







我们首先学习一些基础的理论知识,然后编写几个demo配合IDA的调试进行mips的传参特点、叶子函数等。
Mips相关知识非常多,接下来要学习的知识都是与我们之后分析路由器相关安全研究联系紧密的知识点。
在路由器中,经常使用的mips架构为mips32.mips32结构是一种基于固定长度的定期编码指令集,采用load/store数据模型。
寄存器:
我们知道mips属于RISC,而RISC一个显著特点就是大量使用寄存器。因为寄存器的存取可以在一个时钟周期内完成,同时简化了寻址方式。所以mips32的指令中除了load/store外,都使用寄存器或者立即数作为操作数。Mips32中的寄存器分为两类,分别是通用寄存器(GPR)和特殊寄存器。
通用寄存器:
共32个,在汇编中表示为$0…
31
。
也
可
以
用
寄
存
器
的
名
字
表
示
,
如
31。也可以用寄存器的名字表示,如
31。也可以用寄存器的名字表示,如sp,
t
l
,
tl,
tl,ra等。
具体的用法可以去网上搜索。这里介绍几个比较重要的。
$0:该寄存器总是返回0.mips常会使用slt,beq,bne等指令和由寄存器$0获得的0值产生所有的比较条件,如相等、不等、小于之类的。
$4$7($a0
a
3
)
:
用
于
将
前
4
个
参
数
传
递
给
子
程
序
,
不
够
的
用
栈
来
处
理
。
这
里
强
调
一
点
:
a3):用于将前4个参数传递给子程序,不够的用栈来处理。这里强调一点:
