





摘要:卷积神经网络在单幅图像去雾任务中取得了显著的成功。遗憾的是,现有的深度去雾模型计算复杂度高,难以应用于高分辨率图像,特别是UHD或4K分辨率的图像。为了解决这一问题,我们提出了一种新的网络,能够在单个GPU上实现4K图像的实时去雾,该网络由三个深度CNN组成。首先CNN以降低的朦胧输入分辨率提取与雾相关的特征,然后在双边空间中拟合局部仿射模型。另一个CNN用于学习多个全分辨率导航图对应的双边模型。因此,通过多导双侧上采样可以重建高频特征图。最后,第三个CNN将高质量的特征映射融合成去雾图像。此外,我们创建了一个大规模的4K图像去雾数据集,以支持对比较模型的训练和测试。实验结果表明,该算法在不同的基准测试条件下都能取得较好的去雾效果。
1.主要贡献
提出了一种多向导双边学习的4K分辨率图像去雾框架,能够以125帧/秒的速度处理4K (3840 × 2160)分辨率的图像。我们部署边缘感知模块,调整双边仿射网格应用于多导矩阵,从不同的颜色通道恢复高质量的特征。该方法能够从朦胧输入中生成更多的边缘和高频细节。我们建立了一个大的、高质量的4K图像数据集,用于图像去雾。在合成图像和真实图像上的实验结果表明,该算法在任意空间输入大小下都能取得较好的效果。
2.去雾模型
给定一个4K分辨率的模糊输入,我们的网络首先使用一个特征提取块在降低的输入分辨率上重建双边系数。利用回归仿射双边网格,在全分辨率特征的指导下生成高质量的特征图。此外,为了提供更丰富的颜色和边缘信息,我们考虑了所有的RGB通道,这样去雾网络可以更好地恢复细节。图2展示了提出的4K分辨率图像去雾网络的体系结构,该网络包括两个分支:低分辨率特征提取和仿射双边网格学习和全分辨率去雾分支。

图2:本文提出的单图像去雾方法的结构和配置,包括三个部分。第一步从低分辨率系数预测流开始,该流使用特征提取块和下采样层来拟合仿射双边网格。然后利用三个制导矩阵和仿射双边网格插值得到不同的高质量特征。最后,该特征融合块将三种高质量特征与全分辨率输入作为四种异构数据进行融合,得到去雾结果。
2.1双边网格学习
由于模糊输入的对比度和可见性的降低,两个像素在一周边缘的空间维是接近的。但是,这两个像素点距离双边滤波器的角度很远,因为它们的值在范围维上相差很大。因此,我们考虑预测仿射双边模型,通过在双边空间上拟合三维仿射函数阵列(即不同强度范围拟合不同的仿射函数)来恢复清晰的图像结构和边缘。首先,我们将4K朦胧输入减少到固定分辨率910 × 512,通过两个卷积块提取底层特征,然后提取一个平均池化层,如图2所示。这将生成一个32 × 56 × 3的特征映射F数组,其中包含丰富的输入模式。然后,我们学习一个仿射双边网格,其中每个坐标都是用第三维(即特征地图F的像素强度的函数)扩充到场景结构。在这种解释下,F可以看作是一个7 × 8 × 8的双边网格,每个网格单元包含12个数字,每个数字代表一个3 × 4仿射变换矩阵的每个系数。具体地说,我们把低分辨率特征F看成一个第三维展开的多通道双边网格B: Bd[x ', y ', c ']↔[x, y, c](1),其中[x ' =7, y ' =8, c ' =8]表示双边网格单元的坐标,每个单元有d=12个数字。[x=32, y=56, c=3]分别对应特征映射 F的高度、宽度和通道。该操作比传统的双边网格更有表现力,后者将退化的输入离散成几个强度箱,然后对结果进行框滤。
2.2高质量特征重建
利用低分辨率分支预测的双边网格系数B,我们现在需要将该信息传输回原始输入的全分辨率空间,以产生高质量的去雾特征。为此,我们引入一个双边网格切割操作,以指导地图和学双边网格执行视数据查找的网格如图3所示,我们使用三线性插值网格数据插入指导张量和使用额外的卷积来获得高质量的特性。首先,构造两个具有坐标制导的映射,并将它们与制导矩阵的维数相同叠加成一个张量;其次,用双边网格填充导频张量的坐标位置,并使用三线性插值构造一个与双边网格深度相同(12通道)的张量。下一步是用一个卷积层来压缩张量,卷积层的核大小为3 × 3,步长为1,深度为3,我们称之为系数张量。最后,我们将系数张量与全分辨率朦胧输入相乘,构建新的高质量特征。

