









Scrapy爬虫(七):爬虫数据存储实例
本章将实现数据存储到数据库的实例。
数据存储
scrapy支持将数据存储到文件,例如csv、jl、jsonlines、pickle、marshal、json、xml,少量的数据存储到数据库还行,如果超大量的数据存储到文件(当然图片还是要存文件的),就显得不太友好,毕竟这些数据要为我所用。
因此我们通常将数据存储到数据库,本处将介绍的是最常用的数据库mysql。我们也看到scrapy中的pipeline文件还没有用到,其实这个文件就是处理spider分发下来的item,我们可以在pipeline中处理文件的存储。
- mysql库(PyMysql)的添加
打开pycharm File–>Default Settings–>Project interpreter点击左下角的“+”,搜索PyMysql,如图:

点击安装install package,如果无法安装可以选择将上面的install to user‘s site…勾选安装到Users目录下。
配置mysql服务
1、安装mysql
root@ubuntu:~# sudo apt-get install mysql-serverroot@ubuntu:~# apt isntall mysql-client root@ubuntu:~# apt install libmysqlclient-dev 期间会弹出设置root账户的密码框,输入两次相同密码。
2、查询是否安装成功
root@ubuntu:~# sudo netstat -tap | grep mysql root@ubuntu:~# netstat -tap | grep mysql
tcp6 0 0 [::]:mysql [::]:* LISTEN 7510/mysqld 3、开启远程访问mysql
- 编辑mysql配置文件,注释掉“bind-address = 127.0.0.1”
root@ubuntu:~# vi /etc/mysql/mysql.conf.d/mysqld.cnf #bind-address = 127.0.0.1- 进入mysql root账户
root@ubuntu:~# mysql -u root -p123456 - 在mysql环境中输入grant all on . to username@’%’ identified by ‘password’;
- 或者grant all on . to username@’%’ identified by ‘password’ with grand option;
root@ubuntu:~# grant all on *.* to china@'%' identified by '123456'; - 刷新flush privileges;然后重启mysql,通过/etc/init.d/mysql restart命令
root@ubuntu:~# flush privileges; root@ubuntu:~# /etc/init.d/mysql restart - 远程连接时客户端设置:
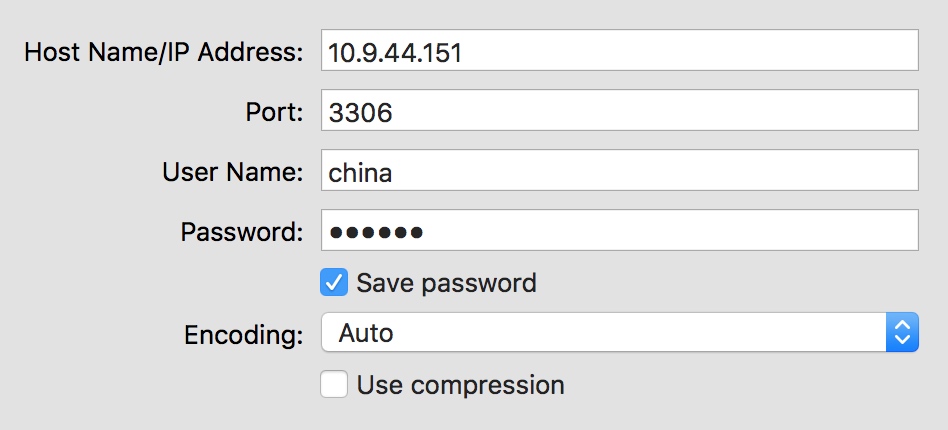
4、常见问题
- 1045 access denied for user ‘root’@’localhost(ip)’ using password yes
1、mysql -u root -p;
2、GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'%' IDENTIFIED BY 'mypassword' WITH GRANT OPTION;
3、FLUSH PRIVILEGES;在mysql中创建好四个item表
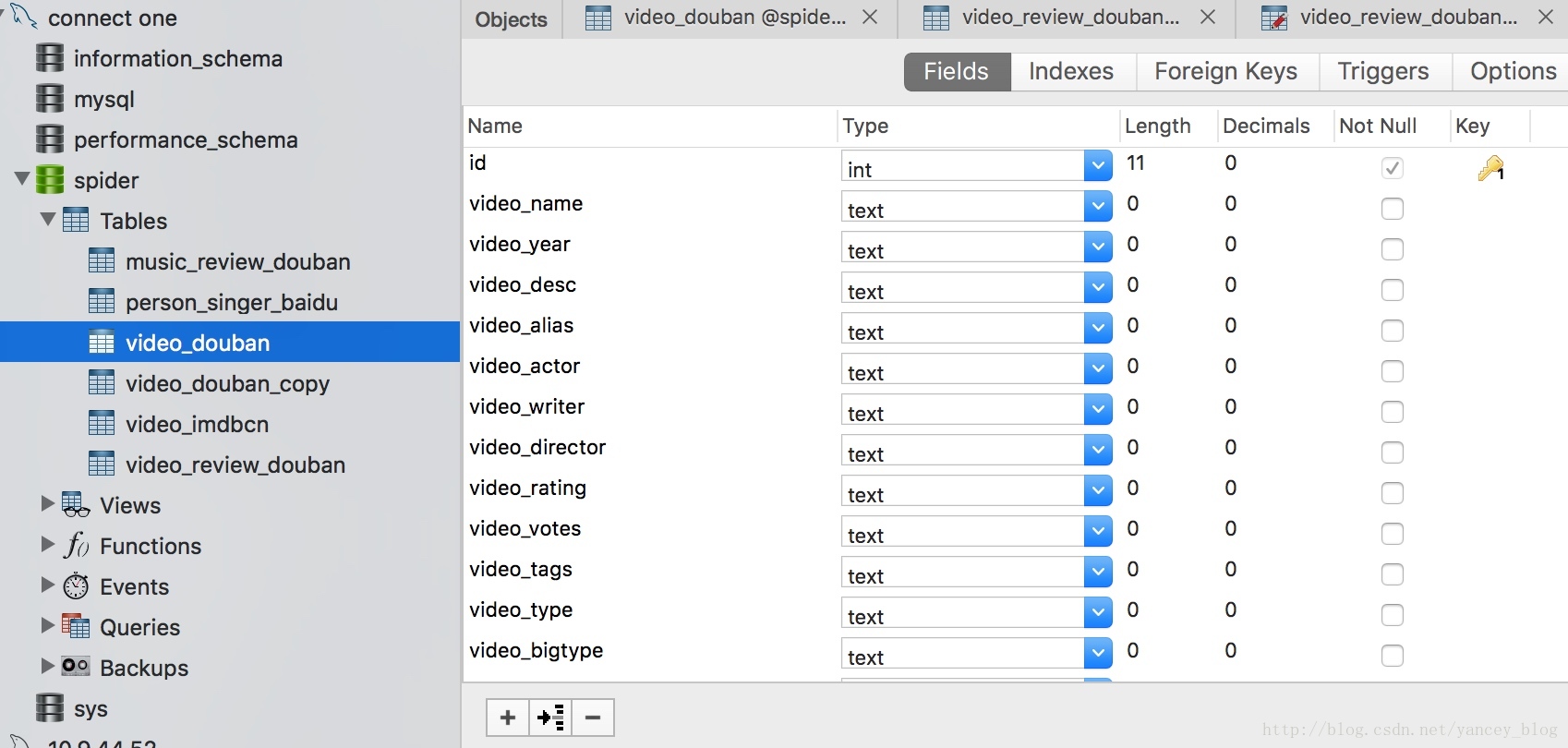
创建项目
安装好PyMysql后就可以在pipeline中处理存储的逻辑了。首先创建项目:scrapy startproject mysql 本例还是使用上一章多个爬虫组合实例的例子,处理将其中四个item存储到mysql数据库。
然后打开创建好的mysql项目,在settings.py中添加数据库连接相关的常量。
# -*- coding: utf-8 -*-
BOT_NAME = 'mysql'
SPIDER_MODULES = ['mysql.spiders']
NEWSPIDER_MODULE = 'mysql.spiders'
MYSQL_HOST = 'localhost'
MYSQL_DBNAME = 'spider'
MYSQL_USER = 'root'
MYSQL_PASSWD = '123456'
DOWNLOAD_DELAY = 1
ITEM_PIPELINES = {
'mysql.pipelines.DoubanPipeline': 301,
}其中ITEM_PIPELINES即是将pipeline加入到配置中生效。
ITEM_PIPELINES = {
'mysql.pipelines.DoubanPipeline': 301,
}pipelines.py配置
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
from scrapy import log
from mysql import settings
from mysql.items import MusicItem, MusicReviewItem, VideoItem, VideoReviewItem
class DoubanPipeline(object):
def __init__(self):
