







文章目录

引言
在后台架构中,压测是发现性能瓶颈和评估流量极限的必备手段。但很多团队的压测往往因模拟参数不真实或场景与线上不一致而产生失真,导致拿不到可信的容量指标。
接下来我们将介绍 如何构建贴合生产流量的高保真压测,并基于结果做出准确的容量规划与限流策略。
一、高保真压测的核心思路与架构
1. 为何要高保真?
- 模拟参数失真:固定账号测试可能命中本地缓存,QPS 大幅高于真实场景。
- 场景差异:手工脚本无法复刻多样化的用户请求。
2. 核心思路
录制生产环境真实流量,并原样回放,保证参数、调用顺序、并发模式与线上一致。
3. 架构组件
基于流量录制的压测架构
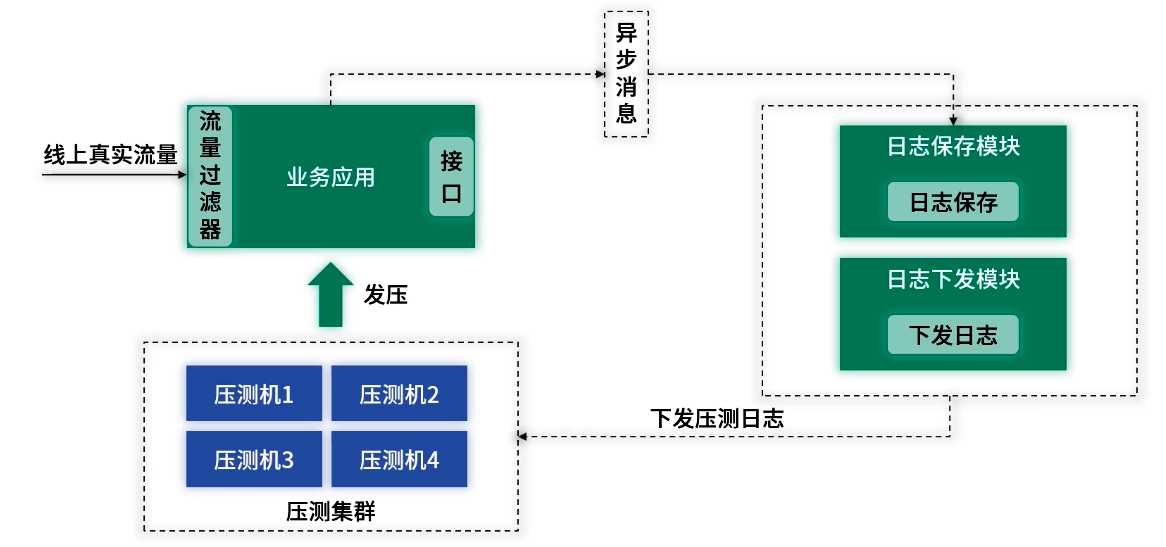
- 流量过滤器:嵌入 RPC 框架拦截入参、出参,经 MQ 转发至日志保存。
- 日志保存模块:按配置收集多样化真实请求,存入分布式文件系统(如 Hadoop)。
- 日志下发模块:将录制日志推送至压测机器本地,避免远程读取开销。
- 压测模块:读取本地日志并并发回放,收集每次调用指标。
- 压测管理端:配置场景参数、查看结果报告。
二、应用层瓶颈与集群扩容测算
1. 单机瓶颈定位
