







更新语句的基本流程

- 更新数据前 会把数据写入uodo 日志文件
- 更新数据后 会把数据写入redo缓冲池,这意味着这个缓冲池落地磁盘,跟事务有关系,可以通过
innodb_flush_log_at_trx_commit配置。 - 当参数是1时,就是必须把redo log写入磁盘才能提交事务。0 的时候就是不会有redo日志、2 的时候是先写oscache 这两种都有丢失数据的风险
- buffer pool就是我们一直在操作的数据的缓冲区。
- redo log 文件里面也是一块一块追加在一起的
Redo Log
redo日志会把事务在执行过程中对数据库所做的所有修改都记录下来,在之后系统奔溃重启后可以把事务所做的任何修改都恢复出来
一个事务可能包含很多语句,即使是一条语句也可能修改许多页面,倒霉催的是该事务修改的这些页面可能并不相邻,这就意味着在将某个事务修改的BufferPool中的页面刷新到磁盘时,需要进行很多的随机IO,随机IO比顺序IO要慢。
我们只是想让已经提交了的事务对数据库中数据所做的修改永久生效,即使后来系统崩溃,在重启后也能把这种修改恢复出来。所以,只需要把修改了哪些东西记录一下就好,比方说某个事务将系统表空间中的第100号页面中偏移量为1000处的那个字节的值1改成2我们只需要记录一下:
redo日志是顺序写入磁盘的,所以相对随机写入性能肯定更好。
InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,那么这块“粉板”总共就可以记录4GB的操作。从头开始写,写到末尾就又回到开头循环写
`innodb_log_group_home_dir`:该参数指定了redo日志文件所在的目录,默认值就是当前的数据目录。
`innodb_log_file_size`该参数指定了每个redo日志文件的大小,在MySQL 5.7.21这个版本中的默认值为48MB,
`innodb_log_files_in_group`该参数指定redo日志文件的个数,默认值为2,最大值为100。
## 如果是现在常见的几个TB的磁盘的话,就不要太小气了,直接将redo log设置为4个文件、每个文件1GB吧
写入过程
语句在执行过程中可能修改若干个页面。还会更新聚簇索引和二级索引对应B+树中的页面。由于对这些页面的更改都发生在Buffer Pool中,所以在修改完页面之后,需要记录一下相应的redo日志。写入的时候会被分成组提交。
log buffer
这些redo日志是一个不可分割的组,所以其实并不是每生成一条redo日志,就将其插入到logbuffer中,而是每个组运行过程中产生的日志先暂时存到一个地方,当该组结束的时候,将过程中产生的一组redo日志再全部复制到log buffer中。而写入 log buffer 也是顺序写。
当log buffer空间不足时、事务提交时、后台线程大约每秒刷新log buffer中的redo日志到磁盘、正常关闭服务器时、刷flush链表时:这些都会让log buffer 强制写磁盘。并且最后会把执行过程中可能修改过的页面加入到Buffer Pool的flush链表
写入时机
为了控制redo log的写入策略,InnoDB提供了innodb_flush_log_at_trx_commit参数,它有三种可能取值
- 设置为0的时候,表示每次事务提交时都只是把redo log留在redo log buffer中;
- 设置为1的时候,表示每次事务提交时都将redo log直接持久化到磁盘;
- 设置为2的时候,表示每次事务提交时都只是把redo log写到page cache。
InnoDB有一个后台线程,每隔1秒,就会把redo log buffer中的日志,调用write写到文件系统的page cache,然后调用
fsync持久化到磁盘。
Undo log
每当我们做了修改数据的操作时,我们需要有回滚操作,undo log 就是保证回滚这一操作的日志,把回滚时所需的东
西都给记下来,要注意的是undo log 日志是维护事务版本链的重要东西。
Insert日志
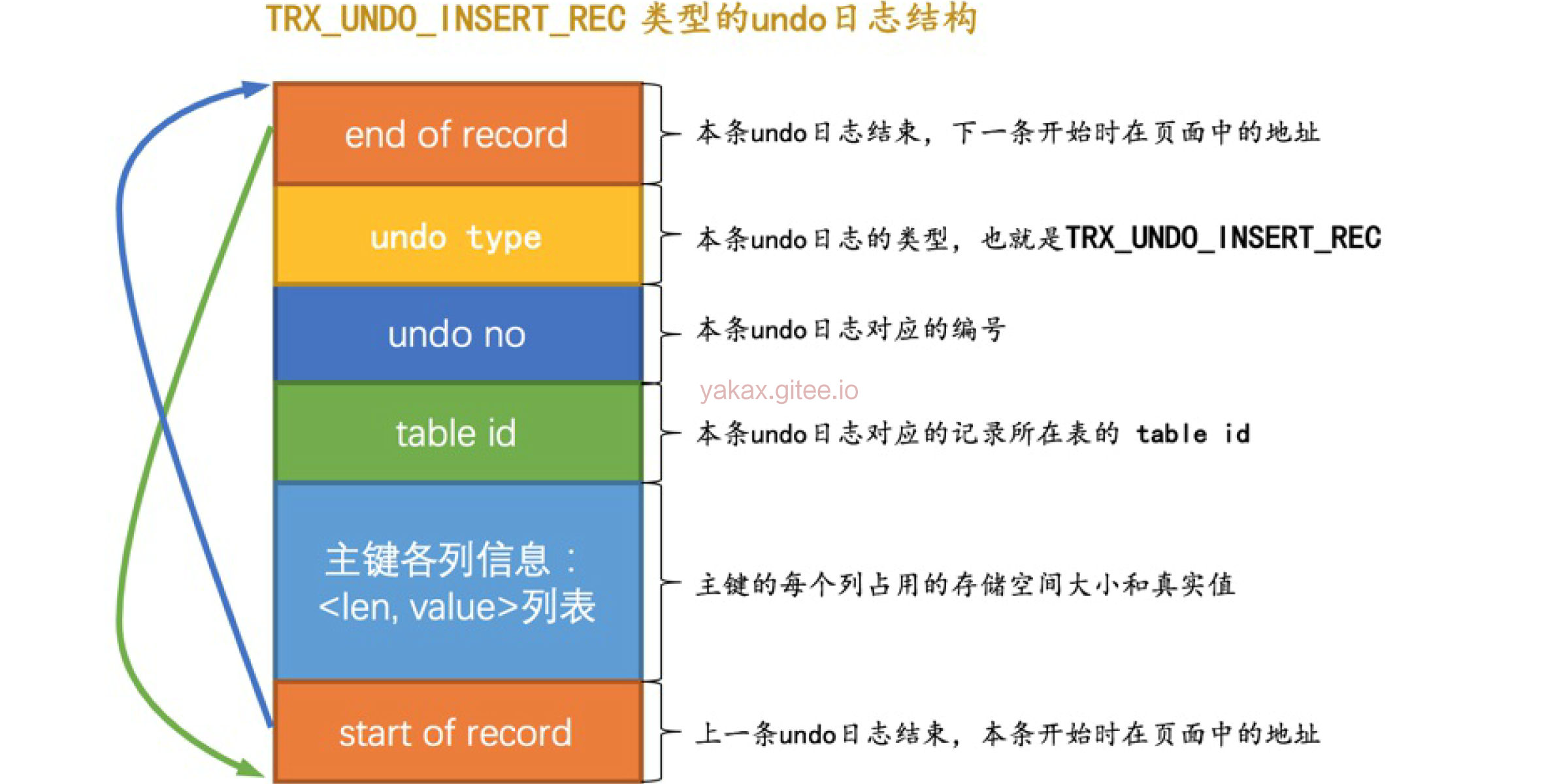
主要就是记录了新增数据的信息而已。 会发现自增id的申请在这之前,所以回滚了。自增id也不会回滚
