







百忙之中抽时间编写了这个小程序,功能是:完美保存整个网页,包括:图片、JS脚本、CSS样式,并且修改网页源码进行“本地化”。由于我火星了,竟然不知道浏览器自带这个功能,因此自己动手做了一个,虽然这个程序不大,但是涉及了三大难题(后文将会详细讲解)。
本来不打算发布源码的,既然浏览器有这个功能,那我就发布一下源码以供大家学习!这个程序的效果和浏览器的效果是完全相同的!而且我对比了一下,获取的js、css、图片一个也不比浏览器获取的少。大家可以参照这个去发挥:做一个网站整站下载器。当然数据库你是绝对下不到的…..
使用说明:
1.填写网页地址然后点转到,这时会激活一键下载,加载网页需要时间,没加载完就点一键下载会有提示,尽量在网速比较好的时候使用!
2.下载完成后会在软件目录下生成一个以网页标题为名称的文件夹,所有必须文件都存放于此,其中以网页标题为名称的HTM文件就是保存的页面,在没有网络的情况下,双击查看的效果和在网络上看是一样的!。
程序截图:
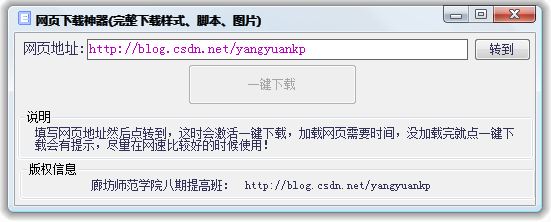
解决的难题:
1.判断网页加载完成。以前都是已知目的网页,可以用“标志法”判断,但是在这个程序里一切是未知的。所以必须用新方法,这里用了HTML对象的Onload事件,结合webbrowser控件完美实现判断网页加载完成,这是目前最安全、最准确、最可靠的方法!适用于一切环境。
判断网页加载完成一直是个非常头疼的问题,至少在VB中是这样。网上所说的方法基本上是不行的,好一点的是有时候行、有时候不行。现在我就贴出一个代码,来终结这个问题
'引用“Microsoft HTML Object Library”
Dim WithEvents page As HTMLWindow2 '注意要定义成全局的
Private Sub WebBrowser1_NavigateComplete2(ByVal pDisp As Object, URL As Variant)
Set page = Me.WebBrowser1.document.parentWindow
End Sub
Private Sub page_onload()
Debug.Print "加载完毕"
End Sub2.获取网页js和css。曾经看到很多人在猪八戒网发帖求人做程序,要求获取网页里所有的js和css。其实这个并不难,百度一下我们可以发现javascript语言提供了这个接口。下面我就演示一下如何利用这个接口获取。
首先用webbrowser控件加载你要提取的网页。
获取js:
strBasicHTM = WebBrowser1.Document.documentElement.outerHTML
WebBrowser1.Navigate "javascript:str='<HTML><HEAD><BASE HREF="" ';str+=document.URL;str+='""></HEAD><BODY><br>\n';c=document.scripts;for(i=0;i<c.length;i++){o=c[i];if (o.src=='')continue;str+='<a href=""';str+=o.src;str+='"">';str+=o.src;str+='</a><br>\n';};str+='</BODY></HTML>';document.write(str);"
While strBasicHTM = WebBrowser1.Document.documentElement.outerHTML '相等说明任务没有执行完毕
DoEvents
Wend
For lngIndex = 0 To WebBrowser1.Document.links.length - 1
Debug.print WebBrowser1.Document.links.Item(lngIndex).innerText
Next
结果图:
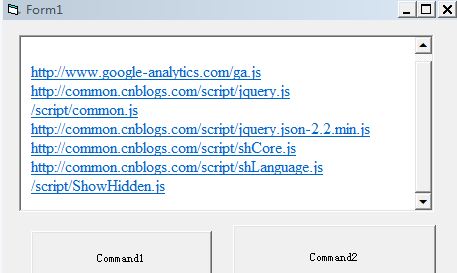
通过上边这段代码webbrowser控件里显示的就是该网页中所有的js路径,这个路径就是网页源码中的路径,不做任何修改。也就是说:如果源码中写的是绝对路径,例如http:/www.xxx.com/x.js,那么返回的就是绝对路径http:/www.xxx.com/x.js;如果是相对路径,例如/js/x.js,那么返回的就是相对路径/js/x.js。
最后用一个循环获取webbrowser控件中显示的js路径(其实就是获取超链接文本)
还有就是注意一下上边代码中的strBasicHTM变量,这个变量是为了获取webbrowser执行javascript语句前后的变化,以判断是否执行完毕,使程序更加安全。
获取css:
获取css和获取js过程一模一样,只需要把
WebBrowser1.Navigate "javascript:str='<HTML><HEAD><BASE HREF="" ';str+=document.URL;str+='""></HEAD><BODY><br>\n';c=document.scripts;for(i=0;i<c.length;i++){o=c[i];if (o.src=='')continue;str+='<a href=""';str+=o.src;str+='"">';str+=o.src;str+='</a><br>\n';};str+='</BODY></HTML>';document.write(str);"改成:
WebBrowser1.Navigate "javascript:str='<HTML><HEAD><BASE HREF="" ';str+=document.URL;str+='""></HEAD><BODY><br>\n';c=document.styleSheets;for(i=0;i<c.length;i++){o=c[i];if (o.src=='')continue;str+='<a href="" ';str+=o.href;str+='"">';str+=o.href;str+='</a><br>\n';};str+='</BODY></HTML>';document.write(str);"
最后说明一点:
javascript没有直接提供获取js文件内容的接口,因此首先要对注册表进行改造:运行regedit,定位到HKEY_CLASSES_ROOT\.js,在它下面增加两个字符串类型的值:
Content Type=application/x-javascript
PerceivedType=text
如果修改的时候不放心,可以参考HKEY_CLASSES_ROOT\.css的缺省设置,它们只是Content Type的值不同。注册表改造是一次性的工作,改完就不用再动。
用代码改就是:
Dim lhwy
Set lhwy = CreateObject("wscript.shell")
lhwy.regwrite "HKEY_CLASSES_ROOT\.js\Content Type", "application/x-javascript"
lhwy.regwrite "HKEY_CLASSES_ROOT\.js\PerceivedType", "text"3.判断网页编码。先以GB编码保存,然后再读取,如果和保存之前不一样,说明是UTF-8编码,再用UTF-8编码保存。
用GB编码保存:
Open App.Path & "\xx.HTM" For Output As #1
Print #1, strHTM
Close #1用UTF-8编码保存:
'引用Microsoft ActiveX Data Objects 2.8 Library
Dim objStream As New ADODB.Stream
Dim str As String
With objStream
.Type = 2
.Mode = 3
.Open
.Charset = "UTF-8"
.WriteText strHTM, adWriteLine
.SaveToFile App.Path & "\xxHTM", adSaveCreateOverWrite
.Close
End With














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









