







本文是:Windows编程基础 第二章 Unicode编码 NMAKE命令解释器
原文的pdf下载地址是:http://yunpan.cn/cd5b2QRyFqeMm 访问密码 9724
一、NMAKE和Makefile
1.1、 NMAKE - 命令解释器,根据Makefile文件中定义的脚本,完成项目的编译等操作。
1.2、Makefile - 定义编译/链接等脚本语言。
Makefile.mak 文件 注意用tab键而不是用空格
Nmake / ? 就可以看到nmake常用的一些参数。
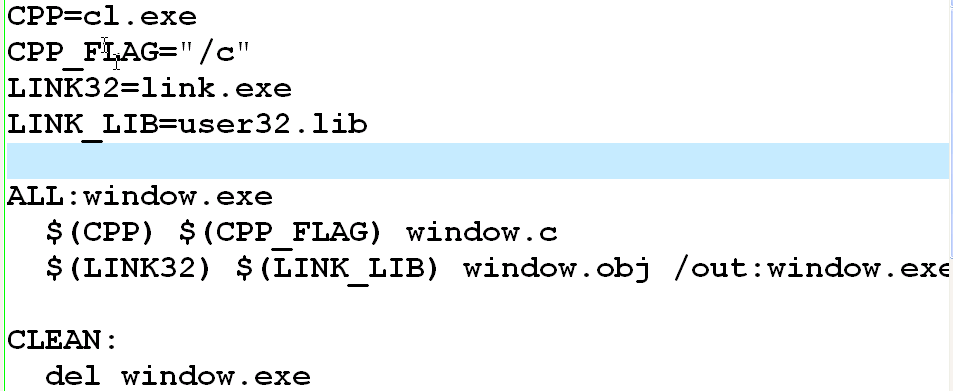
例如:window.exe:
cl.exe yang.c /c
link.exe yang.obj user32.lib
nmake /f makefile.mak
1.3 、Makefile文件的编写
1.3.1、基本语法规则
window.exe:window.obj // 依赖行
cl.exe window.c /c // 命令行
link.exe window.obj user32.lib
window.exe的依赖项是window.obj,如果 window.obj被重新改写,window.exe将重新生成.
通过时间戳(time stamp)判断程序是否需要重新编译链接,如果当文件修改最后时间与时间戳不同,将会重新编译链接。
【它有一个小的时间间隔,如果是2秒之内,修改的那么,他就不会重新的编译,但是如果是两秒之后修改的他就会重新的编译,注意有这么一个小的时间间隔。】
依赖项 命令行 时间戳

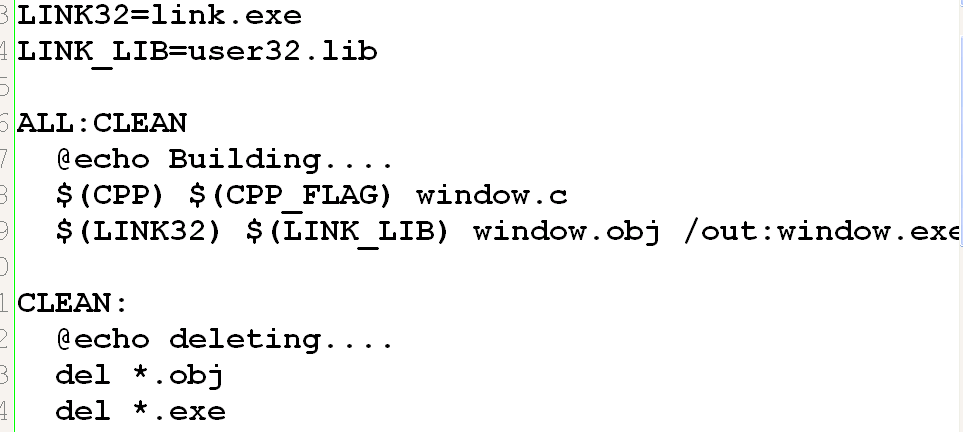
注意这里@echo Building…….这里的@表示的意思就是 不要显示出这句Echo Building 而只是显示出Building。
1.3.2 、执行过程
1 、NMAKE首先找到第一个依赖行,根据依赖
行之间的关系,建立依赖树。例如:
A:B
B:C
C:D
NMAKE会建立对应的依赖树
A
|-B
|-C
|-D
2、在树建好后,NMAKE会首先执行D的命令行, 然后依次执行父结点的命令行
3、 在A的命令执行结束后,退出NMAKE.
4、 如果需要执行指定依赖行,需要在执行
NMAKE时增加依赖行的名称
NMAKE /f Makefile.mak B <--指定从B执行
1.4、使用
1.4.1、 NAMKE指定文件名
NMAKE /f Makefile.mak
1.4.2、使用缺省文件名Makefile
NMAKE在执行时会自动查找这个文件。
二、字符编码
2.1、 编码的历史
2.1.1、 ASCII 0-127 7位表示
2.1.2 、ASCII扩展码 0-255 8位表示
代码页:通过代码页来切换对应的字符
【比如同样是第二页,第一本书的第二页是A,第二本书的第二页就是X,但是都是第二页】
2.1.3、 双字节字符集 DBCS
使用一个或两个字节表示字符.
"A 中 B 国" :字符
1 2 1 2 :字节个数
A: 0x41 中:0x8051 B: 0x42 国:0x8253
1 2 3 4 5 6
0x41 0x80 0x51 0x42 0x82 0x53
A 中 B 国
2.1.4 、Unicode
全部使用2个字节表示字符
"A 中 B 国":字符
2 2 2 2 :字节个数
A: 0x0041 中:0x8051 B: 0x0042 国:0x8253
1 2 3 4 5 6 7 8
41 00 51 80 42 00 53 82
【这个时候就出现了一个问题,因为我们学习c语言的时候知道,如果输出字符串的话,遇到0的时候就停止输出,所以,如果这么写:

那么上来就停止输出了,就会出现问题,因为上来就是00】
内存/硬盘等资源占用变大.
对编程支持度.
【unicode推广了很多年但是用的还是不是很广,windows NT内核都是unicode编写的 unicde 需要一定的时间 才能取代其他的编码】

SetConsoleOutputCP( nCodePage );这函数是win32标准函数用来调整(代码页),我们可以使用MSDN来进行查询。这个函数用来修改当前控制台程序的字符集。需要头文
件windows.h对这个函数来时候437代表标准的英文输出。中文是936。这个可以去,这个路径查找:
目录---平台SDK----Windows BaseServices-----International Features----Unicode and Character Sets---Unicode andCharacter Set Constants----ANSI Code-Page Identifiers
字符编码是按照上面的函数旁边的【】的顺序发展的。
如何调出VC自带的内存查看器:首先要按F10 进行调试,然后才可以打开查看内存情况,你可以在Name中输入要查看的变量地址如int t,输入&t,回车(右边会显示地址
值),在按F10进行调试,就可得到t的地址,然后copy到内存查看器中即可!
View->Debug Windows->Memory
字符串长度和字符内存数,他们并不是一个事情,所以这里结果是wcslen(“ABCD”)=4你不能说因为他占用了8个字节就说他的字符串的长度是8,这个字符串的长度还是4
2.2、C语言和编码
2.2.1、单字节的字符和字符串
char cText = 'A';
char * pszText = "ABCD";
2.2.2 、宽字节的字符
wchar_t cText ='A'
wchar_t * pszText = L"ABCD";
Unicode码是宽字符的一种,不能说宽字符和unicode是等价的。但是基本可以理解unicode码就是宽字符码,但是如果抠细节的话,就不是了。
2.2.3、相关函数
单字字符的函数,对应有多.宽字节的函数.
Strlen wcslen mbslen(m表示multiple多,b表示byte,多字节)
printf wprintf
2.2.4 、TCHAR
比如一个程序里面既有前面出现的,wchar_t * pwszChs = L"我是程序员"又有这种:char * pszChs = "我是程序员",那么我就需要两套函数还处理这些这个就非常的麻烦,于是出现了如下的解决办法:
为了程序中可以方便的支持的Unicode和多字节字符等,所以使用TCHAR来定义字符和字符串.根据_UNICODE宏开关,会将TCHAR编译成不同字符
类型.
#ifndef _UNICODE
typedef char TCHAR
#define __T(x) x (注意这个下划线,是两个小下划线。)
#else
typedef wchar_t TCHAR
#define__T(x) L##x
#endif
使用时,要增加(TCHAR.H)头文件支持,使用 _UNICODE 宏开关进行编译
使用_UNICODE的两种方式:方式[1]
CL window.c /D _UNICODE
这样在命令行上面敲上,就可以使用_UNICODE这个宏了 /D表示定义的意思
方式[2]:也可以在,使用的时候在头文件上面加上:
#define _UNICODE
#include "tchar.h"
定义方式:
TCAHR * pszText = __T("ABCDEF");
代码使用:使用UNICODE宏开关,通知编译器选择编译的代码.
#ifndef _UNICODE
intnLen = strlen( pszText );
#else
intnLen = wcslen( pszText );
#endif
2.2.5 、Unicode的控制台(就是cmd的那个dos窗口)打印
【比如我们要打印汉字,但是你会发现这个汉字在标准c的printf这个函数里面打印的话,会出现很多的问题,因为printf这个函数对unicode码的支持就不是很好,所以我们就不要用printf这个函数来打印,我们使用下面的这个函数来在控制台,打印出unicode码】
BOOL WriteConsole(
HANDLE hConsoleOutput, //控制台输出流的句柄
CONST VOID * lpBuffer,//输出的字符串的指针
DWORD nNumberOfCharsToWrite,//【返回】输出的字符串的长度【可以通过参数返回,类似于linux编程中的那个通过参数返回】
LPDWORDlpNumberOfCharsWritten, // 返回已输出字符的数量
LPVOID lpReserved
); // 保留值
【注意这个WriteConsole();这个函数真正存在的是WriteConsoleA()和WriteConsoleW()就和前面的messagebox这个函数的原理是一样的。如果你在原代码中使用鼠
标的邮件,查看WriteConsole()这个函数的定义的时候,你就会发现这样的一个宏:
#ifdef UNICODE
#define WriteConsole WriteConsoleW
#else
#define WriteConsole WriteConsoleA
#endif // !UNICODE】
上面这个函数的第一个参数,也就是(HANDLE hConsoleOutput, //控制台输出流的句柄),是通过这个函数得到的:
HANDLE GetStdHandle( DWORD nStdHandle // input, output, or error device);
void PrintUnicode( )
{
HANDLE hOut = GetStdHandle(STD_OUTPUT_HANDLE );//MSDN上面可以查看到
