







MyBatis学习笔记
架构篇
架构图

接口层
- 接口层是mybatis提供给开发人员的一套API,主要使用SqlSession接口。通过SqlSession接口和Mapper接口,开发人员可以通知mybatis调用那一条SQL命令以及SQL命令关联参数。
数据处理层
- 数据处理层是mybatis框架内部实现,来完成对数据库具体操作,主要负责:
- 参数与SQL命令绑定
- SQL命令发送方式
- 查询结果类型转换
支撑层
- 支撑层用来完成mybatis与数据库基本连接方式以及SQL命令与配置文件交互,主要负责:
- mybatis与数据库连接方式管理
- mybatis对事务管理方式
- SQL命令与XML配置对应
- mybatis查询缓存管理
架构流程图

- mybatis配置文件:SqlMapConfig.xml 作为mybatis的全局配置文件,配置了mybatis的运行环境等信息;Mapper.xml 作为mybatis的sql映射文件,配置了操作数据库的sql语句,此文件需要在SqlMapConfig.xml中加载。
- SqlSessionFactory:通过mybatis环境配置信息构造SqlSessionFactory——会话工厂。
- SqlSession:通过会话工厂创建SqlSession——会话,程序员通过SqlSession会话接口对数据库进行增删改查操作。
- Executor执行器:mybatis底层自定义了Executor执行器接口来具体操作数据库,Executor接口有两个实现。一个是基本执行器(默认)、一个是缓存执行器。SqlSession底层是通过Executor接口操作数据库的。
- MappedStatement:它也是mybatis一个底层封装对象,它包装了mybatis配置信息及sql映射信息等。mapper.xml文件中一个select\insert\update\delete 标签对应一个MappedStatement对象,select\insert\update\delete 标签的id即是Mapped Statement的id。
- MappedStatement 对sql执行输入参数定义,包括HashMap、基本类型、pojo,Executor通过Mapped Statement在执行sql前将输入的java对象映射到sql中,输入参数映射就是jdbc编程中对preparedStatement设置参数。
- MappedStatement 对 sql执行输出结果定义,包括HashMap、基本类型、pojo,Executor通过Mapped Statement在执行sql后将输出结果映射到java对象中,输出结果映射的过程相当于jdbc编程中对结果的解析处理过程。

调用流程图

- SqlSession:接收开发人员提供的 StatementID和参数,并返回操作结果。
- Executor:Mybatis执行器,是Mybatis调度的核心,负责SQL语句的生成和查询缓存的维护。
- StatementHandler:封装了JDBC Statement操作,负责对JDBC statement的操作,如:设置参数、将Statement结果集转换成List集合。
- ParameterHandler:负责对用户传递的参数转换为JDBC Statement所需要的参数。
- ResultSetHandler:负责将JDBC返回的ResultSet结果集对象转换成List类型的集合。
- TypeHandler:负责Java数据类型和jdbc数据类型之间的映射和转换。
- MappedStatement:维护一条<select|update|delete|insert>节点的封装。
- SqlSource:负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回BoundSql表示动态生成的Sql语句以及相应的参数信息。
- Configuration:Mybatis所有的配置信息都维持在Configuration对象之中。
进阶篇-Mybatis应用
应用列表
- 主键返回
- 批量查询
- 动态传参
- 多表关联查询
- 查询缓存
- 延迟加载
- 逆向工程
- PageHelper分页插件
主键返回
- 映射文件
<!-- 添加用户,主键返回 -->
<insert id="insertUser" parameterType="user">
<!--
主键返回配置
注意事项: order只有自增主键时,才是AFTER,否则为BEFORE
selectKey中SQL语句,不是死的,这个语句只能获取自增主键的ID
-->
<selectKey keyProperty="id" order="AFTER" resultType="int">
select LAST_INSERT_ID()
<!-- SELECT UUID() 此种主键返回,需要注意结果类型问题 -->
</selectKey>
insert into
user(username, birthday, sex, address)
values(#{username}, #{birthday}, #{sex}, #{address})
</insert>
- Mapper接口
public interface UserMapper {
// 主键返回
void insertUser(User user);
}
- 测试代码
/**
* 测试主键返回
* 啥应用场景?提交订单(订单表、订单明细表[需要订单ID]、配送信息表)
*/
@Test
public void testInsertUser(){
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = new User();
user.setUsername("老大");
user.setSex("男");
user.setAddress("XX大厦");
userMapper.insertUser(user);