a3):用于将前4个参数传递给子程序,不够的用栈来处理。这里强调一点:a0$a3,$v0
v
1
,
v1,
v1,ra共同完成子程序调用过程,分别用以传递参数、返回结果、和存放返回地址。当需要使用更多的寄存器时就需要栈了。Mips为参数在栈中留有空间,以防有参数需要存储。
$27$27($k0$k1):通常被中断或异常处理程序使用,以保存一些系统参数
28
(
28(
28(gp):该寄存器作为全局指针(global pointer),在编译时,数据需要在以$gp为基指针的64KB范围内。
30
(
30(
30(fp):一般用作栈指针(frame pointer),在另外一些编译器里被用作保存寄存器($s8)
31
(
31(
31(ra):存放返回地址。常见于与jal使用。Jal(jump-and-link)跳转并链接指令,在跳转到某个地址时可把下一条指令的地址存放到$ra中,用于支持子程序。
特殊寄存器:
共3个。分别是pc(程序计数器),HI(乘除结果高位寄存器),LO(乘除结果地位寄存器).在进行乘法运算时,HI,LO保存乘法的运算结果,其中HI存储高32位,LO存储低32位;进行除法运算时,HI保存余数,LO存储商。
指令:
有三种类型

各字段含义如下:
Opcode:指令基本操作,操作码
Rs:第一个源操作数寄存器
Rt:第二个源操作数寄存器
Rd:存放操作结果的目的操作数
Shamt:位移量
Funct:函数
常用的指令如下:
1)Load/store指令:以l开头的都是加载指令,以s开头的都是存储指令,这些指令用于从存储器中读取数据,或者而降数据保存在存储器中,如:



2)算术运算指令:算术运算指令所有操作数都是寄存器,不能直接使用ram地址或间接寻址,操作数的大小都是4字节。如:
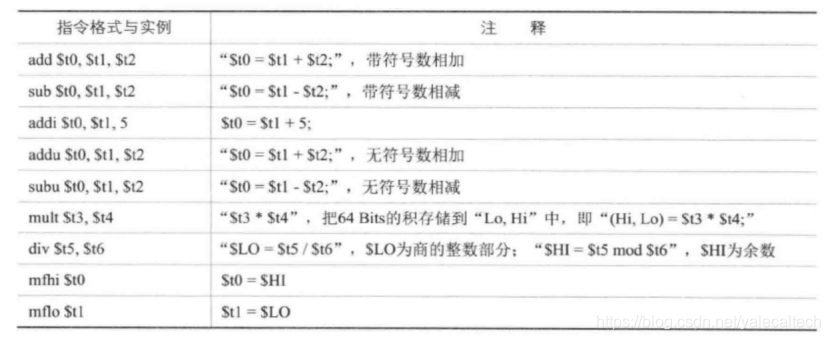
3)跳转指令
分析时需要注意对子函数的调用和返回
子程序的调用的形式 jar sub_routine_label
分为两步进行1.复制当前的pc值到$ra寄存器中(当前的pc值就是子程序执行完毕后返回地址)
2.程序跳转到子程序标签sub_routine_label处
子程序的返回:jr
r
a
这
时
需
要
注
意
子
程
序
内
如
果
又
调
用
了
其
他
函
数
,
则
ra 这时需要注意子程序内如果又调用了其他函数,则
ra这时需要注意子程序内如果又调用了其他函数,则ra的值应被保存到堆栈中(因为$ra的值总是对应着当前执行的子函数的返回地址)

4)分支跳转指令:
通过比较两个寄存器中的值来决定是否跳转
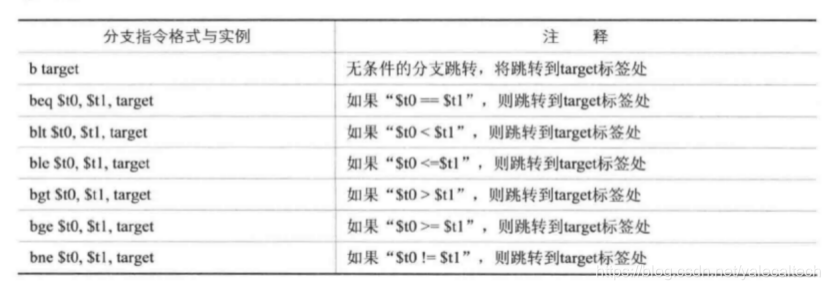
5)SYSCALL(system call)
可产生软中断,从而实现系统调用。在后面分析学习shellcode时会涉及该指令
栈:
栈是由内存高地址向内存低地址方向增长。
调用栈(call stack)指存放某个程序正在运行的函数的信息的栈
调用栈由栈帧(stack frames)组成,每个栈帧对应一个未完成运行的函数。
栈用于传递函数参数、存储返回值信息、保存寄存器,回复调用前处理机的状态等。
