






长连接与脑裂的监控
TCP协议中有长连接和短连接之分。短连接在数据包发送完成后就会自己断开,长连接在发包完毕后,会在一定的时间内保持连接,即我们通常所说的Keepalive(存活定时器)功能。
默认的Keepalive超时需要7,200,000 milliseconds,即2小时,探测次数为5次。它的功效和用户自己实现的心跳机制是一样的。开启Keepalive功能需要消耗额外的宽带和流量,尽管这微不足道,但在按流量计费的环境下增加了费用,另一方面,Keepalive设置不合理时可能会因为短暂的网络波动而断开健康的TCP连接。
keepalive并不是TCP规范的一部分。在Host Requirements RFC罗列有不使用它的三个理由:(1)在短暂的故障期间,它们可能引起一个良好连接(good connection)被释放(dropped),(2)它们消费了不必要的宽带,(3)在以数据包计费的互联网上它们(额外)花费金钱。然而,在许多的实现中提供了存活定时器。
一些服务器应用程序可能代表客户端占用资源,它们需要知道客户端主机是否崩溃。存活定时器可以为这些应用程序提供探测服务。Telnet服务器和Rlogin服务器的许多版本都默认提供存活选项。
个人计算机用户使用TCP/IP协议通过Telnet登录一台主机,这是能够说明需要使用存活定时器的一个常用例子。如果某个用户在使用结束时只是关掉了电源,而没有注销(log off),那么他就留下了一个半打开(half-open)的连接。如果客户端消失,留给了服务器端半打开的连接,并且服务器又在等待客户端的数据,那么等待将永远持续下去。存活特征的目的就是在服务器端检测这种半打开连接。
也可以在客户端设置存活器选项,且没有不允许这样做的理由,但通常设置在服务器。如果连接两端都需要探测对方是否消失,那么就可以在两端同时设置(比如NFS)。
keepalive工作原理:
若在一个给定连接上,两小时之内无任何活动,服务器便向客户端发送一个探测段。(我们将在下面的例子中看到探测段的样子。)客户端主机必须是下列四种状态之一:
1)客户端主机依旧活跃(up)运行,并且从服务器可到达。从客户端TCP的正常响应,服务器知道对方仍然活跃。服务器的TCP为接下来的两小时复位存活定时器,如果在这两个小时到期之前,连接上发生应用程序的通信,则定时器重新为往下的两小时复位,并且接着交换数据。
2)客户端已经崩溃,或者已经关闭(down),或者正在重启过程中。在这两种情况下,它的TCP都不会响应。服务器没有收到对其发出探测的响应,并且在75秒之后超时。服务器将总共发送10个这样的探测,每个探测75秒。如果没有收到一个响应,它就认为客户端主机已经关闭并终止连接。
3)客户端曾经崩溃,但已经重启。这种情况下,服务器将会收到对其存活探测的响应,但该响应是一个复位,从而引起服务器对连接的终止。
4)客户端主机活跃运行,但从服务器不可到达。这与状态2类似,因为TCP无法区别它们两个。它所能表明的仅是未收到对其探测的回复。
服务器不必担心客户端主机被关闭然后重启的情况(这里指的是操作员执行的正常关闭,而不是主机的崩溃)。当系统被操作员关闭时,所有的应用程序进程(也就是客户端进程)都将被终止,客户端TCP会在连接上发送一个FIN。收到这个FIN后,服务器TCP向服务器进程报告一个文件结束,以允许服务器检测这种状态。
在第一种状态下,服务器应用程序不知道存活探测是否发生。凡事都是由TCP层处理的,存活探测对应用程序透明,直到后面2,3,4三种状态发生。在这三种状态下,通过服务器的TCP,返回给服务器应用程序错误信息。(通常服务器向网络发出一个读请求,等待客户端的数据。如果存活特征返回一个错误信息,则将该信息作为读操作的返回值返回给服务器。)在状态2,错误信息类似于“连接超时”。状态3则为“连接被对方复位”。第四种状态看起来像连接超时,或者根据是否收到与该连接相关的ICMP错误信息,而可能返回其它的错误信息。
