










思维导图
概述
在讨论Oracle的性能问题时,通常要假设一个前提,那就是这个系统是OLTP还是OLAP(或者说数据仓库系统)。 只有在这个前提下,讨论一些性能问题才有意义,因为这两类系统太不一样了,甚至很多技术是相悖的。
举个例子 我们说绑定变量,这是一个在OLTP系统上有意义的话题,而对于OLAP系统却完全没有意义,设置不需要它。 再比如说内存命中率,OLTP系统中这个指标非常重要,因为OLTP系统中内存的效率决定了数据库的效率;而OLAP系统中却不太需要关注它。 在OLAP系统,SQL语句的执行效率决定了数据库的效率,而OLTP系统中,SQL语句的执行效率通常是很高的。
并行和OLAP系统
如果讨论数据库性能方面的问题,这个技术就不应该忽略,如果要把并行也像上面划一个使用范围的话,我认为应该是OLAP系统的一个重要的技术。
我们下看下并行执行的处理模型举例:
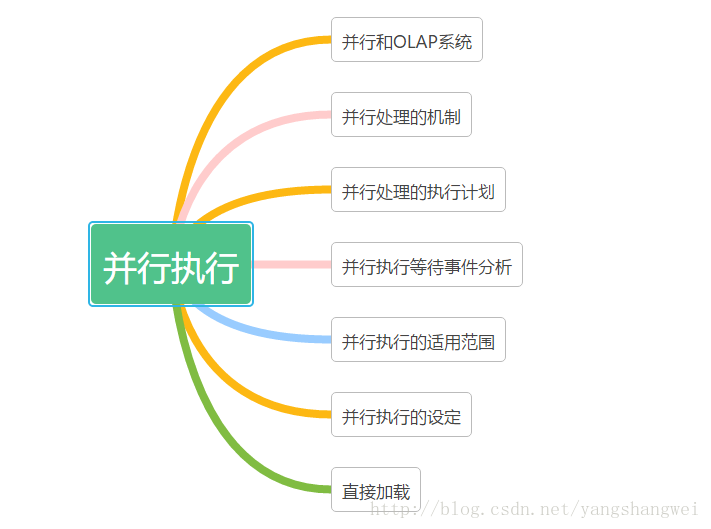
首先,Oracle 会创建一个进程用于协调并行服务进程之间的信息传递,这个协调进程将需要操作的数据集(比如表的数据块)分割成很多部分,称为并行处理单元,然后并行协调进程给每个并行进程分配一个数据单元。
比如有四个并行服务进程,他们就会同时处理各自分配的单元,当一个并行服务进程处理完毕后,协调进程就会给它们分配另外的单元,如此反复,直到表上的数据都处理完毕,最后协调进程负责将每个小的集合合并为一个大集合作为最终的执行结果,返回给用户。
并行处理的机制实际上就是把一个要扫描的数据集分成很多小数据集,Oracle 会启动几个并行服务进程同时处理这些小数据集,最后将这些结果汇总,作为最终的处理结果返回给用户。
这种数据并行处理方式在OLAP系统中非常有用,OLAP系统的表通常来说都是非常大,如果系统的CPU比较多,让所有的CPU共同来处理这些数据,效果就会比串行执行要高的多。
然而对于OLTP系统,通常来讲,并行并不合适,原因是OLTP系统上几乎在所有的SQL操作中,数据访问路劲基本上以索引访问为主,并且返回结果集非常小,这样的SQL 操作的处理速度一般非常快,不需要启用并行。
话不多说,上案例:
注意 alter table t parallel 4;
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0
Connected as xxx@xgj
SQL> create table t as select object_id ,object_name from dba_objects;
Table created
SQL> create index ind_t on t(object_id);
Index created
SQL> exec dbms_stats.gather_table_stats(user,'t',cascade => true);
PL/SQL procedure successfully completed
SQL> alter table t parallel 4;
Table altered我们查看下下面SQL的执行计划
SQL> select * from t where t.object_id=10433;
OBJECT_ID OBJECT_NAME
---------- --------------------------------------------------------------------------------
10433 KU$_PFHTABPROP_VIEW
SQL> select a.SQL_ID ,a.CHILD_NUMBER from v$sql a where a.SQL_TEXT like 'select * from t where t.object_id=10433%';
SQL_ID CHILD_NUMBER
------------- ------------
1afhswsarn20q 0
SQL> select * from table(dbms_xplan.display_cursor('1afhswsarn20q',0));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
SQL_ID 1afhswsarn20q, child number 0
-------------------------------------
select * from t where t.object_id=10433
Plan hash value: 4013845416
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 2 (100)|
| 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 24 | 2 (0)| 00:00
|* 2 | INDEX RANGE SCAN | IND_T | 1 | | 1 (0)| 00:00
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."OBJECT_ID"=10433)
19 rows selected
SQL> 上面的SQL是OLTP系统中比较典型的SQL,尽管在表上启用了并行属性,但是CBO并没有选择启用并行,原因是T表object_id字段重复率非常的低,这种情况下访问索引的代价非常小,可能只有几个逻辑读,所以没有必要启用并行.