self.connect = pymysql.connect(
host=settings.MYSQL_HOST,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8',
use_unicode=True)
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
if item.__class__ == MusicItem:
try:
self.cursor.execute("""select * from music_douban where music_url = %s""", item["music_url"])
ret = self.cursor.fetchone()
if ret:
self.cursor.execute(
"""update music_douban set music_name = %s,music_alias = %s,music_singer = %s,
music_time = %s,music_rating = %s,music_votes = %s,music_tags = %s,music_url = %s
where music_url = %s""",
(item['music_name'],
item['music_alias'],
item['music_singer'],
item['music_time'],
item['music_rating'],
item['music_votes'],
item['music_tags'],
item['music_url'],
item['music_url']))
else:
self.cursor.execute(
"""insert into music_douban(music_name,music_alias,music_singer,music_time,music_rating,
music_votes,music_tags,music_url)
value (%s,%s,%s,%s,%s,%s,%s,%s)""",
(item['music_name'],
item['music_alias'],
item['music_singer'],
item['music_time'],
item['music_rating'],
item['music_votes'],
item['music_tags'],
item['music_url']))
self.connect.commit()
except Exception as error:
log(error)
return item
elif item.__class__ == MusicReviewItem:
try:
self.cursor.execute("""select * from music_review_douban where review_url = %s""", item["review_url"])
ret = self.cursor.fetchone()
if ret:
self.cursor.execute(
"""update music_review_douban set review_title = %s,review_content = %s,review_author = %s,
review_music = %s,review_time = %s,review_url = %s
where review_url = %s""",
(item['review_title'],
item['review_content'],
item['review_author'],
item['review_music'],
item['review_time'],
item['review_url'],
item['review_url']))
else:
self.cursor.execute(
"""insert into music_review_douban(review_title,review_content,review_author,review_music,review_time,
review_url)
value (%s,%s,%s,%s,%s,%s)""",
(item['review_title'],
item['review_content'],
item['review_author'],
item['review_music'],
item['review_time'],
item['review_url']))
self.connect.commit()
except Exception as error:
log(error)
return item
elif item.__class__ == VideoItem:
try:
self.cursor.execute("""select * from video_douban where video_url = %s""", item["video_url"])
ret = self.cursor.fetchone()
if ret:
self.cursor.execute(
"""update video_douban set video_name= %s,video_alias= %s,video_actor= %s,video_year= %s,
video_time= %s,video_rating= %s,video_votes= %s,video_tags= %s,video_url= %s,
