







一ML的基类
CvStatModel类
ML模块的抽象基类
1>CvStatModel::save
将模型保存到文件
void CvStatModel::save(const char* filename,
const char* name=0 )
//将整个模型状态通过指定的名称或者默认名称(取决于特定的类),保存到
//XML/YML文件 2>CvStatModel::load
从文件加载模型
void CvStatModel::load(const char* filename,
const char* name=0 )
//通过指定文件的指定名称或者默认名称,重新加载模型 3>CvStatModel::write
将模型写到file storage
void CvStatModel::write(CvFileStorage* storage,
const char* name)
//将模型以指定名称写到storage 4>CvStatModel::read
从file storage的指定node加载模型
void CvStatModel::read(CvFileStorage* storage,
CvFileNode* node)
//从指定结点读取模型状态 5>CvStatModel::train
训练模型
bool CvStatModel::train(const Mat& train_data,
[int tflag,] ...,
const Mat& responses, ...,
[const Mat& var_idx,] ...,
[const Mat& sample_idx,] ...
[const Mat& var_type,] ...,
[const Mat& missing_mask,])
/*利用输入的特征向量和响应值来训练统计模型,特征向量被保存在
*train_data中,必须为CV_32FC1
*tflag=CV_ROW_SAMPLE,表示特征向量以行向量存储
*tflag=CV_COL_SAMPLE,表示特征向量以列向量存储
*responses,响应数据,以一个行向量或者一个列向量存储,
*CV_32SC1(分类问题中)或者CV_32FC1,一般情况下,每个输入特征向量
*对应一个值
*对于分类问题,响应值是离散的类别标签,对于回归问题,响应值是被估计
*函数的输出值
*针对两类问题都能处理的算法(var_type):
*CV_VAR_CATEGORICAL,则响应值是离散的类别标签
*CV_VAR_ORDERED(CV_VAR_NUMERICAL)当做回归问题,输出值被排序
*var_idx,sample_idx指定感兴趣的特征和样本,可以为32SC1向量,
*或者8位(8uC1)的使用的特征或者样本的掩码,也可以使用NULL表示全部
*使用
*/6>CvStatModel::predict
预测样本的反应
float CvStatModel::predict(const Mat& sample, ...) const
/*这个函数用来预测一个新样本的响应值(response)。
*在分类问题中,这个函数返回类别编号;在回归问题中,返回函数值。
*输入的样本必须与传给train_data的训练样本同样大小。
*如果训练中使用了var_idx参数,在predict函数中使用跟训练特征一致
*的特征。
*/二支持向量机
是作为寻求最优二分类器的一种技术,被拓展到回归和聚类应用,SVM是一种基于核函数的方法,它通过某些核函数把特征向量映射到高维空间,然后建立一个线性判别函数
SVM就是找出一个能够将某个值最大化的超平面,这个值就是超平面离所有训练样本的最小距离,间隔(margin)
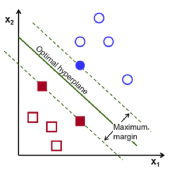
计算最优超平面
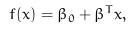
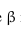
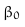
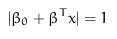
x表示离超平面最近的点
x到超平面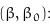
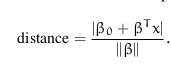
对于典型的超平面(canonical hyperplane),表达式中分子为1
支持向量到canonical hyperplane的距离为:
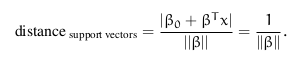
间隔(margin)用M表示,是最近距离的两倍:
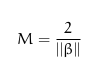
最大化M(利用拉格朗日乘数法,附加条件下最大化函数)
附加条件为,超平面将所有训练样本xi正确分类