图3:通道的高质量去雾特征重建
到目前为止,我们已经介绍了仿射系数双边网格的生成和上采样的过程。然而,我们注意到,将颜色空间压缩到单个地图中所获得的引导信息会导致信息丢失(例如,颜色、对比度和边缘)。此外,为了降低计算成本,我们采用了更小的双边网格。因此,双边网格中的每个单元都没有足够的数据来充分适应仿射变换的颜色信息。为了解决这个问题,我们建议用不同的引导图来处理每个颜色通道,如图2的底部所示。我们使用两个卷积层(3 × 3 × 3和3 × 3 × 1),然后使用PReLU从每个颜色通道中提取引导图,然后用于为三个R、G和B通道生成高质量的去雾特征。我们在图4中演示了多制导地图的有效性。以图6(a)的朦胧图像为例。图4(a)显示了模糊输入的边缘。例如,图4(e)所显示的房屋的边缘和结构信息比图(b)中所显示的(如绿色和蓝色的方框所示)要多。为了进一步验证所提多导图的有效性,我们随机选取100幅朦胧图像,分别计算了单导图和多导图对重建特征的熵。如图4(f)所示,对双边网格进行多次导引可以获得较大的熵值,这说明恢复的边缘和结构更加尖锐。因此,我们的去雾过程遵循学习到的边缘和结构细节,从而规范我们的最终预测,走向边缘感知的解决方案。

图4:(a)为图6(a)中朦胧输入的边缘图;(b)为单导图生成的高质量特征恢复的边缘图;(c)-(e)分别为三种颜色通道的多导图生成的高质量特征的边缘图。红色、绿色和蓝色的框表示使用多引导的地图生成的边界和结构细节比单引导的地图更丰富。在(f)中,我们比较了两种方法产生的高质量特征的熵。
2.3特征融合
为了有效地融合重建的高质量特征以保持良好的可见性,我们采用一种特征融合方案来过滤其重要特征。我们将10个多层卷积块串联起来,并在每个块中添加跳跃连接,得到一个系数张量,它是霾浓度的函数。最后,将预测的系数张量乘以朦胧雾的输入来估计干净的图像。我们发现使用系数张量可以显著加快网络的收敛速度,并有助于生成清晰的去雾图像。我们也尝试通过直接使用卷积层或线性组合来恢复最终的结果,但没有得到改善。我们通过最小化训练集上的L2损失来优化所提网络的权值和偏差:
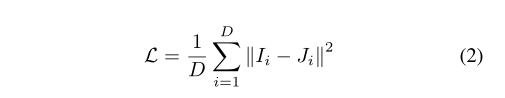
其中D为训练图像的数量,i为我们的网络去雾化的结果,J为相应的真实图像。我们也尝试了总变化和对抗损失,但我们注意到,L2损失足以在去雾的结果中产生清晰和生动的颜色。
3.实验结果
3.1训练数据
为了训练和评估所提出的网络以及比较方法,我们构建了一个新的4K (3840 × 2160)分辨率图像去雾(4KID)数据集,该数据集由多个不同的手机从100个4K分辨率的视频片段中提取的10,000帧模糊/清晰图像组成。利用大气散射模式合成了雾天图像。按照[14,24,27,37]中的原型,我们随机采样大气光条件A∈[0.8,1],散射系数β∈[0.4,2.0],生成相应的朦胧图像。进一步利用平移模块将合成的朦胧图像从合成域转换为真实域,提高了真实情况下深度模型的泛化能力。最后,随机选取8000幅图像作为训练集。由于传统的去雾方法对4K图像的处理时间过长,我们从剩余的图像中随机选取200张作为测试数据。
3.2结果

4.结论
本文提出了一种基于多导双边学习的超高清图像去雾方法。该方法的关键是利用深度CNN构建一个仿射双边网格,它是一种有效的特征存储方法,包含了保持图像细节边缘和纹理的元素。同时,建立多个制导矩阵,辅助仿射双边网格恢复高质量的特征,为图像去雾提供丰富的颜色和纹理信息。定量和定性结果表明,该网络在精度和推理速度(125帧/秒)方面优于目前最先进的去雾方法,可以在真实的4K雾霾图像上产生令人愉悦的视觉效果。















 6871
6871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









