






GroundingDINO
于2023年由清华大学、IDEA 研究院联合提出。GLIP是基于传统的one-stage detector结构,而Grounding DINO是一个双encoder单decoder结构,它包含了1个image backbone(Swin Transformer)用于提取多尺度图像特征,1个text backbone用于提取文本特征,1个feature enhancer用于融合图像和文本特征,1个language-guide query selection模块用于query初始化,1个cross-modality decoder用于bbox预测。
论文:https://arxiv.org/pdf/2303.05499
官方源码:https://github.com/IDEA-Research/GroundingDINO
解读:https://zhuanlan.zhihu.com/p/627646794
官方的GroundingDino只开源了推理的代码,没有给出训练代码,数据集格式也未知,而Open-GroundingDino是作为GroundingDino的第三方实现训练的开源代码,关注GroundingDino的工作是否适合迁移到个人数据集中。
Open-GroundingDino
https://github.com/longzw1997/Open-GroundingDino
__Open-GroundingDino 和 GroundingDino是两个源码 __
以下是配置文件注释说明,以作记录。
data_aug_scales = [480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800] #随机缩放尺度
data_aug_max_size = 1333 # 缩放后图像最长边最大值
data_aug_scales2_resize = [400, 500, 600] # 第二次随机缩放
data_aug_scales2_crop = [384, 600] # 第二次随机裁剪
data_aug_scale_overlap = None # 缩放比例
batch_size = 4 # 批大小
modelname = 'groundingdino' # 模型名称
backbone = 'swin_T_224_1k' # 骨干网络:swin_T_224_1k 对应预训练模型 gdinot-1.8m-odvg.pth swin_B_384_22k 对应预训练模型 groundingdino_swinb_cogcoor.pth
position_embedding = 'sine' # 位置编码方式
pe_temperatureH = 20 # 位置编码参数
pe_temperatureW = 20 # 位置编码参数
return_interm_indices = [1, 2, 3] # 返回的中间层索引
enc_layers = 6 # Transformer的编码层数
dec_layers = 6 # Transformer的解码层数
pre_norm = False # 是否使用预归一化
dim_feedforward = 2048 # 前向传播维度
hidden_dim = 256 # 隐藏层维度
dropout = 0.0 # dropout率
nheads = 8 # 注意力头数
num_queries = 900 # 查询数
query_dim = 4 # 查询维度
num_patterns = 0 # 模式数
num_feature_levels = 4 # 特征层数
enc_n_points = 4 # 编码点数
dec_n_points = 4 # 解码点数
two_stage_type = 'standard' # 两阶段类型
two_stage_bbox_embed_share = False # 是否共享bbox嵌入
two_stage_class_embed_share = False # 是否共享类别嵌入
transformer_activation = 'relu' # transformer激活函数
dec_pred_bbox_embed_share = True # 是否共享预测bbox嵌入
dn_box_noise_scale = 1.0 # 噪声比例
dn_label_noise_ratio = 0.5 # 标签噪声比例
dn_label_coef = 1.0 # 标签系数
dn_bbox_coef = 1.0 # 边框系数
embed_init_tgt = True # 是否初始化目标嵌入
dn_labelbook_size = 91 # 训练和推理的最大类别数量, 默认91
max_text_len = 256 # Visual Grounding任务的最大文本长度,目标检测任务不用修改
text_encoder_type = "bert-base-uncased" # 文本编码模型路径,提前下载更换成bert-base-uncased文件夹地址
use_text_enhancer = True # 是否使用文本增强器
use_fusion_layer = True # 是否使用融合层
use_checkpoint = True # 是否使用检查点
use_transformer_ckpt = True # 是否使用transformer检查点
use_text_cross_attention = True # 是否使用文本交叉注意力
text_dropout = 0.0 # 文本dropout率
fusion_dropout = 0.0 # 融合dropout率
fusion_droppath = 0.1 # 融合droppath率
sub_sentence_present = True # 是否使用子句
max_labels = 80 # pos + neg
lr = 0.0001 # base learning rate
backbone_freeze_keywords = None # only for gdino backbone
freeze_keywords = None # for whole model, e.g. ['backbone.0', 'bert'] for freeze visual encoder and text encoder
lr_backbone = 1e-05 # specific learning rate
