







有需求:以n分钟为粒度统计n分钟内事件数量,要求时间连续。
数据结构如下:
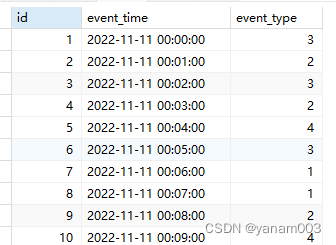
event_time:事件产生时间;event_type:事件类型
如果查询2022-11-11 10:21 至 2022-11-11 10:41之间,每5分钟的事件类型为3(event_type=3)的事件数量,有两种方案查询:
第一种是以下面语句做分组查询:
SELECT DATE_FORMAT( CONCAT(DATE(event_time),' ', HOUR(event_time),':', FLOOR(MINUTE(event_time) / 5) * 5), '%Y-%m-%d %H:%i') as start_time,
COUNT(*) as num
FROM tbl_event
WHERE event_type = 3
AND event_time BETWEEN '2022-11-11 10:21' AND '2022-11-11 10:41'
GROUP BY start_time
ORDER BY start_time得到结果:

这种结果与需求不符,因为10:21到10:41之间,以5分钟为粒度,应该有10:21-10:25,10:26-10:30,10:31-10:35:10:36-10:41四个时间段,而直接使用SQL查询,如果数据比较分散,可能出现不连续的时间段。另外这种查询方式,第一个时间段的开始时间也是由数据决定,不能很准确的从指定时间开始。这种方案SQL稍有点复杂。
第二种是以简单SQL初步筛选数据,然后在代码里处理分段逻辑。
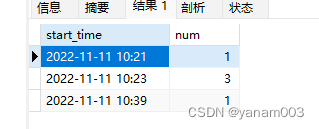
使用以下SQL语句按每分钟分组:
SELECT DATE_FORMAT(event_time, '%Y-%m-%d %H:%i') as start_time,
COUNT(*) as num FROM tbl_event
WHERE event_type = 3
AND event_time BETWEEN '2022-11-11 10:21' AND '2022-11-11 10:41'
GROUP BY start_time
ORDER BY start_time得到如下结果,中间出现断档,是因为没有数据。
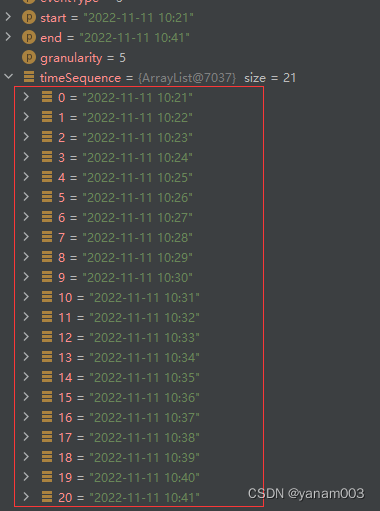
在程序里以指定的开始时间到结束时间生成每分钟的时间序列,以本例条件生成的时间序列如下
循环这个时间序列,以指定分钟粒度来划分时间段:
List<StatisticsVO> result = new ArrayList<>();
int total = 0;
String currentTime = "";
for (int i = 1; i <= timeSequence.size(); i++) {
currentTime = timeSequence.get(i - 1);
if (statisticsResult.containsKey(currentTime)) {
total += statisticsResult.get(currentTime).getNum();
}
if ((i % granularity) == 0 || i == timeSequence.size()) {
StatisticsVO vo = new StatisticsVO();
int idx = i % granularity == 0 ? i - granularity : i - (i % granularity);
vo.setStartTime(timeSequence.get(idx));
vo.setNum(total);
result.add(vo);
total = 0;
}
}得到如下结果:
[
{
"startTime": "2022-11-11 10:21",
"num": 4
},
{
"startTime": "2022-11-11 10:26",
"num": 0
},
{
"startTime": "2022-11-11 10:31",
"num": 0
},
{
"startTime": "2022-11-11 10:36",
"num": 1
},
{
"startTime": "2022-11-11 10:41",
"num": 0
}
]这样就符合要求了。















 8630
8630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