在看下下面的SQL
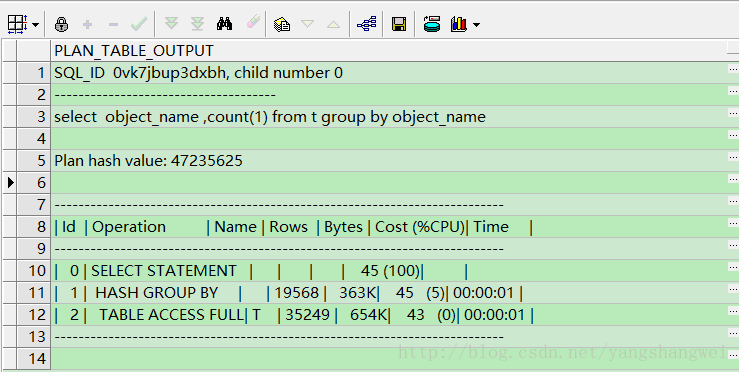
SQL>select object_name ,count(1) from t group by object_name;
....省略输出
SQL> select a.SQL_ID ,a.CHILD_NUMBER from v$sql a where a.SQL_TEXT like 'select object_name ,count(1) from t group by object_name%';
SQL_ID CHILD_NUMBER
------------- ------------
0vk7jbup3dxbh 0
SQL> select * from table(dbms_xplan.display_cursor('0vk7jbup3dxbh',0));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
SQL_ID 0vk7jbup3dxbh, child number 0
-------------------------------------
select object_name ,count(1) from t group by object_name
Plan hash value: 552882851
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 13 (100)|
| 1 | PX COORDINATOR | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 19568 | 363K| 13 (8)| 00:00:
| 3 | HASH GROUP BY | | 19568 | 363K| 13 (8)| 00:00:
| 4 | PX RECEIVE | | 35249 | 654K| 12 (0)| 00:00:
| 5 | PX SEND HASH | :TQ10000 | 35249 | 654K| 12 (0)| 00:00:
| 6 | PX BLOCK ITERATOR | | 35249 | 654K| 12 (0)| 00:00:
|* 7 | TABLE ACCESS FULL| T | 35249 | 654K| 12 (0)| 00:00:
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
---------------------------------------------------
7 - access(:Z>=:Z AND :Z<=:Z)
24 rows selected
SQL> 上面的SQL是OLAP系统比较典型的SQL,它的特点是需要对SQL做并行处理。 因为处理的数据量很大,所以这种情况使用了并行将更能提高效率。
上述就是并行执行的执行计划,如果还原成1
SQL> alter table t parallel 1;
Table altered执行计划如下,区别还是很明显的。
并行处理的机制
当Oracle 数据库启动的时候,实例会根据初始化参数:
PARALLEL_MIN_SERVERS=n的值来预先分配n个并行服务进程,当一条SQL 被CBO判断为需要并行执行时发出SQL的会话进程变成并行协助进程,它按照并行执行度的值来分配进程服务器进程。
首先协调进程会使用ORACLE 启动时根据参数: parallel_min_servers=n的值启动相应的并行服务进程,如果启动的并行服务器进程数不足以满足并行度要求的并行服务进程数,则并行协调进程将额外启动并行服务进程以提供更多的并行服务进程来满足执行的需求。
然后并行协调进程将要处理的对象划分成小数据片,分给并行服务进程处理;并行服务进程处理完毕后将结果发送给并行协调进程,然后由并行协调进程将处理结果汇总并发送给用户。
以上是一个并行处理的基本流程。 实际上,在一个并行执行的过程中,还存在着并行服务进程之间的通信问题。
在一个并行服务进程需要做两件事情的时候,它会再启用一个进程来配和当前的进程完成一个工作,比如这样的一条SQL语句:
Select * from employees order by last_name;假设employees表中last_name 列上没有索引,并且并行度为4,此时并行协调进程会分配4个并行服务进程对表employees进行全表扫描操作,因为需要对结果集进行排序,所以并行协调进程会额外启用4个并行服务进程,用于处理4个进程传送过来的数据,这新启用的用户处理传递过来数据的进程称为父进程,用户传出数据(最初的4个并行服务进程)成为子进程,这样整个并行处理过程就启用了8个并行服务进程。
其中每个单独的并行服务进程的行为叫作并行的内部操作,而并行服务进程之间的数据交流叫做并行的交互操作。
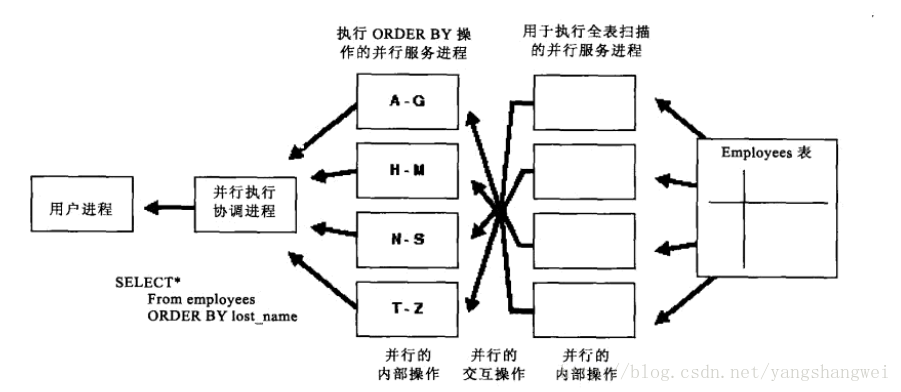