lr_backbone_names = ['backbone.0', 'bert'] # 骨干网络名称
lr_linear_proj_mult = 1e-05 # 学习率乘数
lr_linear_proj_names = ['ref_point_head', 'sampling_offsets'] # 线性投影层名称
weight_decay = 0.0001 # 权重衰减
param_dict_type = 'ddetr_in_mmdet' # 参数字典类型
ddetr_lr_param = False # 是否使用ddetr学习率参数
epochs = 30 # 训练轮数
lr_drop = 10 # 学习率下降轮数. 每训练10轮,进行学习率更新,默认更新学习率=学习率*0.1
save_checkpoint_interval = 10 # 保存检查点间隔
clip_max_norm = 0.1 # 梯度裁剪最大范数
onecyclelr = False # 是否使用onecyclelr
multi_step_lr = False # 是否使用多步骤学习率
lr_drop_list = [10, 20] # 学习率下降轮数列表
frozen_weights = None # 冻结权重
dilation = False # 是否使用dilation
pdetr3_bbox_embed_diff_each_layer = False # 是否每个层使用不同的bbox嵌入
pdetr3_refHW = -1 # 参考点高度和宽度
random_refpoints_xy = False # 随机参考点xy
fix_refpoints_hw = -1 # 固定参考点高度和宽度
dabdetr_yolo_like_anchor_update = False # 是否使用yolo_like_anchor_update
dabdetr_deformable_encoder = False # 是否使用deformable_encoder
dabdetr_deformable_decoder = False # 是否使用deformable_decoder
use_deformable_box_attn = False # 是否使用deformable_box_attn
box_attn_type = 'roi_align' # 边框注意力类型
dec_layer_number = None # 解码层数
decoder_layer_noise = False # 是否使用decoder_layer_noise
dln_xy_noise = 0.2 # 噪声比例
dln_hw_noise = 0.2 # 噪声比例
add_channel_attention = False # 是否添加通道注意力
add_pos_value = False # 是否添加位置值
two_stage_pat_embed = 0 # 第二阶段模式嵌入
two_stage_add_query_num = 0 # 第二阶段添加查询数
two_stage_learn_wh = False # 第二阶段学习宽高
two_stage_default_hw = 0.05 # 第二阶段默认宽高
two_stage_keep_all_tokens = False # 第二阶段保留所有token
num_select = 300 # 最大候选目标个数
batch_norm_type = 'FrozenBatchNorm2d' # 批量归一化类型
masks = False # 是否使用掩膜
aux_loss = True # 是否使用辅助损失
set_cost_class = 1.0 # 设置损失类别
set_cost_bbox = 5.0 # 设置损失边框
set_cost_giou = 2.0 # 设置损失giou
cls_loss_coef = 2.0 # 类别损失系数
bbox_loss_coef = 5.0 # 边框损失系数
giou_loss_coef = 2.0 # giou损失系数
enc_loss_coef = 1.0 # 编码损失系数
interm_loss_coef = 1.0 # 中间损失系数
no_interm_box_loss = False # 是否不使用中间边框损失
mask_loss_coef = 1.0 # 掩膜损失系数
dice_loss_coef = 1.0 # 掩膜损失系数
focal_alpha = 0.25 # 掩膜损失系数
focal_gamma = 2.0 # 掩膜损失系数
decoder_sa_type = 'sa' # 解码注意力类型
matcher_type = 'HungarianMatcher' # 匹配器类型
decoder_module_seq = ['sa', 'ca', 'ffn'] # 解码模块序列
nms_iou_threshold = -1 # nms iou阈值,默认-1表示不使用nms,如果使用nms,则需要设置阈值,如nms_iou_threshold=0.5
dec_pred_class_embed_share = True # 是否共享预测类别嵌入
match_unstable_error = True # 是否使用不稳定的匹配错误
use_detached_boxes_dec_out = False # 是否使用分离的边框输出
dn_scalar = 100 # 缩放比例
use_coco_eval = True # 是否使用coco评估, 默认True, 需要修改为False
label_list = ['cat','dog'] # 标签名列表
注意:
use_coco_eval 默认是True。如果实际训练类型不是coco的类别数量时,会有如下报错
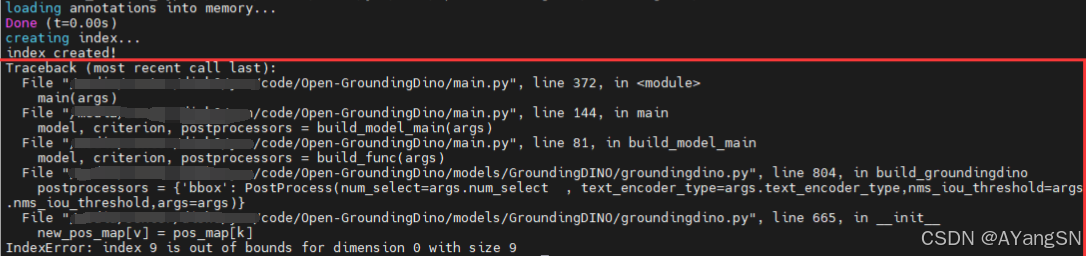
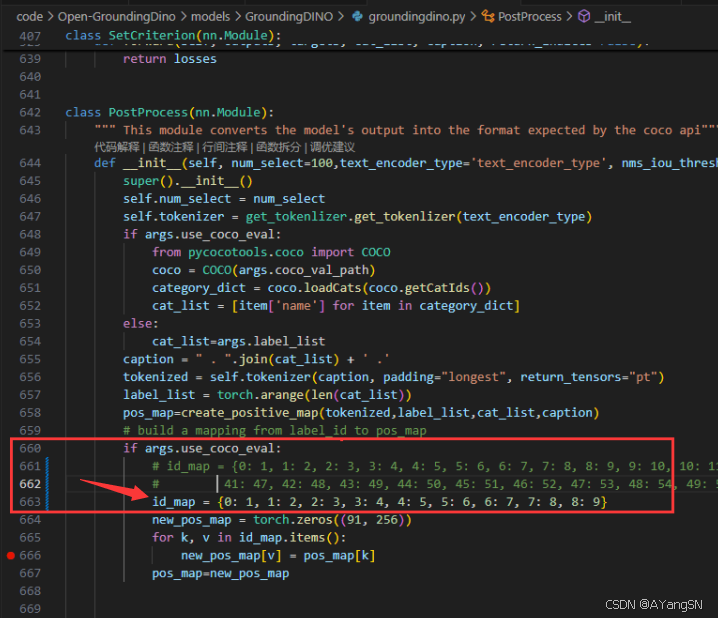
当然也可以修改code/Open-GroundingDino/GroundingDINO/groundingdino/models/GroundingDINO/groundingdino.py中的id_map值与自己训练数量一致即可成功执行训练。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









