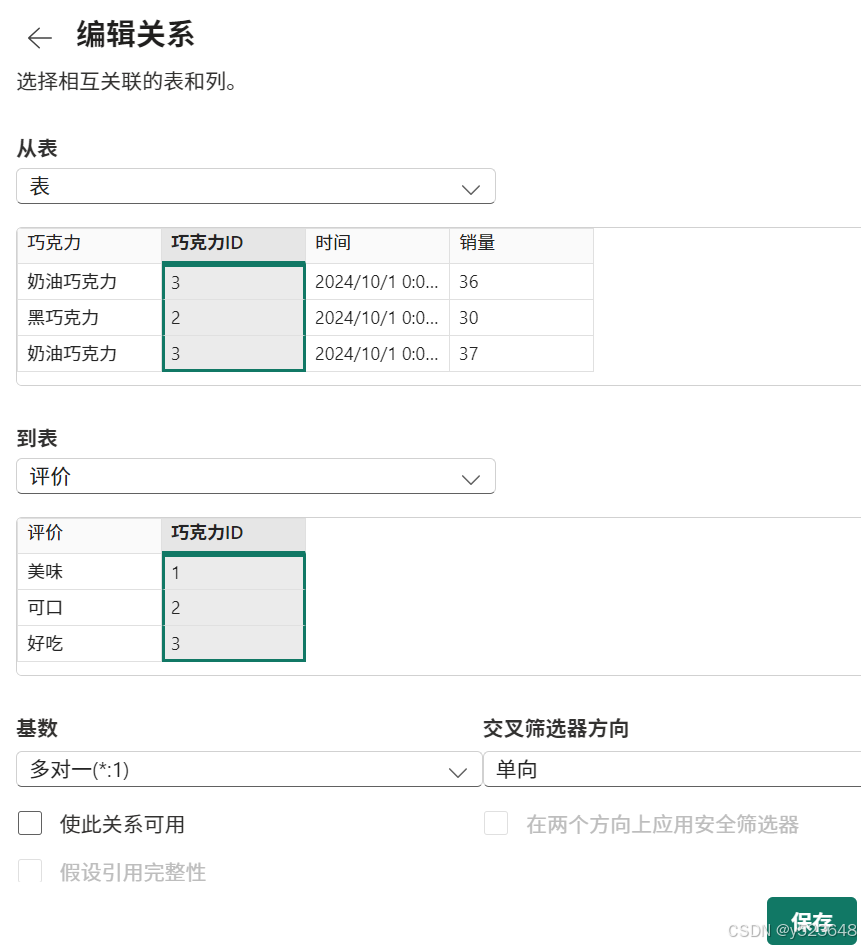
解决方法是:右键任意一个表,然后选择"管理关系"。
手动给两张表建立一个关联关系即可:


而使用CROSSJOIN()就不会遇到这种问题,因为它不需要指定关联列
表_不同列2 = SELECTCOLUMNS(
FILTER(CROSSJOIN('表_不同列','评价'),[巧克力ID]=[ID]),
"时间",[时间],
"巧克力",[巧克力],
"销量",[销量],
"评价",[评价]
)更好的解决方案
无论是NATURALLEFTOUTERJOIN(),或者是CROSSJOIN()函数,它们都只能对应特定的情境,而且写起来也非常繁琐,一旦关联表的数量较多,列名增多,会大大降低效率。
这里还有一个更简单的方法。
以 [销量]表 为例,我们想要的,无非就是把 [巧克力ID] 换成 [巧克力名称] 而已,那么我们直接用ADDCOLUMNS()函数,把名称添加进去不就解决了?
首先,我们给表之间建立好关系:

接着,把 [巧克力名称] 添加到 [销量]表里,就OK了:
表 = ADDCOLUMNS('销量',
"巧克力",SELECTCOLUMNS(
RELATEDTABLE('巧克力'),"巧克力",[巧克力名称])
)
表_不同列名 = ADDCOLUMNS('销量',
"巧克力",SELECTCOLUMNS(
RELATEDTABLE('巧克力(不同列名)'),"巧克力",[巧克力名称])
)这种方式的另一个好处,是可以应对关联表较多的情况,比如我们再关联上 [评价]表:
表 = ADDCOLUMNS('销量',
"巧克力",SELECTCOLUMNS(
RELATEDTABLE('巧克力'),"巧克力",[巧克力名称]),
"评价", SELECTCOLUMNS(
RELATEDTABLE('评价'),"评价",[评价])
)
表_不同列名 = ADDCOLUMNS('销量',
"巧克力",SELECTCOLUMNS(
RELATEDTABLE('巧克力(不同列名)'),"巧克力",[巧克力名称]),
"评价", SELECTCOLUMNS(
RELATEDTABLE('评价'),"评价",[评价])
)所以简单的总结一下:
NATURALLEFTOUTERJOIN() --->适合两张表的关联列名称相同
CROSSJOIN() ---> 适合两张表有不同的列名,无论有无关联,通过FILTER()确定关联。如果有相同列名,也可以使用SELECTCOLUMNS重命名列名后再使用。或者使用LOOKUPVALUE()函数,但是性能不太好。
RELATEDTABLE() ---> 无论列名,只要两张,或多张表有正确的关联关系,就能使用
如果客户没有非要合并到一张表查询的需求,就只需要建立表之间的关联关系即可,组件是可以引用多个表的字段,筛选也会自动应用到所有有关系的表的字段上,包括度量值。
但是要注意,如果多表间存在一对多,多对多等复杂关联关系,表数量一旦多起来,及有可能造成数据统计不正确。所以,掌握合并多表的技能是很重要的。

















 3176
3176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