sqlSession.commit();
System.out.println("返回主键值是:" + user.getId());
}
批量查询
- 映射文件
<!-- 批量查询(方式一) -->
<select id="batchQueryByQueryVO" parameterType="UserQueryVO" resultType="user">
select * from user
<!--
动态SQL
where标签就是将后面的AND关键字去掉
-->
<where>
<!-- 注意:如果通过PO类的List类型的属性或者数组类型的属性传递参数时,参数名称就是属性名称 -->
<if test="idList!=null and idList.size()>0">
and id in
<foreach collection="idList" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</if>
<if test="user!=null">
<!-- 注意:字符串判断是否为空,要判断null和空串 -->
<if test="user.username!=null and user.username!=''">
and username like '%${user.username}%'
</if>
</if>
</where>
</select>
<!-- 批量查询 (方式二)-->
<select id="batchQueryByIdList" parameterType="java.util.List" resultType="user">
select * from user
<where>
<!-- 注意:如果直接传List类型或者数组类型的参数时,参数只能为list或者array -->
<if test="list!=null and list.size()>0">
<!--
and id in (1, 3, 5)
and id=1 or id=3 or id=5
-->
and id in
<foreach collection="list" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</if>
</where>
</select>
- UserQueryVO
public class UserQueryVO {
private User user;
// 批量ID
private List<Integer> idList;
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
public List<Integer> getIdList() {
return idList;
}
public void setIdList(List<Integer> idList) {
this.idList = idList;
}
}
- Mapper接口
public interface UserMapper {
// 批量查询
List<User> batchQueryByQueryVO(UserQueryVO vo);
List<User> batchQueryByIdList(List<Integer> idList);
}
- 测试代码
/**
* 测试批量查询
* 比如说:批量删除、根据id列表获取结果
*/
@Test
public void testBatchQuery(){
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<Integer> idList = new ArrayList<Integer>();
idList.add(1);
idList.add(3);
idList.add(5);
List<User> list1 = userMapper.batchQueryByIdList(idList);
System.out.println("批量查询结果1:" + list1);
UserQueryVO vo = new UserQueryVO();
vo.setIdList(idList);
User user = new User();
user.setUsername("张三");
vo.setUser(user);
List<User> list2 = userMapper.batchQueryByQueryVO(vo);
System.out.println("批量查询结果2:" + list2);
}
动态SQL
- 动态SQL的思想就是使用不同的动态SQL标签去完成字符串的拼接处理,解决的问题是:
- 在映射文件中,会编写很多有重叠部分的SQL语句,比如select语句和where语句等这些重叠语句
- 如果页面传递过来一个参数,但是SQL语句中的条件有多个,此时会发生问题
if标签
- 综合查询的案例中,查询条件是由页面传入,页面中的查询条件可能输入用户名,也可能不输入用户名,例如:
<select id="findUserList" parameterType="UserQueryVO" resultType="user">
select * from user where 1=1
<if test="user!=null">
<!-- 注意:字符串判断是否为空,要判断null和空串 -->
<if test="user.username!=null and user.username!=''">
and username like '%${user.username}%'
</if>
</if>
</select>
where标签
- 上边的sql中的1=1,虽然可以保证sql语句的完整性,但是存在SQL安全问题和性能问题,mybatis提供了where标签来解决该问题。例如:
<select id="findUserList" parameterType="UserQueryVO" resultType="user">