undo no 是在事务的版本链里面会用到。
delete日志
删除数据是没有真正删除,在删除的过程中有中间状态,不过事务提交后。后台会有线程把删除状态的数据加入到链表头部。
删除链表的数据的空间是会被新插入的数据利用的,但是如果不够用,或者用不了。就会出现页合并的情况。
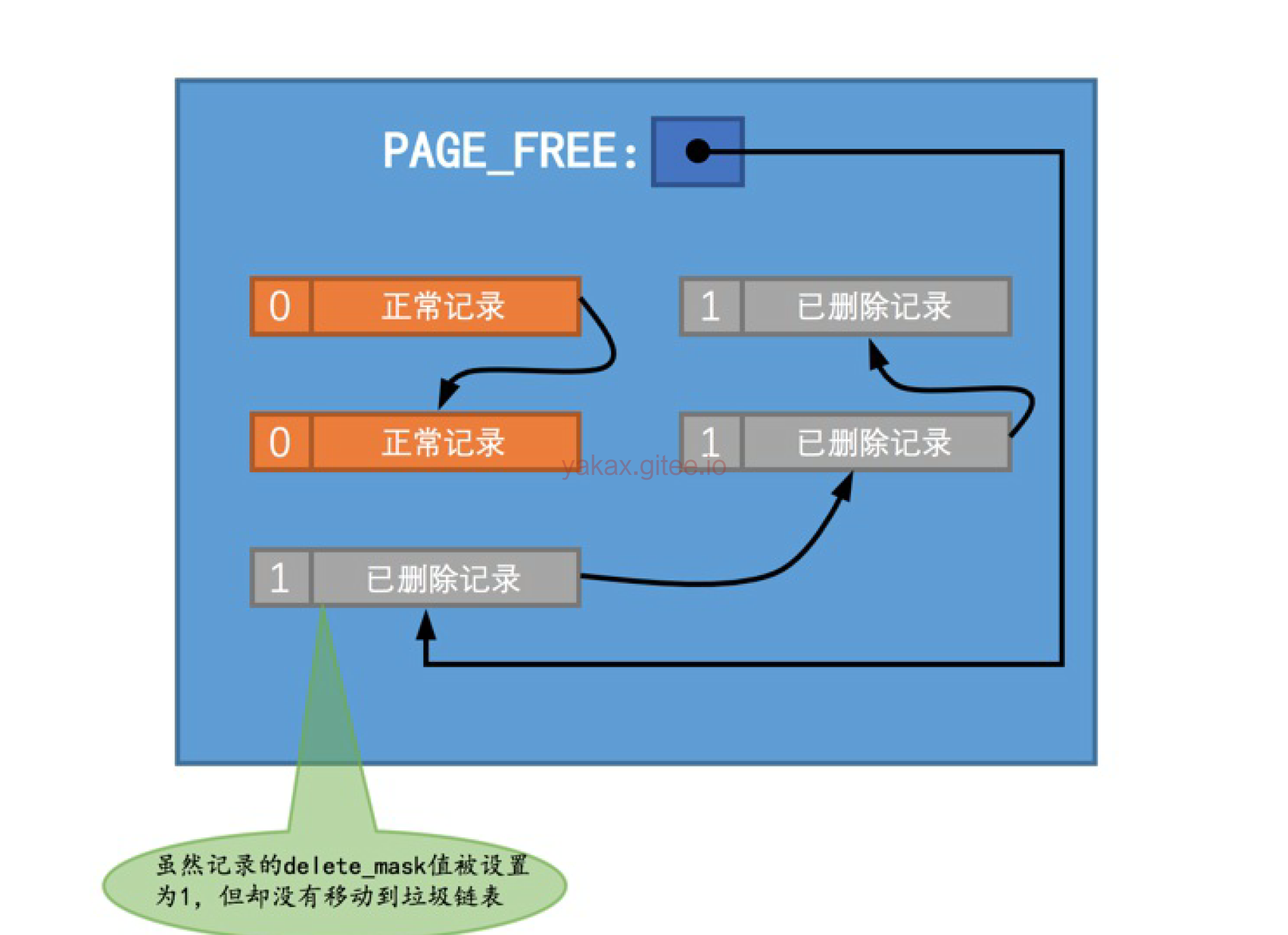
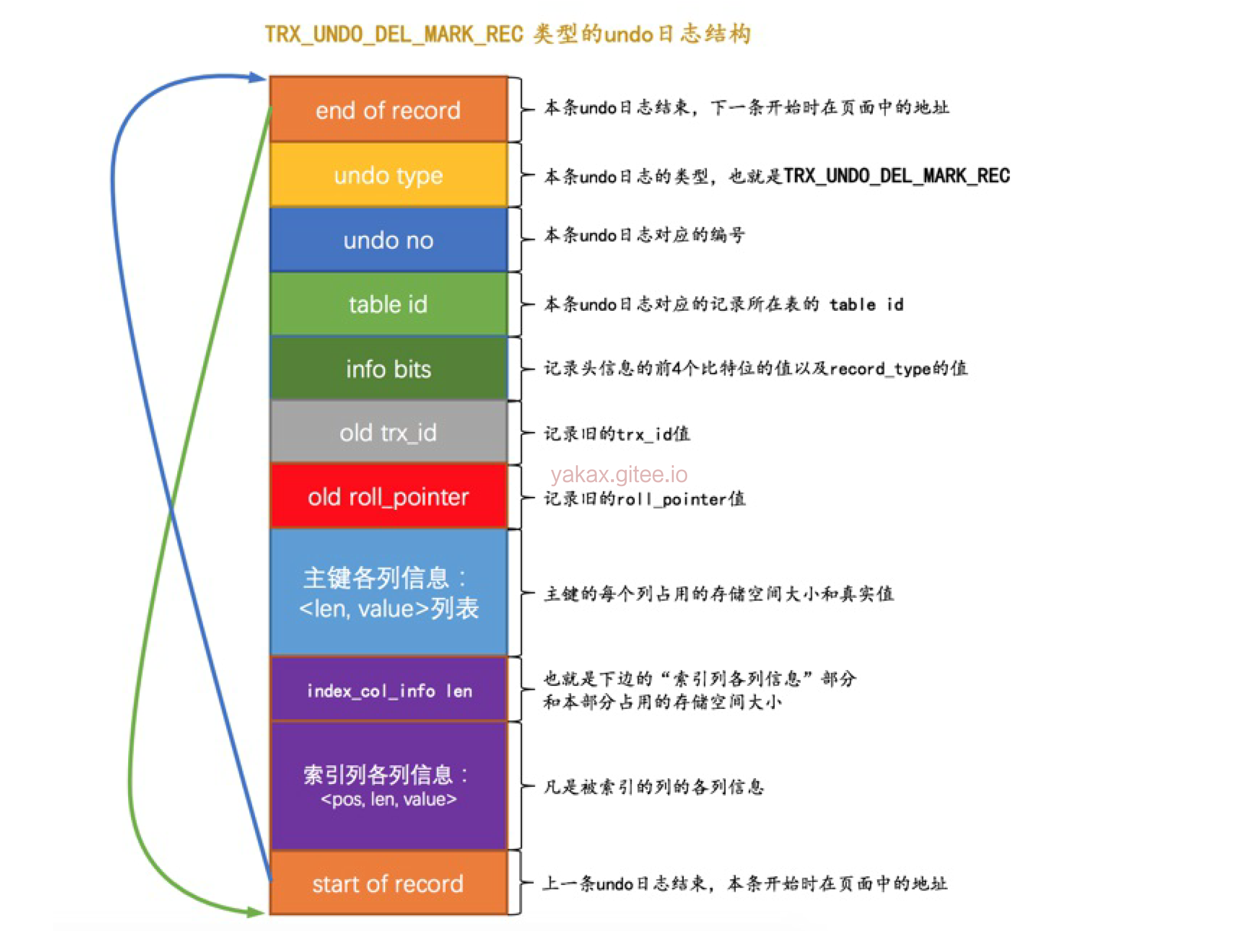
在删除语句所在的事务提交之前,只会经历标记数据阶段,也就是delete mark阶段(提交之后我们就不用回滚了,所以只需考虑对
删除操作的标记影响进行回滚)。
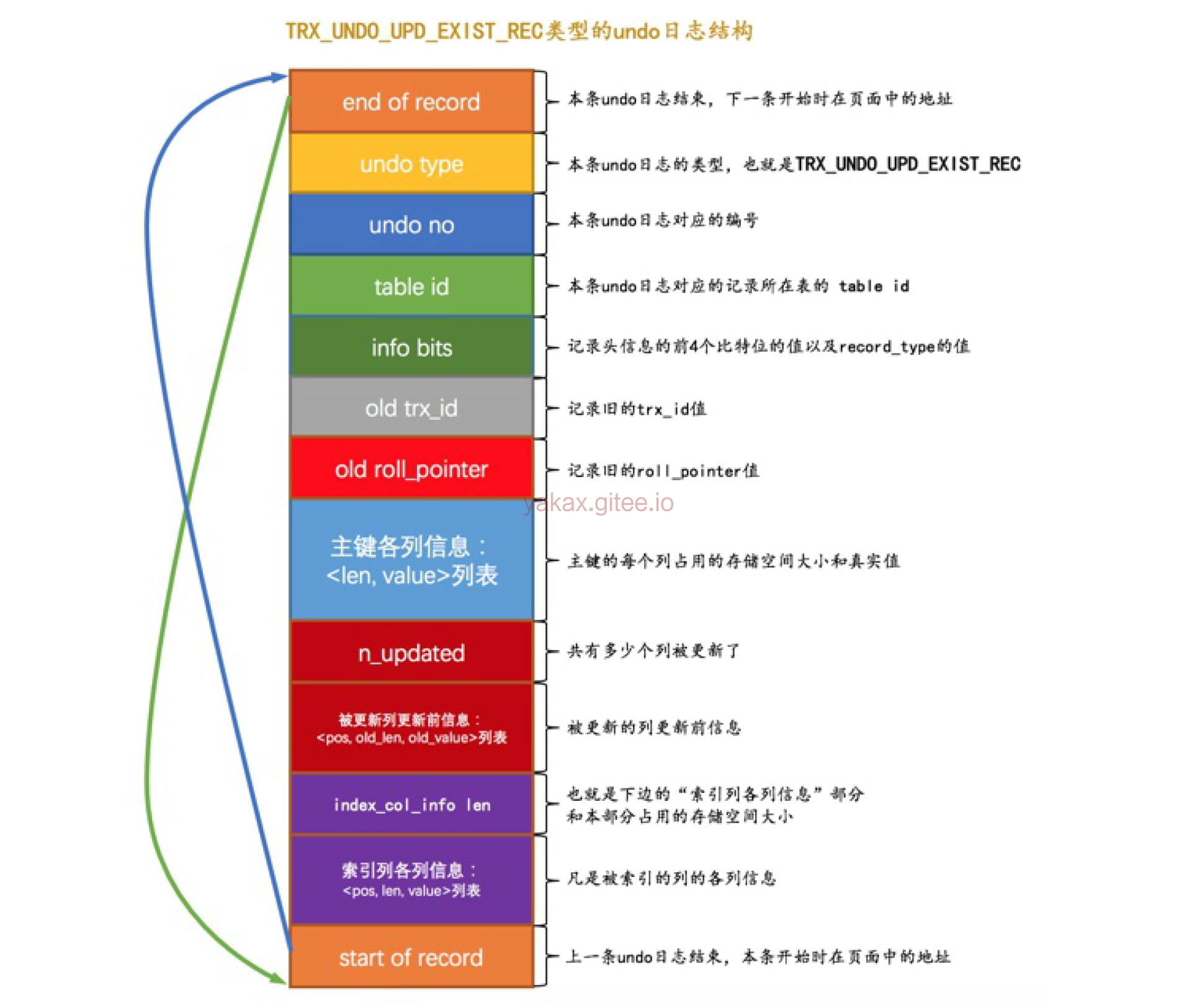
update日志
不更新主键
在不更新主键的情况下,undo log日志会直接记录更新前的数据在日志里(UPDATE语句更新的列大小都没有改动,所以可以采用就地更新的方式),把老数据真的删除,插入更新后的数据。
更新主键的情况
在聚簇索引中,记录是按照主键值的大小连成了一个单向链表的,如果我们更新了某条记录的主键值,意味着这条记录在聚簇索引中的位置将会发生改变,比如你将记录的主键值从1更新为10000,如果还有非常多的记录的主键值分布在1 ~ 10000之间的话,那么这两条记录在聚簇索引中就有可能离得非常远,甚至中间隔了好多个页面。针对UPDATE语句中更新了记录主键值的这种情况,InnoDB在聚簇索引中分了两步处理
