








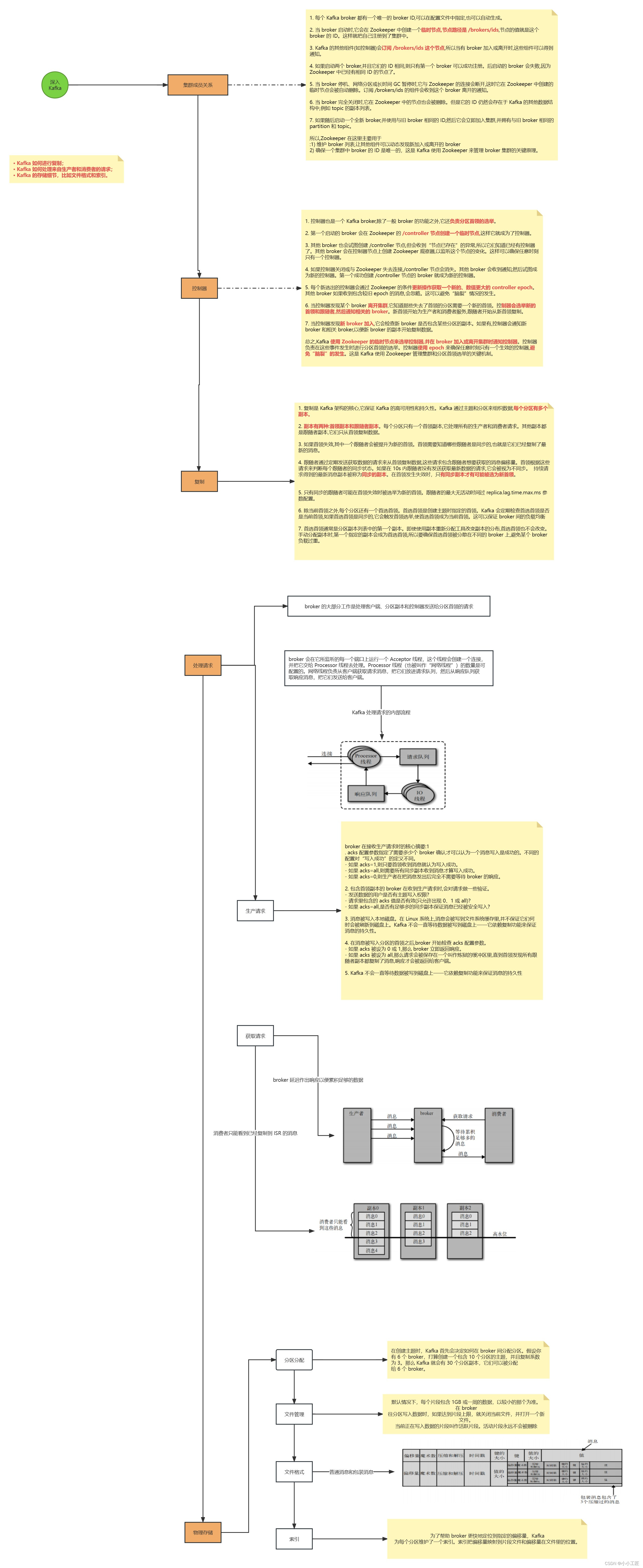
Kafka的实现机制
作为Kafka专家,我很高兴为您深入解释Kafka的实现机制。我将从以下几个方面对Kafka进行分析:集群成员关系、控制器、Kafka的复制、请求处理和物理存储。
1. 集群成员关系:
Kafka是一个分布式系统,由多个服务器组成的集群来处理数据流。在Kafka中,集群成员通过ZooKeeper来进行协调和管理。ZooKeeper维护了有关Kafka集群中所有服务器的元数据信息,包括主题(topics)、分区(partitions)以及它们在集群中的分布情况。
2. 控制器*:
Kafka集群中的一个服务器充当控制器角色,负责管理整个集群的状态。控制器负责领导者(leader)选举、分区的分配和重新分配以及副本(replica)的管理。当控制器检测到某个分区的领导者不可用时,它会负责选择新的领导者。
3. Kafka的复制:
Kafka通过副本机制提供数据冗余和高可用性。每个分区可以有多个副本,其中一个副本被指定为领导者,负责处理读写请求,其他副本则充当追随者。领导者接收到的消息会被复制到所有追随者,以确保数据的可靠性。当领导者失效时,控制器将选择一个新的领导者。
4. 请求处理:
Kafka使用了一种基于提交日志(log)的消息存储模型。生产者将消息追加到主题分区的提交日志中,消费者则从日志中按顺序读取消息。请求处理过程包括生产者的写入请求和消费者的读取请求。生产者将消息发送给分区的领导者,领导者将消息追加到日志并进行复制。消费者从领导者或追随者拉取消息进行消费。
5. 物理存储:
Kafka使用了一种持久化的日志存储模型。每个主题分区都被划分为多个日志片段(segment),每个日志片段都是一个物理文件。消息以追加的方式写入日志片段,并根据一定的大小或时间策略进行日志段的滚动和压缩。这种存储模型支持高吞吐量的消息写入和顺序读取,并允许消息的持久化存储和回溯。
总之,Kafka的实现机制包括集群成员关系的管理、控制器的角色分配、基于副本的复制机制、请求的处理和基于提交日志的物理存储。
导图















 9413
9413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











