




 本文介绍文本相似度计算的两种常见方法:Jaccard系数和余弦相似度,通过实验对比分析了这两种方法在衡量文本相似度上的性能差异。
本文介绍文本相似度计算的两种常见方法:Jaccard系数和余弦相似度,通过实验对比分析了这两种方法在衡量文本相似度上的性能差异。
基础知识
文本相似度计算是把文本投影到向量空间,文本的相似度是把文本投影到向量空间,用向量相似度来表示语义相似度,通过比较计算向量的空间距离来比较文本的相似度。
Jaccard系数
Jaccard系数是计算两个集合重合度的常用方法:两个集合A和B交集元素的个数在A、B并集中所占的比例,称为这两个集合的Jaccard系数,用符号 J(A,B) 表示。Jaccard系数是衡量两个集合相似度的一种指标,公式如下:
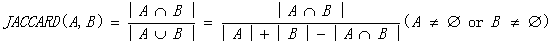
其中,A,B集合中的元素为是文本中的全部词项,且集合中相同词项只保留一个。
余弦相似度
余弦相似度,是通过计算两个向量的夹角余弦值来评估向量间的相似度。将向量根据坐标映射到向量空间。求得他们的夹角,并得出夹角对应的余弦值,余弦值就可以用来表示这两个向量的相似性。
夹角越小,余弦值越接近于1,它们的方向更加吻合,则越相似。两个向量A,B之间的余弦相似度计算公式如下:
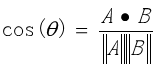
计算文本之间的余弦相似度时,首先要对文本分词、去除停用词,构建所有文本的词袋,然后计算文本词项的tf-idf值,接着利用词袋模型将每个文本都映射到统一的向量空间中,向量的坐标值就是对应的特征词项的tf-idf值。
实验内容
- 选定3个文本:doc1,doc2,doc3,其中doc1和doc2是两篇关于“机器学习”的介绍,doc3是1篇人大会议报道。
- 计算上述3个文档之间的Jaccard系数矩阵(行列为文档,元素值为两个文档之间的系数值)。
- 利用向量空间模型计算词项-文档关联矩阵,并计算3个文档之间余弦相似度矩阵(行列为文档,元素值为两个文档之间的相似度值)。
- 对比分析Jaccard系数和余弦相似度的性能。
步骤
- 获取停用词表,文本分词
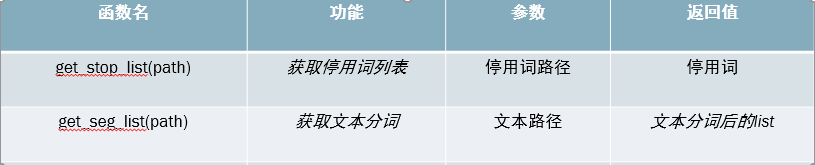
这一步是自然语言处理的基本操作,代码略。 - 获取去停用词后的词典

def get_dic(text_list, stop_words_list):
dic = {
}
for myword in text_list:
if not (myword.strip() in stop_words_list):
dic.setdefault(myword, 0)
dic[myword] += 1
return dic
dic为该文本去除停用词之后的词典,键是文本中的词,值是这个词出现的频数
- 计算余弦相似度
首先,调用步骤1中的函数,清洗文本,获取全部词项
def get_cos 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









