



 本文详细介绍了Python的requests库如何发起HTTP请求,包括GET和POST方法的使用,以及如何处理JSON格式的响应数据。对于POST请求,演示了表单数据和JSON数据的提交方式,并强调了参数的正确格式。在响应处理部分,讲解了如何对JSON响应进行序列化和反序列化操作,以及如何避免处理空响应时的错误。最后,提供了一个基础模板,展示了如何在实际工作中发送请求并处理返回结果。
本文详细介绍了Python的requests库如何发起HTTP请求,包括GET和POST方法的使用,以及如何处理JSON格式的响应数据。对于POST请求,演示了表单数据和JSON数据的提交方式,并强调了参数的正确格式。在响应处理部分,讲解了如何对JSON响应进行序列化和反序列化操作,以及如何避免处理空响应时的错误。最后,提供了一个基础模板,展示了如何在实际工作中发送请求并处理返回结果。
一. request库的请求:
#1. 导入模块
import requests
#2. 请求格式:
request.get(url, params, kwargs)
request.post(url, data, json, kwargs)
#3. 发送post 请求,参数:
表单: (x-www-form-urlencoded)
json: (application/json)
#表单方式的post请求(x-www-form-urlencoded)
import requests
url = "https://editor.net/"
data = {"key": "value"} # 字典 外层无引号
resp = requests.post(url,data=data)
print(resp.text)
#json类型的post请求
import requests
url = "https://editor.net/"
data1 = '{"key": "value"}' # json字符串格式
resp = requests.post(url, data=data1)
data2 = {"key": "value"}
# 将字典格式的data数据赋给post方法的json参数
resp = requests.post(url, json=data2)
print(resp.text)
#4. post参数:
data参数:支持字典格式(表单)和json字符串格式;(json字符串可使用json.dumps()生成)
json参数:必须为合法json格式,否则没用,如果有布尔值要小写,不能有非Unicode字符。
#使用字典格式填写参数,传递时转换为json格式
import requests
import json
url = "https://editor.net/"
data = {"key": "value"}
resp = requests.post(url, data=json.dumps(data))
print(resp.text)
import requests
import json
url = "https://editor.net/"
data = {"key": "value"}
resp = requests.post(url, json=data)
print(resp.text)
一. 使用Python的requests库请求——响应结果处理
在实际工作中,很多接口的响应都是json格式的数据,需要对其进行处理和分析。涉及到json数据处理的方法有两种:序列化和反序列化:
python中 序列化——将python的字典转换成json格式字符串,以便进行储存或者传输;
反序列化——将json格式字符串转换成python字典,用于对其进行分析和处理。
JSON和DICT格式互转方法:
import json
