







abstract:测量和评估源代码相似性是一项基本的软件工程活动,涵盖了广泛的应用程序,包括但不限于代码推荐、重复代码、剽窃、恶意软件和气味检测。本文对代码相似性测量和评估技术进行了系统的文献综述和荟萃分析,以阐明现有的方法及其在不同应用中的特点。我们最初通过查询四个数字图书馆发现了超过10000篇文章,最终在该领域进行了136项初步研究。这些研究根据其方法、编程语言、数据集、工具和应用程序进行了分类。一项深入的调查揭示了80种软件工具,在五个应用领域中使用八种不同的技术。近49%的工具用于Java程序,37%的工具支持C和C++,而不支持许多编程语言。值得注意的一点是,存在12个与源代码相似性测量和重复代码相关的数据集,其中只有8个数据集可以公开访问。缺乏可靠的数据集、实证评估、混合方法以及对多范式语言的关注是该领域的主要挑战。代码相似性度量的新兴应用除了集中在维护之外,还集中在开发阶段。
1 Introduction
源代码相似性测量是解决软件工程中许多代码相关任务的基本活动,包括克隆和重用识别[1]-[9]、剽窃检测[10]-[16]、恶意软件和漏洞分析[17]-[22]以及代码推荐[23]-[26]。几乎所有用于测量程序质量[27]-[30]、检测代码气味[31]-[34]、建议重构[35]、[36]、修复程序[37]、[38]和总结源代码[24]、[39]的基于机器学习的方法都使用一种源代码相似性指标。
在文献中,代码相似性也称为代码克隆或重复代码。虽然代码相似性是一个比代码克隆更广泛的概念,但克隆代码是影响软件维护的主要因素之一。软件系统中的代码克隆通常是复制粘贴编程[41]、[48]、[49]实践的结果,导致代码克隆的其他操作包括语言限制、编码风格、执行相同规则的API,以及由不同的开发人员巧合地实现相同的逻辑[6],[48]。
克隆代码的一个主要挑战是,如果在一段代码中检测到故障,则必须识别所有克隆零件,以检查缺陷的可能性。另一方面,一些研究声称重构重复的代码并不总是可取的。例如,删除代码克隆会增加不同组件之间的依赖关系,这些组件可能由于引用一段代码而不是单独的克隆而紧密耦合。因此,即使不采取任何行动,也至少应该识别克隆代码[51]-[55]。不幸的是,检测代码克隆实例并不简单。然而,克隆类型的定义和分类有时并不明确,研究中也没有很好地界定代码克隆和代码相似性之间的界限。
本文提出了一种关于代码相似性测量和评估方法的系统文献综述(SLR)和荟萃分析,以对该领域存在的技术方面进行分类:
1.我们介绍了用于代码相似性测量和克隆检测的最先进的技术、软件工具和数据集。
2.我们对现有代码相似性测量研究的基本方面进行了识别和分类,并比较了它们在不同应用领域的优缺点,包括克隆检测、恶意软件检测、剽窃检测和代码推荐。
3.我们指定并讨论了当前代码相似性测量中存在的挑战和机遇,以及该领域出现的新应用。
研究人员提出了80种不同的软件源代码相似性测量和克隆检测工具,这些工具基于至少八种不同的技术。大多数提出的技术测量代码片段中标记之间的相似性,而基于机器学习和混合方法的更先进技术正在出现。公共工具和数据集的缺乏以及Java应用程序中对克隆检测的关注是现有研究中最关键的挑战之一。随着大型码库的快速发展,源代码相似度测量和克隆检测算法的效率、准确性和可扩展性已成为重要因素。
2 Background
2.1 Code similarity and clone definitions
源代码相似性是一个概念,用于衡量一段代码片段在文本、语法和语义方面的相似程度。Yamamoto等人[56]将软件系统相似性定义为:考虑具体相似性度量的两个给定系统中相似元素对与元素对总数的比率。程序源代码的相似性与软件系统的相似性相同,Yamamoto的定义可以作为程序源代码相似性度量的基础。
区分测量代码相似性的任务和识别相似(或克隆)代码的任务是很重要的。事实上,前者是一个通用概念,后者可以归类为代码相似性测量的应用之一。例如,通过使用阈值来过滤相似性测量的结果,可以将最相似的实例报告为克隆实例[1]。尽管如此,代码克隆检测是代码相似性最突出的应用,也是该领域许多文章和工具的主题。克隆检测方法的进步可以促进其他代码相似性测量应用。
作为广泛接受的定义之一,Baxter等人[1]将克隆代码定义如下:
