







第三部分 变量
第十章 使用变量的一般事项
10.3 变量初始化原则
1. 在声明变量的时候初始化。
2. 在靠近变量第一次使用的位置初始化它。相关的操作放在一起。
3. 理想情况下,在靠近第一次使用变量的位置声明和定义该变量。
4. 在可能的情况下使用final或者const。
5. 特别注意计数器和累加器。
6. 在类的构造函数里初始化该类的数据成员。
7. 检查是否需要重新初始化。
8. 一次性初始化具名常量:用可执行代码来初始化变量。
9. 使用编译器设置来自动初始化所有变量。
10. 利用编译器的警告信息。
11. 检查输入参数的合法性。
12. 使用内存访问检查工具来检查错误的指针。
13. 在程序开始时初始化工作内存。把程序的工作内存填充为一个可以预料的值。也能保证程序不会因内存初始值的随机性而受到影响。
10.4 作用域
减小作用域的一般原则。
1. 在循环开始之前再去初始化该循环里使用的变量,而不是在该循环所属的子程序的开始处初始化这些变量。
2. 直到变量即将被使用时再为其赋值。
3. 把相关语句放到一起。
4. 把相关语句组提取成单独的子程序。
5. 开始时采用最严格的可见性,然后根据需要扩展变量的作用域。
这是方便性和智力可管理性理念的争斗。
10.5持续性
与持续性相关的最主要问题是变量实际生命期比你想象的要短。
1. 在程序中加入调试代码或者断言来检查哪些关键变量的合理取值。如果变量取值变得不合理,就发出警告信息通知你去寻找是否有不正确的初始化。
2. 准备抛弃变量时给它们赋上不合理的数值。例如指针置null。
3. 编写代码时要假设数据并没有持续性。不适于static。
4. 养成在使用所有数据之前声明和初始化的习惯。
10.6 绑定时间
把变量和它的值绑定在一起的时间。
1. 编码时(使用神秘数值)。
2. 编译时(使用具名常量)。
3. 加载时(从Windows注册表、Java属性文件等外部数据源中读取数据)。
4. 对象实例化时(例如在美刺窗体创建的时候读取数据)。
5. 即时(例如在每次窗体重绘的时候读取数据)。
绑定时间越早灵活性越差,但复杂度也会降低。
10.8 为变量指定单一用途
1. 每个变量只用于单一用途。少用temp这类。
2. 避免让代码具有隐含意义。比如秘密约定大于500000就是过期账户。
3. 确保使用了所有已声明的变量。
第十一章 变量名的力量
11.1 选择好变量名的注意事项
该名字要完全、准确地描述出该变量所代表的事物。
以问题为导向。表达what而不是how。
名字长度在8-20个字符之间。
对位于全局命名空间中的名字加以限定词。
变量名中的计算值限定词放到名字的最后,如revenueTotal、customerCount、customerIndex。
变量名中常用的对仗词:

11.2 为特定类型的数据命名
1. 为循环下标命名,描述性。
2. 为状态变量命名,别带flag,描述性。
3. 为临时变量命名,警惕临时变量,这表示你还没有弄清它们的实际用途。
4. 为布尔变量命名,
a) 谨记典型的布尔变量名。如:done/error/found/success。
b) 给布尔变量赋予隐含真/假含义的名字:isDone/isProcessingComplete。
c) 使用肯定的布尔变量名,以免双重否定。
5. 为枚举变量命名,使用组前缀区别组。
6. 为常量命名,描述性。
11.4 非正式命名规则
与语言无关的命名规则的指导原则
1. 区分变量名和子程序名字。
2. 区分类和对象。如 Widget aWidget;
3. 标识全局变量。g_前缀。
4. 标识成员变量。m_前缀。
5. 标识类型声明。如t_Color。
6. 标识具名常量。如c_。
7. 标识枚举类型的元素。如Color_前缀。
8. 格式化命名以提高可读性。
与语言相关的命名规则的指导原则

第十二章 基本数据类型
12.1 数值概论
1. 避免使用magic number。
2. 如果需要,可以使用硬编码的0和1.
3. 预防除零错误。
4. 使类型转换变得明显。
5. 避免混合类型的比较。
6. 注意编译器的警告。
12.2 整数
1. 检查整数除法。应当最后执行除法,以防截去小数后的错误。
2. 检查整数溢出。