。
Mips并不直接支持堆栈,没有单独的栈操作指令,所有对栈的操作都是统一的内存访问方式。在发生函数调用时,调用者把函数调用之后要用的寄存器压入堆栈,被调用者把返回地址寄存器
r
a
(
并
非
任
何
时
候
都
保
存
ra(并非任何时候都保存
ra(并非任何时候都保存ra)和保留寄存器压入堆栈,同时,调整堆栈指针,并在返回时从堆栈中恢复寄存器。
Mips32架构中没有ebp(栈底指针),进入一个函数时,需要将当前栈指针向下移动n比特,这块大小为n比特的存储空间就是此函数的stack frame的存储区域。函数返回时将栈指针加上这个偏移量恢复栈现场。
如果函数a调用函数b,函数a会在自己的栈顶预留一部分空间来保存b的参数,称之为调用参数空间
前4个传入的参数通过
a
0
a0~
a0 a3传递,超过4个的,被放入调用传参空间。
我们可以写一段代码来看看。
test.c内容如下
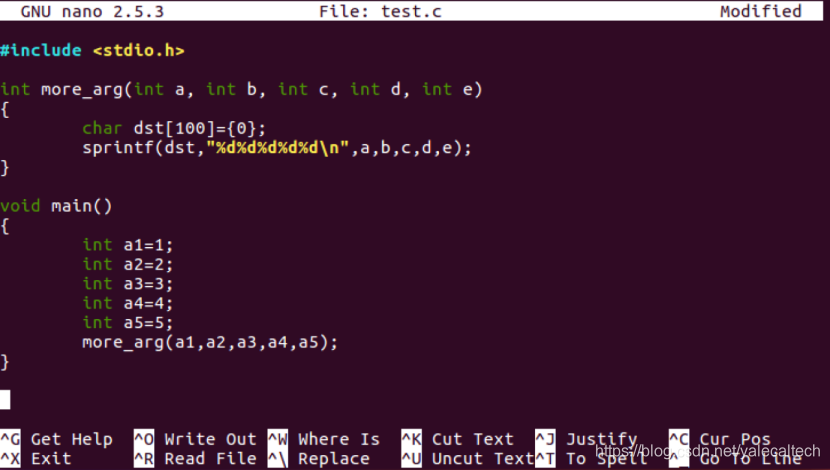
可以看到需要传5个参数,根据之前的知识,我们知道a0~a3四个寄存器不能满足参数的传递,因此会使用栈保存第5个参数
将其编译成test

然后载入ida分析
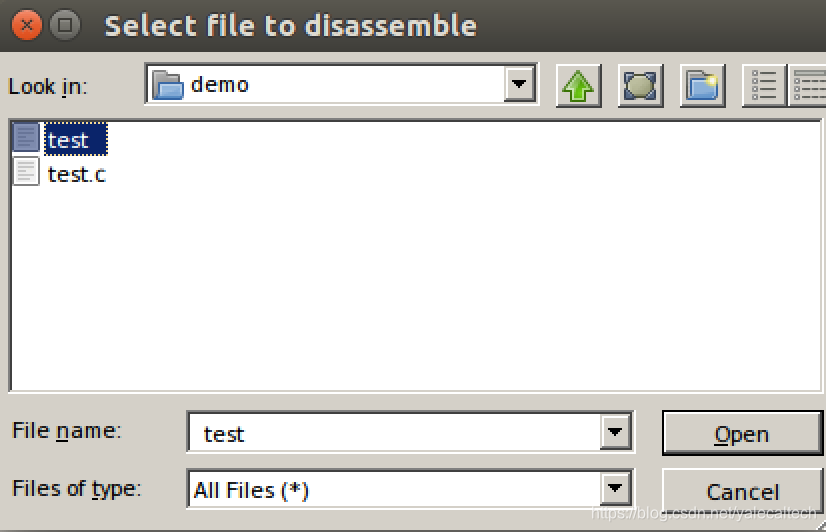
在main函数中看到临时分配了5个变量,将需要的5个参数分别保存其中
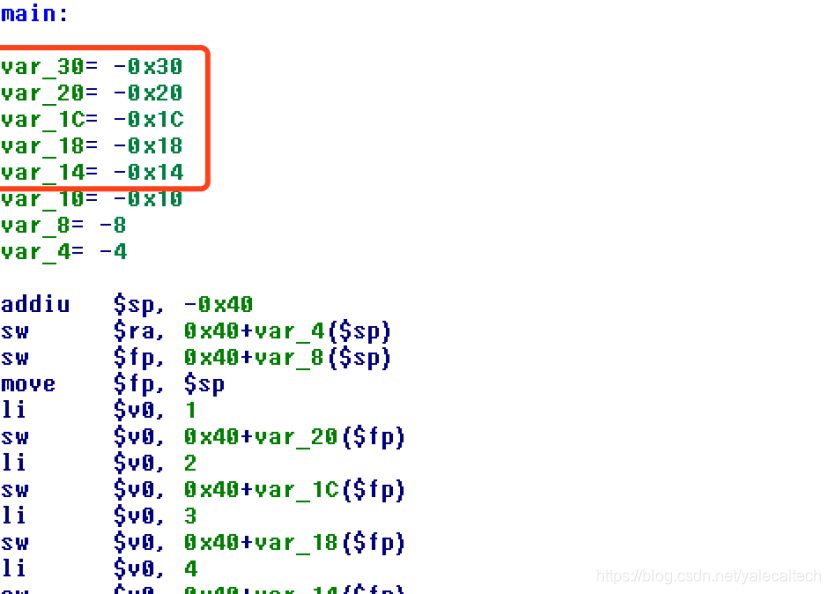
调用more_args之前可以看到