这也是有时我们发现并行服务进程数量是并行度的2倍,就是因为启动了并行服务父进程操作的缘故。
读懂一个并行处理的执行计划
搞清楚了并行执行的内部机制,就很容易读懂一个并行处理的执行计划了。
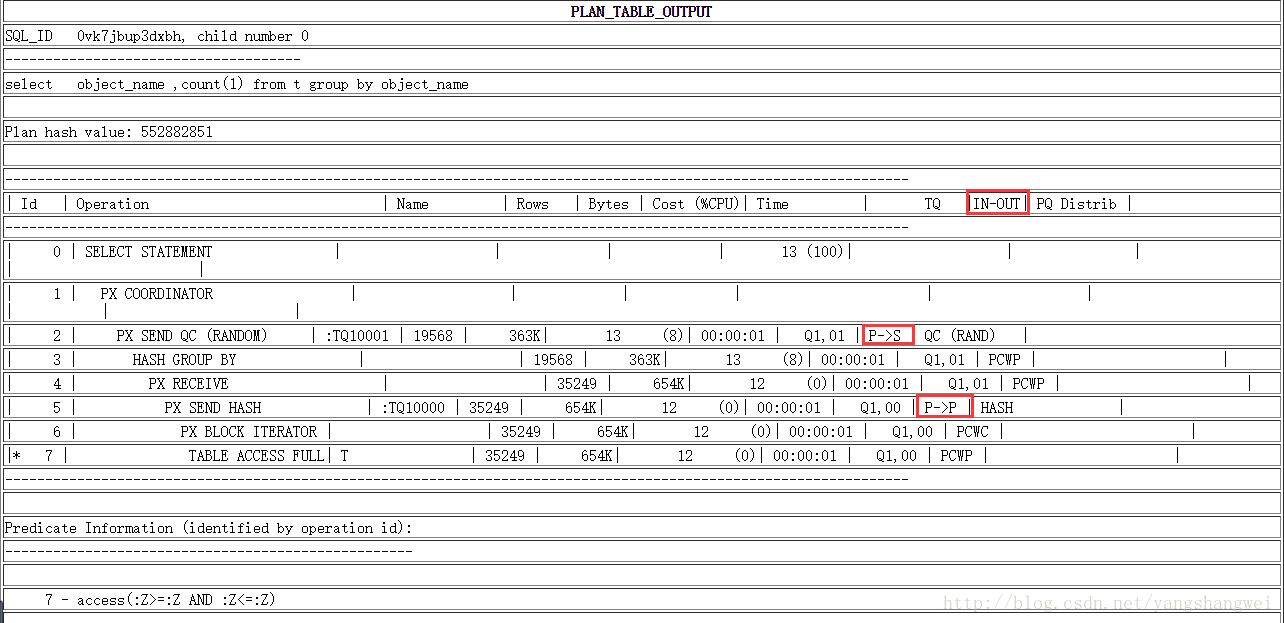
缩进最深的首先执行,依次类推
执行步骤:
(1)并行服务进程对t表进行全表扫描。
(2)并行服务进程以ITERATOR(迭代)方式访问数据块,也就是并行协调进程分给每个并行服务进程一个数据片,在这个数据片上,并行服务进程顺序地访问每个数据块(Iterator),所有的并行服务进程将扫描的数据块传给另一组并行服务进程(父进程)用于做Hash Group操作。
(3)并行服务父进程对子进程传递过来的数据做Hash Group操作。
(4)并行服务进程(子进程)将处理完的数据发送出去。
(5)并行服务进程(父进程)接收到处理过的数据。
(6)合并处理过的数据,按照随即的顺序发给并行协调进程(QC:Query Conordinator)。
(7)并行协调进程将处理结果发给用户。
PX:Parallel Execution (并行执行)
当使用了并行执行,SQL的执行计划中就会多出一列:in-out。 该列帮助我们理解数据流的执行方法.
常见值的含义:
- Parallel to Serial(P->S):
表示一个并行操作发送数据给一个串行操作,通常是并行incheng将数据发送给并行调度进程。
- Parallel to Parallel(P->P):表示一个并行操作向另一个并行操作发送数据,疆场是两个从属进程之间的数据交流。
- Parallel Combined with parent(PCWP): 同一个从属进程执行的并行操作,同时父操作也是并行的。
- Parallel Combined with Child(PCWC): 同一个从属进程执行的并行操作,子操作也是并行的。
- Serial to Parallel(S->P): 一个串行操作发送数据给并行操作,如果select 部分是串行操作,就会出现这个情况。
一个很常见的并行执行等待事件
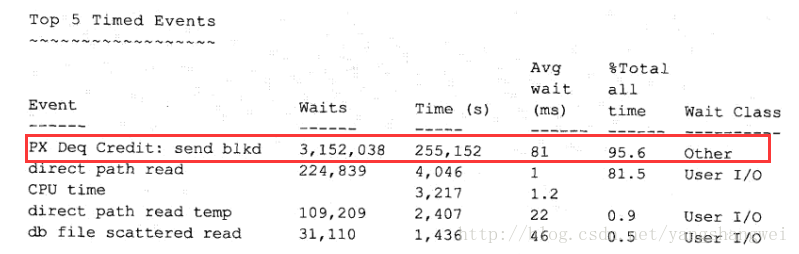
在做并行执行方面的性能优化的时候,可能会遇到如下等待时间:
PX Deq Credit: send blkd这是一个有并行环境的数据库中,从statspack 或者AWR中经常可以看到的等待事件.