3. 检查中间结果溢出。换用更长的整型或者浮点型。
12.3 浮点数
1. 避免数量级相差巨大的数之间的加减运算。先对这些数排序,然后从最小值开始把它们加起来。
2. 避免等量判断。先确定可接受的精确度范围,然后用布尔函数判断数值是否足够接近。Equals()函数。
3. 处理舍入误差问题。
4. 检查语言和函数库对特定数据类型的支持。
12.4 字符和字符串
1. 避免使用神秘字符和神秘字符串。
2. 避免off-by-one错误。即因为读写操作超出了字符串末尾而导致的错误。
3. 了解你的语言和开发环境是如何支持Unicode的。
4. 在程序生命期中尽早决定国际化/本地化策略。比如,决定是否把所有字符串保存在外部资源里,是否为每一种语言创建单独的版本,或者在运行时确定特定的界面语言。
5. 如果你知道只需要支持单一文字的语言(如英语,非汉语),请考虑使用ISO8859字符集。
6. 如果你需要支持多种语言,请使用Unicode。
7. 采用某种一致的字符串类型转换策略。
12.5 布尔变量
1. 用布尔变量对程序加以文档说明。不同于仅仅判断一个布尔表达式,你可以把这种表达式的结果赋给一个变量,从而使得这一判断的含义变得明显。
2. 用布尔变量来简化复杂的判断。
3. 如果需要的话,创建你自己的布尔类型。C++不需要。
12.6 枚举类型
1. 用枚举类型来提高可读性。特别适用于定义子程序参数。
2. 用枚举类型来提高可靠性。
3. 用枚举类型来简化修改。
4. 将枚举类型作为布尔变量的替换方案。
5. 检查非法数值。
6. 定义出枚举的第一项和最后一项,以便用于循环边界。
7. 把枚举类型的第一个元素留做非法值。即0。
8. 明确定义项目代码编写标准中第一个和最后一个元素的使用规则,并且在使用时保持一致。合法项都从1开始?美剧中第一个和最后一个元素合法吗?
9. 警惕给枚举元素明确赋值而带来的失误。小心中间是否有非法数值。
12.7 具名常量
1. 在数据声明中使用具名常量。
2. 避免使用magic number,即使是“安全”的。
3. 统一地使用具名常量。
12.8 数组
少用,用容器。
12.9 创建你自己的类型(类型别名)
typedef float coordinate; // for coordinate variables
易修改,数据集中在一处好管理,增加可靠性。
1. 给所创建的类型取功能导向的名字。
2. 避免使用预定义类型。
3. 不要重定义一个预定义的类型。
4. 定义替代类型以便于移植。
5. 考虑创建一个类而不是使用typedef。
第十三章 不常见的数据类型
13.1 结构体
用结构体(只让相关的东西在一起)的理由:
1. 用结构体来明确数据关系。
2. 用结构体简化对数据块的操作。
3. 用结构体来简化参数列表。
4. 用结构体来减少维护。
13.2 指针
1. 把指针操作限制在子程序或者类里面。
2. 同时声明和定义指针。初始化。
3. 在与指针分配相同的作用域中删除指针。谁创建谁删除。
4. 使用指针之前检查指针。
5. 先检查指针所引用的变量再使用它。
6. 用狗牌字段来检测损毁的内存。tag field或者dog tag是指你加入结构体内的一个仅仅用于检测错误的字段。在分配一个变量的时候,把一个应该保持不变的数值放在它的标记字段里。当使用该结构的时候——特别是释放其内存的时候——检测这个标记字段的取值。如果这个标记字段的取值与预期不相符,那么这一数据就被破坏了。
7. 用额外的指针变量来提高代码清晰度。
8. 简化复杂的指针表达式。
9. 画一个图。
10. 分配一片保留的内存后备区域。
11. 在删除或者释放指针之后把它们设为空值。
12. 在删除变量之前检查非法指针。
13. 编写覆盖子程序,集中实现避免指针问题的策略。SAFE_NEW/SAFE_DELETE
针对C++:
1. 理解指针和引用之间的区别。
2. 把指针用于“按引用传递”参数,把const引用用于“按值传递”参数。
3. 使用auto_ptr。
4. 灵活运用智能指针。
13.3 全局数据
用访问器子程序来取代全局数据。
1. 要求所有的代码通过访问器子程序来存取数据。
2. 不要把你所有的全局数据都扔在一处。
3. 用锁定来控制对全局变量的访问。
4. 在你的访问器子程序里构建一个抽象层。
5. 使得对一项数据的所有访问都发生在同一个抽象层上。
只有万不得已时才使用全局数据。
1. 创建一种命名规则来突出全局变量。
2. 为全部的全局变量创建一份注释良好的清单。
3. 不要用全局变量来存放中间结果。
4. 不要把所有的数据都放在一个大对象中并到处传递,以说明你没有使用全局变量。
