






直接上程序,我就说怎么用就好了。
import requests
from bs4 import BeautifulSoup
import re
h={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'}
u=input('小说网址:')
b=input('半节点:')
w=input('文本id:')
x=input('下一章id:')
n=input('书名:')
c=int(input('剩余章数:'))
q=len(input('清除末尾字数:'))
for i in range(c):
r=requests.get(u,headers=h)
s=BeautifulSoup(r.text,'html.parser')
t=s.select('#'+w)[0].text[:-q]
t=re.sub(" ","\n ",t)
t = t.replace('\ufffd', '()')#替换
u='https://m.hafuklxt.cc/'+s.select("#"+x)[0].get('href')
with open(n+'.txt','a') as f:
f.write(t)
print(i)
print('下载完成')
使用时一行一行输入信息,具体上面有写,下面是示范。
目标:我不是戏神
运行程序
小说网址:https://m.hafuklxt.cc/chapter/15543941/67855658.html
半节点:https://m.hafuklxt.cc/
文本id:chaptercontent
下一章id:pb_next
书名:我不是戏神
剩余章数:700
清除末尾字数:111111111111111111111111111111111#有32个字就行
其实本质上就是下面这个程序
import requests
from bs4 import BeautifulSoup
import re
u='https://m.hafuklxt.cc/chapter/15543941/67855658.html'
h={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'}
for i in range(30):
r=requests.get(u,headers=h)
s=BeautifulSoup(r.text,'html.parser')
t=s.select('#chaptercontent')[0].text[:-32]
t=re.sub(" ","\n ",t)
t = t.replace('\ufffd', '()')#替换
u='https://m.hafuklxt.cc/'+s.select("#pb_next")[0].get('href')
with open('cs.txt','a') as f:
f.write(t)
print(i)id用f12开发者工具找,如图所示。
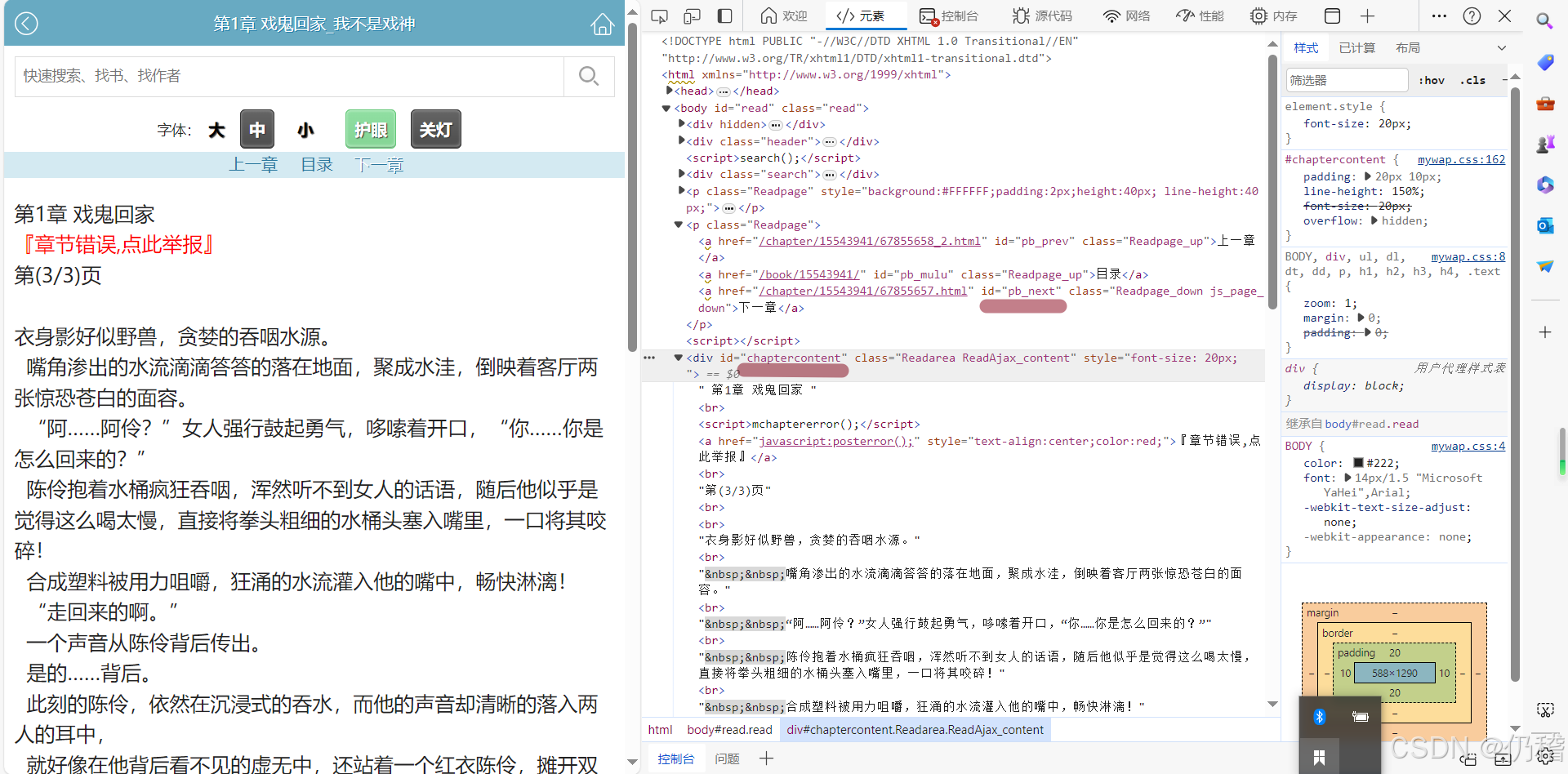
本程序只能用id定位,当然,改一下就能用其他的定位方法了,记住文件是追加,所以如果有同名文件或者程序重复运行的话内容就会重复,当然,把网址填成断的那一章就行,比如说从100章更新到110章,你已经爬了100章了,网址就用101章的就行了,对了要在同名文件夹下,不然你就要自己改程序写入文本的位置。
对了,由于处理特殊字符的方式是直接消灭,所以有些地方可能有空白,但应该不怎么影响阅读体验吧,主要是我只会替换特殊字符。
ok,本篇文章结束了,希望能帮到你。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









