









启动hadoop集群、启动hive的服务器端和客户端。
一、创建内部表
在weekend12客户端上执行如下命令:
创建表语句(默认是内部表)
create table teacher(id int ,name String ) row format delimited fields terminated by '\t';
row format delimited fields terminated by '\t'; 后缀的作用是指定行的分隔符以空格结束。
上传本地文件到表中
load data local inpath '/usr/local/teacher.txt' overwrite into table teacher;
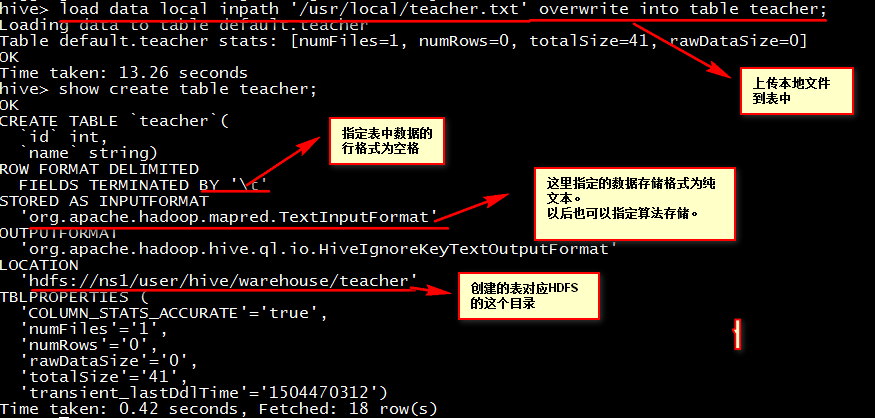
查看HDFS目录文件(http://weekend08:50070/dfshealth.jsp)
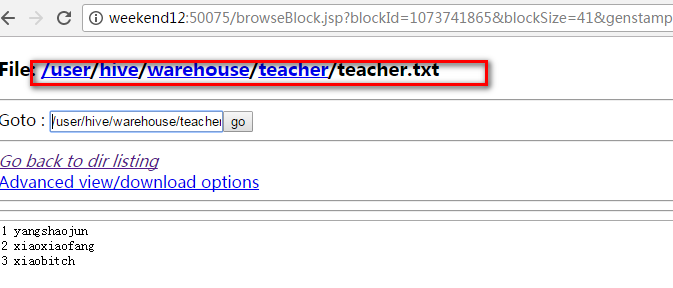
注意:创建内部表时,表对应的HDFS的目录就是我们配置Hive时指定的HDFS目录。外部表需要我们指定目录。
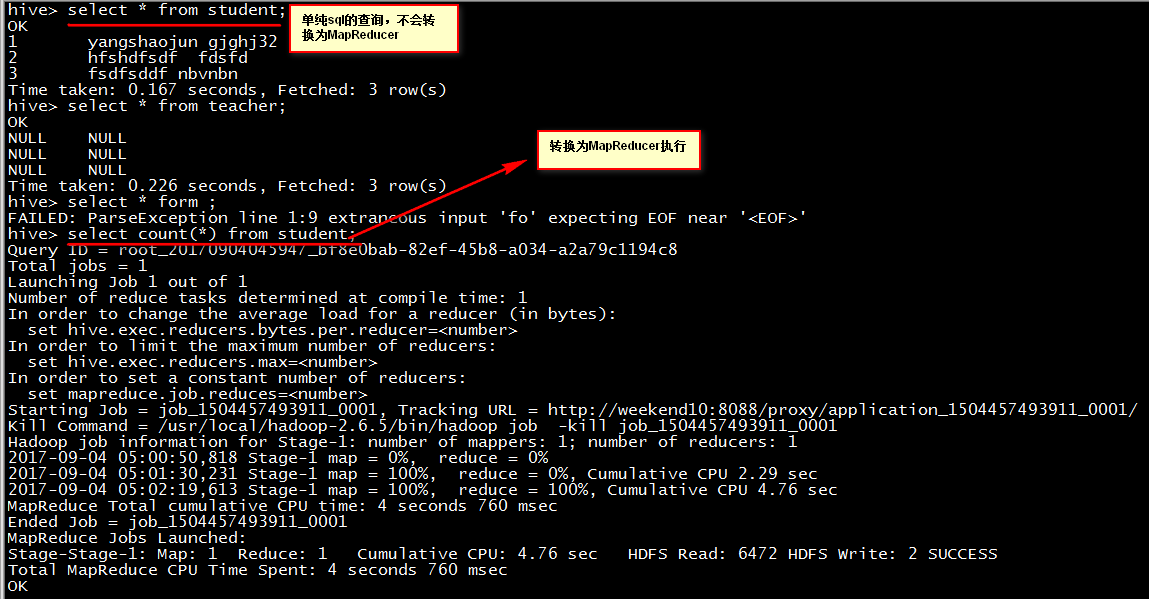
练习:
create table student(id int, name string) row format delimited fields terminated by ',';
load data local inpath '/usr/local/student' overwrite into table student;
row format delimited fields terminated by ',';后缀的作用是指定行的分隔符以逗号结束。
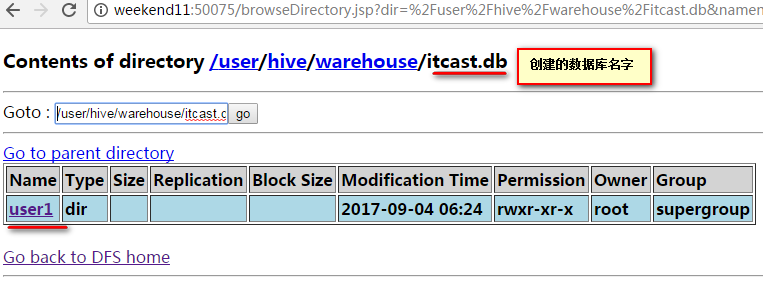
二、在Hive客户端创建数据库
create table user1(id int ,name String ) row format delimited fields terminated by '\t';

三、创建外部表
create external table psn3 (
