







研究背景: 随着多模态大型语言模型(MM-LLMs)的发展,它们在多种下游任务中取得了显著的性能提升。然而,随着模型规模和数据集的不断扩大,传统的多模态模型在从头开始训练时面临着巨大的计算成本。为了解决这一问题,研究者们开始利用现有的预训练单模态基础模型,特别是强大的大型语言模型(LLMs),以成本效益高的训练策略来增强多模态输入或输出的支持。这种策略旨在减轻计算开销,提高多模态预训练的效率,从而推动了MM-LLMs这一新兴领域的发展。

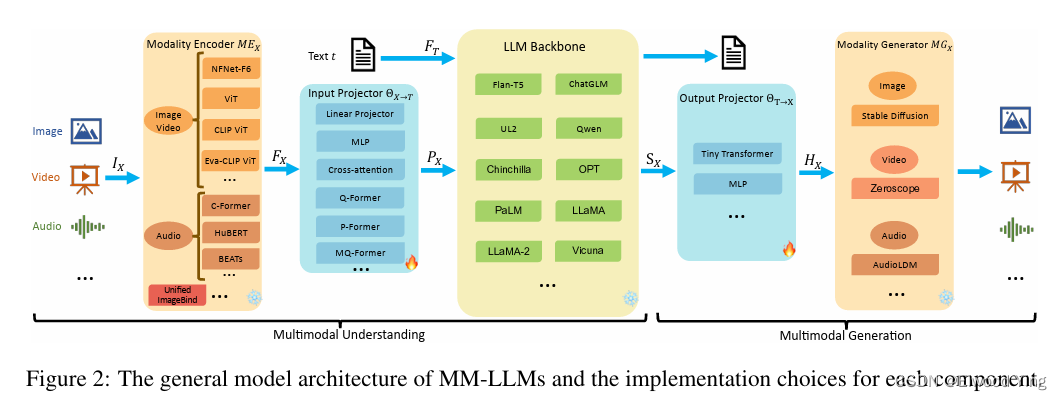

过去方案和缺点: 以往的多模态模型在训练时通常需要从头开始,这不仅计算成本高,而且在处理多模态数据时存在效率低下的问题。此外,这些模型在指令遵循、零样本学习、上下文学习(ICL)和交互能力方面存在不足。此外,传统的训练流程仅包括预训练(PT)阶段,而没有包含指令微调(IT)阶段,限制了模型的灵活性和适应性。
本文方案和步骤: 本文提出了一种全面的研究调查,旨在促进MM-LLMs的进一步研究。首先,文章概述了模型架构和训练流程的一般设计公式。然后,介绍了一个包含122个MM-LLMs的分类体系,每个模型都有特定的公式特征。此外,文章回顾了选定的MM-LLMs在主流基准测试上的性能,并总结了关键的训练配方以增强MM-LLMs的效能。最后,文章探讨了MM-LLMs的有前景的发展方向,并建立了一个实时跟踪网站以跟踪该领域最新进展。
本文实验和性能: 文章中没有提供具体的实验结果或性能数据,因为它主要是一篇综述性论文,旨在提供一个关于MM-LLMs的全面概述。然而,文章中提到了对主流MM-LLMs在多个视觉-语言(VL)基准上的比较,这些基准包括OKVQA、IconVQA、VQAv2等。这些比较可以帮助理解不同模型在特定任务上的表现,并从中提取提高模型效能的训练配方。
阅读总结报告: 本文是一篇关于多模态大型语言模型(MM-LLMs)的综述性论文,它提供了对这一领域最新进展的全面概述。文章首先介绍了MM-LLMs的研究背景,指出了传统多模态模型在计算成本和训练效率方面的挑战。然后,文章提出了一种利用预训练的大型语言模型(LLMs)来增强多模态输入或输出的方法,以解决这些挑战。文章详细介绍了MM-LLMs的模型架构、训练流程,并建立了一个包含122个模型的分类体系。此外,文章还探讨了MM-LLMs的未来发展,包括模型的增强、更具挑战性的基准测试、移动/轻量级部署、具身智能和持续学习等方向。最后,文章通过建立一个实时跟踪网站,为研究人员提供了一个持续更新和协作的平台。总的来说,这篇论文为MM-LLMs领域的研究人员提供了宝贵的资源和指导。














 55
55











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