linux内核包含对keepalive的支持。其中使用了三个参数:tcp_keepalive_time(开启keepalive的闲置时 长)tcp_keepalive_intvl(keepalive探测包的发送间隔)和tcp_keepalive_probes(如果对方不予应答,探测包的发送次数);在liunx中,keepalive是一个开关选项,可以通过函数来使能。具体地说,可以使用以下代码:
setsockopt(rs, SOL_SOCKET, SO_KEEPALIVE, (void *)&keepAlive, sizeof(keepAlive));
当tcp检测到对端socket不再可用时(不能发出探测包,或探测包没有收到ACK的响应包),select会返回socket可读,并且在recv时返回-1,同时置上errno为ETIMEDOUT。此时TCP的状态是断开的。
keepalive参数设置代码如下:
// 开启KeepAlive
BOOL bKeepAlive = TRUE;
int nRet = ::setsockopt(socket_handle, SOL_SOCKET, SO_KEEPALIVE, (char*)&bKeepAlive, sizeof(bKeepAlive));
if (nRet == SOCKET_ERROR)
{
return FALSE;
}
// 设置KeepAlive参数
tcp_keepalive alive_in = {0};
tcp_keepalive alive_out = {0};
alive_in.keepalivetime =5000; // 开始首次KeepAlive探测前的TCP空闭时间
alive_in.keepaliveinterval =1000; // 两次KeepAlive探测间的时间间隔
alive_in.onoff = TRUE;
unsigned long ulBytesReturn =0;
nRet = WSAIoctl(socket_handle, SIO_KEEPALIVE_VALS, &alive_in, sizeof(alive_in),
&alive_out, sizeof(alive_out), &ulBytesReturn, NULL, NULL);
if (nRet == SOCKET_ERROR)
{
return FALSE;
}
开启Keepalive选项之后,对于使用IOCP模型的服务器端程序来说,一旦检测到连接断开,GetQueuedCompletionStatus函 数将立即返回FALSE,使得服务器端能及时清除该连接、释放该连接相关的资源。对于使用select模型的客户端来说,连接断开被探测到时,以recv 目的阻塞在socket上的select方法将立即返回SOCKET_ERROR,从而得知连接已失效,客户端程序便有机会及时执行清除工作、提醒用户或 重新连接。
TCP连接非正常断开的检测(KeepAlive探测)
此处的”非正常断开”指TCP连接不是以优雅的方式断开,如网线故障等物理链路的原因,还有突然主机断电等原因
有两种方法可以检测:1.TCP连接双方定时发握手消息2.利用TCP协议栈中的KeepAlive探测
第二种方法简单可靠,只需对TCP连接两个Socket设定KeepAlive探测。
在windows下使用,要包含MSTcpIP.h的头文件。点击下面的链接即可下载这个文件
MSTcpIP
备注:长连接虽好,但是比较好用但是占用系统资源比较大。个人建议如无特殊需要,用自己的心跳包机制最好
脑裂
简介
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果——或者共享资源被瓜分、2边“服务”都起不来了;或者2边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)。
对付HA系统“裂脑”的对策,目前达成共识的的大概有以下几条:
添加冗余的心跳线,例如:双线条线(心跳线也HA),尽量减少“裂脑”发生几率;
启用磁盘锁。正在服务一方锁住共享磁盘,“裂脑”发生时,让对方完全“抢不走”共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动“解锁”,另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了“智能”锁。即:正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
设置仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端。不仅“心跳”、还兼对外“服务”的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源
脑裂产生的原因
一般来说,脑裂的发生,有以下几种原因:
高可用服务器对之间心跳线链路发生故障,导致无法正常通信
因心跳线坏了(包括断了,老化)
因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)
因心跳线间连接的设备故障(网卡及交换机)
因仲裁的机器出问题(采用仲裁的方案)
高可用服务器上开启了 iptables防火墙阻挡了心跳消息传输
高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败
其他服务配置不当等原因,如心跳方式不同,心跳广插冲突、软件Bug等
注意:
Keepalived配置里同一 VRRP实例如果 virtual_router_id两端参数配置不一致也会导致裂脑问题发生。
脑裂的常见解决方案
在实际生产环境中,我们可以从以下几个方面来防止裂脑问题的发生:
同时使用串行电缆和以太网电缆连接,同时用两条心跳线路,这样一条线路坏了,另一个还是好的,依然能传送心跳消息
当检测到裂脑时强行关闭一个心跳节点(这个功能需特殊设备支持,如Stonith、feyce)。相当于备节点接收不到心跳消患,通过单独的线路发送关机命令关闭主节点的电源
做好对裂脑的监控报警(如邮件及手机短信等或值班).在问题发生时人为第一时间介入仲裁,降低损失。例如,百度的监控报警短信就有上行和下行的区别。报警消息发送到管理员手机上,管理员可以通过手机回复对应数字或简单的字符串操作返回给服务器.让服务器根据指令自动处理相应故障,这样解决故障的时间更短.
当然,在实施高可用方案时,要根据业务实际需求确定是否能容忍这样的损失。对于一般的网站常规业务.这个损失是可容忍的
zabbix脑裂监控
监控备上有无VIP地址
备机上出现VIP有两种情况:
发生了脑裂
正常的主备切换
监控脚本
[root@localhost ~]# cat /scripts/echeck_keepalived.sh
#!/bin/bash
if [ `ip a show ens33 |grep 192.168.101.250|wc -l` -ne 0 ]
then
echo 0
else
echo 1
fi
//修改配置文件
[root@localhost ~]# vim /usr/local/etc/zabbix_agentd.conf
UserParameter=check_log,/scripts/echeck_keepalived.sh
//重启zabbix
[root@localhost ~]# pkill zabbix_agentd
[root@localhost ~]# zabbix_agentd
添加监控项
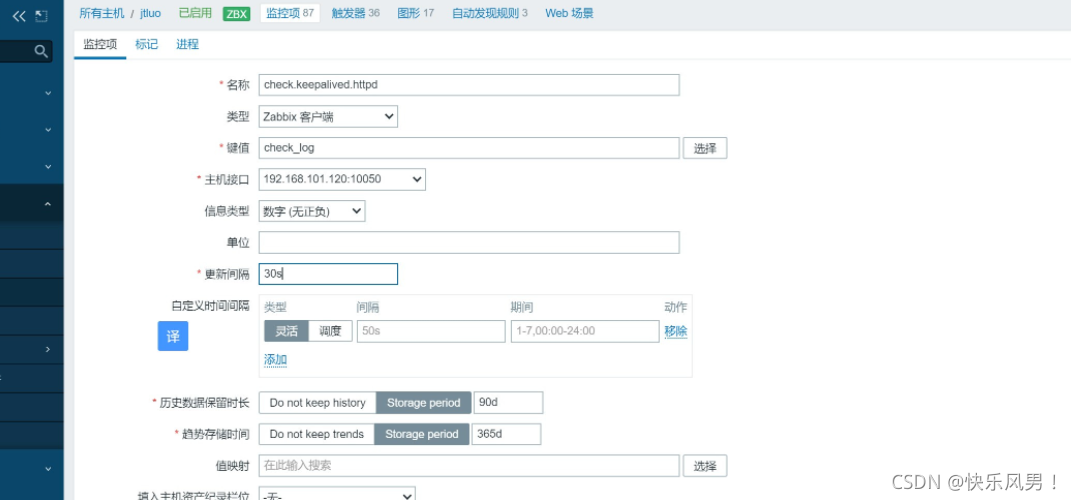
创建触发器
















 8211
8211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









