









Scrapy爬虫(九):scrapy的调试技巧
本章将介绍scrapy的一些调试技巧。
scrapy的调试
在开发爬虫时调试工作是必要的且重要的,无论是开发前的准备工作,比如测试该网站在scrapy爬虫中是否可用;或者是下载时的伪装工作,比如为爬虫设置请求参数模拟浏览器;亦或是在解析下载下来的数据,比如如何使用xpath解析等等,不可能每次都运行程序爬虫来达到调试的目的,因为这样效率太低了。
在开发时我所用到的方法通常是使用浏览器调试及scrapy命令工具调试。
浏览器调试
浏览器调试通常可以通过浏览器开发工具来获取请求参数,如显示源码、局部检查、firebug等。
1、显示源码
通常我们使用浏览器右键–>显示网页源码 功能,可以获取该url页的网页源码。
2、代码检查
代码检查可以精确查看当前选中元素的html标签
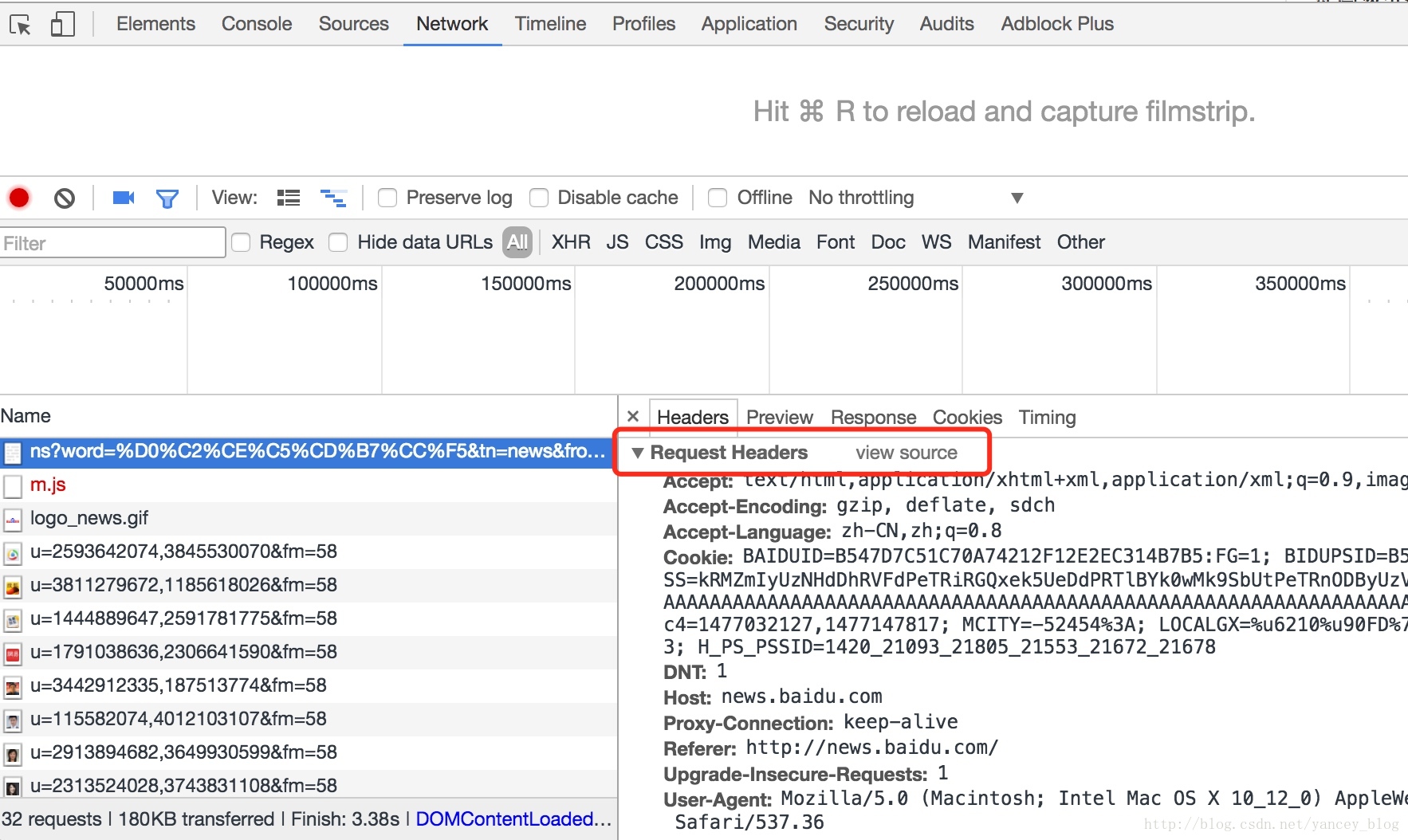
3、查看请求参数
打开代码检查后再network标签下,查看请求头Request Headers
chrome浏览器
火狐浏览器自带工具
