







前言
在当今这个信息爆炸的大数据互联网时代,信息的爆炸使得人们按照传统方式寻找需要的信息会显得乏力而不准确。除了应用先进的搜索技术使得用户主动搜索外,个性化的推荐技术也能准确地将信息定位到用户,并取得非常好的效果。本文首先介绍传统的推荐引擎技术,接下来重点讲解当下流行的,个性化协同过滤推荐算法并附上源码实现。
传统推荐技术
推荐引擎,是建立在对每一个用户的信息和行为深刻了解的基础之上,为用户提供个人化信息的技术,它不是被动等待用户的搜索请求,而是为用户主动推送最相关的信息。
推荐引擎工作原理
下图展示了推荐系统(或称推荐引擎)的工作原理。它的输入是推荐的数据源,一般情况下,推荐引擎所需要的数据源包括:
- 要推荐物品或内容的元数据,例如关键字,基本描述等;
- 系统用户的基本信息,例如性别,年龄等;
- 用户对物品或者信息的偏好,例如用户对物品的评分,用户查看物品的记录,用户的购买记录等。最近,我在阿里参与的一个项目就是需要综合用户的这些特征来进行推荐。
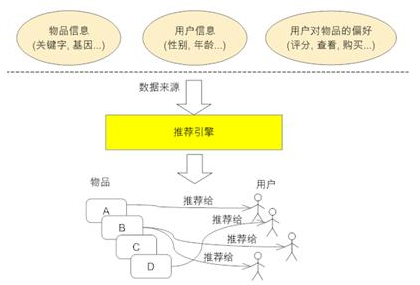
推荐引擎根据不同的推荐机制可能用到数据源中的一部分或全部,然后在这些数据的基础上结合推荐算法将不同信息推荐给不同用户。
推荐机制分类
在推荐系统中,常见的推荐机制有如下几种:
- 基于人口统计学的推荐;
- 基于内容的推荐;
- 基于协同过滤的推荐;
- 混合的推荐机制。
由于篇幅限制,在这里,博主只是列举出来并没有逐一展开。如果有机会,在后面会作为一个专栏给大家讲解。
协同过滤推荐算法
协同过滤推荐(Collaborative Filtering recommendation,后文简称CF)在信息过滤和信息系统中正迅速成为一项很受欢迎的技术。与传统的基于内容过滤直接分析内容进行推荐不同,协同过滤分析用户兴趣,在用户群中找到指定用户的相似(兴趣)用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。
从上面的定义可以看出,协同过滤是一种集体智慧的体现,也就是基于兴趣群体的推荐技术。例如,你现在想观看一部新电影,但并不知道看哪一部。这种时候,大部分人都会选择询问有相同电影偏好的朋友,让他们推荐一两部电影。这便是协同过滤的集体智慧体现。
从上面咨询朋友进行电影推荐的例子中,我们可以粗略总结出协同过滤推荐的步骤:
- 根据历史资料总结出用户偏好或者资料特征;
- 计算需要推荐的对象相似度;
- 进行推荐。
不难发现,整个算法有两个难点:
- 如何计算对象间的相似度;
- 相似度计算完之后,如何找到对象的邻居。
相似度计算
一般而言,在进行数据处理的时候,我们会将对象特征归一化为向量表示,然后计算相似度,距离越近相似度越高。相似度的计算有以下几种方式,
1. 欧几里得距离(Euclidean Distance)
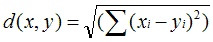
采用欧几里得距离计算时,一般使用如下公式进行相似度转换,
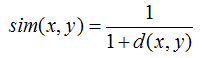
可以看出,欧氏距离越小时,相似度越近。
2. 皮尔逊相关系数(Pearson Correlation Coefficient)
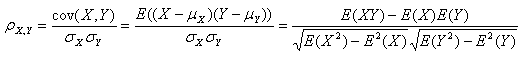
Pearson相关系数一般用于计算两个定距变量间联系的紧密程度,它的取值在 [-1,+1] 之间。它有一个特点,在计算两个数列的相似度时忽略平均值的差异。比如说有的用户对商品评分普遍偏低,有的用户评分普遍偏高,而实际上他们具有相同的爱好,他们的Pearson相关系数会比较高。举例说明,用户A对某三个商品的评分是X=(1,2,3),用户B对这三个商品的评分是Y=(4,5,6),则X和Y的Pearson相关系数是0.865,相关性仍然比较高。
3. Cosine 相似度(Cosine Similarity)
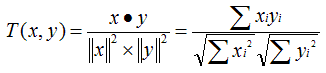
Cosine 相似度被广泛应用于文档数据的相似度计算。
计算相似邻居
上一小节,我们讨论了如何计算两个对象的相似度。这一节我们将继续讨论协同过滤算法的第二个难点,如何找到相似的邻居。
常用的计算相似邻居的算法有两种:固定数量的邻居和基于相似度门槛的邻居。
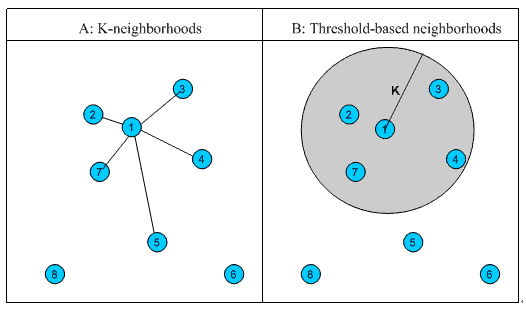
1. 固定数量的邻居:K-neighborhoods 或者 Fix-size neighborhoods
不论邻居的“远近”,只取最近的 K 个,作为其邻居。如图 1 中的 A,假设要计算点 1 的 5- 邻居,那么根据点之间的距离,我们取最近的 5 个点,分别是点 2,点 3,点 4,点 7 和点 5。但很明显我们可以看出,这种方法对于孤立点的计算效果不好,因为要取固定个数的邻居,当它附近没有足够多比较相似的点,就被迫取一些不太相似的点作为邻居,这样就影响了邻居相似的程度,比如图 1 中,点 1 和点 5 其实并不是很相似。
2. 基于相似度门槛的邻居:Threshold-based neighborhoods
与计算固定数量的邻居的原则不同,基于相似度门槛的邻居计算是对邻居的远近进行最大值的限制,落在以当前点为中心,距离为 K 的区域中的所有点都作为当前点的邻居,这种方法计算得到的邻居个数不确定,但相似度不会出现较大的误差。如图 1 中的 B,从点 1 出发,计算相似度在 K 内的邻居,得到点 2,点 3,点 4 和点 7,这种方法计算出的邻居的相似度程度比前一种优,尤其是对孤立点的处理。
图 1. 相似邻居计算示意图
协同过滤分类
协同过滤刚开始使用的时候是基于用户(User-based)的推荐,后来亚马逊根据自己的业务改进,发明了基于物品(Item-based)的推荐算法。这两种算法在下文逐一介绍。
基于用户的协同过滤算法
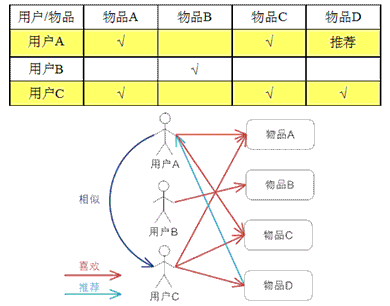
基于用户的 CF 根据用户对物品的偏好找到邻居用户,然后将邻居用户喜欢的物品推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。下图给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
基于物品的协同过滤算法
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给用户。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。下图给出了一个例子,对于物品 A,根据所有用户的历史偏好&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









