







之前写过一篇PyTorch节省显存的文章,在此基础上进行补充
老博文传送门
一、单卡加载大型网络
1.1 梯度累加Gradient Accumulation
单卡加载大型网络,一般受限于大量的网络参数,训练时只能使用很小的batch_size或者很小的Seq_len。这里可以使用梯度累加,进行N次前向反向更新一次参数,相当于扩大了N倍的batch_size。
正常的训练代码是这样的:
for i, (inputs, labels) in enumerate(training_set):
loss = model(inputs, labels) # 计算loss
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向计算梯度
optimizer.step() # 更新参数
加入梯度累加后:
for i, (inputs, labels) in enumerate(training_set):
loss = model(inputs, labels) # 计算loss
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # 反向计算梯度,累加到之前梯度上
if (i+1) % accumulation_steps == 0:
optimizer.step() # 更新参数
model.zero_grad() # 清空梯度
Tricks:
batch变相扩大后,要想保持样本权重相等,学习率也要线性扩大或者适当调整,batchNorm也会受到影响(小batch下的均值和方差肯定不如大batch的精准)。
梯度累加Tricks详情:https://www.zhihu.com/question/303070254/answer/573037166
1.2 梯度检查点Gradient Checkpointing
梯度检查点是一种以时间换空间的方法,通过减少保存的激活值压缩模型占用空间,但是在计算梯度时必须重新计算没有存储的激活值。
详情参考:陈天奇的 Training Deep Nets with Sublinear Memory Cost
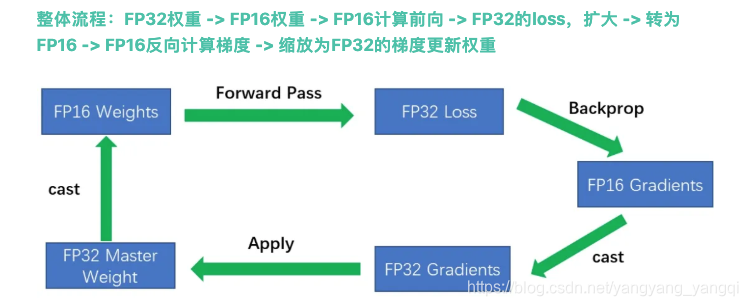
1.3 混合精度训练
具体实现可参考我的实验:https://github.com/TianWuYuJiangHenShou/textClassifier
混合精度训练在单卡和多卡情况下都可以使用,通过cuda计算中的half2类型提升运算效率。一个half2类型中会存储两个FP16的浮点数,在进行基本运算时可以同时进行,因此FP16的期望速度是FP32的两倍。
二、 分布式训练Distribution Training
2.1 数据并行 Data Parallelism
2.2 模型并行 Model Parallelism
具体理论与实验待续,欢迎来GitHub骚扰














 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