firebug工具
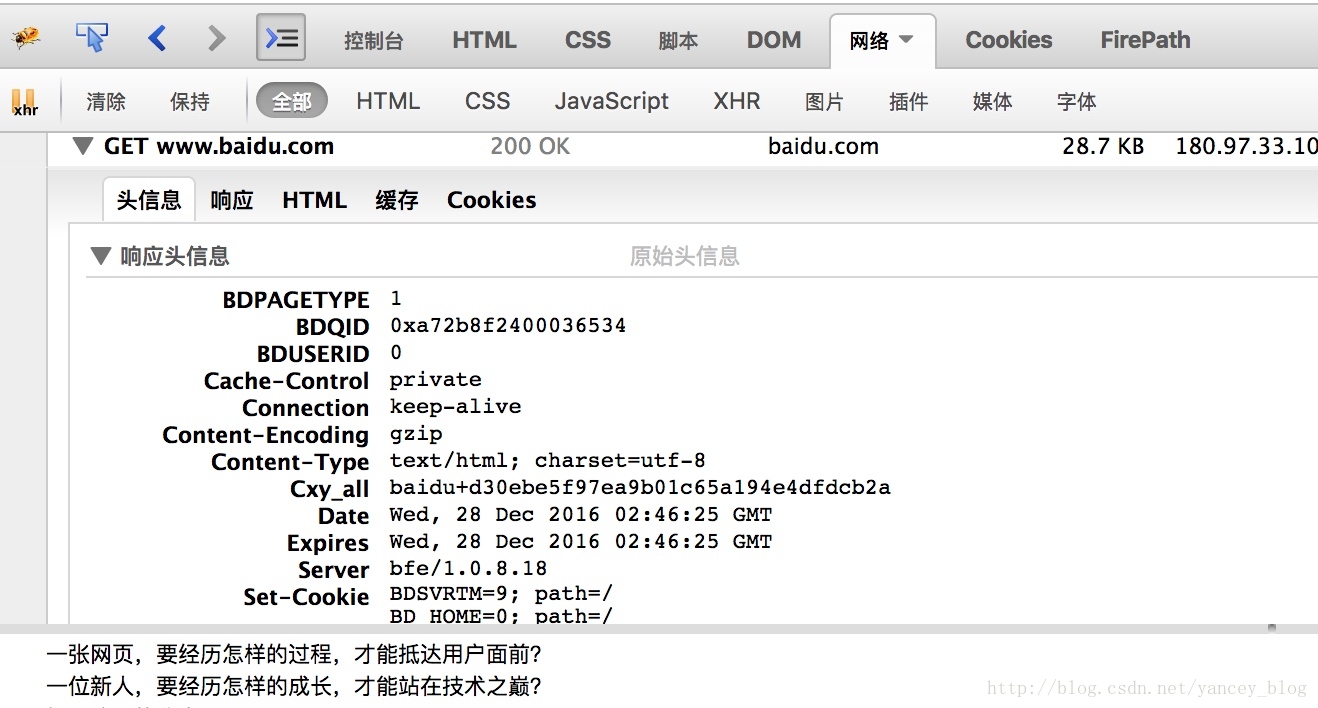
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding:gzip, deflate, sdch
Accept-Language:zh-CN,zh;q=0.8
Cookie:BAIDUID=B547D7C51C70A74212F12E2EC314B7B5:FG=1; BIDUPSID=B547D7C51C70A74212F12E2EC314B7B5; PSTM=1470221362; BDUSS=kRMZmIyUzNHdDhRVFdPeTRiRGQxek5UeDdPRTlBYk0wMk9SbUtPeTRnODByUzVZSVFBQUFBJCQAAAAAAAAAAAEAAAAWX1g4y87WvsTPAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADQgB1g0IAdYY; Hm_lvt_e9e114d958ea263de46e080