定义1(克隆代码):如果根据某种相似性定义,两个代码片段c1、c2相似,则它们是克隆。
定义1中的代码段对在不同的编程抽象方面处于特定的粒度级别,包括程序中的语句、块、方法、类、包或组件。此外,根据预期应用,可以在一个或多个项目的范围内执行代码相似性测量。当调查多个项目的实体以测量相似性并找到相似的实例时,定义并使用所谓的跨项目相似性测量技术[23],[26],[59]。在实践中,代码相似性测量的结果可以用向量来报告,包括给定代码片段和具有相同实体级别的所有代码片段的排序相似性。事实上,定义1导致根据相似性度量的定义形成不同的克隆类型。与代码相似性度量的一般定义相比,克隆检测任务必须考虑两个额外的方面:相似性类型和阈值。相似性阈值用于指示克隆实例在一起的接近程度。该阈值的最大相似性值指示实例的精确匹配。因此,并非所有的相似性测量方法和相似性测量都适用于代码克隆检测任务。在本文中,我们针对代码相似性度量的一般问题。然而,在大多数情况下,所提出的技术仅基于克隆检测概念(例如克隆类型)具有可比性。
可以检测到一种编程语言或几种语言之间的代码克隆。后一种类型的克隆检测也称为跨语言克隆检测(CLCD)[60],[61]。跨语言克隆通常发生在准备在不同环境中使用代码库以实现可移植性时。例如,在为不同的操作系统构建游戏时,游戏的主代码库实际上是相同的,并且每个操作系统都有细微的差异[48]。
2.2 Code similarity and clone types
代码克隆的自动检测是一个复杂而多用途的问题。先前的研究已经识别了四种类型的克隆,旨在简化问题[3]、[22]、[48]。两段代码之间的相似性可以从两个维度来查看和衡量,包括源代码的语法(程序文本)和源代码的语义或行为(程序功能)[48]。三种类型的克隆,即I型(精确克隆)、II型和III型(近乎缺失的克隆),在前一维度上被识别[8]、[48]、[62]。后一个维度用于定义克隆的类型IV[48],[63]-[65],也称为语义克隆。应该注意的是,没有单一或通用的克隆分类,所提出的克隆检测方法可以使用它们对代码克隆和克隆类型的定义[66]。根据现有研究[3]、[8]、[22]、[48]、[62]-[66],广泛接受的克隆类型定义总结如下:
类型I:除了空白处和注释中可能存在的更改外,代码片段完全相同。
类型II:代码片段的结构相同。但是,标识符的名称、类型、空格和注释各不相同。
类型III:在这种类型中,除了标识符、变量名、数据类型和注释的更改外,还可以删除或更新代码的某些部分,或者添加一些新的部分。
类型IV:两段代码具有不同的文本,但具有相同的功能。
图1显示了四种克隆类型中每一种的代码片段示例。初始代码片段CF0显示了一个带有简单if-else块的for循环。在CF1中,只有注释被更改,这导致了类型I的克隆。在CF2中,注释和标识符名称发生了更改,导致了类型为II的代码克隆。在CF3中,语句a=10*b被添加为新的代码片段,这导致了III型克隆。最后,在CF4中,相同的程序被重写为一个全新的结构。很明显,找到II型克隆比找到I型更具挑战性。类似地,由于存在新的代码片段,检测III型克隆比II型克隆更复杂。克隆类型IV是最难识别的静态分析程序。研究代码克隆创建的起源有助于开发自动克隆检测和代码相似性方法。

2.3 Origins and root causes of code similarity and clones
1.开发策略:特定的开发方法,如复制粘贴编程,以重用不同的软件组件创建克隆。例如,使用工具生成代码或合并两个类似系统的源代码通常会导致克隆。
2.利用可维护性优势:开发人员经常在维护阶段做出增加代码相似性的更改。3.编程语言限制和供应商锁定:一些广泛使用的编程结构缺乏内置功能和抽象机制,这促使开发人员重复特定的代码片段。例如,C编程语言中缺乏继承和模板,可能会导致重复的相同代码块发生微小的更改。这样的重复结构可以产生潜在的频繁克隆。
3.编程语言限制和供应商锁定:一些广泛使用的编程结构缺乏内置功能和抽象机制,这促使开发人员重复特定的代码片段。例如,C编程语言中缺乏继承和模板,可能会导致重复的相同代码块发生微小的更改。这样的重复结构可以产生潜在的频繁克隆。
4.偶然的相似性:代码的相似性可能是无意中创建的。例如,用于与API和库交互的协议通常需要一系列函数调用或命令序列,从而导致代码相似性。此外,两个或多个独立的开发人员可以使用相同的逻辑来解决特定的问题。
