







1)没有标签的图像语义如何提取
2)端到端的对齐过程如何构建,具体损失函数是什么
3)attention如何加入,双端反馈如何建立联系,attention训练过程的损失函数是什么
1: Karpathy A, Fei-Fei L. Deep Visual-Semantic Alignments for Generating Image Descriptions.
IEEE Trans Pattern Anal Mach Intell. 2017 Apr;39(4):664-676.
面向图像自动语句标注的注意力反馈模型
摘要
这篇文章的作者提出了一种方法,可以用于生成图像的自然语言描述。
主要包含了两个部分:
(1)视觉语义的对齐模型;
(2)为新图像生成文本描述的 Multimodal RNN 模型。
其中视觉语义的对齐模型主要由3部分组成:
- 应用于图像区域的卷积神经网络(Convolution Neural Networks)。
- 应用于语句的双向循环神经网络(bidirectional Recurrent Neural Networks)。
- 结构化的目标函数,通过多模态嵌入来对齐视觉与语义。
概述
图片的描述语句通常仅提到“有什么”,而不知道“在哪里”,所以作者提出将 imgae caption 数据集的描述语句看作 弱标签(weak labels),这些语句中有一些单词,对应了图片中一些特殊但位置未知的物体,那么我们就想如何 “对齐” 这些单词和物体(就像做连线题一样),然后再学习如何生成描述。
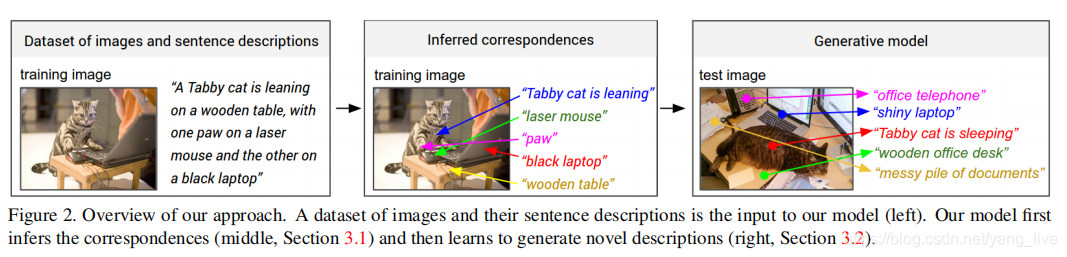
- 图像数据和其对应的语句描述作为模型的输入(左图)
- 模型学习推理子图像区域和其对应的语句片段(中图)
- 最后模型学习为图像生成一些描述语句(右图)
第一个模型对齐模型是第二个模型生成模型的准备工作,第二个模型在第一个模型推测出的对应关系上进行训练。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1327
1327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









