







Fibonacci数的定义如下:

在Java中,该算法的非常好容易实现
public static long fibonacci(int x) {
if(x==0 || x==1)
return x;
return fibonacci(x-1) + fibonacci(x-2);
}
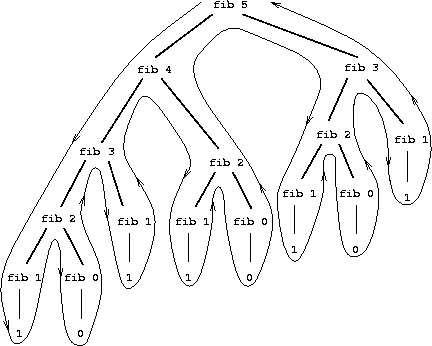
从上图可知,该算法存在严重的重复计算。
但是在Java8中,利用其两个新特性,可以优化该算法。
思路如下:
上面算法最严重的问题就是存在太多的重复计算,因此我们可以使用内存来尽量规避这个问题,也就是说,提供一种缓存结果的机制来规避重复计算。
在Java中,可以将Fibonacci数缓存在哈希表或者Map中,这样只需要最左边分支使用递归来计算,并将计算结果缓存到Map中,所有的右边分支只需到哈希表中查询,
在哈希表中找到中的正确结果返回即可,不需要再次计算。
在Java8给Map增加了一些新方法,简化了上面这个思路的实现,比如computeIfAbsent(key, function),该函数key可以为需要计算的数字,而function为一个能够递归计算Fibonacci数的lambda表达式,如果key对应的Fibonacci数不在map中,则该lambda表达式能够正确的计算出Fibonacci数
首先要定义一个Map,同时缓存fibonnaci(0) 和 fibonacci(1)的结果
private static Map<Integer,Long> memo = new HashMap<>();
static {
memo.put(0,0L); //fibonacci(0)
memo.put(1,1L); //fibonacci(1)
}public static long fibonacci(int x) {
return memo.computeIfAbsent(x, n -> fibonacci(n-1) + fibonacci(n-2));
}














 256
256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