id int,
name string,
likes ARRAY<string>,
address MAP<string, string>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LOCATION '/psn3';
注意: LOCATION '/psn3'; 指定表存储在HDFS的目录。
建完表后加载如下数据到表中(这些数据存储在 /usr/local/data1.txt 文件下面)
likes爱好
address住址
1,xiaoming1,book-sleep-mv,beijing:xisanqi-shanghai:pudong
2,xiaoming2,book-sleep-mv,beijing:xisanqi-shanghai:pudong
3,xiaoming3,book-sleep-mv,beijing:xisanqi-shanghai:pudong
4,xiaoming4,book-sleep-mv,beijing:xisanqi-shanghai:pudong
5,xiaoming5,book-sleep-mv,beijing:xisanqi-shanghai:pudong
执行命令: load data local inpath '/usr/local/data1.txt' into table psn3;
load data inpath '/psn3/data1.txt' into table psn3;
注意:当创建完表加载数据的时候,不加local关键字 是指上传hdfs文件到表中。
加local 是指上传的linux本地文件到数据表中。

命令:show create table o_re_st_webflow(表名); 用来查看创建的表的语句信息。


命令:show partitions o_re_st_webflow(表名) :用来查看表的分区情况
四、内部表和外部表的区别
内部表删除操作:表的结构信息,元数据信息,以及HDFS中的数据信息都会删除。
外部表的删除操作:只是删除表的结构,以及表的元数据信息。而HDFS中的数据没有删除。
五、分区表