563e254c4=1477032127,1477147817; MCITY=-52454%3A; LOCALGX=%u6210%u90FD%7C%36%36%39%33%7C%u6210%u90FD%7C%36%36%39%33; PSINO=3; H_PS_PSSID=1420_21093_21805_21553_21672_21678
DNT:1
Host:news.baidu.com
Proxy-Connection:keep-alive
Referer:http://news.baidu.com/
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36查看user-agent,chrome中也可以通过chrome://version/
4、xpath调试
现在的话scrapy主要使用xpath、css、正则表达式,但是还是以xpath为主,关于这部分的知识,可以google下,这里我不在重复造轮子。
关于xpath的使用 点击
chrome浏览器
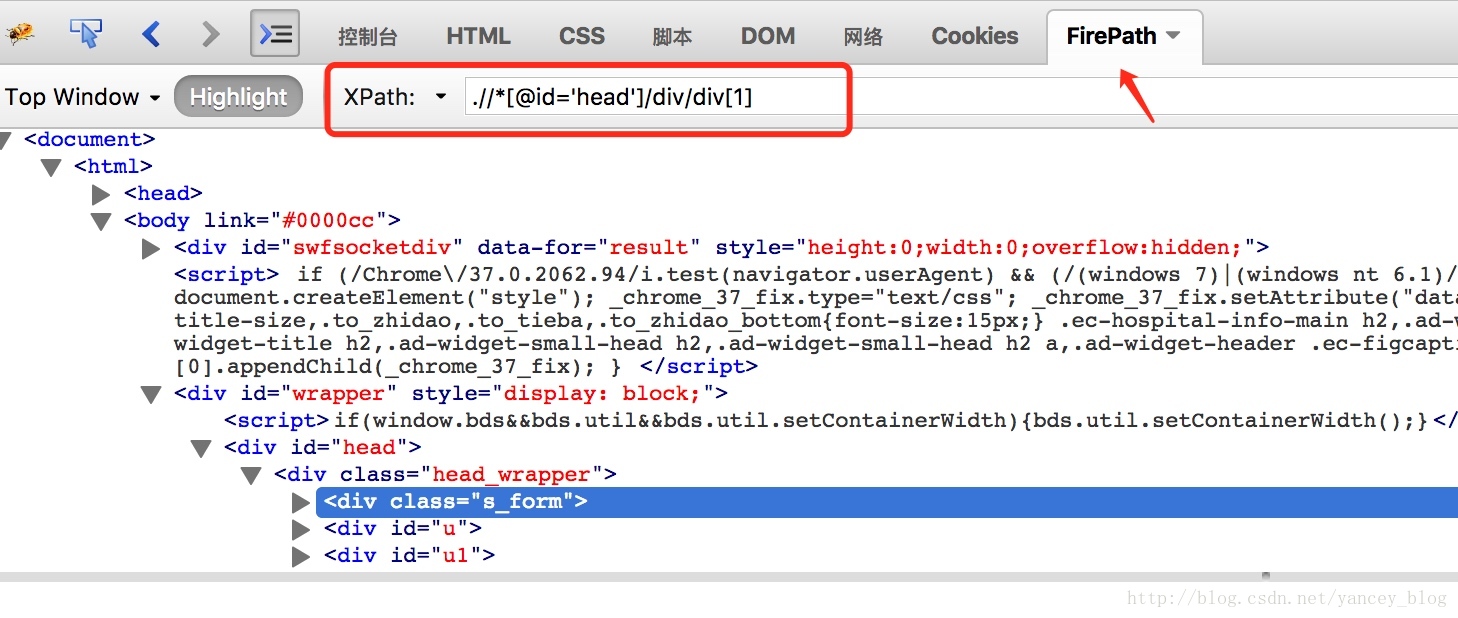
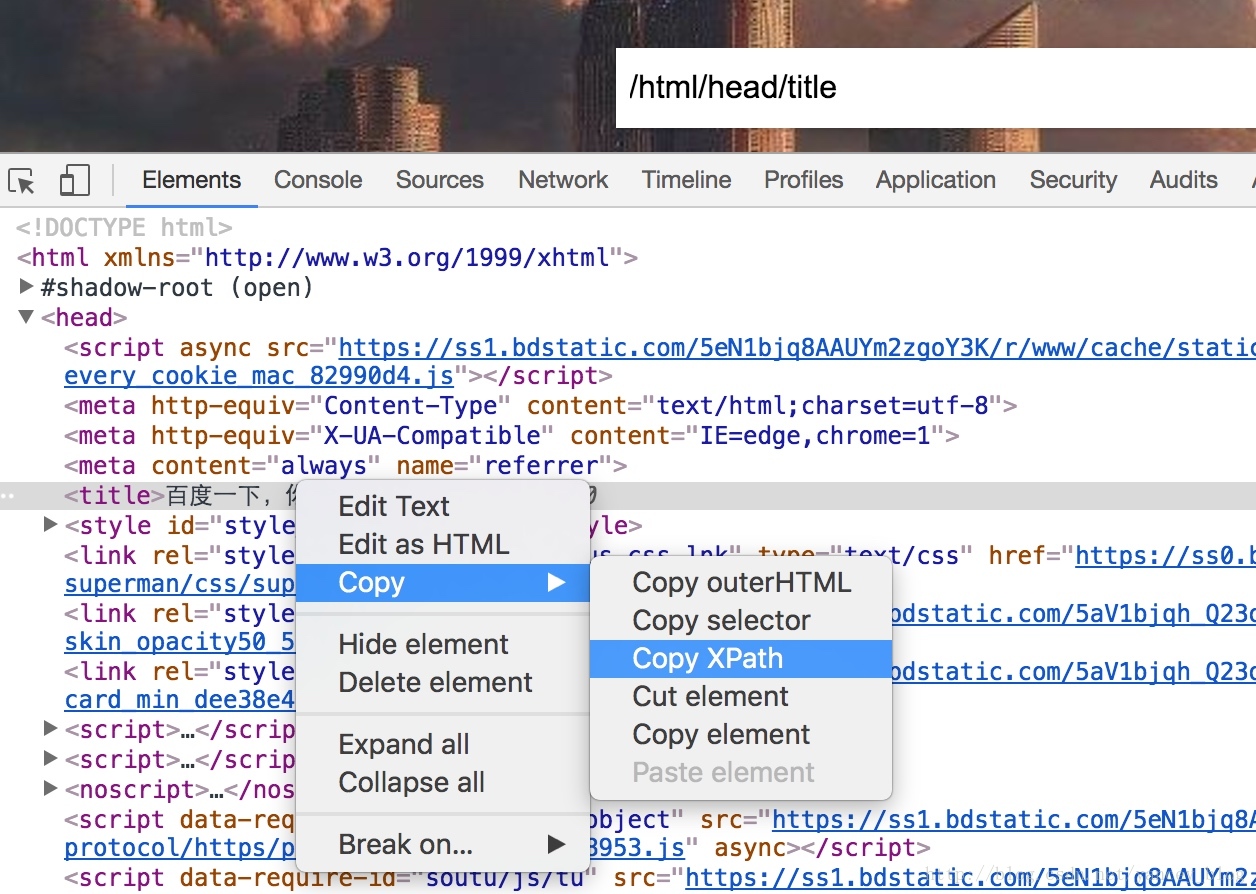
检查代码后可以在标签上右键–>Copy–>Copy XPath
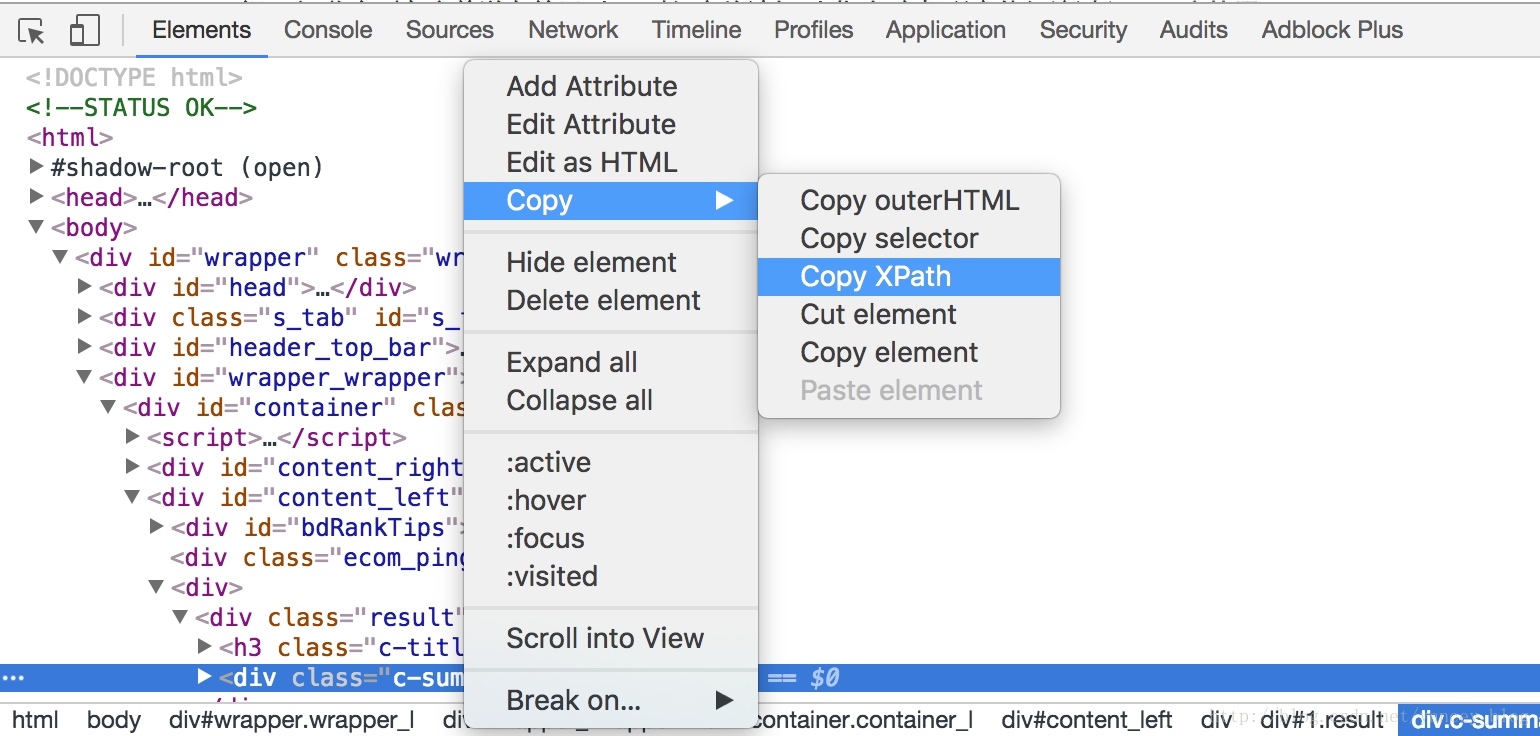
结果为
//*[@id="content_right"]火狐浏览器 可以使用firebug插件
scrapy命令调试
scrapy自带调试命令
localhost:~ yancey$ scrapy
Scrapy 1.2.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
commands
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a commandscrapy startproject project
创建project项目scrapy crawl project
进入project目录运行project爬虫scrapy version