2.4 Related research
一些研究综述了克隆检测方法[48]、[67]-[71]或其特定应用[72]。例如,Novak等人[72]已经审查了源代码中的剽窃检测。
Roy和Cordy[48]发表了第一份关于软件克隆检测研究的全面技术报告。作者描述了克隆文献中常用的术语,并将其映射到常用的克隆类型。他们还提出了一份关于克隆分类法、检测方法和实验评估的57个公开问题和问题的清单。在克隆检测方法和为软件开发人员提供有价值信息的工具之间进行了一些基本的比较。
Rattan等人[67]对软件克隆检测和管理进行了系统综述。他们的调查涵盖了几乎所有软件克隆主题,如克隆定义、克隆类型、克隆创建原因、克隆检测方法和克隆检测工具。他们还试图通过评论来回答克隆是“有用”还是“有害”的根本问题。
Min和Ping[68]以及Ain等人[69]最近对软件克隆检测进行了类似的调查。这些研究涵盖了用于代码克隆检测的方法、工具和开源主题系统,帮助研究人员根据需要选择合适的方法或工具来检测代码克隆。
Novak等人[72]对剽窃检测技术和工具进行了综述。他们对该领域进行了系统的审查,以帮助大学教授检测学生提供的源代码中的剽窃行为。
Burd和Bailey[73]评估了五种代码克隆检测工具在中等规模Java程序上的性能。他们得出的结论是,在克隆检测方面,没有单一的、彻底的赢家技术。
Bellon等人[62]使用包含八个大型C和Java程序的基准测试,评估了六个克隆检测器的精度、召回率和执行时间。所选择的工具基于不同的代码相似性测量方法,包括处理文本信息、词汇和句法信息、软件度量和程序依赖图的技术。得出的结论是,与基于树和基于图的工具相比,基于文本和基于标记的工具表现出更高的召回率,但精度更低。此外,基于树的技术的执行时间高于其他基于文本和令牌的技术。
Biegel等人[74]对四个Java项目中基于文本、基于令牌和基于树的源代码相似性测量方法的召回率和计算时间进行了实证比较。他们使用这些工具来检测代码中的重构片段。作者发现,不同工具的结果有很大的重叠。然而,基于令牌的克隆检测工具CCFinder[2]比其他两种相似性测量方法慢得多。
通用的文本相似性度量工具提供了与特定的代码相似性测量工具类似的性能。然而,总的来说,特定源代码的相似性度量技术和工具可以比一般的文本相似性度量执行得更好。
Chen等人[70]在2006年至2020年间对不同的代码重复方法进行了批判性审查。作者得出的结论是,没有具有大量样本的有效测试数据集来验证可用代码克隆检测的有效性。此外,作者报告说,大多数技术都非常复杂,支持单一的编程语言,并且无法检测语义克隆(IV型克隆)。然而,他们没有研究我们论文中讨论的广泛的代码相似性测量应用。具体来说,除了先前确定的源代码相似性测量技术之外,我们还添加并讨论了基于学习、基于测试、基于图像和混合算法。我们还确定了代码相似性测量的一些新兴应用,包括代码推荐和故障预测。
3 Research Methodology
4 Results and Findings
4.2 Classifying and comparing code similarity studies
对主要研究的分析表明,代码相似性度量研究暴露出一些共同的方面。对这些方面的适当分类,我们为每项关于代码相似性测量的研究指定了五个正交维度,包括技术、工具、支持的编程语言、数据集和应用领域。不幸的是,并非所有研究都提供了所有五个拟议类别的信息和讨论。
在技术方面,现有的研究要么基于静态程序分析,要么基于动态程序分析。基于静态分析的方法,如[10]、[40]、[61]、[81]-[83],不使用任何程序执行来测量相似性。他们正在使用算法、数据驱动或混合方法来寻找类似的源代码。很少有研究[84]、[85]使用动态分析,在动态分析中,使用测试套件或工作负载执行程序,以获得运行时信息,如程序函数输出,然后通过比较获得的信息来找到类似的代码片段。第4.4节详细讨论了现有技术。
关于工具,拟议的研究可能有工具支持,也可能没有工具支持。现有的工具和方法可以检测一种或多种编程语言中的源代码相似性。还有独立于语言的工具[90]。第4.5节介绍了现有的代码相似性度量工具和支持语言。
