







1.HDFS安装
1.配置hdfs的NameNode(core-site.xml)
vi hadoop-2.7.2/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://kafka1:9000</value>
<description>配置NameNode的URL</description>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/ysw/hadoop/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
2.配置HDFS路径(hdfs-site.xml)
vi hadoop-2.7.2/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/ysw/hadoop/hadoop-2.7.2/data/namenode</value>
<description>NameNode存储名称空间和事务日志的本地文件系统上的路径</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/ysw/hadoop/hadoop-2.7.2/data/datanode</value>
<description>DataNode存储名称空间和事务日志的本地文件系统上的路径</description>
</property>
</configuration>
3.启动HDFS
(a)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
bin/hdfs namenode -format
(b)启动NameNode
sbin/hadoop-daemon.sh start namenode
(c)启动DataNode
sbin/hadoop-daemon.sh start datanode
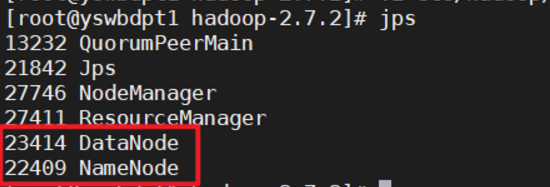
查看是否启动成功
jps
4.web端查看HDFS文件系统
http://kafka1:50070/dfshealth.html#tab-overview
5.操作hdfs
1.在HDFS文件系统上创建一个文件夹命名为input
bin/hdfs dfs -mkdir -p /user/ysw/input


2.将测试文件内容上传到文件系统上
现在本地任意位置新建文件
vi b.txt
写入如下内容:
hello hdfs
hello hdfs
hello hdfs
hello hdfs
hello hdfs
hello hdfs
将b.txt文件内容上传到HDFS文件系统上
bin/hdfs dfs -put input/hdfs/b.txt /user/ysw/input/

在页面上查上传到hdfs文件

使用命令查上传到hdfs文件
bin/hdfs dfs -ls /user/ysw/input/
bin/hdfs dfs -cat /user/ysw/ input/b.txt

2.YARN安装
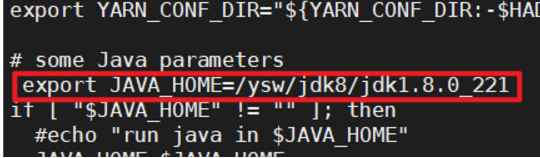
1.配置yarn-env.sh
配置一下JAVA_HOME, 如果已经配置了环境的JAVA_HOME这里可以不配置
2.配置yarn-site.xml
vi etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
<description>为每个容器请求分配的最小内存限制资源管理器(512M)</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
<description>为每个容器请求分配的最大内存限制资源管理器(4G)</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>虚拟内存比例,默认为2.1,此处设置为4倍</description>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>kafka1</value>
</property>
</configuration>
3.启动yarn
(a)启动前必须保证NameNode和DataNode已经启动
(b)启动ResourceManager
sbin/yarn-daemon.sh start resourcemanager
(c)启动NodeManager
sbin/yarn-daemon.sh start nodemanager
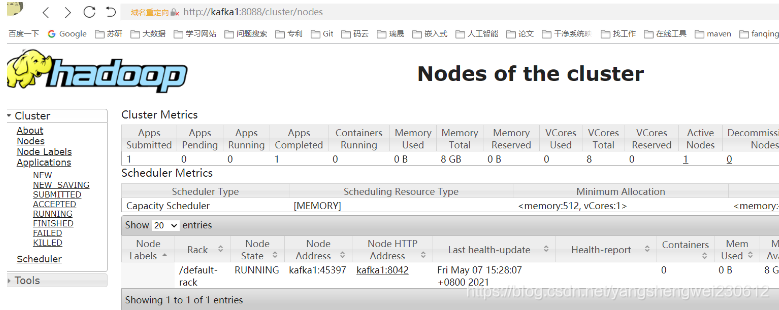
(a)YARN的浏览器页面查看
http://kafka1:8088/cluster
3.MapReduce程序在YARN模式运行
1.配置集群在YARN上运行MR
配置:mapred-env.sh
配置一下JAVA_HOME, 如果已经配置了环境的JAVA_HOME这里可以不配置
配置mapres的运行模式为yarn
配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>执行MapReduce的方式:yarn/local</description>
</property>
</configuration>
2.MapReduce程序在YARN模式运行
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/ysw/input/b.txt /user/ysw/output