-
将旧记录进行delete mark操作
之所以只对旧记录做delete mark操作,是因为别的事务同时也可能访问这条记录,如果把它真正的删除加入到垃圾链表后,别的事务就访问不到了。这个功能就是所谓的MVCC。数据在事务提交后才由专门的线程做purge操作,把它加入到垃圾链表中。
-
根据更新后各列的值创建一条新记录,并将其插入到聚簇索引中(需重新定位插入的位置)。
针对UPDATE语句更新记录主键值的这种情况,在对该记录进行delete mark操作前,会记录一条类型delete的undo日志;之后插入新记录时,会记录一条类型为insert的undo日志,也就是说每对一条记录的主键值做改动时,会记录2条undo日志。
undo链表
一个事务可能执行多个update insert语句, 在对记录的改变记录不同的链表来维持记录的变动。
事务提交后,undolog链表如果是比较小的是会被重用的。具体undo写入过程就不写了。
binlog
Redo log是InnoDB独有的,是为了崩溃恢复,数据持久
而MySQL本身独有的文件是binlog:是在事务提交的时候同时写入binlog ,并且会完善redo数据的正确性commit。以便崩溃恢复redolog数据的正确性。binlog是MySQL用来全量回复到某个时间点的日志
binlog刷盘也是会有异步同步的情况,异步是写入oscache 默认是异步写入。
binlog是逻辑日志,记录的是这个语句的原始逻辑,比如“给ID=2这一行的c字段加1 ”。
redo log是循环写的;binlog是可以追加写入的。指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
通过两阶段提交保证数据正确性,简单说,redo log和binlog都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。
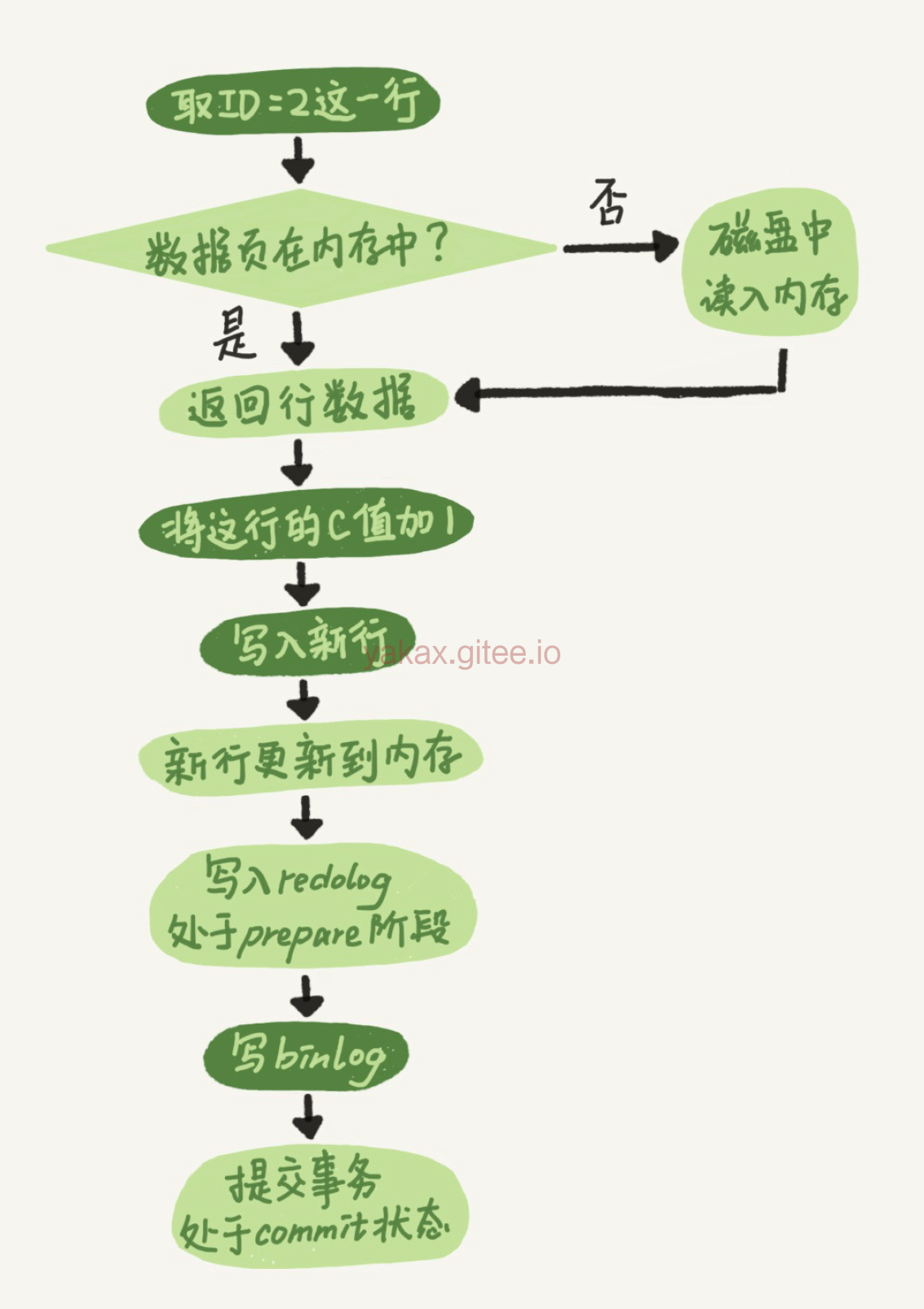
处于prepare阶段的redo log加上完整binlog,重启就能恢复
binlog写入时机
binlog的写入逻辑比较简单:事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache写
到binlog文件中。一个事务的binlog是不能被拆开的,因此不论这个事务多大,也要确保一次性写入。
系统给binlog cache分配了一片内存,每个线程一个,参数binlog_cache_size用于控制单个线程内binlog cache所占内存
的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