我们对主要研究的回顾显示了三种用于创建和验证代码相似性测量方法的数据集:具有人类预言机的数据集[62]、[91]、具有机器预言机的数据库[92]、[93]和混合数据库[43]。第一类数据集要么由该领域的专家手动标记,要么基于针对编程竞赛平台(如Google CodeJam[94]和Codeforces[95])中特定问题提交的解决方案。自动生成的数据集使用不同现有工具[62]、突变算子[93]、程序转换规则[96]或代码库的版本历史之间的多数投票,在没有人为干预的情况下为相似和不相似的代码片段制作标签。最后,这些方法的组合可以用于创建大型高质量的数据集。第4.6节讨论了现有代码相似性基准和数据集的细节。
关于代码相似性测量的应用,我们观察到代码克隆和重用检测的直接应用和几种间接应用,它们被进一步分类为剽窃检测、恶意软件和漏洞检测、代码预测和代码推荐。虽然大多数主要研究都集中在寻找克隆实例上,但我们的调查表明,源代码相似性测量可以解决软件工程活动中许多与代码相关的任务。第4.3节描述了我们回顾的研究所涵盖的代码相似性测量的不同应用。
4.3代码相似性测量应用
除了代码克隆和剽窃检测,还有其他三种代码相似性测量应用,包括恶意软件检测、缺陷预测和代码推荐。代码克隆检测是代码相似性测量研究中最常见的应用。在超过84%的初步研究中对其进行了讨论。事实上,大多数研究都是在代码克隆的一般领域中研究代码相似性,而不是直接讨论特定的应用程序。在生产代码和测试代码中都检测到代码克隆[97]。
代码剽窃检测是具有第二频率等级的琐碎代码相似性测量应用之一,其目标是识别程序源代码的未经授权的重用[72],[98],[99]。类似地,具有已知缺陷的源代码套件的克隆实例被识别为可能存在缺陷的程序[101]-[103]。最后,代码推荐[26],[104]是代码相似性的最新应用之一。它建议根据开发中的代码与给定语料库中现有代码的相似性,对代码进行修改和改进,如bug修复补丁、实体名称、重构和代码生成。例如,已经提出了几种方法来向程序员建议方法和类名,以提高源代码质量因素[23]、[24]、[26]、[105]、[106]。
4.4 Code similarity measurement techniques代码相似性测量技术
我们确定了主要研究中使用的九种测量代码相似性的技术。图5展示了源代码相似性度量技术的结构化级别。以前的调查最多考虑了结构化树叶子中的六个类别,但我们的SLR可以确定三类新的源代码相似性测量技术,包括基于学习、基于图像和基于测试的方法。
图7说明了初级研究中不同代码相似性测量技术的频率。可以观察到,将两个或多个基本方法相结合的混合方法是最常用的代码相似性测量技术。根据该图,近28%的研究提出了一种测量源代码相似性的混合方法。基于学习的方法和基于令牌的方法分别排在第二和第三位。基于图、基于树和基于文本的技术分别位于第四、第五和第六位。最后,基于度量、基于测试和基于图像的方法是检查最少的方法。本节剩余部分将讨论基于每种技术提出的最重要的初步研究,以提供每种方法的机制和细节。
4.4.1 Text-based techniques——基于文本
最简单和早期设计的代码相似性测量技术是将源代码视为文本文档[P2]。基于文本的方法将源代码视为字符串序列[P30]。将两个代码片段比较在一起以找到最长的公共字符串序列,然后将匹配的部分报告为克隆实例。比较通常在没有任何预处理的情况下对原始代码执行。在某些应用程序中,在序列匹配之前会删除空白和注释。基于文本的方法的主要优点是它们是高效的,并且可以在不进行任何修改的情况下应用于任何编程语言。
Burrows等人[P10]提出了一种基于文本的方法来发现源代码中的剽窃。使用局部对齐过程[107](一种近似字符串匹配算法)计算从源代码获得的字符串序列之间的相似性。为了获得更好的效率,评估语料库中的每个令牌只存储和索引一次。作者已经表明,他们的方法的有效性与JPlag[P6]工具(基于令牌)相当,同时由于过滤和索引源代码片段,它具有高度的可扩展性和高效性。
NICAD是一种众所周知且最常用的基于文本的克隆检测工具,它使用文本规范化来消除噪声、标准化格式并将程序语句分解为多个部分,从而将潜在的更改检测为简单的逐行文本差异[P11]、[P14]。Ragkhitwetsagul和Krinke[P63]使用编译和反编译作为预处理步骤,以规范代码片段中的语法变化,并提高NICAD的准确性。gCad[P35]是一个基于NICAD检测程序多版本中克隆的未遂克隆谱系提取器。它接受一个程序的n个版本,在连续版本之间映射克隆类,并提取每个克隆类在整个观察期内的变化情况。