select * from user
<where>
<if test="user!=null">
<!-- 注意:字符串判断是否为空,要判断null和空串 -->
<if test="user.username!=null and user.username!=''">
and username like '%${user.username}%'
</if>
</if>
</where>
</select>
sql片段
- 在映射文件中可使用sql标签将重复的sql提取出来,然后使用include标签引用即可,最终达到sql重用的目的。例如:
<sql id="query_user_where">
<if test="user!=null">
<!-- 注意:字符串判断是否为空,要判断null和空串 -->
<if test="user.username!=null and user.username!=''">
and username like '%${user.username}%'
</if>
</if>
</sql>
<select id="findUserList" parameterType="UserQueryVO" resultType="user">
select * from user
<where>
<include refid="query_user_where"></include>
</where>
</select>
- 注意:如果引用其他mapper.xml的sql片段,则在引用时需要加上namespace,例如:
<include refid="namespace.sql片段"/>
foreach标签
- 综合查询时,传入多个id查询用户信息,例如:
<foreach collection="list" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
- 注意:如果parameter为java.util.List,那么collection的属性值必须是list,如果parameter为java.util.Array,那么collection的属性值必须是array。查阅 mybatis 源码:TypeAliasRegistry.java
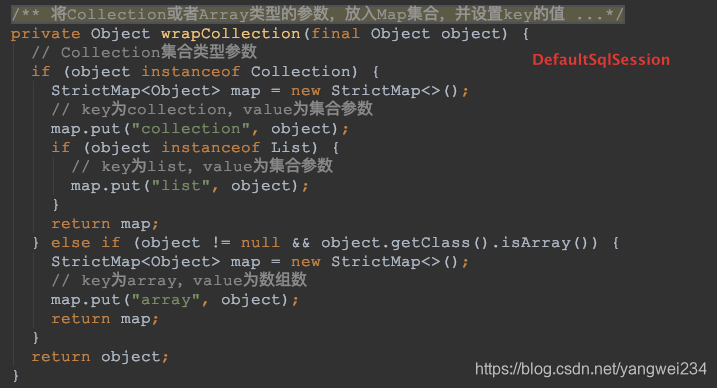
查询缓存
- Mybatis提供查询缓存,如果缓存中有数据就不用从数据库中获取,用于减轻数据库压力,提高提供性能。Mybatis的查询缓存总共有两级,我们称为一级缓存和二级缓存

- 一级缓存是SqlSession级别的缓存。在操作数据库时需要构造SqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据,不同的SqlSession之间的缓存数据区域(HashMap)是相互不影响的。
- 二级缓存是Mapper(namespace)级别的缓存。多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
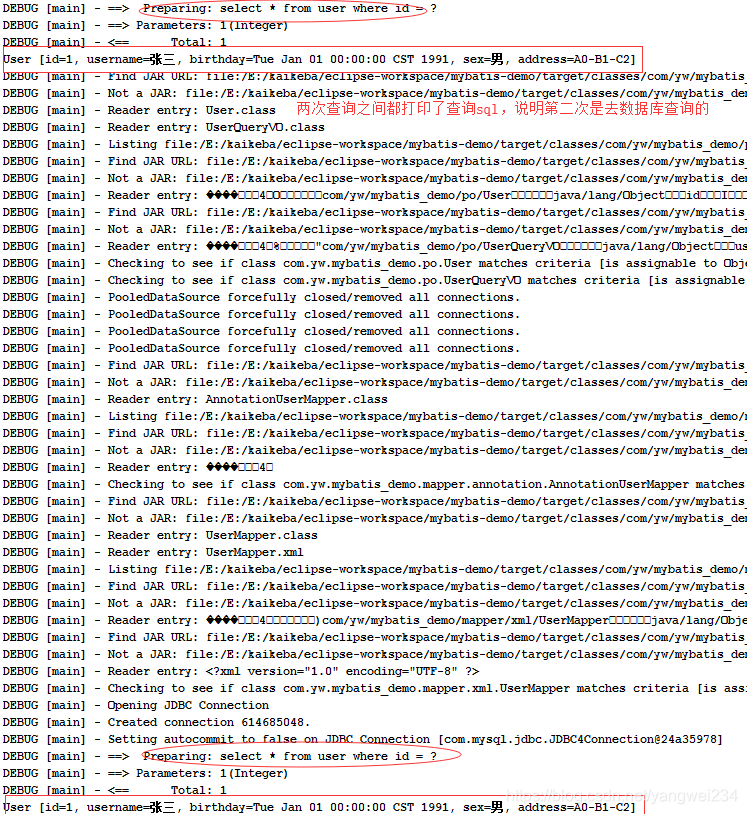
一级缓存
- Mybatis默认是开启一级缓存的,原理图

- 测试代码
@Test
public void testOneLevelCache() throws Exception{
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
// 第一次查询ID为1的用户,去缓存找,找不到就去查找数据库
User user1 = userMapper.findUserById(1);
System.out.println(user1);
// 第二次查询ID为1的用户
User user = userMapper.findUserById(1);
System.out.println(user);
sqlSession.close();
}

@Test
public void testOneLevelCache() throws Exception{
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
// 第一次查询ID为1的用户,去缓存找,找不到就去查找数据库
User user1 = userMapper.findUserById(1);
System.out.println(user1);
User user = new User();
user.setUsername("OneLevelCache");
user.setAddress("Cache");
// 执行增删改操作,清空缓存
userMapper.insertUser(user);
// 第二次查询ID为1的用户
User User = userMapper.findUserById(1);
System.out.println(User);
sqlSession.close();
}
二级缓存
基本使用
- Mybatis默认是没有开启二级缓存的,开启方式是:在全局配置文件SqlMapConfig.xml中加入以下内容(开启二级缓存总开关)
<settings>
<!-- 开启二级缓存总开关 -->
<setting name="cacheEnabled" value="true"/>
</settings>
- 在UserMapper.xml映射文件中,加入以下内容,开启二级缓存
<!-- 开启com.yw.mybatis.example.mapper.xml.UserMapper命名空间下的二级缓存 -->
<cache />
- 实现序列化:由于二级缓存的数据不一定都是存储到内存中,它的存储介质多种多样,比如说存储到文件系统中,所以需要给缓存的对象执行序列化。如果该类存在父类,那么父类也要实现序列化。
@Data
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private int id;