1,CvParamGrid类
用于CvSVM的初始化,用于制定训练规范
CvSVMParams::CvSVMParams(int svm_type, int kernel_type,
double degree, double gamma,
double coef0, double Cvalue,
double nu, double p,
CvMat* class_weights,
CvTermCriteria term_crit)
/*svm_type,SVM的类型:
*CvSVM::C_SVC - n(n>=2)分类器,允许用异常值惩罚因子C进行不完
*全分类
* CvSVM::NU_SVC - n类似然不完全分类的分类器。参数nu取代了c,其
* 值在区间[0,1]中,nu越大,决策边界越平滑
*CvSVM::ONE_CLASS - 单分类器,所有的训练数据提取自同一个类里,
*然后SVM建立了一个分界线以分割该类在特征空间中所占区域和其它类在
*特征空间中所占区域
*CvSVM::EPS_SVR - 回归, 训练集中的特征向量和拟合出来的超平面
*的距离需要小于p,异常值惩罚因子C被采用
*CvSVM::NU_SVR - 回归;nu 代替了p
*kernel_type核类型:
*CvSVM::LINEAR - 没有任何向映射至高维空间,线性区分(或回归)在
*原始特征空间中被完成,这是最快的选择。 d(x,y) = x•y == (x,y)
*CvSVM::POLY - 多项式核: d(x,y) = (gamma*(x•y)+coef0)degree
*CvSVM::RBF - 径向基,对于大多数情况都是一个较好的选择:
*d(x,y) = exp(-gamma*|x-y|2)
*CvSVM::SIGMOID - sigmoid函数被用作核函数:
*d(x,y) = tanh(gamma*(x•y)+coef0)
*degree, gamma, coef0:都是核函数的参数
*C, nu, p:在一般的SVM优化求解时的参数
*class_weights:可选权重,赋给指定的类别。一般乘以C以后去影响不同
*类别的错误分类惩罚项。权重越大,某一类别的误分类数据的惩罚项就越
*大
*term_crit:SVM的迭代训练过程的中止
*/2,CvParamGrid类
用于CvSVM精度的规定
CvParamGrid::CvParamGrid(double min_val, double max_val,
double log_step)
//min_val,statmodel的最小值
//max_val,statmodel的最大值
//log_step迭代次数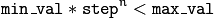
step>1
3,CvSVM类
支持向量机
1>CvSVM::train
继承CvStatModel::train,但有以下限制:
[1]CV_ROW_SAMPLE,只支持特征向量以行存储
[2]输入变量均有效
[3]输出变量要么被分类(params.svm_type=CvSVM::C_SVC/ params.svm_type=CvSVM::NU_SVC),或者有序(params.svm_type=CvSVM::EPS_SVR/ params.svm_type=CvSVM::NU_SVR),
或者不要求(params.svm_type=CvSVM::ONE_CLASS)
[4]不支持掩码
2>CvSVM::train_auto
会自动优化参数
[1]k_fold,交叉验证参数,训练集被分成k_fold个子集,一个用来测试,一个用来验证,SVM算法会被执行k_fold次
[2]balanced,if true 并且问题是2分类问题,则会创建更加平衡的交叉验证参数
3>CvSVM::predict
预测输入样本的响应
float CvSVM::predict(const Mat& sample,
bool returnDFVal=false ) const
//returnDFVal,if true并且是二分类问题,该方法返回间隔(margin)
//的长度,否则返回类标签(分类问题)或者估计的函数值(回归问题) 应用:
//定义训练数据
//labels为分类标记,1为一组,-1为一组
float labels[4] = {1.0, -1.0, -1.0, -1.0};
Mat labelsMat(4, 1, CV_32FC1, labels);
//训练的向量,是四个点的坐标
float trainingData[4][2] =
{ {501, 10}, {255, 10}, {501, 255}, {10, 501} };
Mat trainingDataMat(4, 2, CV_32FC1, trainingData);
//设定SVM的参数
CvSVMParams params;
params.svm_type = CvSVM::C_SVC;
params.kernel_type = CvSVM::LINEAR;
params.term_crit =
cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6);
//进行训练,训练完成之后SVM已经对Mat进行区域划分
CvSVM SVM;
SVM.train(trainingDataMat, labelsMat, Mat(), Mat(), params);
//进行结果的绘制
int width = 512, height = 512;
Mat image = Mat::zeros(height, width, CV_8UC3);
Vec3b green(0,255,0), blue (255,0,0);
for (int i = 0; i < image.rows; ++i)
for (int j = 0; j < image.cols; ++j)
{
Mat sampleMat = (Mat_<float>(1,2) << j,i);
//根据每个点的坐标,进行判断在哪个区域
float response = SVM.predict(sampleMat);
if (response == 1)
image.at<Vec3b>(i,j) = green;
else if (response == -1)
image.at<Vec3b>(i,j) = blue;
} 效果图:
















 3479
3479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