[得到标准输出流的句柄,把这个句柄作为WriteConsoleW的参数传递进去]
wchar_t * pszText = L"我是程序员";
WriteConsoleW( hOut,pszText,wcslen(pszText),NULL, NULL );
wchar_t szText[2] = { 0 };
for( BYTE nHigh=0x48; nHigh<0x9F;nHigh++ )
{
for( BYTE nLow=0;nLow<0xFF; nLow++ )
{
szText[0] =MAKEWORD( nLow, nHigh );//MAKEWORD这个是一个宏,意思就是把高字节和低字节的数据合成一个数据。
WriteConsoleW(hOut,szText,wcslen(szText), NULL, NULL );
}
}
注意上面的BYTE:C++语言的内建类型中没“BYTE”这么个类型。你引用的这段程序,指得可能是WINDOWS Platform SDK中windef.h里面定义的:
typedef unsigned char BYTE;
//上面这个程序段的意思就是告诉你,字符和数字,没有明显的界限,不要把字符和数字看的差异那么的大。
2.3、 Win32程序与编码
2.3.1、Win32 API的定义
每个API对多字节字符和UNICODE分别有不同的版本.
MessageBox :
MessageBoxA 多字节字符
MessageBoxW UNICODE字符
【MessageBox其实是在库里声明了一个宏当你使用宽字符的时候,也就是unicode的时候,自动帮你转换使用MessageBoxW而当你使用窄字符的时候,会自动帮你转换到
MEssageBoxA其实你手动调用也是可以的,反正当宽窄不相同的时候编译器会自动帮你转换,不过我个人习惯用MessageBox,毕竟少打一个字母】
在window.h之前把unicode这个宏开关打开就行了。
#ifdef UNICODE
2.3.2、 字符的定义,使用TEXT(这个是一个宏), 由Winnt.h提供定义
#ifdef UNICODE
#define __TEXT(quote) L##quote
#else /* UNICODE */
#define __TEXT(quote) quote
#endif/* UNICODE */
TCHAR * pszText = TEXT( "ABCD" );
2.3.3、字符转换
Int WideCharToMultiByte(
UINTCodePage, //代码页
DWORD dwFlags, //转换方式
LPCWSTR lpWideCharStr, //需要被转换WCHAR地址
int cchWideChar, //需要被转换WCHAR的长度
LPSTRlpMultiByteStr,//用于存放转换后的结果BUFFER
intcchMultiByte, //BUFFER的长度
LPCSTR lpDefaultChar,//使用的缺省字符串的地址
LPBOOLlpUsedDefaultChar //缺省字符串被使用的标识
);
Int MultiByteToWideChar(
UINTCodePage,// 代码页
DWORD dwFlags,// 转换方式
LPCSTRlpMultiByteStr, // 需要被转换CHAR地址
intcchMultiByte,//需要被转换CHAR的长度
LPWSTRlpWideCharStr,//用于存放转换后的结果BUFFER
int cchWideChar );//BUFFER的长度
使用方法:也就是下面两个函数的使用方法,也就是WideCharToMultiByte和MultiByteToWideChar的使用的方法。
1 、将要转换的字符串,传递给函数,从返回值中获取转换后字符串的长度。
2、 分配字符串空间
3 、再次调用函数,并将分配的空间传递给函数,获取结果.
void Multi2Wide( )
{
CHAR * pszText = "Multi2Wide";
//获取转换后需要的BUFFER的长度
int nLen = MultiByteToWideChar( CP_ACP,
0, pszText, strlen(pszText),
NULL, 0 );
//分配BUFFER的空间
WCHAR * pwszText =
(WCHAR *)malloc( nLen * sizeof(WCHAR) );
//进行转换
MultiByteToWideChar( CP_ACP,
0, pszText, strlen(pszText),
pwszText, nLen );
MessageBoxW( NULL,pwszText,
L"Wide", MB_OK );
free( pwszText );
}
void Wide2Multi( )
{
WCHAR * pwszText = L"Wide2Multi";
//计算转换后的字符串长度
int nLen = WideCharToMultiByte(
CP_ACP, 0, pwszText, wcslen(pwszText),
NULL, 0, NULL, NULL );
//分配内存
char * pszText = (char *)malloc( nLen );
//获取结果
WideCharToMultiByte(
CP_ACP, 0, pwszText, wcslen(pwszText),
pszText, nLen, NULL, NULL );
//
MessageBoxA( NULL, pszText, "Multi", MB_OK );
free( pszText );
}















 226
226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