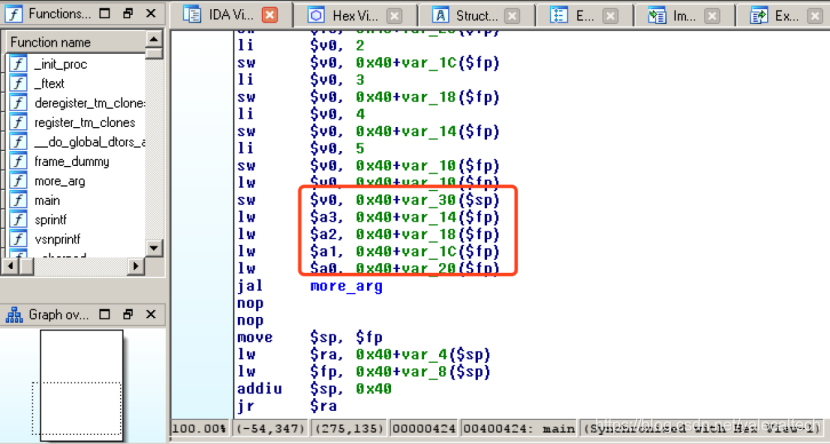
将more_args()需要的5个参数,前4个加载到
a
0
a0~
a0 a3,第五个从临时变量中取出,存储到main函数预留的调用参数空间中。
接下来执行more_args,注意到more_args会调用spinrf函数,在调用sprintf之前,more_args会先将a0a3复制到main函数栈帧与预留的调用参数空间中,在执行sprintf时,它需要7个参数,此时会将前4个参数存入a0a3,剩余的3个参数保存到more_args自己的调用参数空间中,如下所示
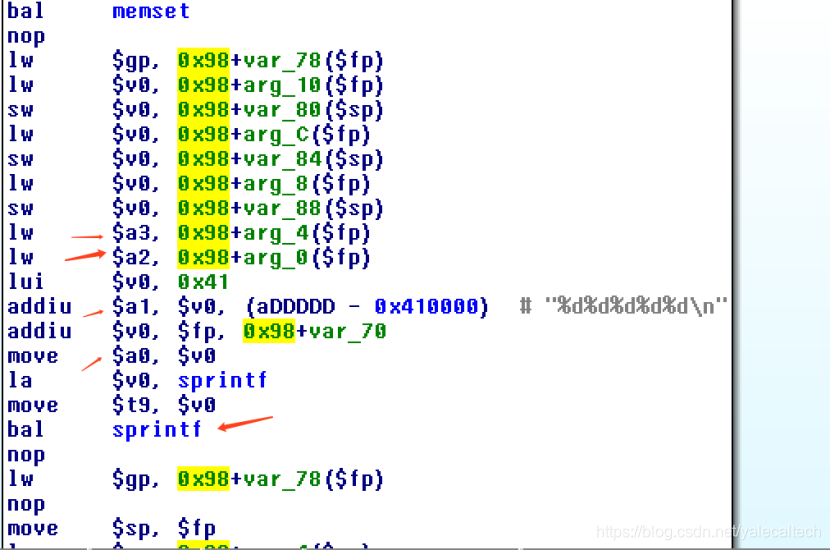
前面是使用ida静态分析,接下来动态分析
首先下断点,分别在main中调用more_args处下一个
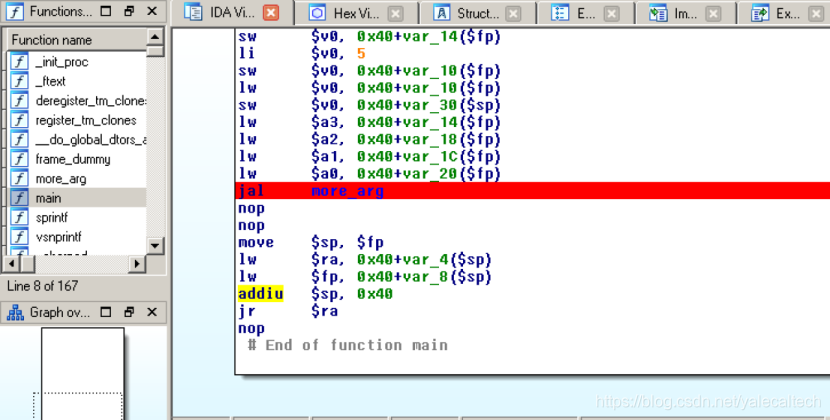
以及more_args中调用sprintf下一个
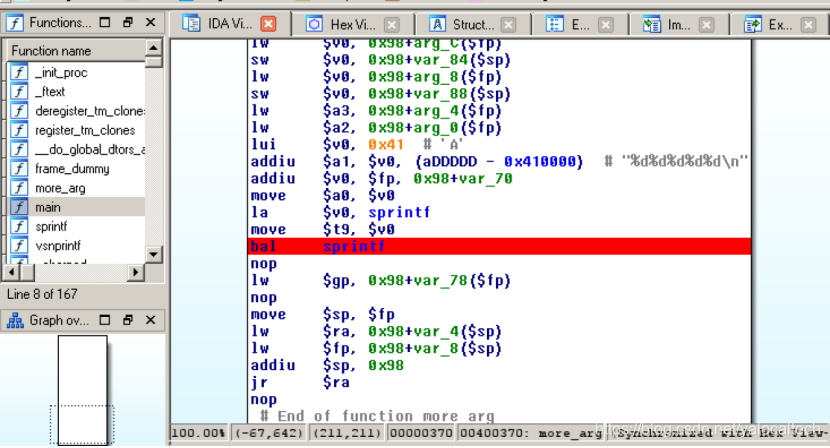
然后在终端中执行


接下来在ida上连上后进行调试即可
f9直接执行,到第一个断点也就是在进入more_args之前命中
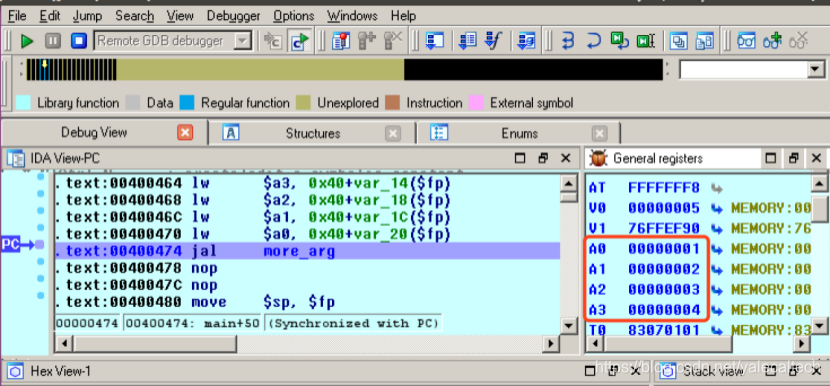
在上图中可以看到
a
0
a0~
a0 a3依次为main传的1,2,3,4
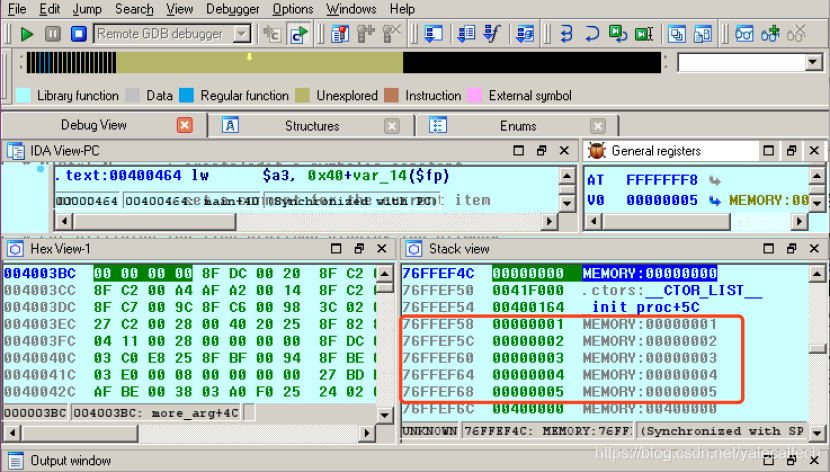
而第五个参数呢?
