







 本文详细介绍了Hadoop的分布式文件系统HDFS,包括其架构、SecondaryNameNode、机架感知策略、HDFS Federation和高可用性,以及常用操作命令。同时,文章探讨了分布式列式存储系统HBase的架构和设计,以及HDFS与HBase的结合使用场景,强调了在选择Hadoop数据组织方式时的考量因素。
本文详细介绍了Hadoop的分布式文件系统HDFS,包括其架构、SecondaryNameNode、机架感知策略、HDFS Federation和高可用性,以及常用操作命令。同时,文章探讨了分布式列式存储系统HBase的架构和设计,以及HDFS与HBase的结合使用场景,强调了在选择Hadoop数据组织方式时的考量因素。
Hadoop数据存储
Hadoop能高效处理数据的基础是有其数据存储模型做支撑,典型的是Hadoop的分布式文件系统HDFS和HBase。
一、HDFS文件系统
1.0、 HDFS简介
HDFS是Hadoop的分布式文件系统的实现,它设计的目的是存储海量的数据,并为分布式在网络中的大量客户端提供数据访问。想成功的使用HDFS,就要其实现方式及工作原理。
1.1、HDFS架构
HDFS的设计思想基于Google File System。它的出现具有以下优势:
1、可以存储相比于nfs能存储的文件的量更大;
2、为在大量机器和文件系统之间传输数据而设计;
3、具有可靠的数据存储能力,并通过数据副本的方式处理集群中某台机器宕机或数据丢失的情况;
4、HDFS与Hadoop的MapReduce模型易于集成,因此,允许数据从本地读取和处理 。
但是HDFS为获得可扩展性和高性能而进行的设计也是有代价的,它的不足之处有: 1、HDFS 并非一个通用的应用程序,而是局限于某些特定的场景;
2、HDFS 优化了高速流数据读取性能,代价则是在随机读取性能上的削弱,因此要避免数据的随机读取,访问 HDFS 文件最好采取顺序读取的方式;
3、HDFS 只支持在文件上做少数的操作,但不包括任何更新操作;
4、HDFS 不提供数据的本地缓存机制。
HDFS被实现为一种块结构的文件系统。如图所示,在Hadoop中,单个文件被拆分为固定大小的块存储在Hadoop集群上。对于每个块保存在哪个DataNode上是随机的,其结果是,访问某个文件需要访问多个DataNode,也就是HDFS能存储的文件大小可以远超出单机的磁盘容量。
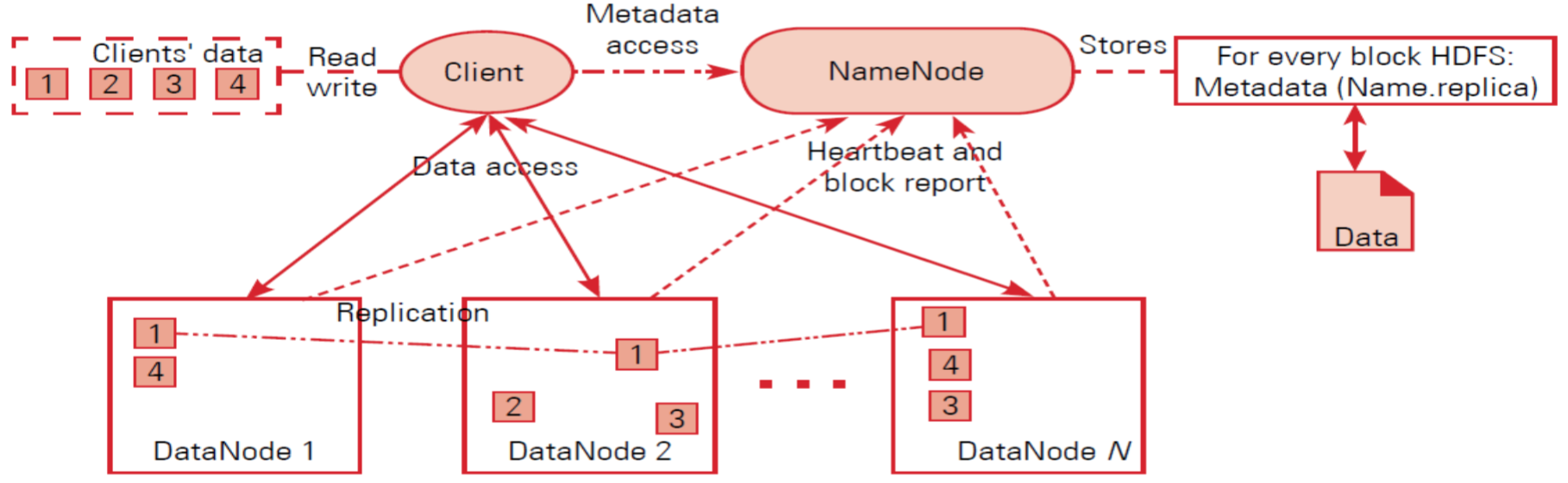
此图展示了HDFS的整体架构,HDFS 采用 master/slave 主从结构,NameNode节点存储了整个集群的文件系统的元数据信息,它管理着文件系统的的命名空间和客户端访问文件的过程,NameNode节点确保HDFS中的元数据在各个节点间保持一致。
1.2、SecondaryNameNode