Cosma和Joy[P22]提出了一种基于文本的方法来检测剽窃,该方法得到了工具PlaGate的支持。他们使用潜在语义分析(LAS)技术将源代码文件转换为数字矩阵,然后计算语料库中每对文件之间的余弦相似度。PlaGate是一个独立于语言的源代码剽窃检测工具。然而,在每个语料库上为LSA矩阵选择正确的维度是具有挑战性的。
Kamiya等人[P45]提出了一种更先进的方法,即词汇分析器创建文本序列。然后为每个序列构造AST,并使用Apriori算法[108]找到公共子树。他们的方法发现具有序列匹配的I型和II型克隆以及具有AST匹配的III型克隆。这种方法的优点是不需要为整个程序创建AST。然而,它不支持检测IV型克隆。
Chen等人[P43]使用了一种基于文本的方法来识别安卓系统的恶意软件应用程序。源代码被分解为小代码片段,这些片段与现有恶意软件之间的相似性是使用NiCad工具[109]来检测恶意软件的。该方法的得分超过95%(召回率为91%,准确率为99%),与其他基于文本的方法相比相对较高。
Tukaram等人[P8]提出了另一种基于文本的方法,该方法使用预处理模块来删除代码中的额外信息,如空格。在他们的方法中使用的其他模块包括关键字、数据类型、变量和函数检测器,用于识别代码的特定部分。最后,它使用了一个负责识别相似性的相似性检查器模块。本文旨在提供有关不同级别应用程序代码相似性的一般信息。优点是它可以用于评估软件并提供有关克隆代码的通用细节。
4.4.2 Token-based techniques——基于令牌
在基于令牌的方法中,程序的源代码转换为令牌序列,然后对这些序列进行比较,以找到公共子序列[P7],[P98]。与基于文本的方法[P15]、[P18]、[P26]相比,基于令牌的技术对代码变化(如标识符词法的变化)更具鲁棒性。它们的效率也足以在软件开发过程中频繁使用[P53]。然而,由于令牌识别和替换操作,处理时间增加了。基于令牌的方法在识别具有I型和II型的代码克隆[P13]、[P87]、[P89]、[P92]、[P95]、[69]以及在检测具有许多编辑的III型克隆的大间隙克隆[P68]、[P75]、[P79]方面已经证明了良好的性能。
Rehman等人[P25]开发了一种工具LSC-Miner,用于使用基于令牌的方法查找克隆代码。LSC-Miner支持多种语言的克隆检测,包括C、C++、VB6、VB.NET和Java。Misu等人[6]指出,具有相似接口的两个功能容易被克隆。他们的方法首先为程序中的每个方法创建相应的接口。然后,计算每对方法的令牌序列之间的Jaccard相似性[110]。该序列包括函数参数和标识符的令牌流。相似性超过70%的函数被分组为克隆的实例。这个阈值是通过实验确定的。他们已经为Java程序开发了自己的方法。Ankali和Parthiban[P113]已经使用Levenstein距离来搜索Java、C和C++中的跨语言代码克隆。克隆类型的分类由作者手动执行。
Lopes等人[P61]已经在GitHub存储库中检测到使用基于C++、Javascript、Java和Python程序的令牌方法的克隆代码。为此,他们使用SourcererCC工具[P47]在项目和文件级别检查源代码。他们得出的结论是,大约14%的Java、25%的C++、18%的Python和48%的JavaScript代码在GitHub存储库中都有克隆实例。CP-Miner[P7]在大规模软件代码中发现复制粘贴及其相关错误。
JPlag[P6]将程序标记为字符串序列,并使用Greedy String Tiling[111]算法,该算法可以找到最大的连续子字符串集。它提供了一种web服务,可以在给定的程序集中找到成对的类似程序。JPlag[P10]主要用于检测源代码剽窃。刘等人[P79][112]已经将Smith Waterman序列比对算法用于令牌匹配,以提高基于令牌的克隆检测的效率。CPDP是一种类似的基于令牌的工具,用于源代码中的剽窃检测[P32]。