前面说了会放到main函数预留的调用参数空间中,如上所示
接下来继续f9执行,程序将命中第二个断点,也就是在more_args调用sprinf之前
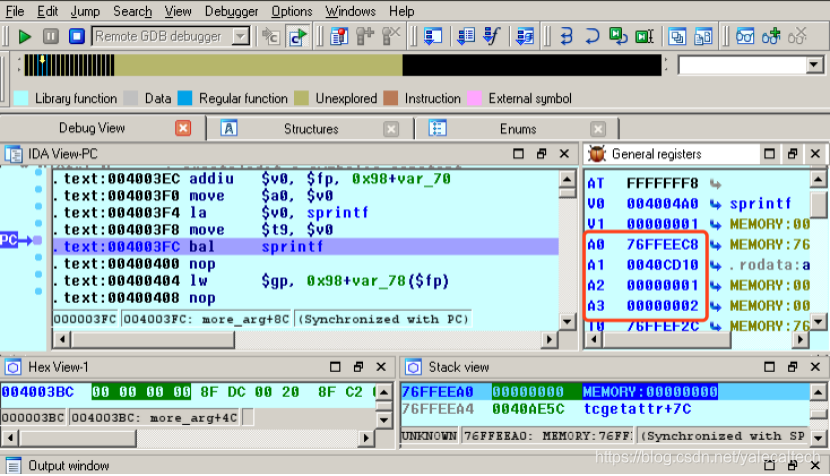
可以看到,按照传参的顺序,前四个依次写到了
a
0
a0~
a0 a3
剩余的三个参数呢?前面说过,会放到more_args()自己的调用参数空间中,可以到stack view中看见
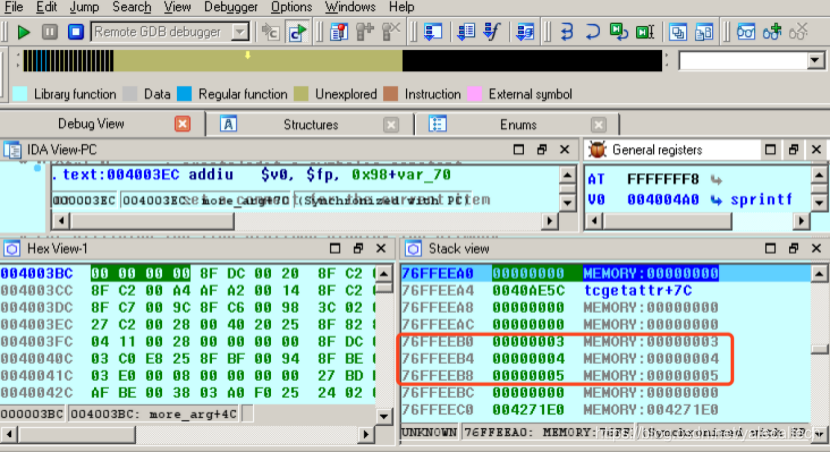
介绍两个概念。叶子函数和非叶子函数。如果一个函数a不再调用其他函数,称之为叶子函数,否则函数a就是一个非叶子函数。
这两个函数的区别主要在于调用时对
r
a
的
处
理
上
。
当
a
调
用
b
时
,
会
复
制
当
前
的
ra的处理上。 当a调用b时,会复制当前的
ra的处理上。当a调用b时,会复制当前的pc寄存器的值到
r
a
,
即
当
前
的
ra,即当前的
ra,即当前的ra的值就是当前函数执行结束的返回地址。接着跳转到b执行。
跳转到b之后,如果b是叶子函数,不做任何处理。如果b是非叶子函数,则首先从
r
a
中
取
出
a
的
返
回
地
址
存
入
堆
栈
,
以
便
由
b
调
用
的
函
数
将
b
的
返
回
地
址
存
入
ra中取出a的返回地址存入堆栈,以便由b调用的函数将b的返回地址存入
ra中取出a的返回地址存入堆栈,以便由b调用的函数将b的返回地址存入ra。
函数返回时,如果为叶子函数,则直接使用”jr
r
a
”
返
回
,
如
果
是
非
叶
子
函
数
,
则
先
从
堆
栈
上
取
出
被
保
存
在
堆
栈
上
的
返
回
地
址
,
然
后
将
返
回
地
址
存
入
ra”返回,如果是非叶子函数,则先从堆栈上取出被保存在堆栈上的返回地址,然后将返回地址存入
ra”返回,如果是非叶子函数,则先从堆栈上取出被保存在堆栈上的返回地址,然后将返回地址存入ra,再使用”jr $ra”指令返回。
先来看非叶子函数的例子:
代码如下,在stack.c
