







1. 关于K-Means
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
如果用数据表达式表示,假设簇划分为(C1,C2,…Ck),则我们的目标是最小化平方误差E:
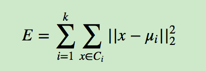
其中μi是簇Ci的均值向量,有时也称为质心,表达式为:
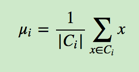
如果我们想直接求上式的最小值并不容易,这是一个NP难的问题,因此只能采用启发式的迭代方法。
K-Means采用的启发式方式很简单,用下面一组图就可以形象的描述。

上图a表达了初始的数据集,假设k=2。在图b中,我们随机选择了两个k类所对应的类别质心,即图中的红色质心和蓝色质心,然后分别求样本中所有点到这两个质心的距离,并标记每个样本的类别为和该样本距离最小的质心的类别,如图c所示,经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。此时我们对我们当前标记为红色和蓝色的点分别求其新的质心,如图4所示,新的红色质心和蓝色质心的位置已经发生了变动。图e和图f重复了我们在图c和图d的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心。最终我们得到的两个类别如图f。
当然在实际K-Mean算法中,我们一般会多次运行图c和图d,才能达到最终的比较优的类别。
传统K-Means算法流程:
首先我们看看K-Means算法的一些要点。
1)对于K-Means算法,首先要注意的是k值的选择,一般来说,我们会根据对数据的先验经验选择一个合适的k值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的k值。
2)在确定了k的个数后,我们需要选择k个初始化的质心,就像上图b中的随机质心。由于我们是启发式方法,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心,最好这些质心不能太近。
好了,现在我们来总结下传统的K-Means算法流程。
输入是样本集D={x1,x2,…xm},聚类的簇树k,最大迭代次数N
输出是簇划分C={C1,C2,…Ck}
1) 从数据集D中随机选择k个样本作为初始的k个质心向量: {μ1,μ2,…,μk}
2)对于n=1,2,…,N
a) 将簇划分C初始化为Ct=∅t=1,2…k
b) 对于i=1,2…m,计算样本xi
和各个质心向量μj(j=1,2,…k)的距离:dij=||xi−μj||22,将xi标记最小的为dij所对应的类别λi。此时更新Cλi=Cλi∪{xi}
c) 对于j=1,2,…,k,对Cj
中所有的样本点重新计算新的质心μj=1|Cj|∑x∈Cjx
e) 如果所有的k个质心向量都没有发生变化,则转到步骤3)
3) 输出簇划分C={C1,C2,…Ck}
。
K-Means非常简单,使用scikit几行代码就搞定了,所以下面我们使用同样的数据,先手工推演一遍,然后尝试使用python进行编程训练。
假设我们有一组二维数据集。如下所示:
D = { (5,3), (10,15), (15,12), (24,10), (30,45), (85,70), (71,80), (60,78), (55,52), (80,91) }
我们要将他们分为两个簇:C1,C2
第一步是随机选择两个簇的质心,我们设C1簇的质心为c1,C2簇的质心为c2,这里就设它们为前两个点好了:c1位(5,3),c2为(10,15)
接下来开始迭代

上表中第二列是数据点,第三列是各点距离c1的欧式距离,第四列是各点距离c2的欧式距离。最后一列是根据各点距离c1,c2的远近被划分到对应的簇的结果。比如第三个点(15,12),它距离c1为13.45,距离c2为5.83,5.83<13.45,所以将其划到C2
在第一轮迭代完毕之后,接下来需要计算新的质点,质点的值是通过各个簇中所有数据点的坐标的平均值计算出来的。
在这里,C1的新质点还是(5,3),因为在第一次迭代后C1只有一个点,而C2的新质点c2的x值为:
(10 + 15 + 24 + 30 + 85 + 71 + 60 + 55 + 80) / 9 = 47.77
同理,y值为
(15 + 12 + 10 + 45 + 70 + 80 + 78 + 52 + 91) / 9 = 50.33
所以,现在的c2为{47.77, 50.33}
在第二次迭代中,就用新的c1,c2同样计算各点到他们的欧式距离

第二次迭代结果如上
同样根据结果计算新的c1,c2
c1(x) = (5, 10, 15, 24) / 4 = 13.5
c1(y) = (3, 15, 12, 10) / 4 = 10.0
所以c1是(13.5, 10.0)
c2(x) = (30 + 85 + 71 + 60 + 55 + 80) / 6 = 63.5
c2(y) = (45 + 70 + 80 + 78 + 52 +91) / 6 = 69.33
所以c2是(63.5, 69.33)
接着第三次迭代
结果如下

计算c1
c1(x) = (5, 10, 15, 24, 30) / 5 = 16.8
c1(y) = (3, 15, 12, 10, 45) / 5 = 17.0
新的c1为(16.8, 17.0)
计算c2
c2(x) = (85 + 71 + 60 + 55 + 80) / 5 = 70.2
c2(y) = (70 + 80 + 78 + 52 + 91) / 5 = 74.2
新的c2为(70.2, 74.2)
第四次迭代

计算c1
c1(x) = (5, 10, 15, 24, 30) / 5 = 16.8
c1(y) = (3, 15, 12, 10, 45) / 5 = 17.0
新的c1为(16.8, 17.0)
计算c2
c2(x) = (85 + 71 + 60 + 55 + 80) / 5 = 70.2
c2(y) = (70 + 80 + 78 + 52 + 91) / 5 = 74.2
新的c2为(70.2, 74.2)
可以看到,这次计算出的c1,c2与第三次迭代的结果相同。这意味着数据无法进一步聚类了。聚类任务已经结束。
接下来我们编程看看如何实现。
首先导入相应的库

加载数据,还是使用手工推演时的数据

先画出最原始的散点图,方便和后面的结果比较

完整代码在1.py
运行结果如下

接下来我们调用KMeans

在第一行中,创建一个KMeans对象并设置n_clusters参数的值传递2。接下来,需要在kmeans上调用fit方法并传递想要聚类的数据,在本例中是我们之前创建的X数组。
接下来我们打印出聚类最终结果得到的质心

完整代码在2.py

可以看到,这个结果与我们前面手工推演得到的是一样的
也可以查看每个数据点的label,即被划分到了哪一簇


这里需要注意,0,1没有任何意义,只是为了区分两个簇而已。
在结果中看到,前5个点归在一起,后5个点归在一起
接下来我们将聚类后的结果可视化

我们将X数组的第一列与第二列绘图,同时将kmeans.labels_作为c的参数的值传递。cmap='rainbow '参数用于为不同的数据点选择不同的颜色类型。
完整代码在4.py
运行后结果如图

从图中可以看到,左下角的点归为一类,右上角的点归为一类
如果我们是聚为3类呢?
很简单,修改n_cluster的参数即可

完整代码在5.py
运行后结果如图

我们还可以把质心也画出来,这里指定质心用黑色表示,以示区分

完整代码在6.py
运行结果如图

在3聚类的情况下,与左下角或右上角的质心相比,中间的两点(以红色显示)离中间的质心(以黑色显示)更近。而如果有两个聚类,中间就不会有质心,因此红点必须与左下角或右上角的聚类点聚集在一起。
参考:
1.《机器学习》(西瓜书)
2. https://en.wikipedia.org/wiki/K-means_clustering
3. https://stackabuse.com/k-means-clustering-with-scikit-learn/
4. https://blog.csdn.net/taoyanqi8932/article/details/53727841
5. https://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html















 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