HDFS的实现基于master/slave 主从架构。一方面极大的简化了HDFS的整体架构,但另一方面,这也变成了HDFS的一个弱点,即NameNode失效就意味着HDFS的失效。为缓解这个问题,Hadoop实现了SecondaryNameNode,但SecondaryNameNode不是一个“热备的NameNode”。它不能在NameNode失效后取代其功能,它为主NameNode提供检查点机制。除保存HDFS NameNode 的状态外,它还在磁盘上维护用于持久化存储当前文件系统状态的两个数据结构;这两个数据结构分别是一个镜像文件和一个编辑日志。镜像文件代表 HDFS 元数据在某个时间点的状态,在一个名为FsImage的文件中;而编辑日志是一个事务日志(与数据库体系结构中的日志相比),纪录了自镜像文件创建之后文件系统元数据的每一次更改,该日志保存在NameNode本地文件系统上的EditLog文件中。当主NameNode失效后,有部分元数据(以及对应的内容数据)会丢失,因为保存在编辑日志中的最新状态是不可用的,所有当主NameNode失效后是不能从SecondaryNameNode完全恢复主NameNode失效前的状态。
1.3、机架感知策略
机架是存储在单一位置的节点的实体集合.,一个大型的HDFS 实例在计算机集群上运行时,通常需要跨越多个机架,同一个机架上的机器节点之间的网络带宽比不同机架上的机器节点之间的网络带宽大,NameNode节点通过Hadoop的机架感知过程决定了每一个DataNode 所属的机架的ID,机架感知策略的一个优化方案就是减轻机架之间的写操作负载,为了最小化整体的带宽消耗和数据读取延迟,HDFS尝试让有读请求的客户端从最近的地方读取复制块。每一个DataNode节点会周期性的发送心跳信息给NameNode节点(如上图),如果DataNode节点失效, NameNode 将会通过不正常的心跳信息检测到。 NameNode如果规定时间内没有收到 DataNodes的心跳信息,就认为该DataNode节点已经失效,并不再发送任何的I/O请求给它们,和现在已有大部分的文件系统类似,HDFS 也支持传统分层的文件组织方式。
1.4、HDFS Federation 及高可用
为克服单个NameNode内存的限制,HDFS Federation是为了缓解HDFS的单点故障问题而提出的NameNode水平扩展方案,HDFS Federation 基于多个独立的NameNodes/Namespace。
● HDFS Federation的优势:
1、命名空间的可扩展性: HDFS 集群的存储空间可以横向扩展,但Namespace不可以;
2、性能: 文件操作的性能局限于单个Namenode的吞吐量;
3、隔离性: 单个 NameNode 节点不提供多个环境配置之间的隔离性。
HDFS Federation是基于独立的NameNode节点集合设计的,因此各NameNode节点之间不需相互协调.