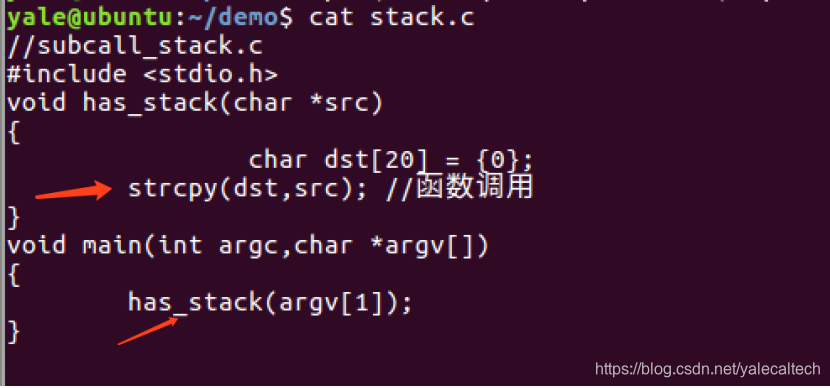
可以看到,main调用has_stack,has_stack调用strcpy,所以has_stack是非叶子函数。返回main函数的地址会先保存在
r
a
中
,
然
后
在
h
a
s
s
t
a
c
k
调
用
s
t
r
c
p
y
时
,
h
a
s
s
t
a
c
k
会
把
返
回
m
a
i
n
的
返
回
地
址
保
存
在
h
a
s
s
t
a
c
k
的
栈
中
,
然
后
s
t
r
c
p
y
会
把
h
a
s
s
t
a
c
k
的
返
回
地
址
保
存
在
ra中,然后在has_stack调用strcpy时,has_stack会把返回main的返回地址保存在has_stack的栈中,然后strcpy会把has_stack的返回地址保存在
ra中,然后在hasstack调用strcpy时,hasstack会把返回main的返回地址保存在hasstack的栈中,然后strcpy会把hasstack的返回地址保存在ra中,执行完strcpy后根据
r
a
返
回
h
a
s
s
t
r
p
y
,
h
a
s
s
t
r
c
p
y
执
行
后
返
回
m
a
i
n
时
,
会
将
保
存
在
栈
中
的
m
a
i
n
的
返
回
地
址
写
入
ra返回has_strpy,has_strcpy执行后返回main时,会将保存在栈中的main的返回地址写入
ra返回hasstrpy,hasstrcpy执行后返回main时,会将保存在栈中的main的返回地址写入ra然后返回。
我们先编译
然后ida载入分析
我们直接来到has_stack的汇编部分
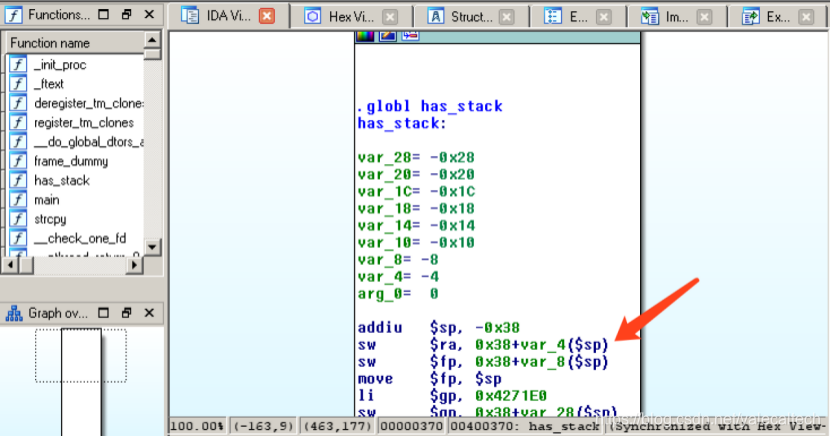
可以看到has_stack被调用后,一开始就执行上图箭头指向的语句,sw指令我们学过,用于将源寄存器的值存入指定的地址。这条指令的作用其实就是把main的返回地址存入has_stack的堆栈中。而当has_stack返回main时怎么办呢?