查看scrapy版本scrapy genspider testspider baidu.com
创建一个spider name为testspider的爬虫,start_urls为http://www.baidu.com/的爬虫scrapy runspider testspider.py
在未创建项目的情况下,运行一个编写在Python文件中的testspider。scrapy fetch --nolog http://www.baidu.com/
下载baidu并标准输出scrapy view http://www.baidu.com/
下载百度页并在浏览器打开当然本处调试时,scrapy shell用的比较多
以百度首页为例 https://www.baidu.com/
scrapy shell https://www.baidu.com/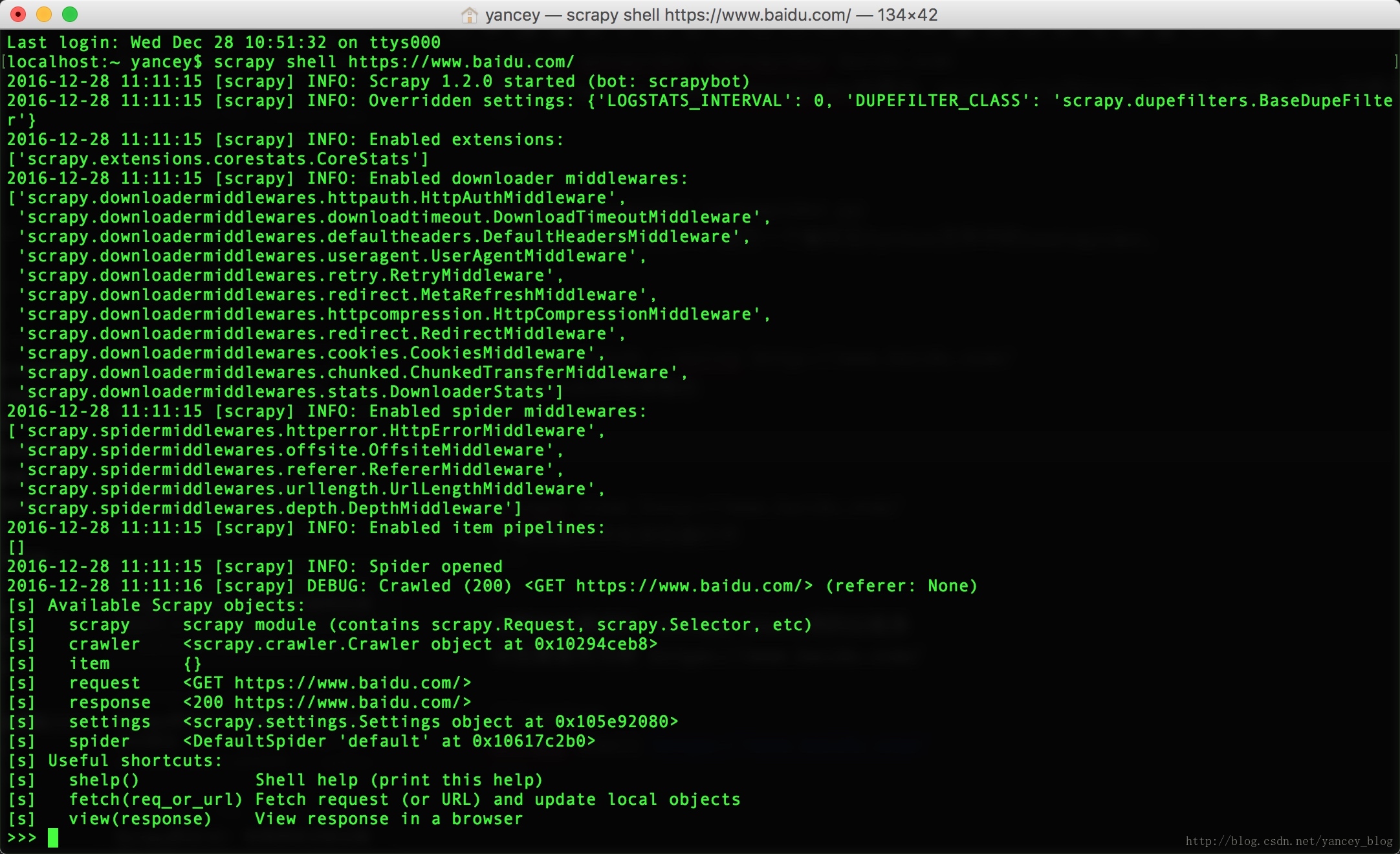
- 操作response,查看url,使用response.url,标准输出

查看百度首页标题,xpath调试
先检查代码获取xpath,为/html/head/title