第四部分 语句
第十四章 组织直线型代码
1. 组织直线型代码的最主要原则是按照依赖关系进行排列。
2. 可以用好的子程序名、参数列表、注释,以及——如果代码足够重要——内务管理变量来让依赖关系变得更明显。
3. 如果代码之间没有顺序依赖关系,那就设法使相关的语句尽可能地接近。
第十五章 使用条件语句
1. 对于简单的if-else语句,注意顺序,特别是用来处理大量错误的时候。要确认正常的情况是清晰的。
2. 对于if-then-else语句串和case语句,选择一种最有利于阅读的排序。
3. 为了捕捉错误,case用default,if-then-else用最后的else。
4. 各种控制结构并不是生来平等的。请为代码的每个部分选用最合适的控制结构。
第十六章 控制循环
1. 保持循环简单有助于别人阅读你的代码。
2. 保持循环简单的技巧包括:避免使用怪异的循环、减少嵌套层次、让入口和出口一目了然、把内务操作代码放在一处。
3. 循环下标易被滥用。因此命名要准确,并且要把它们各自仅用于一个用途。
4. 仔细地考虑循环,确认它在每一种情况下都运行正常,并且在所有可能的条件下都能退出。
第十七章 不常见的控制结构
17.1 子程序中的多处返回
1. 如果能增强可读性,那么久使用return。
2. 用早返回或早退出来简化复杂的错误处理,避免很深的嵌套逻辑。
3. 减少每个子程序中return的数量。
17.2 递归
1. 确认递归能够停止。
2. 使用安全技术器防止出现无穷递归。
3. 把递归限制在一个子程序内。
4. 留心栈空间。可以new在堆上。
5. 不要用递归去计算竭诚或者斐波那契数列。
第十八章 表驱动法
表驱动法是一种编程模式(scheme)——从表里面查找信息而不使用逻辑语句(if和case)。程序中的信息存放在数据里而不是逻辑里。
18.1 表驱动法使用总则
两个问题:怎样从表里查询条目;应该在表里面存些什么。
三种方法:直接访问(Direct access)、索引访问(Indexed access)、阶梯访问(Stair-step access)。
18.2 直接访问表
构造查询键值(如1-10一个样,11-50一个样,中间那些重复的怎么办?)
1. 复制信息从而能够直接使用键值。冗余易出错。
2. 转换键值以使其能够直接使用。
3. 把键值转换提取成独立的子程序。
18.3 索引访问表
有的时候,只用一个简单的数学运算还无法把age这样的数据转换成为表键值。这类情况中的一部分可以通过使用索引访问的方法加以解决。
当你使用索引的时候,先用一个基本类型的数据从一张索引表中查出一个键值,然后再用这一键值查出你感兴趣的主数据。
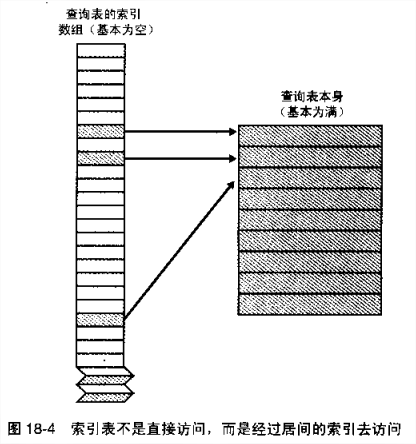
18.4 阶梯访问表
比索引访问方法省空间,费时间。表中的记录对于不同的数据范围有效,而不是对不同的数据点有效。
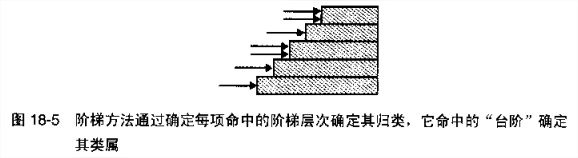
1. 留心端点。
2. 考虑用二分查找取代顺序查找。
3. 考虑用索引访问取代阶梯技术。
4. 把阶梯表查询操作提取成单独的子程序。
第十九章 一般控制问题
19.1 布尔表达式
只用true和false。
简化复杂的表达式:
1. 拆分复杂的判断并引入新的布尔变量。
2. 把复杂的表达式做成布尔函数。
3. 用决策表代替复杂的条件。
编写肯定形式的布尔表达式。
用括号使布尔表达式更清晰。
19.4 驯服危险的深层嵌套
1. 通过重复检测条件中的某一部分来简化嵌套的if语句。
2. 用break块来简化嵌套if。
3. 把嵌套if转换成一组if-then-else语句。
4. 把嵌套if转换成case语句。
5. 把深层嵌套的代码抽取出来放进单独的子程序。
6. 使用一种更面向对象的方法。多态。
7. 重新设计深层嵌套的代码。
19.5 编程基础:结构化编程
一个应用程序应该只采用一些单入单出的控制结构。单入单出的控制结构指的就是一个代码块,它只能从一个位置开始执行,并且只能结束于一个位置。初次之外再无其他入口或出口。
结构化编程的三个组成部分
1. 顺序Sequence:顺序指一组按照先后顺序执行的语句。
2. 选择Selection:选择是一种有选择的执行语句的控制语句。
3. 迭代Iteration:迭代是一种使一组语句多次执行的控制结构。循环。
将复杂度降低到最低水平是编写高质量代码的关键。















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