private String username;
private Date birthday;
private String sex;
private String address;
}
- 测试代码
@Test
public void testTwoLevelCache() throws Exception{
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class);
// 第一次查询ID为1的用户,去缓存找,找不到就去查找数据库
User user1 = mapper1.findUserById(1);
System.out.println(user1);
// 关闭SqlSession1
sqlSession1.close();
// 第二次查询ID为1的用户
User user2 = mapper2.findUserById(1);
System.out.println(user2);
// 关闭SqlSession2
sqlSession2.close();
}
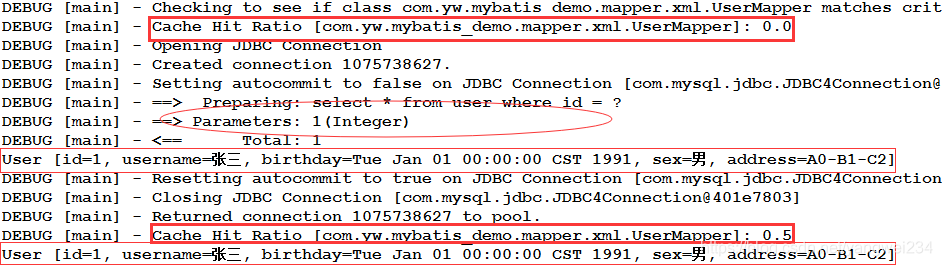
- Cache Hit Radio : 缓存命中率:第一次缓存中没有记录,则命中率0.0;第二次缓存中有记录,则命中率0.5(访问两次,有一次命中)。
禁用二级缓存
- 默认二级缓存的粒度是Mapper级别的,但是如果在同一个Mapper文件中某个查询不想使用二级缓存的话,就需要对缓存的控制粒度更细。
- 在select标签中设置 useCache=false,可以禁用当前select语句的二级缓存,即每次查询都是去数据库中查询,默认情况下是true,即该Statement使用二级缓存。
<select id="findUserById" parameterType="int" resultType="user" useCache="true">
select * from user where id = #{id}
</select>
刷新二级缓存
- 通过 flushCache 属性,可以控制select\insert\update\delete标签是否刷新二级缓存。默认设置:
- 如果是select语句,那么flushCache是false
- 如果是insert\update\delete,那么flushCache是true
- 默认配置解读
- 如果查询语句设置为true,那么每次查询都是去数据库查询,意味着该查询的二级缓存失效;
- 如果增删改语句设置为false,那么如果数据库中修改了数据,而缓存数据还是原来的,这个时候就会出现脏读。
应用场景
- 对于访问响应速度要求高,但是实时性不高的查询,可以采用二级缓存技术。
- 注意:在使用二级缓存时,要设置一下刷新间隔(cache标签中有一个flashInterval属性)来定时刷新二级缓存,这个刷新间隔根据具体需求来设置,比如设置:30分钟、60分钟等,单位为毫秒。
局限性
- Mybatis二级缓存对细粒度的数据级别的缓存实现不好。
- 场景:对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次查询都是最新的商品信息,此时如果使用二级缓存,就无法实现当一个商品发生变化只刷新该商品的缓存信息而不刷新其它商品缓存信息,因为二级缓存是 Mapper 级别的,当一个商品的信息发生更新,所有的商品信息缓存数据都会清空。
- 解决办法:此类问题,需要在业务层根据需要对数据有针对性的缓存。比如可以对经常变化的数据操作单独放到另一个 namespace 的 mapper 中。
多表关联查询
- 商品订单数据模型

一对一查询
- 需求:查询所有订单信息,关联查询下单用户信息。
- 映射文件:
<!-- 查询订单关联用户信息使用的resultMap -->
<resultMap type="OrdersExt" id="ordersAndUserRstMap">
<id column="id" property="id"/>
<result column="user_id" property="user_id"/>
<result column="number" property="number"/>
<result column="note" property="note"/>
<!--
一对一关系映射
property:Orders对象的user属性
javaType:user属性对应的类型
-->
<association property="user" javaType="user">
<id column="user_id" property="id"/>
<result column="username" property="username"/>
<result column="address" property="address"/>
</association>
</resultMap>
<!-- 一对一关联查询 -->
<select id="one2One" resultMap="ordersAndUserRstMap">
select orders.*, user.username, user.address
from orders left join user on orders.user_id = user.id
</select>
- 实体类:
// Orders.java
@Data
public class Orders {
private int id;
private int user_id;
private String number;
private String note;
}
// OrdersExt.java
@Data
public class OrdersExt extends Orders {
// 关联用户信息
private User user;
}
- Mapper接口
public interface UserMapper {