比如在一个statspack的报告中有如下的信息:
QL> show param parallel
NAME TYPE VALUE
------------------------------------ ----------- ---------------------
fast_start_parallel_rollback string LOW
parallel_adaptive_multi_user boolean TRUE
parallel_automatic_tuning boolean FALSE
parallel_degree_limit string CPU
parallel_degree_policy string MANUAL
parallel_execution_message_size integer 16384
parallel_force_local boolean FALSE
parallel_instance_group string
parallel_io_cap_enabled boolean FALSE
parallel_max_servers integer 480
parallel_min_percent integer 0
parallel_min_servers integer 0
parallel_min_time_threshold string AUTO
parallel_server boolean FALSE
parallel_server_instances integer 1
parallel_servers_target integer 192
parallel_threads_per_cpu integer 2
recovery_parallelism integer 0
SQL> 在Oracle 9i 里面, 这个等待事件被列入空闲等待。一般来说空闲等待可以忽略它,但是实际上空闲等待也是需要关注的,因为一个空闲的等待,它反映的是另外的资源已经超负荷运行了。 基于这个原因,在Oracle 10g里已经把PX Deq Credit: send blkd等待时间不在视为空闲等待,而是列入了Others 等待事件范围。
PX Deq Credit: send blkd 等待事件的意思是: 当并行服务进程向并行协调进程QC(也可能是上一层的并行服务进程)发送消息时,同一时间只有一个并行服务进程可以向上层进程发送消息,这时候如果有其他的并行服务进程也要发送消息,就只能等待。直到获得一个发送消息的信用信息(Credit),这时候会触发这个等待事件,这个等待事件的超时时间为2秒钟。
如果我们启动了太多的并行进程,实际上系统资源(CPU)或者QC 无法即时处理并行服务发送的数据,那么等待将不可避免。 对于这种情况,我们就需要降低并行处理的并行度。
我们通过show param parallel查看数据库中最多可以启动480个并行进程。
parallel_max_servers 480 报告中同时也可以看到大量的direct path read ,direct path temp ,db file scattered read
一般direct path read 或者 db file scattered read ,通常来讲都是使用并行操作。
当出现PX Deq Credit:send blkd等待的时间很长时,我们可以通过平均等待时间来判断等待事件是不是下层的并行服务进程空闲造成的。
该等待事件的超时时间是2秒,如果平均等待时间也差不多是2秒,就说明是下层的并行进程“无事所做”,处于空闲状态。
如果和2秒的差距很大,就说明不是下层并行服务超时导致的空闲等待,而是并行服务之间的竞争导致的,因为这个平均等待事件非常短,说明并行服务进程在很短时间的等待之后就可以获取资源来处理数据。
所以对于非下层的并行进程造成的等待,解决的方法就是降低每个并行执行的并行度,比如对象(表,索引)上预设的并行度或者查询Hint 指定的并行度。
并行执行的适用范围
Oracle的并行技术在下面的场景中可以使用:
- Parallel Query(并行查询)
- Parallel DDL(并行DDL操作,如建表,建索引等)
- Parallel DML(并行DML操作,如insert,update,delete等)
并行查询
并行查询可以在查询语句,子查询语句中使用,但是不可以使用在一个远程引用的对象上(如DBLINK).
一个查询能够并行执行,需要满足一下条件:
(1) SQL语句中有Hint提示,比如Parallel 或者 Parallel_index.
(2) SQL语句中引用的对象被设置了并行属性。
(3) 多表关联中,至少有一个表执行全表扫描(Full table scan)或者跨分区的Index range SCAN。
如:
select /*+parallel(t 4) * from t;并行DDL 操作
表操作的并行执行
以下表操作可以使用并行执行:
CREATE TABLE … AS SELECT
ALTER TABLE … move partition
Alter table … split partition
Alter table … coalesce partition
DDL操作,我们可以通过trace 文件来查看它的执行过程。
查看当前的trace 文件:
SELECT u_dump.VALUE
|| '/'
|| db_name.VALUE
|| '_ora_'
|| v$process.spid
|| NVL2 (v$process.traceid, '_' || v$process.traceid, NULL)
|| '.trc'
"Trace File"
FROM v$parameter u_dump
CROSS JOIN
v$parameter db_name
CROSS JOIN
v$process
JOIN
v$session
ON v$process.addr = v$session.paddr
WHERE u_dump.name = 'user_dump_dest'
