







 本文是Andrew Ng的Coursera机器学习课程笔记,详细介绍了无监督学习中的K-Means算法。K-Means通过迭代找到样本的最佳分类,优化目标是最小化聚类误差平方和。文章还讨论了初始化方法、如何选择聚类数量以及可能的局部最优问题。
本文是Andrew Ng的Coursera机器学习课程笔记,详细介绍了无监督学习中的K-Means算法。K-Means通过迭代找到样本的最佳分类,优化目标是最小化聚类误差平方和。文章还讨论了初始化方法、如何选择聚类数量以及可能的局部最优问题。
此文是斯坦福大学,机器学习界 superstar — Andrew Ng 所开设的 Coursera 课程:Machine Learning 的课程笔记。力求简洁,仅代表本人观点,不足之处希望大家探讨。
课程网址:https://www.coursera.org/learn/machine-learning/home/welcome
Week 8 后半部分PCA:http://blog.csdn.net/ironyoung/article/details/49154327
Week 8:Unsupervised Learning & Dimensionality Reduction
Unsupervised Learning
- 之前课程中说到的学习,都是监督学习,即有一个label,明确告诉你这个样本,属于哪个类型,或者导致的值是多少。但是,如果我碰到没有label,或者我也不知道label是怎样的情况,但是我还是想要分成若干类。这样的问题,就是一种无监督问题。
- 聚类(clustering)
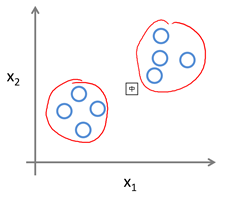
聚类是一种典型的无监督学习例子,但是聚类不等同于无监督学习,密度估计同样是一个典型的无监督学习例子。回到聚类,例如有下图:
每种样本(蓝色圆圈)都没有label指定类别,但是人眼一看就知道分成两类比较合适。如何让机器也知道如何分类呢?这就是聚类问题。
K-Means Algorithm
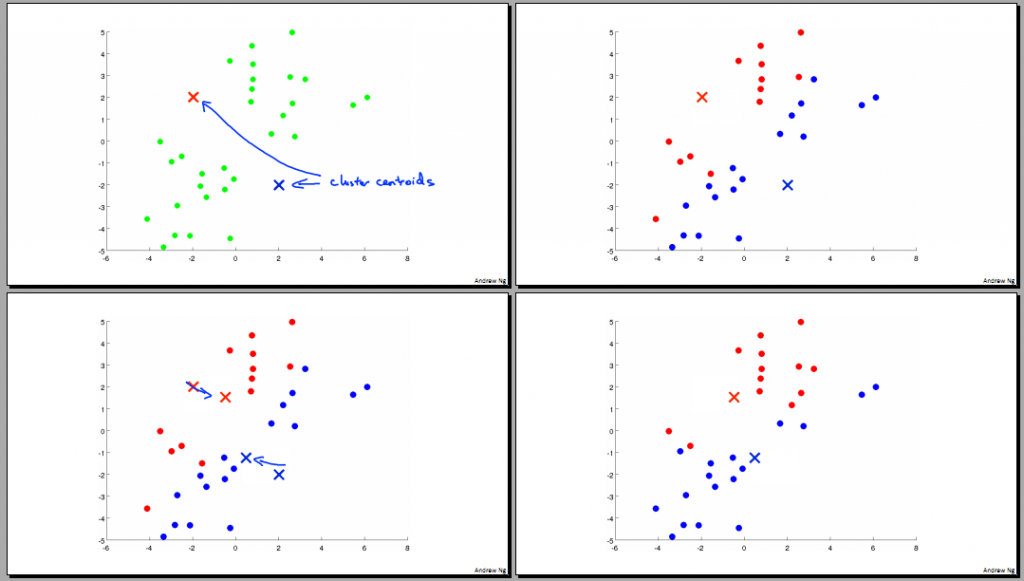
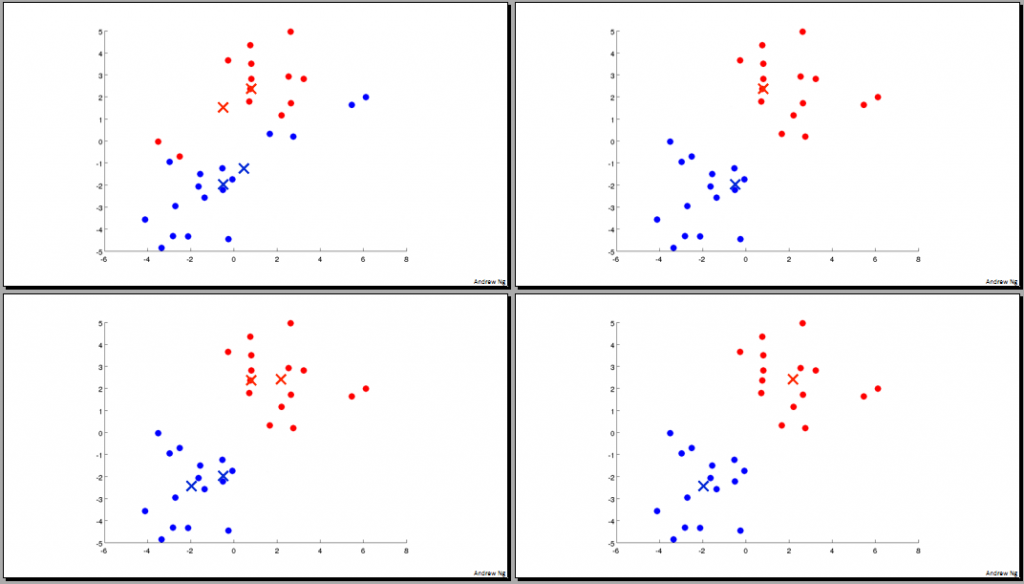
K-Means 算法是解决无监督学习的有效算法之一。K(大写)表示将样本分为K个类型。算法具体的过程通俗易懂,如下图所示:
配合上图,再作一些简单的解释:- 随机找到 K 个点,作为聚类中心(centroids) μ 1 ,μ 2 ,...,μ K
- 进行聚类的主要两个步骤:
- 簇分配:遍历每个样本点 x 1 ,x 2 ,...,x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1630
1630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