// 关联查询之一对一关联查询
List<OrdersExt> one2One();
}
- 测试代码
@Test
public void testOne2One(){
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<OrdersExt> list = userMapper.one2One();
System.out.println(list);
}
一对多查询
- 需求:查询所有用户信息及其用户关联的订单信息
- 映射文件:
<!-- 查询用户关联订单信息使用的resultMap -->
<resultMap type="UserExt" id="userAndOrderRstMap">
<!-- 用户信息映射 -->
<id column="id" property="id"/>
<result column="username" property="username"/>
<result column="birthday" property="birthday"/>
<result column="sex" property="sex"/>
<result column="address" property="address"/>
<!-- 一对多关系映射 -->
<collection property="orders" ofType="orders">
<id column="id" property="id"/>
<result column="user_id" property="user_id"/>
<result column="number" property="number"/>
<result column="note" property="note"/>
</collection>
</resultMap>
<!-- 一对多查询 -->
<select id="one2Many" resultMap="userAndOrderRstMap">
select user.*, orders.id, orders.number, orders.note
from user left join orders on user.id = orders.user_id
</select>
- 实体类:
// UserExt.java
@Data
public class UserExt extends User {
private static final long serialVersionUID = 1L;
private List<Orders> orders;
}
- Mapper接口
public interface UserMapper {
// 关联查询之一对多关联查询
List<UserExt> one2Many();
}
- 测试代码
@Test
public void testOne2Many(){
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<UserExt> list = userMapper.one2Many();
System.out.println(list);
}
延迟加载
什么是延迟加载
- Mybatis中的延迟加载,也称为懒加载,是指在进行关联查询时,按照设置延迟规则推迟对关联对象的select查询。延迟加载可以有效的减少数据库压力。
- Mybatis的延迟加载,需要通过resultMap标签中的association和collection子标签才能演示成功。
- Mybatis的延迟加载,也称为嵌套查询,对应的还有嵌套结果的概念,可以参考一对多关联的案例。
- 注意:Mybatis的延迟加载只是对关联对象的查询有延迟设置,对于主加载对象都是直接执行查询语句的。
延迟加载的分类
MyBatis根据对关联对象查询的select语句的执行时机,分为三种类型:
- 直接加载:执行完主加载对象的select语句,马上执行对关联对象的select查询。
- 侵入式延迟:执行对主加载对象的查询时,不会执行对关联对象的查询。但是要访问主加载对象的详情时,就会马上执行关联对象的select查询。即对关联对象的查询执行,侵入到了主加载对象的详情访问中。也可以这样理解:将关联对象的详情侵入到了主加载对象的详情中,即将关联对象的详情作为主加载对象的详情的一部分出现了。
- 深度延迟:执行对主加载对象的查询时,不会执行对关联对象的查询。访问主加载对象的详情时也不会执行关联对象的select语句。只有当真正访问关联对象的详情时,才会执行对关联对象的select语句。
案例
- 需求:查询订单信息及它的下单用户信息。
- 修改全局配置文件SqlMapConfig.xml:
<settings>
<!--
延迟加载总开关
true:开启延迟加载 false:直接加载
-->
<setting name="lazyLoadingEnabled" value="true"/>
<!--
侵入式延迟加载开关
true:侵入式延迟加载 false:深度延迟加载
-->
<setting name="aggressiveLazyLoading" value="false"/>
<!-- 开启二级缓存总开关 -->
<setting name="cacheEnabled" value="true"/>
</settings>
- 映射文件:
<!-- 延迟加载 -->
<resultMap type="OrdersExt" id="lazyOrdersAndUserRstMap">
<id column="id" property="id"/>
<result column="user_id" property="user_id"/>
<result column="number" property="number"/>
<result column="note" property="note"/>
<!--