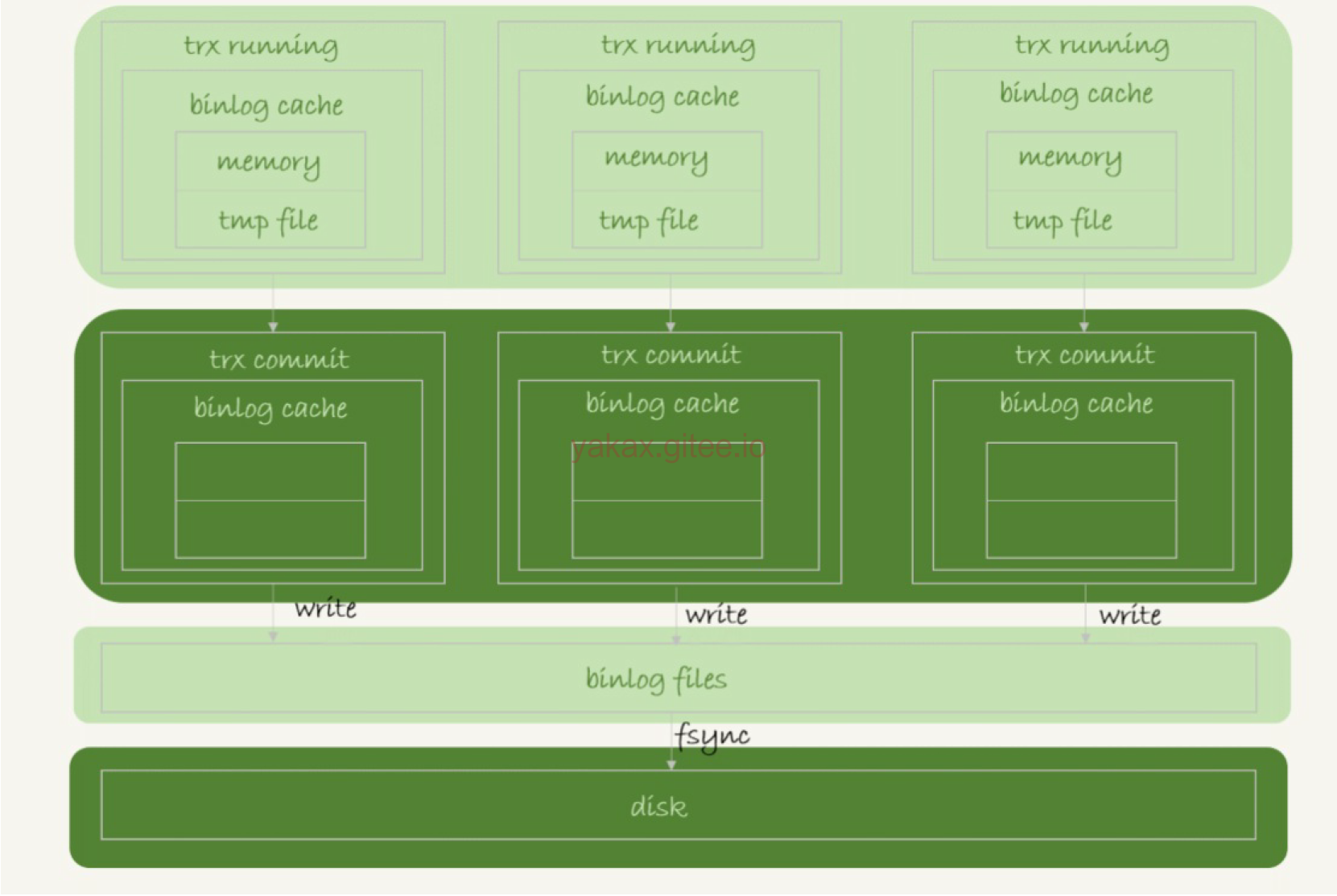
write:指的就是指把日志写入到文件系统的page cache,并没有把数据持久化到磁盘,所以速度比较快
fsync:才是将数据持久化到磁盘的操作。一般情况下,我们认为fsync才占磁盘的IOPS。
write 和fsync的时机,是由参数sync_binlog控制的:
-
sync_binlog=0的时候,表示每次提交事务都只write,不fsync;
-
sync_binlog=1的时候,表示每次提交事务都会执行fsync;
-
sync_binlog=N(N>1)的时候,表示每次提交事务都write,但累积N个事务后才fsync。
因此,在出现IO瓶颈的场景里,将sync_binlog设置成一个比较大的值,可以提升性能。在实际的业务场景中,考虑到丢
失日志量的可控性,一般不建议将这个参数设成0,比较常见的是将其设置为100~1000中的某个数值。但是,将sync_binlog设置为N,对应的风险是:如果主机发生异常重启,会丢失最近N个事务的binlog日志。
通常我们说MySQL的“双1”配置,指的就是sync_binlog和innodb_flush_log_at_trx_commit都设置成 1。也就是说,一个事
务完整提交前,需要等待两次刷盘,一次是redo log(prepare 阶段),一次是binlog。在配合组提交。这样tps相对压力还好。
redo log 和 binlog都是顺序写,磁盘的顺序写比随机写速度要快;组提交机制,可以大幅度降低磁盘的IOPS消耗。
binlog的三种格式
statement:记录的是具体的事务语句。当主从设置这个格式是很危险的,因为相当于针对语句,没有针对具体数据。
row:row格式的binlog里没有了SQL语句的原文,binlog里面记录了真实操作的主键id。
mixed:
因为有些statement格式的binlog可能会导致主备不一致,所以要使用row格式。但row格式的缺点是,很占空间。比如你用一个delete语句删掉10万行数据,用statement的话就是一个SQL语句被记录到binlog中,占用几十个字节的空间。但如果用row格式的binlog,就要把这10万条记录都写到binlog中。这样做会占用更大的空间,同时写binlog也要耗费IO资源,影响执行速度。
所以,MySQL就取了个折中方案,也就是有了mixed格式的binlog。mixed格式的意思是,MySQL自己会判断这条SQL语句是否可能引起主备不一致,如有可能,就用row格式,否则就用statement格式。















 240
240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