AND db_name.name = 'db_name'
AND v$session.audsid = SYS_CONTEXT ('userenv', 'sessionid');然后用tkprof分析。
创建索引的并行执行
创建索引时使用并行方式在系统资源充足的时候会使性能得到很大的提高,特别是在OLAP系统上对一些很大的表创建索引时更是如此。
以下的创建和更改索引的操作都可以使用并行:
Create index
Alter index … rebuild
Alter index … rebuild partition
Alter index … split partition
一个简单的语法:
create index t_ind on t(id) parallel 4;监控这个过程和上面一样,需要通过10046事件。
使用并行方式,不论是创建表,修改表,创建索引,重建索引,他们的机制都是一样的,那就是Oracle 给每个并行服务进程分配一块空间,每个进程在自己的空间里处理数据,最后将处理完毕的数据汇总,完成SQL的操作。
并行DML 操作
Oracle 可以对DML操作使用并行执行,但是有很多限制。 如果我们要让DML 操作使用并行执行,必须显示地在会话里执行如下命令:
SQL> alter session enable parallel dml;只有执行了这个操作,Oracle 才会对之后符合并行条件的DML操作并行执行,如果没有这个设定,即使SQL中指定了并行执行,Oracle也会忽略它。
delete,update和merge 操作
Oracle 对Delete,update,merge的操作限制在,只有操作的对象是分区表示,Oracle 才会启动并行操作。原因在于,对于分区表,Oracle 会对每个分区启用一个并行服务进程同时进行数据处理,这对于非分区表来说是没有意义的。
insert 的并行操作
实际上只有对于insert into … select … 这样的SQL语句启用并行才有意义。 对于insert into .. values… 并行没有意义,因为这条语句本身就是一个单条记录的操作。
Insert 并行常用的语法是:
insert /*+parallel(t 2) */ into t select /*+parallel(t1 2) */ * from t1;这条SQL 语句中,可以让两个操作insert 和select 分别使用并行,这两个并行是相互独立,互不干涉的,也可以单独使用其中的一个并行。
并行执行的设定
并行相关的初始化参数
parallel_min_servers=n
在初始化参数中设置了这个值,Oracle 在启动的时候就会预先启动N个并行服务进程,当SQL执行并行操作时,并行协调进程首先根据并行度的值,在当前已经启动的并行服务中条用n个并行服务进程,当并行度大于n时,Oracle将启动额外的并行服务进程以满足并行度要求的并行服务进程数量。
parallel_max_servers=n
如果并行度的值大于parallel_min_servers或者当前可用的并行服务进程不能满足SQL的并行执行要求,Oracle将额外创建新的并行服务进程,当前实例总共启动的并行服务进程不能超过这个参数的设定值。
parallel_adaptive_multi_user=true|false
Oracle 10g R2下,并行执行默认是启用的。 这个参数的默认值为true,它让Oracle根据SQL执行时系统的负载情况,动态地调整SQL的并行度,以取得最好的SQL 执行性能。
parallel_min_percent
这个参数指定并行执行时,申请并行服务进程的最小值,它是一个百分比,比如我们设定这个值为50. 当一个SQL需要申请20个并行进程时,如果当前并行服务进程不足,按照这个参数的要求,这个SQL比如申请到20*50%=10个并行服务进程,如果不能够申请到这个数量的并行服务,SQL 将报出一个ORA-12827的错误。
当这个值设为Null时,表示所有的SQL在做并行执行时,至少要获得两个并行服务进程。
并行度的设定
并行度可以通过以下三种方式来设定:
- 使用Hint 指定并行度。
SQL>Select /*+ parallel(t 4) */ count(*) from t;
- 使用alter session force parallel 设定并行度。
SQL>Alter session force parallel query parallel 4;- 使用SQL中引用的表或者索引上设定的并行度,原则上Oracle 使用这些对象中并行度最高的那个值作为当前执行的并行度。
SQL>Alter table t parallel 4;Oracle 默认并行度计算方式
Oracle 根据CPU的个数,RAC实例的个数以及参数parallel_threads_per_cpu的值,计算出一个并行度。
对于并行访问分区操作,取需要访问的分区数为并行度。
并行度的优先级别从高到低:
Hint->alter session force parallel->表,索引上的设定-> 系统参数
实际上,并行只有才系统资源比较充足的情况下,才会取得很好的性能,如果系统负担很重,不恰当的设置并行,反而会使性能大幅下降。
直接加载
在执行数据插入或者数据加载的时候,可以通过append hint的方式进行数据的直接加载。
在insert 的SQL中使用APPEND,如:
insert /*+append */ into t select * from t1;还可以在SQL*LOADER里面使用直接加载:
Sqlldr userid=user/pwd control=load.ctl direct=trueOracle 执行直接加载时,数据直接追加到数据段的最后,不需要花费时间在段中需找空间,数据不经过data buffer直接写到数据文件中,效率要比传统的加载方式高。















 1307
1307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