select属性:加载完主信息之后,会根据延迟加载策略,去调用select属性指定的statementID
column属性:表示将主查询结果集中指定列的结果取出来,作为参数,传递给select属性的statement中
注意:如果select指定的statement,入参需要多个值,需要在column中{col1=prop1,col2=prop2}
-->
<association property="user" column="user_id" javaType="user"
select="com.yw.mybatis.example.mapper.xml.UserMapper.findUserById" />
</resultMap>
<select id="findOrdersAndUser" resultMap="lazyOrdersAndUserRstMap">
select * from orders
</select>
- Mapper接口
public interface UserMapper {
// 延迟加载
List<OrdersExt> findOrdersAndUser();
}
- 测试代码
@Test
public void testLazyLoading() throws Exception{
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
// 该行代码是否加载用户信息?直接加载会、侵入式延迟加载和深度延迟加载不会
List<OrdersExt> list = userMapper.findOrdersAndUser();
for (OrdersExt ordersExt : list) {
// 侵入式延迟加载会去查询用户信息\深度延迟不会
System.out.println(ordersExt.getNumber());
// 深度延迟加载不会去查询用户信息
System.out.println(ordersExt.getUser().getId());
}
}
N+1问题
- 深度延迟加载的使用会提升性能。
- 如果延迟加载的表数据太多,此时会产生N+1的问题,主信息加载一次算1次,而从信息是会根据主信息传递过来的条件,去查询从表多次。比如:查询用户信息及用户订单信息,使用深度延迟加载时,主信息只查询了一次,但是该用户如果订单很多(10000单),这个时候加载从信息(订单),会一次提交1万条查询语句,对数据库造成压力。
逆向工程
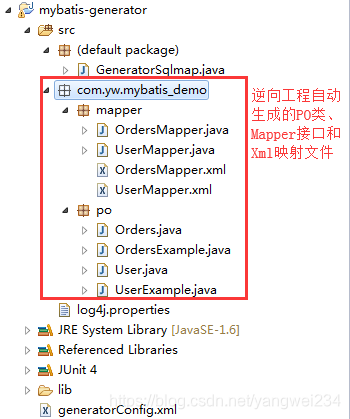
简介
- Mybatis逆向工程可以使用官方网站的 Mapper 自动生成工具 mybatis-generator-core-1.3.2 来针对单表生成po类(Example)、Mapper接口和mapper映射文件。
- 修改配置文件:在 generatorConfig.xml 中配置Mapper生成的详细信息,注意修改以下几点:
- 修改要生成的数据库表;
- pojo文件所在包路径;
- Mapper所在的包路径。
使用
- 配置文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<context id="testTables" targetRuntime="MyBatis3">
<commentGenerator>
<!--
是否去除自动生成的注释
true:是; false:否
-->
<property name="suppressAllComments" value="true" />
</commentGenerator>
<!-- 数据库连接的信息:驱动类、连接地址、用户名、密码 -->
<jdbcConnection driverClass="com.mysql.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/mybatis" userId="root"
password="yw@910714">
</jdbcConnection>
<!--
默认false,把JDBC DECIMAL 和 NUMERIC 类型解析为 Integer,
为 true时把JDBC DECIMAL 和 NUMERIC 类型解析为java.math.BigDecimal
-->
<javaTypeResolver>
<property name="forceBigDecimals" value="false" />
</javaTypeResolver>
<!-- targetProject:生成PO类的位置 -->
<javaModelGenerator targetPackage="com.yw.mybatis.example.po" targetProject=".\src">
<!-- enableSubPackages:是否让schema作为包的后缀 -->
<property name="enableSubPackages" value="false" />
<!-- 从数据库返回的值被清理前后的空格 -->
<property name="trimStrings" value="true" />
</javaModelGenerator>
<!-- targetProject:mapper映射文件生成的位置 -->
<sqlMapGenerator targetPackage="com.yw.mybatis.example.mapper" targetProject=".\src">
<!-- enableSubPackages:是否让schema作为包的后缀 -->
<property name="enableSubPackages" value="false" />
</sqlMapGenerator>
<!-- targetPackage:mapper接口生成的位置 -->
<javaClientGenerator type="XMLMAPPER" targetPackage="com.yw.mybatis.example.mapper" targetProject=".\src">