当对原始源代码进行结构修改(如更改控制结构)时,源代码剽窃检测系统可能会混淆[P32]。为了缓解这些问题,Duric和Gaševic[P26]提出了一种增强的基于令牌的剽窃检测工具SCSDS,该工具具有专门的预处理功能,可以避免一些结构修改的影响。例如,Java数字类型的所有标识符,例如int、long、float和double类型,都用<NUMERIC_TYPE > 代币此外,还会删除所有分号标记。与众所周知的JPlag工具[10]相比,SCSDS获得了更好的F1分数。然而,这种比较是在一个学生编程作业的小数据集上进行的,这威胁到了该方法的通用性。
Ullah等人[P75]使用了基于令牌的克隆检测来检测学生编程作业中的抄袭行为。他们的方法首先使用潜在语义分析(LSA)创建频繁重复的程序令牌矩阵[113]。此方法有助于将源代码转换为自然语言。编程分配之间的相似性由LSA[113]计算。LSA算法已被应用于从令牌中提取语义,以发现学生在C++和Java编程作业中的剽窃行为。作者报告了他们提出的方法的最大召回率为80%。
使用基于文本或基于令牌的方法检测IV型代码克隆是具有挑战性的,因为程序的文本通常不同。Rajakumari等人[P89]通过五个步骤解决了Java程序IV型克隆的检测问题:选择输入、分离模块、提取克隆、对克隆进行分类和报告结果。Ragkhitwetsagul等人[P87]已经使用众所周知的TF-IDF技术将标记序列转换为载体。首先,执行索引阶段以创建令牌的向量表示,并为每个向量分配分数。然后,检测阶段选择类似的实例并将其报告为克隆。他们提出的工具Siamese可以检测Java程序的I、II和III型克隆,最大召回率为99%。这种方法的另一个优点是它在检测克隆实例时具有相对较高的时间性能。然而,暹罗人无法检测到IV型克隆。FastDCF[P128]是另一个使用HDFS[115]和MapRed的基于令牌的克隆检测工具。
4.4.3 Tree-based techniques
使用基于树的方法[P8]、[P16]、[P78]、[P121]中的编程语言解析器将源代码转换为解析树或抽象语法树(AST)。在解析树或AST中执行对相似代码的搜索,以找到相似子树[P24]。这种方法对不同的阻塞和穿刺等代码变化是稳健的。然而,为大型代码库创建解析树或AST非常耗时,并且需要为每种编程语言指定一个特定的解析器[P93]。此外,匹配子树在计算上是昂贵的[P93]。在代码克隆检测的应用中,基于树的方法可以准确识别I、II和III类型的代码克隆。它们还被应用于代码相似性测量的其他应用领域,如恶意软件检测[P74]和缺陷预测[P115]。
DECKARD[P9]是一种基于树的代码克隆检测,它使用树编辑距离度量来测量代码相似性。两棵树的编辑距离㼿1和㼿2,表示为㼿(㼿1.㼿2) ,是转换所需的编辑操作的最小序列㼿1至㼿2.DECKARD[P9]的性能在很大程度上取决于用于确定相似性的阈值。Gharehyazie等人[P91]开发了基于DECKARD的CLONE-HUNTRESS工具,用于识别和跟踪GitHub项目中的克隆实例。然而,他们的工具无法捕获IV型克隆。Chandran等人[P57]考虑到代码的安全相关属性,增强了函数的抽象语法树(AST),以发现易受攻击和有缺陷的克隆实例。
Tekchandani等人[P27]提出了一种基于树的方法来检测IV型克隆。首先,首先创建源代码AST,然后比较AST叶子的序列以识别克隆对。他们的方法试图从源代码样本中提取语法,并构建AST以支持多种编程语言。因此,这种方法在编程语言的语法不可用的情况下效果很好。然而,克隆检测时间由于从源代码样本中提取语法而增加,而其准确性由于语法提取过程中的错误而降低。Asta[P19]使用类似的方法将AST节点转换为具有有限长度的顺序模式,并比较这些模式以检测可能的克隆。
Gao等人[P78]提出了一种工具TECCD,该工具在程序AST上使用word2vec算法[117]来减少基于树的相似性测量的时间。ANTLR解析器生成器[118]用于创建源代码AST,并且将包含AST节点的矩阵馈送到word2vec模型,从而产生每个AST的向量表示。计算对应AST向量对之间的欧几里得距离作为相似性的度量。将学习到的模型用于将新的源代码转换为向量,提高了基于树的方法的效率。它可以检测I、II和III型的代码克隆,准确率为88%,召回率为87%。TECCD无法检测IV型克隆。
