







Word2vec
word2vec有两种训练方法
- CBOW:在句子序列中,从当前次的上下文去预测当前词
- skip-gram:与CBOW相反,输入某个词,预测当前词的上下文
NNLM的训练:输入一个单词的上文,与预测这个单词
word Embedding 存在的问题:多义词问题
ELMO:
ELMO对这一问题有了好的解决:
使用预先训练的语言模型学习好单词的word Embedding,此时多义词无法区分。在实际的下游任务中,句子已经具备了上下文信息,可以根据上下文语义去调整单词的word Embedding,这样调整后的Word Embedding更能表达在上下文中的具体含义。
deep contextualized 词向量的特点:
在word2vec为代表的词向量模型中,每个词对应着一个向量,但是这个模型是根据一个句子赋予每个词汇向量。ELMO提出的方法,在NLP模型的输入之前加一个动态计算词向量的前向量的前向网络BiLMs;这个前向网络是在一个大的数据集上训练好的,同时前向网络的输入及n个更初始的词向量(来自于大的数据集)。
这个词向量论文中是采用字符卷积的方式得到的(如下图),采用英文语料进行文本分类准确率可达95%;也可以采用word2vec、glove等训练的词向量,效果未实现过,暂不好说。
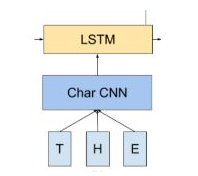
关于深层:
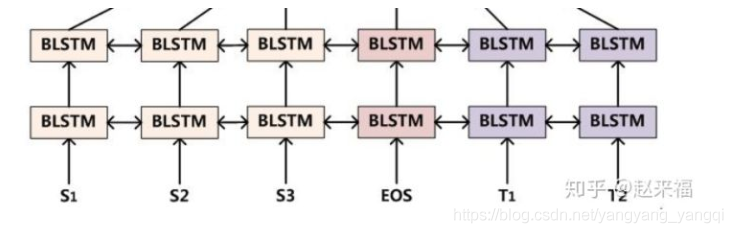
(盗图)知乎传送门:https://zhuanlan.zhihu.com/p/37684922
这是一个深层双向LSTMs网络,层数为L,每个位置的输出在输入到下一个位置的同时,也作为下一层的同一位置的输入。
以下是前向网络的举例:

ELMO的问题:在特征抽取器方面使用的是LSTM而不是transformer,特征提取能力较弱。
ELMO的输出
最简单的方法:使用最顶层的LSTM输出
优化:对每层(LSTM层等),添加一个权重(一个实数),将每层的向量与权重相乘,然后再乘以一个权重
。
每层LSTM输出或者每层LSTM学到的东西是不一样的,针对每个任务每层的向量重要性也不一样。
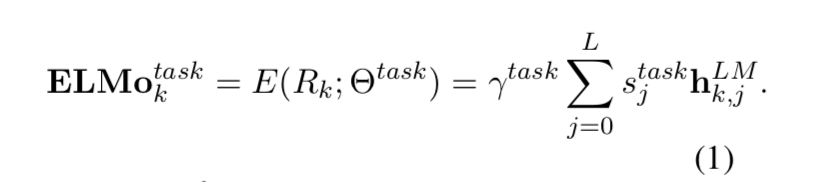
GPT
GPT也是采用两阶段模型进行训练:
- 利用语言模型进行预训练
- 通过fine-tuning模式解决下游任务
GPT与ELMO的区别:
- 特征抽取器采用的是transformer,特征抽取能力更强
- 预训练仍然是以语言模型为目标,但采用的是单向的语言模型
Bert
与GPT完全相同的两阶段模型:
- 双向语言模型预训练
- Fine-Tuning模式解决下游任务
Bert 最关键两点,一点是特征抽取器采用 Transformer;第二点是预训练的时候采用双向语言模型。
Bert与ELMO的区别:
对比ELMo,虽然都是“双向”,但目标函数其实是不同的。
ELMo是分别以 和
作为目标函数,独立训练处两个representation然后拼接。
BERT则是以 作为目标函数训练LM。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