# 序列化成json字符串
d = {‘name':‘jod'}
j = json.dumps(d)
#反序列化成字典
print json.loads(j)而在requests库中,不用json.loads方法进行反序列化,而是提供了响应对象的json方法,用来对json格式的响应体进行反序列化:
r = requests.get(url)
r.json()
二. requests库返回的数据有两种方法可以处理:
1.对requests发起请求返回的响应对象进行.json()操作,.json操作返回的是一个字典类型(如果返回的结果为空时则会报错),如下: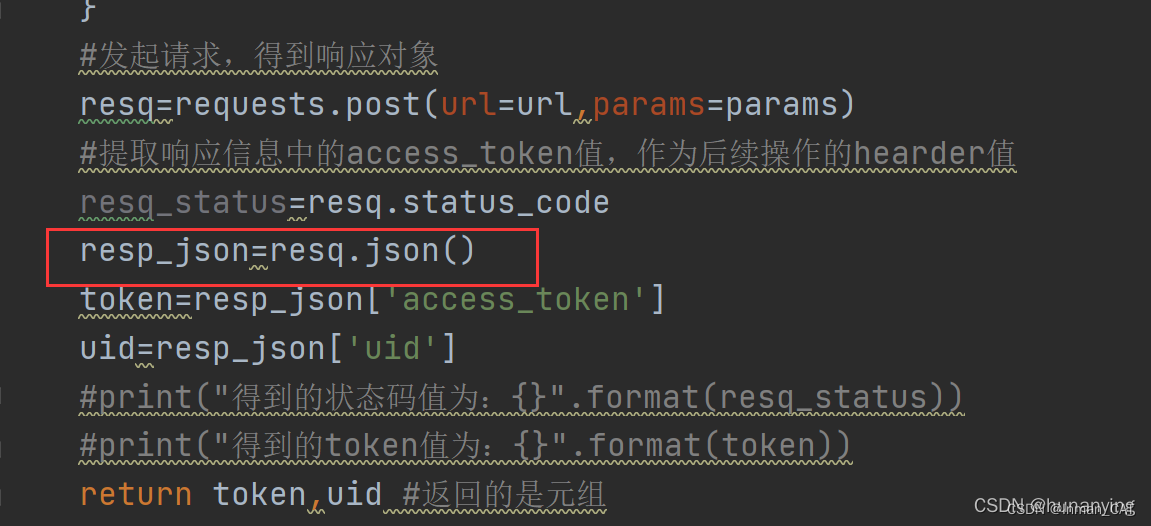
2.对requests请求得到的响应对象中的text数据进行json.loads(text)操作,操作后返回的是字典类型(建议使用这种方法,使用前判断text是否为空,为空也会报错),如下:
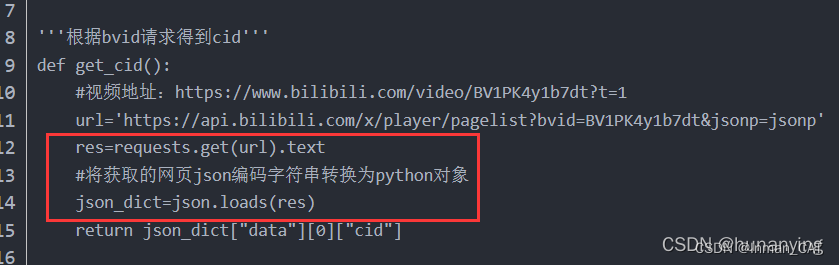
# response.json()方法 同 json.loads(response.text)
三. 使用requests发送请求并处理返回的结果--基础模板
import requests
import json# 以get方法进行请求,可以直接把参数附在后面,也可以传入参数进行
response=requests.get(f"http://XXXXX/anyq?question={question}")
param={"question":question}
res = requests.get(url='https://b.faloo.com/l/0/1.html',params=param)
# 这里形参为params
# 如果是post,可以以data形式作为参数进行
params = {"username": self.username,"email": self.email, "password": self.password}
response = requests.post(request_url, data=params)response = requests.post(request_url, json=params)
# 这里形参为data# 需要传json类型参数,使用json 参数
# 如果返回的数据是unicode编码,例如
(python3将字符串unicode转换为中文)
"""
"answer\":\"\u8bb2\u8bdd\u4ea4\u6d41\u6700\u5c11\u76f8\u96941\u7c73\uff0c\u6700\u597d2\u7c73\u3002
\u4e00\u822c\u60c5\u51b5\u4e0b\uff0c\u98de\u6cab\u4f20\u64ad\u53ea\u6709\u4e0e\u4f20\u67d3\u6
e90\u8fd1\u8ddd\u79bb\u63a5\u89e6\u65f6\u624d\u53ef\u80fd\u5b9e\u73b0\u3002\u98de\u6cab
"""# 参考 https://www.cnblogs.com/573734817pc/p/10855147.html 进行解码
decode_rs=response.text.encode("utf-8").decode('unicode_escape')# 如果以json格式返回,直接使用json解析; 或者text- json.loads() 进行处理
json_rs=response.json()
print(json_rs)

















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