上传本地文件data1.txt 到hdfs根目录: hdfs dfs -put /usr/local/data1.txt /
create table psn4 (
id int,
name string,
likes ARRAY<string>,
address MAP<string, string>
)
partitioned by (sex string)
ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':';
#####################################
查看表的描述信息
desc formatted psn4;
desc psn4;
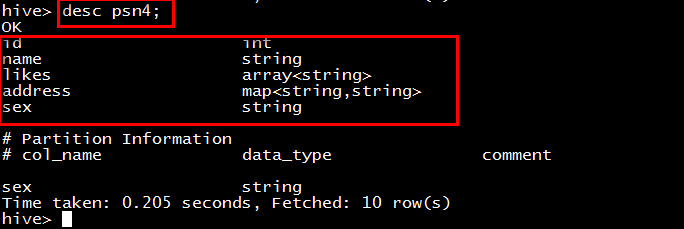
注意:发现分区的字段最后也是我们表的字段。所以说在创建分区表的时候不能把创建的字段作为分区的字段。分区的字段需要额外的指定。
load data local inpath '/usr/local/data1.txt' into table psn4 partition (sex='man');
load data local inpath '/usr/local/data2.txt' into table psn4 partition (sex='woman');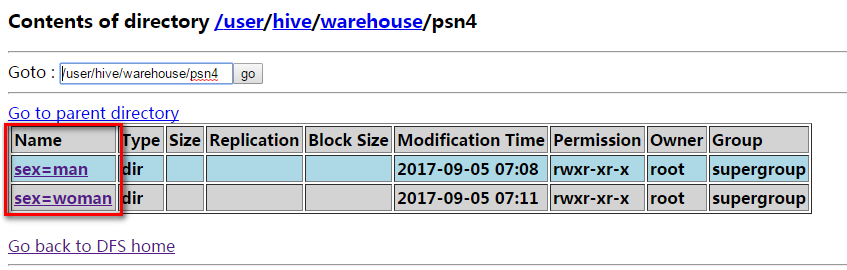
通过上图发现创建的分区对应着子目录。
根据分区进行查询
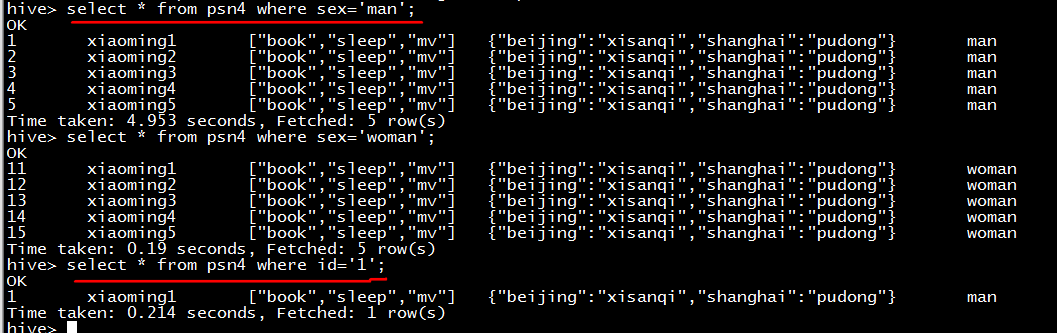
总结:创建分区表的目的:提高数据的查询效率。
就像上面的两条查询语句;分区的查询只是查询了当前分区的数据;而根据id进行查询是从整个表中查询的数据。所以说通过分区进行查询可以大大的提高 查询的效率。
创建两个分区字段的分区表
create table psn7 (
id int,
name string,
likes ARRAY<string>,
address MAP<string, string>
)
partitioned by (sex string,age int)
ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
