







Python如何爬取《王者荣耀盒子》APP
1.安装fiddler
百度网盘下载链接:https://pan.baidu.com/s/1EjGfVrYpAaweitUxv7DS8w
提取码:q2kj
傻瓜式安装,一键到底。Fiddler软件界面如图所示:

2.Fiddler设置
打开fiddler软件,点击Tools->Opyion…

如图操作

在Connections中设置如下,这里使用默认8888端口,当然也可以自己更改,但是注意不要与已经使用的端口冲突

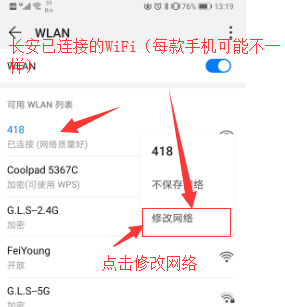
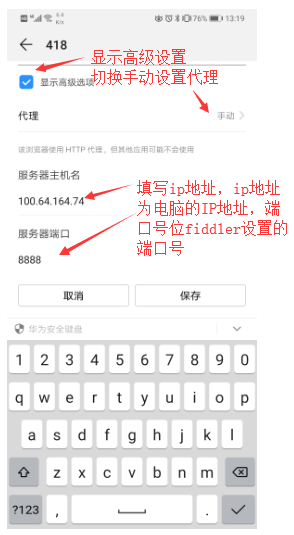
3.设置手机WiFi代理
查看电脑IP:桌面—>Windows键+R—>cmd—>ipconfig(例如:ip为:192.168.1.14)
手机——>设置——>WiFi设置——>长按出现修改网络——>代理——>手动——>输入ip地址和端口号——>确定
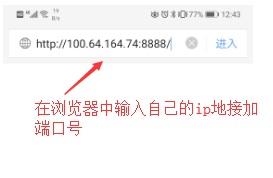
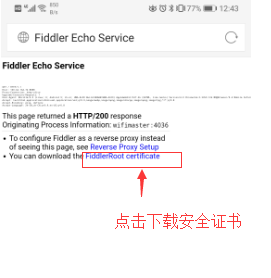
点击“FidderRoot certificate”,安装证书
设置完成之后,Fidder就可以抓取手机app上的https请求了(有时候可能抓不到请求,此时一般需要你重启fidder)
4.抓取王者荣耀盒子app
在浏览器中下载:王者荣耀盒子app、

获取所有英雄图片:
![]](https://img-blog.csdnimg.cn/20190710162613782.png)

有时候获取到的内容太多不易查找,所以要先清除一下获取到的内容:


获取所有装备:


获取英雄的攻略:

上面只是一个英雄的攻略,要想湖区所有的英雄攻略就要找出他们的规律出来:

完整代码:
#-*- coding: UTF-8 -*-
from urllib.request import urlretrieve
import requests
import json
import os
'''
下载英雄图片
打印硬性id 和name 以便于查找
'''
def download_img(url,headers):
#GET请求
r = requests.get(url=url, headers = headers)
#获取网页的json文件
r=r.json()
#len 对象的长度
length = len(r['list'])
print("一共有%d英雄" % length)
#文件夹名
hero_images_path = 'img'
i = 0
# 在r['lisr']列表中查找img_url(图片链接)
for img in r['list']:
img_url = img['cover']
# img_name(每张图片的名字)
img_name = img['name']+'.jpg'
# hero_id(英雄id:英雄名字)
hero_id = img['hero_id']+':'+img['name']
# 图片存储的路径
filename = hero_images_path + '/' + img_name
#判断文件夹是否存在,不存在就创建该文件夹
if hero_images_path not in os.listdir():
os.makedirs(hero_images_path)
#下在图片,存在img文件夹中
urlretrieve(url=img_url, filename=filename)
#输出每个英雄的hero_id(英雄id:英雄名字)
print('%s' % hero_id, end=' ')
i += 1
#每行输出9个英雄 换行
if i == 9:
i = 0
print()
print('\n图片在当前路径下的%s文件夹中\n下载完毕\n'%hero_images_path)
'''
函数功能:返回网页中的所有装备信息json文件
参数:url (请求网址) headers(模拟请求头)
'''
def equip_json(url ,headers):
#请求网页
r = requests.get(url=url,headers=headers)
#获取网页json文件
r = r.json()
#r['list'] 所有装备信息
equip_choice = r['list'] #equip_choice 是一个list类型
#print(equip_choice)
return equip_choice
'''
函数功能:返回装备equip_name(名字)、equip_price(价格)
参数: equip_id (装备的id号)
equip_choice_json (装备的json文件)
返回: equip_name (装备的名字)
equip_price (每件装备的价格)
'''
def equipment(equip_id ,equip_choice_json):
for equip in equip_choice_json :
if equip['equip_id'] == str(equip_id):
equip_name = equip['name']
equip_price = equip['price']
#print("根据id查找装备的名字和价格:id=%s equip_name=%s equip_price=%s"%(equip['equip_id'], equip_name,equip_price))
return equip_name, equip_price
'''
函数功能:1、打印查找的英雄历史
2、打印查找英雄的出装
3、计算出装总价格
4、打印查找英雄的推荐铭文
参数:url (网页地址)
headers(模拟请求头)
equip_choice_json(装备json文件)
'''
def strategy(url , headers, equip_choice_json):
r = requests.get(url, headers=headers).json()
# print(type(r['info']['rec_inscriptions']))
if r['info']['history_intro'] != '':
print('\n历史上的%s:\n %s' % (r['info']['name'], r['info']['history_intro']))
else:
print('\n历史上的%s:\n 没有历史' % r['info']['name'])
for equip_choice in r['info']['equip_choice']:
money = 0
print('%s:\n%s'%(equip_choice['title'],equip_choice['description']))
for list in equip_choice['list']:
equip_name ,equip_price = equipment(list['equip_id'],equip_choice_json)
print("%s:%s"%(equip_name,equip_price),end='')
money += int(equip_price)
print("\n神装价格一共为:%d金币"%money+'\n')
for rec_inscriptions in r['info']['rec_inscriptions']:
print('铭文推荐%s:' % rec_inscriptions['title'])
for list_1 in rec_inscriptions['list']:
name = list_1['name']
print('%s ' % name, end='')
print()
if __name__ == "__main__":
#模拟请求头
headers = {
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'okhttp/3.11.0'
}
#英雄地址
url = 'http://gamehelper.gm825.com/wzry/hero/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=13.0.1.0&version_code=13010&cuid=28AF0114144CEBEF577E60622E5B9D90&ovr=9&device=HUAWEI_HMA-AL00&net_type=1&client_id=F3is9CPoJWGAMNlY%2FwrL4w%3D%3D&info_ms=vhinK9v9nL60DJGTepQm3A%3D%3D&info_ma=HK7m8s3VEYDi%2B2YwvnyAaC4mdmxZg6Ax6%2BxsUAXEJjc%3D&mno=0&info_la=Eokw0W4dZv%2FPSWvIaPYoQQ%3D%3D&info_ci=Eokw0W4dZv%2FPSWvIaPYoQQ%3D%3D&mcc=0&clientversion=13.0.1.0&bssid=HK7m8s3VEYDi%2B2YwvnyAaC4mdmxZg6Ax6%2BxsUAXEJjc%3D&os_level=28&os_id=a61208690da35eb1&resolution=1080_2163&dpi=480&client_ip=192.168.155.2&pdunid=66J5T19119000998'
# print(r.text, r.encoding)
#装备地址
url_equip = 'http://gamehelper.gm825.com/wzry/equip/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=13.0.1.0&version_code=13010&cuid=28AF0114144CEBEF577E60622E5B9D90&ovr=9&device=HUAWEI_HMA-AL00&net_type=1&client_id=F3is9CPoJWGAMNlY%2FwrL4w%3D%3D&info_ms=vhinK9v9nL60DJGTepQm3A%3D%3D&info_ma=HK7m8s3VEYDi%2B2YwvnyAaC4mdmxZg6Ax6%2BxsUAXEJjc%3D&mno=0&info_la=Eokw0W4dZv%2FPSWvIaPYoQQ%3D%3D&info_ci=Eokw0W4dZv%2FPSWvIaPYoQQ%3D%3D&mcc=0&clientversion=13.0.1.0&bssid=HK7m8s3VEYDi%2B2YwvnyAaC4mdmxZg6Ax6%2BxsUAXEJjc%3D&os_level=28&os_id=a61208690da35eb1&resolution=1080_2163&dpi=480&client_ip=192.168.155.2&pdunid=66J5T19119000998'
#下载英雄图片
download_img(url,headers)
hero_id = input("请输入要查找英雄id:")
# 攻略地址 + hero_id
url_strategy = 'http://gamehelper.gm825.com/wzry/hero/detail?hero_id='+hero_id+'&channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=13.0.1.0&version_code=13010&cuid=28AF0114144CEBEF577E60622E5B9D90&ovr=9&device=HUAWEI_HMA-AL00&net_type=1&client_id=F3is9CPoJWGAMNlY%2FwrL4w%3D%3D&info_ms=vhinK9v9nL60DJGTepQm3A%3D%3D&info_ma=HK7m8s3VEYDi%2B2YwvnyAaC4mdmxZg6Ax6%2BxsUAXEJjc%3D&mno=0&info_la=Eokw0W4dZv%2FPSWvIaPYoQQ%3D%3D&info_ci=Eokw0W4dZv%2FPSWvIaPYoQQ%3D%3D&mcc=0&clientversion=13.0.1.0&bssid=HK7m8s3VEYDi%2B2YwvnyAaC4mdmxZg6Ax6%2BxsUAXEJjc%3D&os_level=28&os_id=a61208690da35eb1&resolution=1080_2163&dpi=480&client_ip=192.168.155.2&pdunid=66J5T19119000998'
# 获取装备文件
equip_choice_json = equip_json(url_equip,headers)
strategy(url_strategy , headers, equip_choice_json)
#os.system("pause")















 8134
8134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