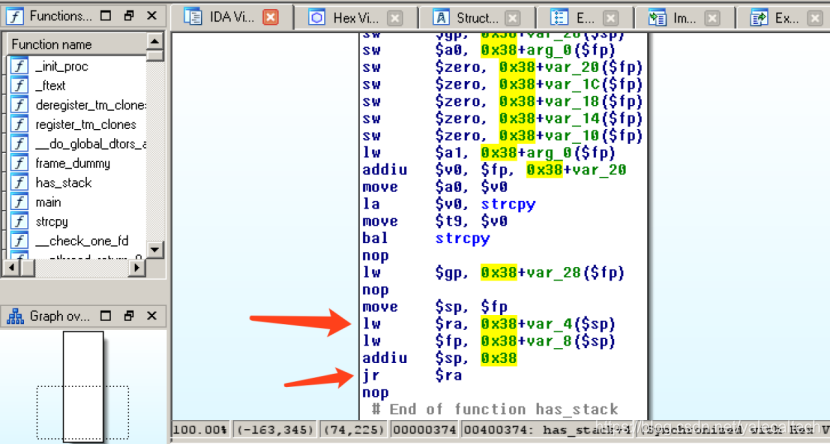
在has_stack最末尾可以看到,会先去之前用于保存返回地址的那个地址处取回,放入$ra,然后通过jr $ra返回到main。
这时候我们是不是可以有这么一个想法:
既然在这种情况下,main的返回地址会先被保存在has_stack的栈上(准确的讲,是在has_stack栈帧底部),那么如果has_stack的局部变量如果存在缓冲区溢出,就有导致堆栈上返回main函数的返回地址被覆盖,这样的话取出的返回main的返回地址不再是正确的地址,而是攻击者特地构造的。后面的课程将会介绍这种情况的攻击。
再来看一个叶子函数的例子,源码如下
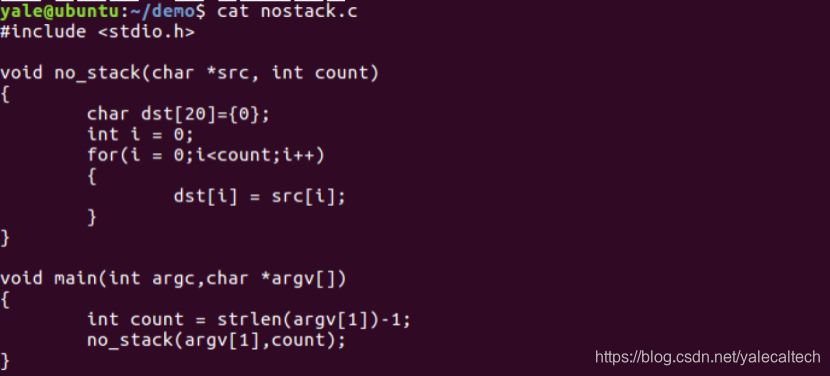
main调用了no_stack,no_stack没有再调用其他函数,故no_stack为叶子函数
编译
ida载入

根据之前的知识我们知道,对于叶子函数,一开始把返回地址存入$ra,最后直接jr $ra返回即可
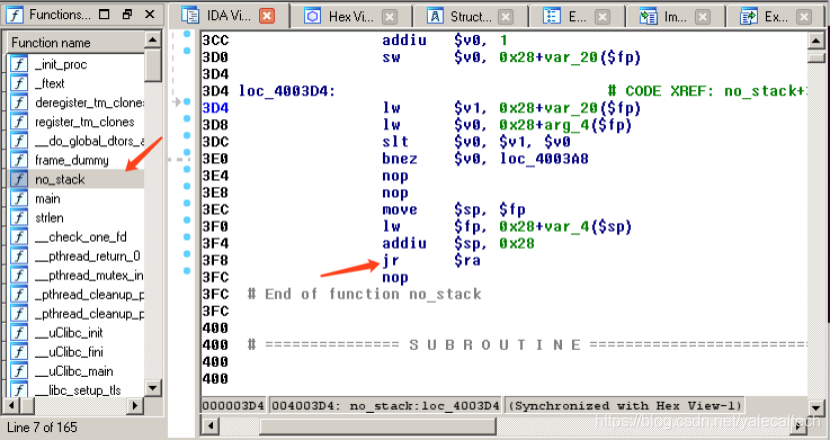
如上图所示,确实除了ja
r
a
以
外
,
没
有
对
ra以外,没有对
ra以外,没有对ra其他的操作了。
因为攻击者可控的缓冲区在内存中,无法控制$ra,所以即使no_stack存在缓冲区溢出,也无法覆盖main返回地址。不过,如果溢出覆盖的区域足够大,no_stack的缓冲区溢出是有可能覆盖main的栈帧的,这样就可能覆盖main栈帧中存放的上层函数的返回地址。
综上所述,不论是叶子函数还是非叶子函数,都是可能进行栈溢出的漏洞利用的。
。
参考:
1.华盛顿大学的课程讲义:https://courses.cs.washington.edu/courses/cse410/09sp/examples/MIPSCallingConventionsSummary.pdf
2.《揭秘家用路由器0day漏洞挖掘技术》

















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