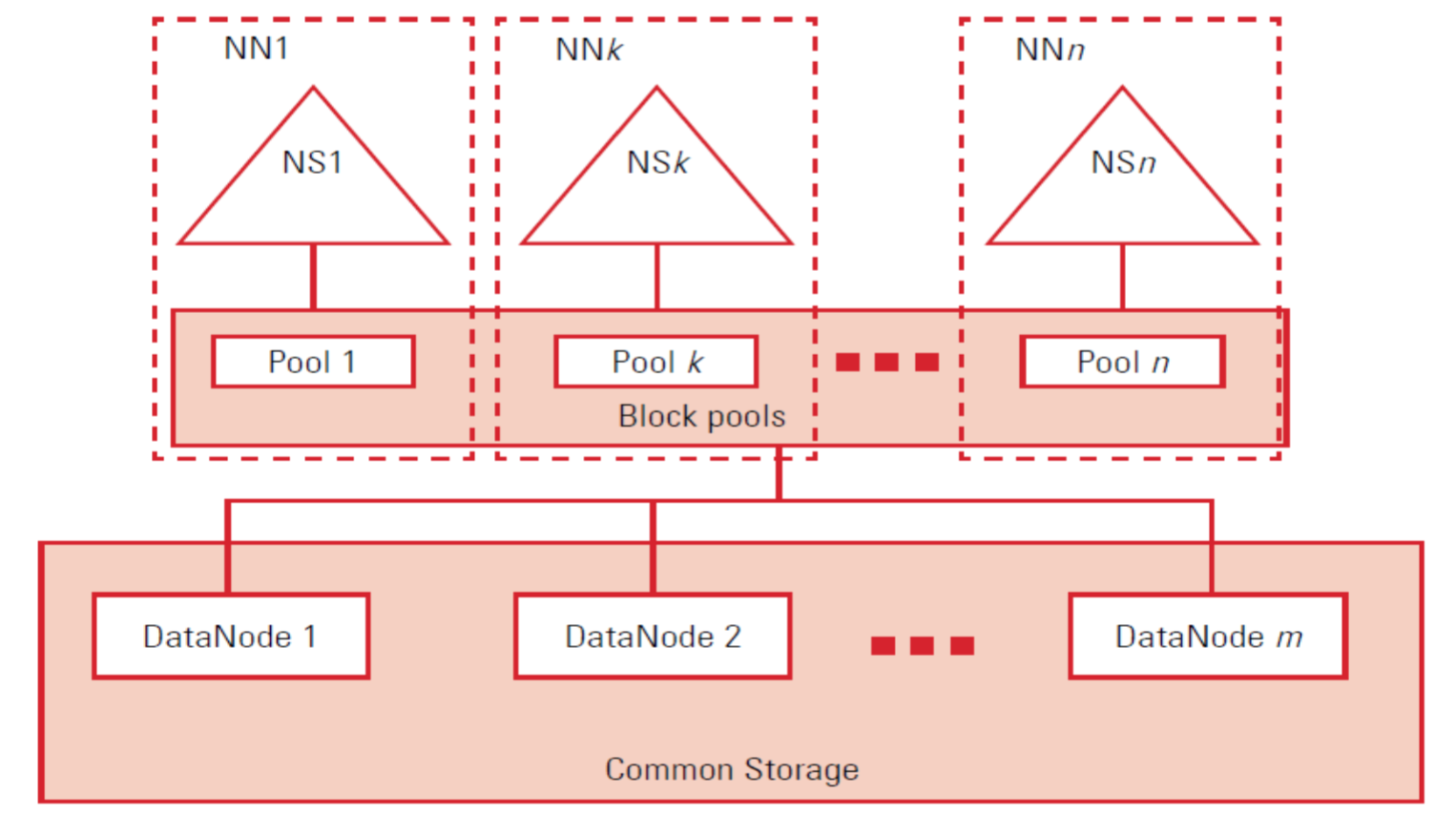
该图展示了HDFS Federation的实现结构,namespace 作为数据块池,可以对数据块集合操作,每一个数据块池都各自独立,这就允许命名空间在为一个新的数据块分配ID时,不需要与其它命名空间进行协调。单个 NameNode节点的失效不会对集群中为其它NameNode服务的Datanode节点产生影响,当某个NameNode/namespace被删除&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1412
1412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