Sager等人[P8]试图使用AST在Java代码中识别类似的类。他们的方法使用Eclipse的JDT API获得每个类的AST。然后,AST被转换为一个称为FAXIM(FAMOOS信息交换模型)的中间模型,这是一个用于显示面向对象源代码的独立编程语言模型[P8]。然后使用比较算法比较两个类之间的相似性,包括自下而上的最大公共子树同构、自上而下的最大公共子树同构和树编辑距离。相似性是在FAXIM树之间测量的。所讨论的方法识别了两个软件项目中平均召回率为74.5%的类似类。
4.4.4 Graph-based techniques
基于图的方法通常为代码片段创建程序依赖图(PDG)[119],然后比较这些图以识别相似性[P21]。PDG包含程序语句之间的数据和控制依赖关系,因此除了语法之外还传达程序的语义。PDG的节点是程序语句,边是数据或控制依赖关系。基于PDG的方法的正确实施可以识别所有类型的克隆[P34],[P19]。然而,比较PDG通常与图同构有关,这是一个NP完全问题[P23],[P31]。因此,一些方法将PDG转换为更简单的树表示,用于克隆检测[P64]。
4.4.5 Metric-based techniques——基于度量的技术
基于度量的方法首先使用向量空间模型理论[121],将源代码表示为不同代码度量的向量。然后,使用向量相似度来测量每个给定源代码之间的相似度。向量相似性在很大程度上取决于为编程语言定义的度量的数量和质量。计算大型程序的源代码度量需要合理的时间,从而使该方法具有适当的效率[P1],[P14]。表2显示了用于代码相似性测量和克隆检测的常见源代码度量。据观察,研究人员只使用了一组有限的源代码度量。
代码行、声明的变量数、运算符总数、局部变量的数量、函数调用的数量、条件语句的数量、迭代语句的数量、返回语句的数量、输入语句的数量、输出语句的数量、通过函数调用的赋值数量、选择语句的数量、赋值语句的数量、传递的参数的数量。
4.4.6 Learning-based techniques——基于学习的技术
鉴于近年来机器学习已经变得广泛[122],我们倾向于将基于学习的方法作为一个单独的类别来讨论。本节总结的机器学习方法在代码相似性测量和克隆检测任务[P17]、[P42]、[P49]、[P59]、[P84]、[P01]、[P02]、[P03]、[P18]、[P19]、[P118]、[P120]、[P132]中显示出了有希望的结果。学习和识别复杂模式的能力使学习算法适合这些任务。然而,基于学习需要大型且干净的代码克隆数据集才能正常工作,这并非适用于所有语言。大多数方法都使用现有的代码克隆检测工具来准备机器学习所需的数据,这是不可靠的,因为这些工具总是会出错。
基于学习的方法旨在通过对已知相似和不相似代码[P42]、[P59]、[P84]、[P102]、[P105]、[P07]的给定数据集进行学习来对相似代码片段进行分类或聚类。Cesare等人[P37]已经使用传统的分类模型在包装水平上识别克隆。作者报告随机森林是最好的学习模式。Joshi等人[P46]使用DBSCAN聚类算法[123]在功能水平上识别克隆的I型和II型。Keivanloo等人[P42]使用k-means聚类算法来确定具有任何相异性阈值的III型真克隆和假克隆,这在非学习方法中很常见。作者使用Friedman方法来评估不同值的聚类质量㼿 聚类算法中的参数。他们的方法无法检测到IV型克隆。
4.4.7 Image-based methods
基于图像的代码相似性测量方法将代码片段转换为图像,然后使用图像处理技术来查找代码片段之间的相似性[132]。受视觉克隆检测的启发,Wang和Liu[P77]提出了一种基于图像的克隆检测方法,将经过预处理的源代码转换为图像,并计算图像之间的Jaccard相似度以找到相似的源代码。源代码预处理步骤主要包括删除注释和空白,并突出显示代码中的关键字、数据类型、标识符和文字。这种方法无法检测IV型克隆或语义相似的代码,因为它主要依赖于代码片段的外观。
4.4.8 Test-based methods