load data local inpath '/usr/local/data1.txt' into table psn6 partition (sex='man',age=31);
load data local inpath '/usr/local/data2.txt' into table psn6 partition (sex='woman',age=18);
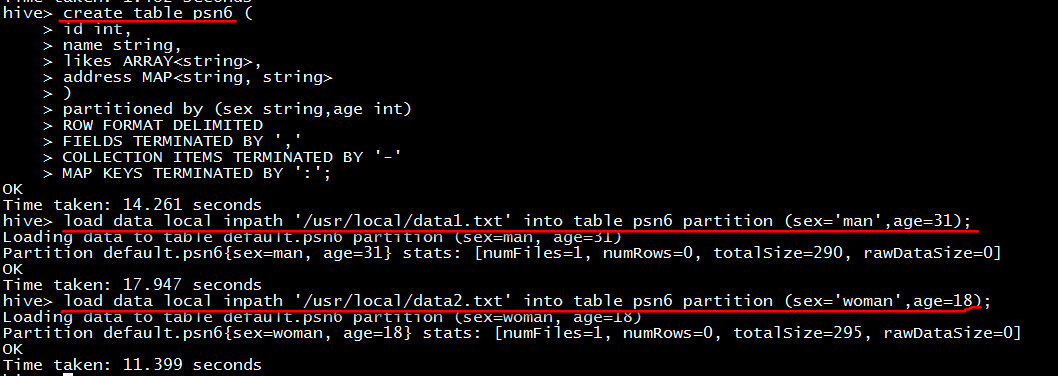
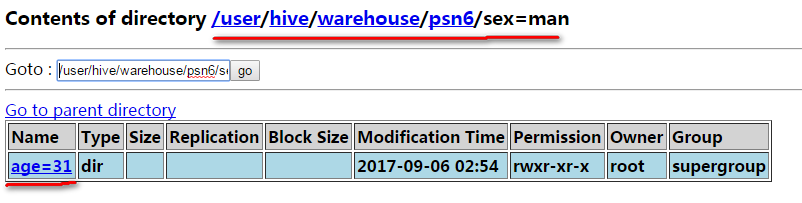

在man分区的基础上在创建age=19和18的分区
alter table psn6 add partition (sex='man',age=19);
alter table psn6 add partition (sex='man',age=18);
在man分区的基础上在删除age=18的分区
create table psn8 like psn6;
复制表操作:复制的表结构和表的数据。
create table psn10 as select id,name,likes from psn6;
create table jg (ct int);
from psn6 insert into table jg select count(*);//将psn6表的记录数插入到jg表中
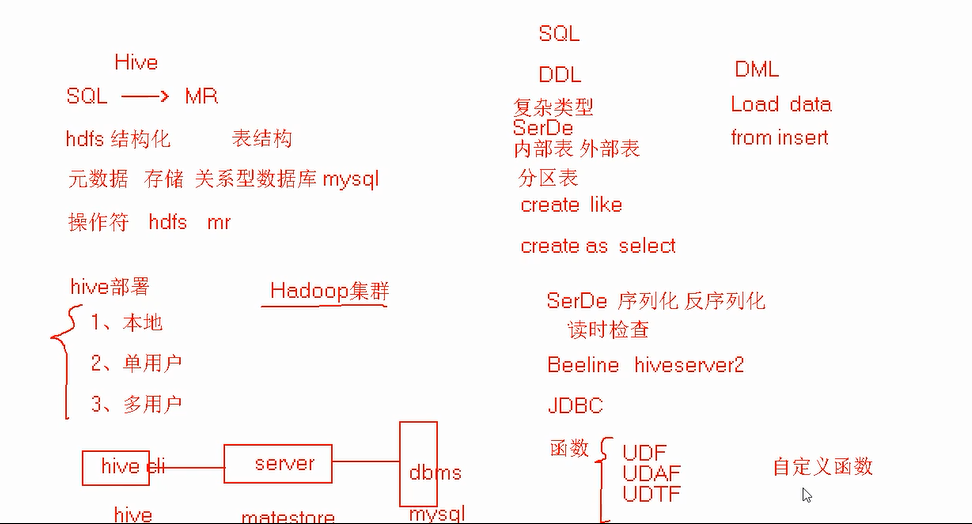
六、Hive SerDe(用的比较少)
Hive SerDe - Serializer and Deserializer
SerDe 用于做序列化和反序列化。
构建在数据存储和执行引擎之间,对两者实现解耦。
Hive通过ROW FORMAT DELIMITED以及SERDE进行内容的读写。
row_format
: DELIMITED
[FIELDS TERMINATED BY char [ESCAPED BY char]]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
: SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