<!-- enableSubPackages:是否让schema作为包的后缀 -->
<property name="enableSubPackages" value="false" />
</javaClientGenerator>
<!-- 指定数据库表 -->
<!-- 需要 -->
<table tableName="user" domainObjectName="User">
<!-- 生成主键返回代码 -->
<generatedKey column="id" sqlStatement="MySql" identity="true"/>
</table>
<table tableName="orders"></table>
</context>
</generatorConfiguration>
- GeneratorSqlmap.java
public class GeneratorSqlmap {
public void generator() throws Exception{
List<String> warnings = new ArrayList<String>();
boolean overwrite = true;
// 指定逆向工程配置文件
File configFile = new File("generatorConfig.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config, callback, warnings);
myBatisGenerator.generate(null);
}
public static void main(String[] args) throws Exception {
try {
GeneratorSqlmap generatorSqlmap = new GeneratorSqlmap();
generatorSqlmap.generator();
} catch (Exception e) {
e.printStackTrace();
}
}
}
PageHelper分页插件
分页插件介绍
使用方法
- 添加依赖
<!-- 分页插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.1.6</version>
</dependency>
- 配置PageHelper:Mybatis全局配置文件
<!-- 配置插件 -->
<plugins>
<!-- 分页插件 -->
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<!-- config params as the following -->
<property name="helperDialect" value="mysql"/>
</plugin>
</plugins>
- 注意:配置顺序

- 与Spring整合时,Spring配置文件
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="plugins">
<array>
<bean class="com.github.pagehelper.PageInterceptor">
<property name="properties">
<value>
helperDialect=mysql
</value>
</property>
</bean>
</array>
</property>
</bean>
- 测试PageHelper
@Test
public void testPageHelper(){
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
// 获取第一页,10条内容,默认查询总数count
PageHelper.startPage(1, 10);
List<User> list = userMapper.selectAll();
// 用PageInfo对结果进行包装
PageInfo<List<User>> page = new PageInfo(list);
// 测试PageInfo全部属性
Assert.assertEquals(1, page.getPageNum());
Assert.assertEquals(10, page.getPageSize());
Assert.assertEquals(1, page.getStartRow());
Assert.assertEquals(4, page.getEndRow());
Assert.assertEquals(4, page.getTotal());
Assert.assertEquals(1, page.getPages());
Assert.assertEquals(true, page.isIsFirstPage());
Assert.assertEquals(true, page.isIsLastPage());
Assert.assertEquals(false, page.isHasPreviousPage());
Assert.assertEquals(false, page.isHasNextPage());
}
- 注意事项:需要分页的查询语句,必须是处于
PageHelper.startPage(1, 10);后面的第一条语句;如果查询语句是使用resultMap进行的嵌套结果映射,则无法使用PageHelper进行分页。 - plugin插件介绍参考网址:http://www.cnblogs.com/fangjian0423/p/mybatis-interceptor.html。















 187
187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