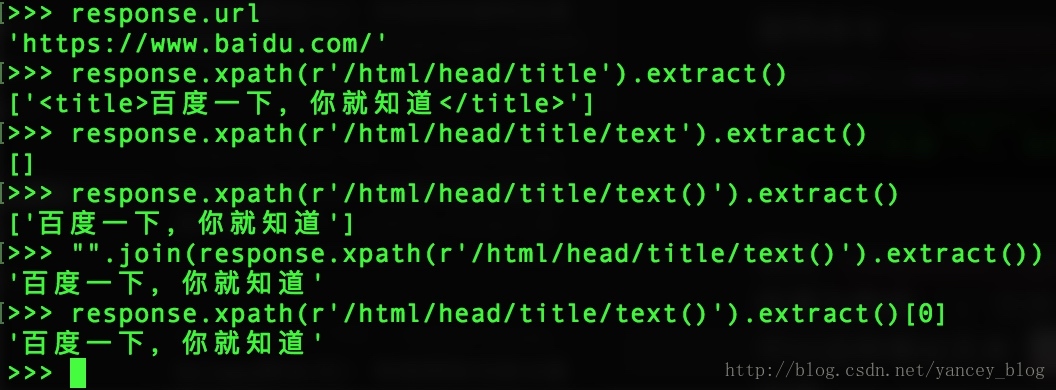
使用命令response.xpath(r'/html/head/title').extract()

优化response.xpath(r'/html/head/title/text()').extract()
结果为数组 ['百度一下,你就知道']
可以这样得出文本response.xpath(r'/html/head/title/text()').extract()[0]
或者"".join(response.xpath(r'/html/head/title/text()').extract())
关于其他命令,读者朋友可以自己捣鼓下,本处不在多讲了,就我而言调试命令主要用于解析xpath的调试。
集成开发环境(IDE)调试
关于集成开发环境的调试大家应该都会使用,本处就不在赘述了。














 1276
1276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