Hive正则匹配
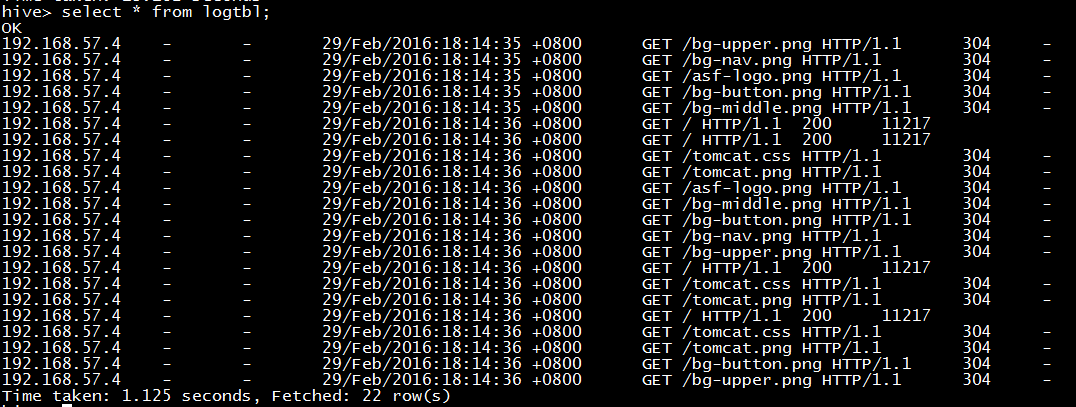
CREATE TABLE logtbl (
host STRING,
identity STRING,
t_user STRING,
time STRING,
request STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
)
STORED AS TEXTFILE;
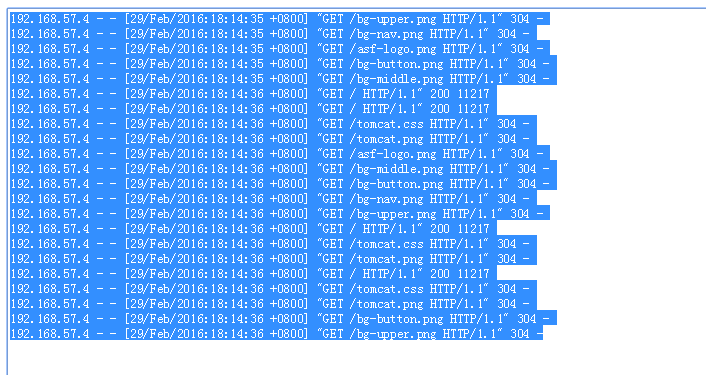
上传数据到创建的表中
load data local inpath '/usr/local/datalog' into table logtbl;
七、Hive Beeline(另外一种客户端)
Beeline 要与HiveServer2配合使用
服务端启动hiveserver2
客户的通过beeline两种方式连接到hive
1、beeline -u jdbc:hive2://localhost:10000/default -n root ###localhost为hive服务器端地址
2、beeline
beeline> !connect jdbc:hive2://<host>:<port>/<db>;auth=noSasl root 123
默认 用户名、密码不验证
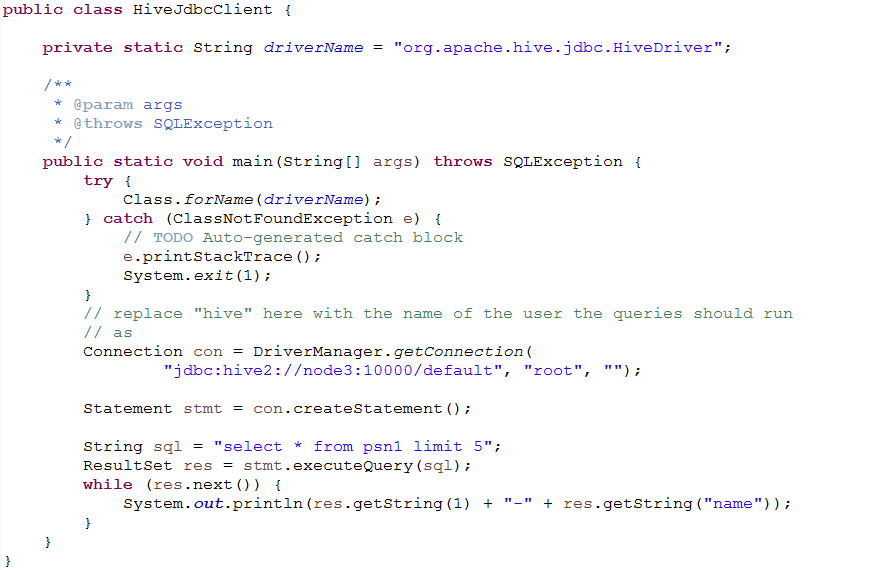
八、Hive (JDBC)
服务端启动hiveserver2后,在java代码中通过调用hive的jdbc访问默认端口10000进行连接、访问
九、Hive函数
1.内置运算符
--关系运算符
--算术运算符
--逻辑运算符
2.内置函数
--数学函数
--收集函数
--类型转换函数
--日期函数
--条件函数
--字符函数
3.内置的聚合函数(UDAF)
4.内置表生成函数(UDTF)
5.自定义函数
自定义函数包括三种UDF、UDAF、UDTF
十、总结















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