大多数代码相似性测量方法使用的静态源代码分析不适合识别语义等效的方法或IV型克隆。基于测试的方法使用动态分析,其中使用样本输入或测试套件执行程序,并收集其运行时数据。然后可以使用这些数据来检测语义上等效的代码。李等人[P66]提出了一种基于测试的克隆检测方法来识别IV型代码克隆。使用EvoSuite测试数据生成工具[133]为每对方法自动生成测试套件。如果两个方法在每个生成的测试用例上生成相同的输出,则它们被认为是语义等效的方法。作者可以在Java开发工具包(JDK)中识别IV类型的克隆方法。但是,生成和执行不同方法的测试用例在计算上是昂贵的。此外,基于测试的方法无法识别方法主体中的等效片段。Su等人[P50]也提出了类似的方法。他们使用现有的工作负载来执行程序,然后根据程序的输入和输出来衡量程序之间的功能相似性。
4.4.9 Hybrid methods——混合方法
混合方法结合了两个或多个基本方法来应对单个方法的挑战。表3显示了我们的初步研究提出的不同方法组合及其应用领域。据观察,基于文本和基于令牌的方法大多与基于图和基于树的方法相结合。前一种方法有效但效率较低,而后一种方法则有效但效率较差。因此,它们的组合为代码相似性测量提供了效率和有效性。基于令牌和基于文本的方法也已结合起来,以实现高鲁棒性,同时保持基于文本的克隆类型I、II和III的效率[P20]、[P29]、[P55]。最后,基于树和基于学习的方法大多被结合起来,以适当地检测未遂克隆和语义克隆[P80]、[P81]、[P82]、[P83]、[P97]、[P125]、[P126]、[P134]、[135]。

4.5 Code similarity measurement tools and languages
CPD(Token-based)工具是PMD源代码分析器[86]中的一个子模块,可在20多种编程语言中查找重复代码,包括但不限于C、C++、C#、Go、Groovy、Java、JavaScript和Matlab。
Simian(Token-based)[89]是另一个识别Java、C#、C、C++、COBOL、Ruby、JSP、ASP、HTML、XML、Visual Basic、Groovy源代码甚至纯文本文件中重复的工具。
iClones(Token-based)[87]使用基于令牌的技术从程序历史中提取克隆进化数据。Ehsan等人[P135]使用iClones从公共GitHub存储库上的程序历史中提取克隆实例。
MOSS(Text-based)[136]和AutoMOSS[88]是专门用于剽窃检测的基于文本的源代码相似性测量。
如图8所示,大多数可用的工具在其后端使用混合、基于学习、基于树或基于令牌的方法。原因是这些方法的高效性以及与大多数编程语言的兼容性。另一方面,只有一种工具可以与基于测试的方法配合使用,这表明了该方向研究的难度和新颖性。
图8:
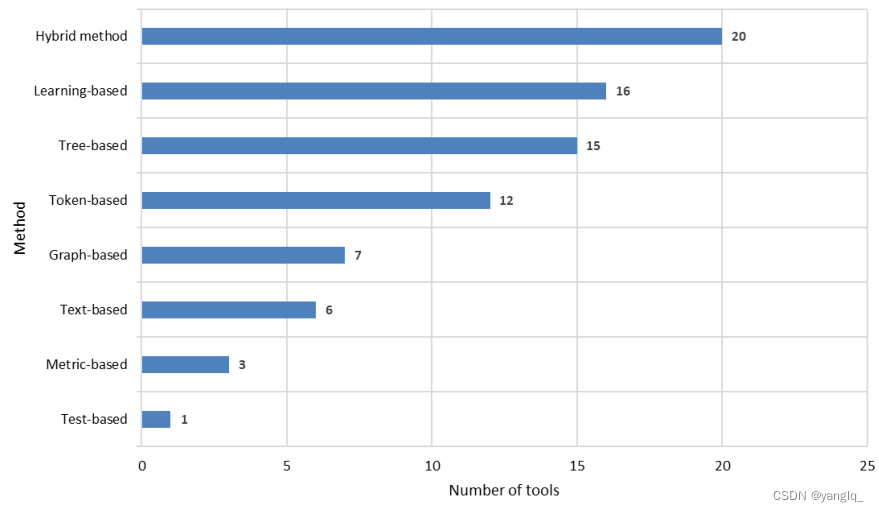
图9显示了可用的源代码相似性测量和克隆检测工具所支持的编程语言的频率。只有一个工具支持的语言单独显示在饼图的右侧。只有一个工具支持大约7%的受支持编程语言。最受支持的五种语言是Java、C、C++、C#和Python。近44%的可用工具支持用Java编写的源代码,33%的工具支持C或C++代码,而其他流行的编程语言,如PHP、Swift和Scala,则没有支持工具。因此,开发多范式和多语言代码相似性测量和克隆检测工具具有巨大的机会。
4.6 Code similarity benchmark and datasets
数据集在构建和验证代码相似性度量工具中起着至关重要的作用。初步研究表明,有12个数据集涉及源代码相似性和克隆检测研究。表5列出了可用的代码相似性数据集和一些附加信息下载链接、支持语言、大小及其主要参考研究。136项研究中只有68项(50%)使用了这些数据集。其余50%的初步研究主要使用了一组有限的开源项目,这表明几乎一半的拟议方法缺乏可靠的评估。我们的调查显示,这些文章中使用了70多个不同的开源项目。大多数研究都只报道了使用基于星星的GitHub项目,没有任何细节,这使得很难公平地比较不同的方法。图10显示了用于根据主要研究中报告的信息创建和评估代码相似性测量工具的项目的单词云图。据观察,主要研究主要使用ApacheAnt、ANTLR、JDK和PostgreSQL项目来构建和验证他们的方法。















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