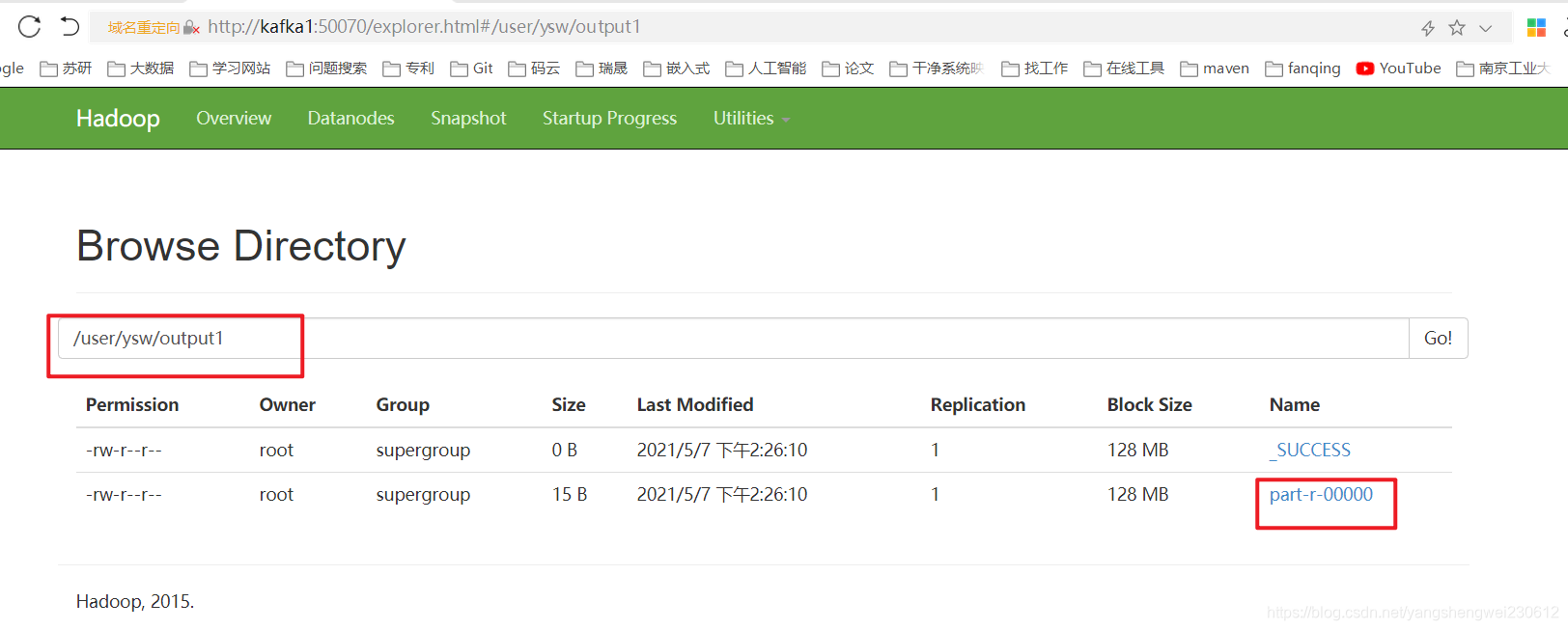
3.yarn 查看结果

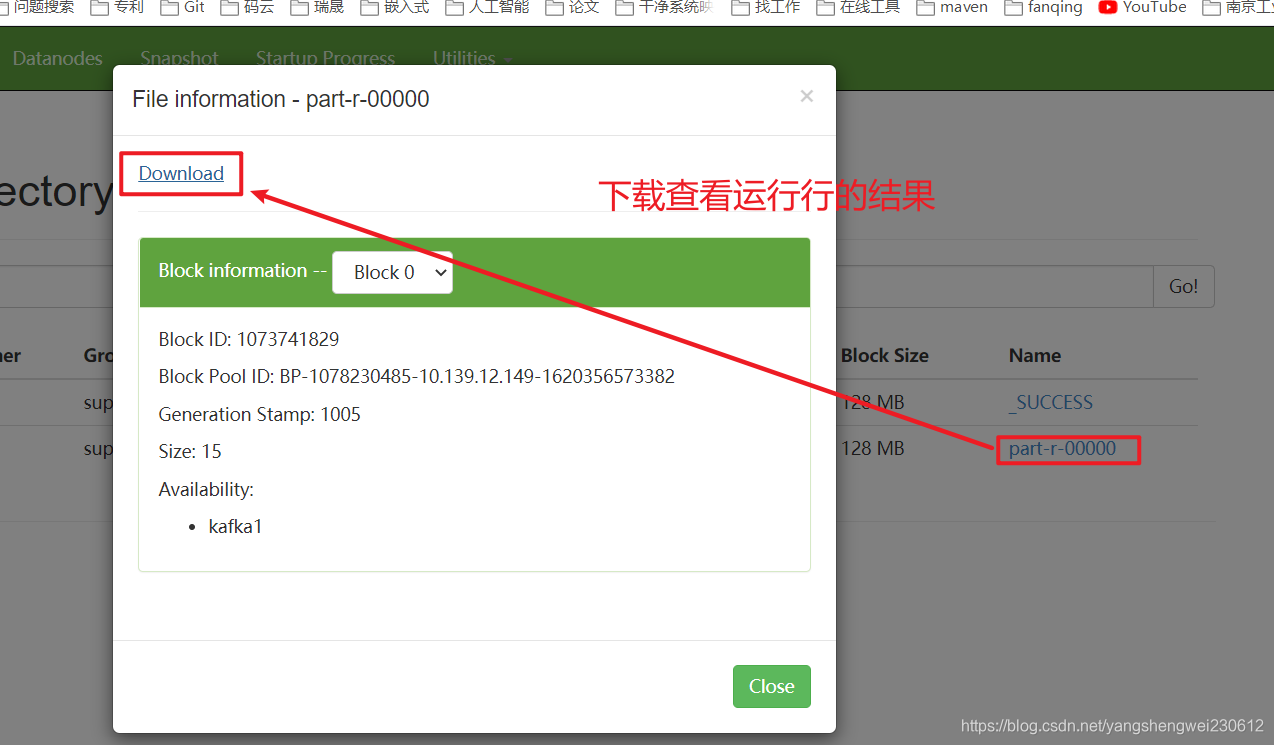
















 4699
4699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