video_director= %s,video_type= %s,video_bigtype= %s,video_area= %s,video_language= %s,
video_length= %s,video_writer= %s,video_desc= %s,video_episodes= %s where video_url = %s""",
(item['video_name'],
item['video_alias'],
item['video_actor'],
item['video_year'],
item['video_time'],
item['video_rating'],
item['video_votes'],
item['video_tags'],
item['video_url'],
item['video_director'],
item['video_type'],
item['video_bigtype'],
item['video_area'],
item['video_language'],
item['video_length'],
item['video_writer'],
item['video_desc'],
item['video_episodes'],
item['video_url']))
else:
self.cursor.execute(
"""insert into video_douban(video_name,video_alias,video_actor,video_year,video_time,
video_rating,video_votes,video_tags,video_url,video_director,video_type,video_bigtype,
video_area,video_language,video_length,video_writer,video_desc,video_episodes)
value (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)""",
(item['video_name'],
item['video_alias'],
item['video_actor'],
item['video_year'],
item['video_time'],
item['video_rating'],
item['video_votes'],
item['video_tags'],
item['video_url'],
item['video_director'],
item['video_type'],
item['video_bigtype'],
item['video_area'],
item['video_language'],
item['video_length'],
item['video_writer'],
item['video_desc'],
item['video_episodes']))
self.connect.commit()
except Exception as error:
log(error)
return item
elif item.__class__ == VideoReviewItem:
try:
self.cursor.execute("""select * from video_review_douban where review_url = %s""", item["review_url"])
ret = self.cursor.fetchone()
if ret:
self.cursor.execute(
"""update video_review_douban set review_title = %s,review_content = %s,review_author = %s,
review_video = %s,review_time = %s,review_url = %s
where review_url = %s""",
(item['review_title'],
item['review_content'],
item['review_author'],
item['review_video'],
item['review_time'],
item['review_url'],
item['review_url']))
else:
self.cursor.execute(
"""insert into video_review_douban(review_title,review_content,review_author,review_video,review_time,
review_url)
value (%s,%s,%s,%s,%s,%s)""",
(item['review_title'],
item['review_content'],
item['review_author'],
item['review_video'],
item['review_time'],
item['review_url']))
self.connect.commit()
except Exception as error:
log(error)
return item
else:
pass
在上面的pipeline中我已经做了数据库去重的操作。
运行爬虫
pycharm运行run.py,mysql数据库表中已经存好了我们要的数据。
















 6362
6362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









