









此文是斯坦福大学,机器学习界 superstar — Andrew Ng 所开设的 Coursera 课程:Machine Learning 的课程笔记。力求简洁,仅代表本人观点,不足之处希望大家探讨。
课程网址:https://www.coursera.org/learn/machine-learning/home/welcome
Week 8 前半部分 K-Means:http://blog.csdn.net/ironyoung/article/details/49029523
Week 8:Unsupervised Learning & Dimensionality Reduction
Unsupervised Learning(见前半部分)
K-Means Algorithm(见前半部分)
Motivation for Dimensionality Reduction
- 为什么要数据降维?目的性一般来说有三个:(1)加速计算,要计算的维度更少;(2)节省空间;(3)可视化,因为现在的可视化只能对于2D或者3D有较好的处理。
- 那么,数据为什么可以降维呢?举个例子,我用一幅图表示厘米与英尺的关系,这时特征有(厘米,英尺)。但其实我存储的时候,只需要其中任意一个,另外一个是极强相关度。此时只有一维特征。
Principal Component Analysis (PCA) 简介
- 主成分分析(Principal Component Analysis)是数据降维的一种极为有效的方法。通过将高维数据投影到低维空间,以求通过牺牲极少的数据精度来换取更低维度的数据。
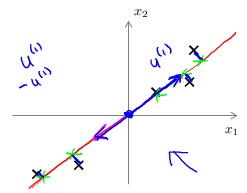
- 先来举个例子,例如下图中的5个点:
如果精确描述这5个点,那么需要2D的特征 (x 1 ,x 2 ) 。但是,如果我们以图中的直线作为唯一的1D特征,将每个点投影到直线上,是不是基本可以区分出这5个点?这肯定丧失了一部分精度。注意:此时的特征正方向(1D空间的基向量),方向沿着直线的任意两方都正确,我们关心的只是直线而不是方向。 - 上图的例子中,PCA的任务就是找到这条直线,然后投影到直线上去。而这条直线,必须满足每个点到直线欧氏距离的平方和最小,即丧失的精度最少: min∑ m i=1 d 2 i .
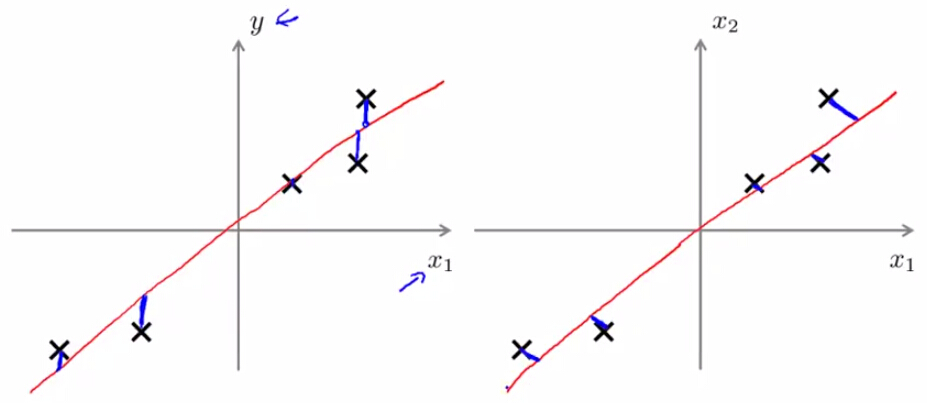
- 既然都是找直线,那肯定有人自然而然想到了线性回归。但是两者之间有着极大不同。首先就是优化目标,见下图:
左图是线性回归所需要最小化的距离(蓝色线段和),右图是2D空间PCA所需要最小化的距离(蓝色线段和)。除此之外,线性回归是为了拟合特殊的变量 y ,而PCA是一种无监督学习,目的性并不明确,每个变量都会降维。
Principal Component Analysis (PCA) 流程
- 述说流程之前,希望大家可以看看这篇分析(本课程缺少理论分析):http://sebastianraschka.com/Articles/2014_kernel_pca.html
- 老规矩,首先要 mean normalization / feature scaling。方法就跟之前课程提到的一样,对每个特征
j 求均值 μ j =1m ∑ m i=1 x (i) j ,然后更新特征的值 x j =(x j −μ j )/S j 。其中 S j 是特征值的范围,可以是最大值减去最小值。 - 计算协方差矩阵: sigma=1m ∑ n i=1 (x (i) )(x (i) ) T ,协方差矩阵一般是对称正定矩阵,一定会求出特征值与特征向量。
- 计算特征值与特征向量,matlab中写作:
[U, S, V] = svd(simga). U 是特征向量集合, U=[u (1) ,u (2) ,...,u (k) ,...,u (n) ] ,S是特征值集合S=⎛ ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ s 11 ⋮⋮0 …s 22 … …⋱… 0⋮⋮s nn ⎞ ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ -
U∈R n×n
,降维之后取
U
的前
k 个特征向量 u (1) ,u (2) ...u (k) 作为子空间的基向量,构造 U reduce =[μ 1 ,μ 2 ,...,μ k ]∈R n×k 。此时 x∈R n →z∈R k
z=U T reduce x
其中 z 是k×1 的列向量, x 是n×1 的列向量, U T reduce 是 k×n 的矩阵 - 降维之后,进行计算获得结果之后,总是需要升维到原空间中。这个时候的升维精确度已经有所下降,但已经是尽量减少损耗。具体的降维转换公式为
x approx =U reduce z
也就是下图中的绿色交叉点返回到2D坐标系中表示。
Principal Component Analysis (PCA) 其他问题
- OK,知道怎么使用PCA,那么我们应该选择降维
k=?
我们应该有评判标准。我们大体目标是
min(1m ∑ m i=1 ||x (i) −x (i) approx || 2 )
,因此我们选择标准为:
1m ∑ m i=1 ||x (i) −x (i) approx || 2 1m ∑ m i=1 ||x (i) || 2 ≤1% ,表示意义为“保留99%的差异性”。
如果使用特征值来表示就是, 1−(∑ k i=1 s ii )/(∑ n i=1 s ii )≤1% - PCA 中,无监督学习的唯一学习参数是 U reduce 。Only Training Data!仅仅是由训练集训练出来的参数。可以用Cross-Validation data 和 test Data进行检验,但是选择主分量的时候只应用training data。
- 有时候 PCA 被用于解决 overfitting ,但这样做其实非常不好。PCA 降低了数据维度,但同时损失了数据原有的标记信息。而之前的课程中提到的regularization 技术才是解决过拟合的正途。
- 使用 PCA 之前,一定要利用原维度的数据进行计算。仅仅当计算过程出现了(1)计算过慢;(2)占用内存过多;这两个问题之后,才应该考虑 PCA。盲目的使用,是不可取的。
- OK,知道怎么使用PCA,那么我们应该选择降维
k=?
我们应该有评判标准。我们大体目标是
min(1m ∑ m i=1 ||x (i) −x (i) approx || 2 )
,因此我们选择标准为:















 2150
2150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