** 简单应用架构**
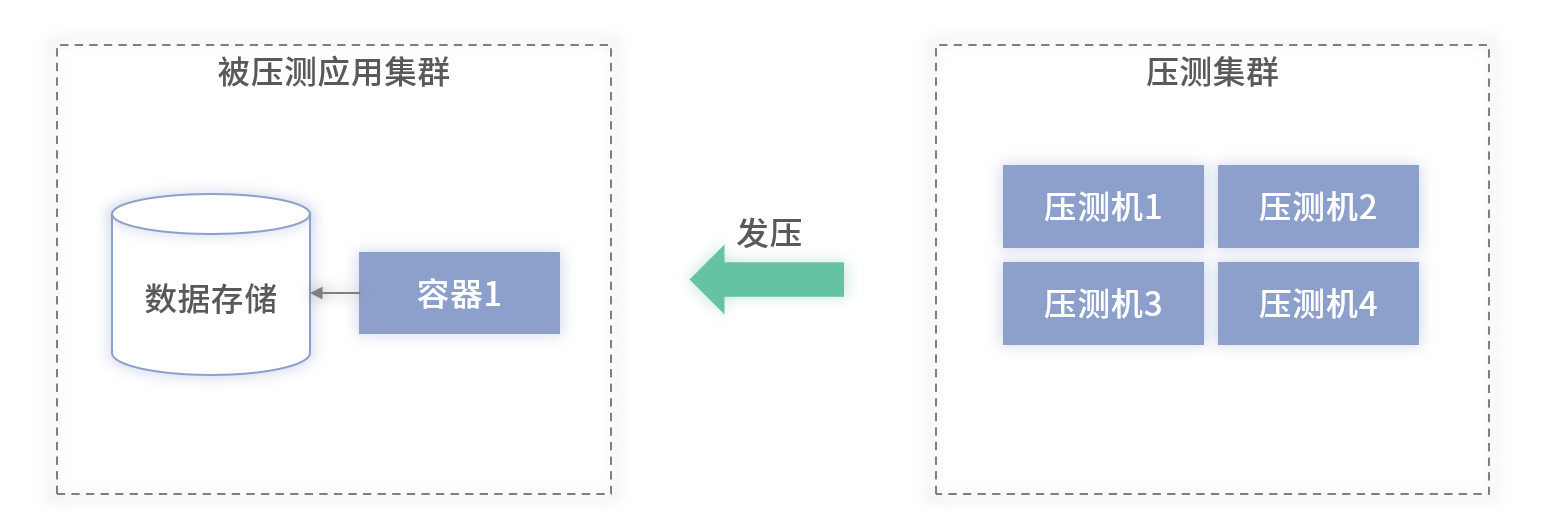
- 单机压测时,常见 CPU 或内存先饱和,得出单机最大 QPS。
2. 多机扩容非线性
-
网络共享、进程切换、存储竞争导致 QPS 与机器数不线性增长。
-
实战方法:依次部署 2、4、8……台,测出每种规模的 QPS,计算“损耗比”。
- 如:1 台 QPS=100,2 台 QPS=180,4 台 QPS=360,损耗比约 10%。
3. 存储与下游最短板
** 带存储依赖的架构**
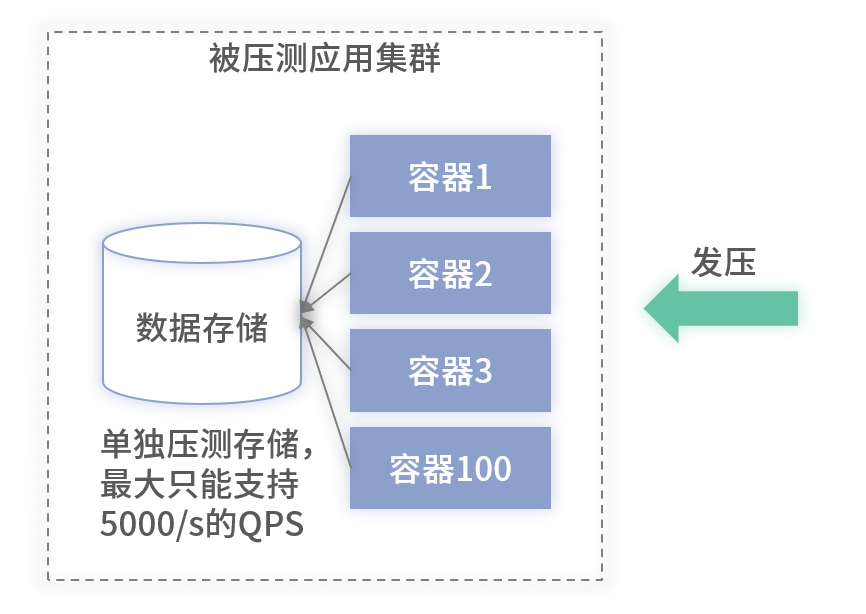
- 如果存储上限为 5000/s,即使扩容至 100 台,整体 QPS 也受限于 5000/s。
- 因此,需对存储及关键依赖分别压测,找出系统的最短板。
三、有状态写服务的高保真方案
写请求不能简单回放,以免造成线上数据污染。两种主流做法:
1. 模拟替换或数据修改
- 模拟账号替换:将录制请求中的用户 ID 换为测试账号,不影响真实用户。
- 公有资源打标:比如新闻投稿,将状态默认设为“待审核”,不对外可见。
2. 数据打标 + 影子库
影子库架构
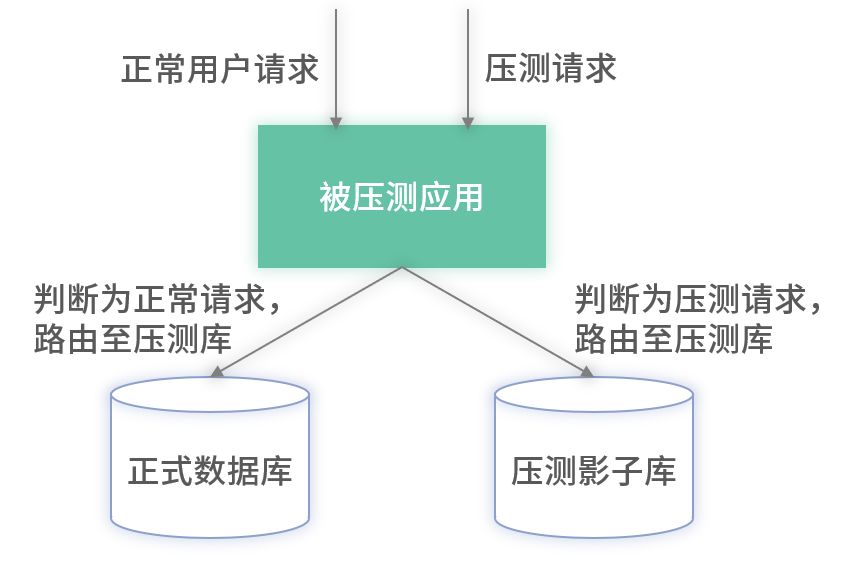
- 请求打标:压测请求统一加标识。
- 应用识别:若检测到压测标识,写入影子库而非生产库。
- 全链路透传:下游服务同样识别标识,将压测数据写入各自影子存储,实现线上级别的环境。
四、基于压测结果的优化与限流规划
1. 瓶颈分析与代码优化
- CPU 消耗聚焦:通过线程/堆栈定位“重 CPU”方法(如 JSON 序列化、深度循环)。
- 慢 SQL 诊断:若存储先饱和,检查索引命中、分页策略等,进行 SQL 优化。
2. 限流阈值设置
-
适度打折:单机压测 QPS=100/s,但 CPU 达到 100%,实际安全负载在 40–50%。
- 建议限流设置 = QPS × 40%。
-
多接口综合:若服务有多个 API,还需再 ÷ 接口数量。
-
集群维度:同样参照损耗比及存储上限,设置集群级限流,确保整体稳定。
小结
- 高保真压测:录制生产流量,原样回放;关键在于日志下发和影子库策略。
- 多维压测:单机、集群、存储及下游依赖皆需测。
- 结果利用:优化热点代码与慢 SQL;据此制定合理的单机及集群限流阈值。




















 2029
2029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











