



 列式存储和行式存储在压缩和读取上有显著区别。列式存储利于压缩和快速读取特定列,适合大数据查询;行式存储适合全表扫描,如TextFile、SequenceFile、Avro是行式存储格式。列式存储如ORC、RCfile、Parquet提供高效查询,尤其在大数据场景下广泛应用。Avro适合ETL,Parquet适合宽表查询,ORC在压缩和ACID属性上有优势。Hive常用ORC和Parquet作为存储格式。
列式存储和行式存储在压缩和读取上有显著区别。列式存储利于压缩和快速读取特定列,适合大数据查询;行式存储适合全表扫描,如TextFile、SequenceFile、Avro是行式存储格式。列式存储如ORC、RCfile、Parquet提供高效查询,尤其在大数据场景下广泛应用。Avro适合ETL,Parquet适合宽表查询,ORC在压缩和ACID属性上有优势。Hive常用ORC和Parquet作为存储格式。
列式存储和行式存储的区别
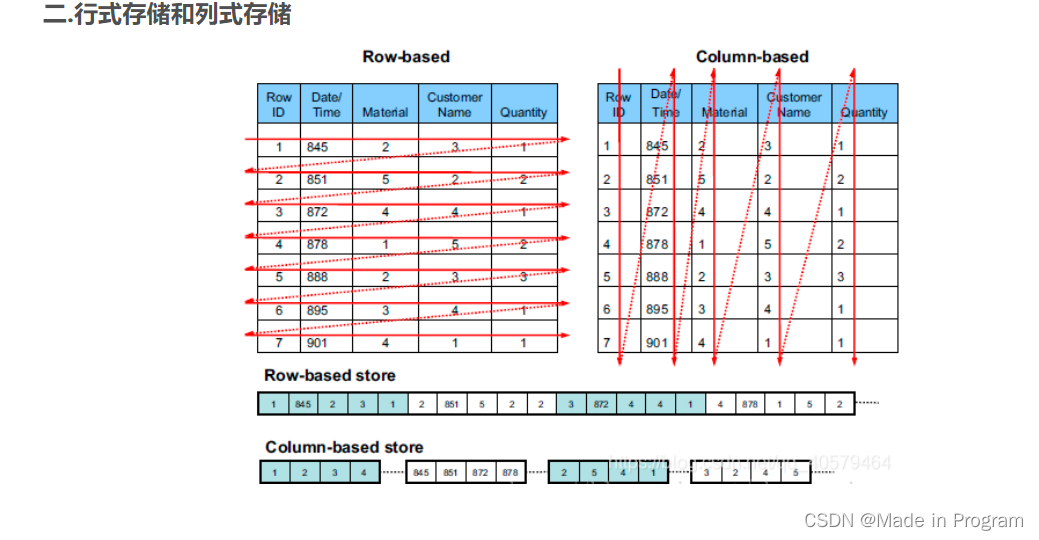
- 压缩比较
列式存储是按照列进行存储的,同一列的相邻的value的数据类型是一样,可以对value进行压缩。
行式存储按照行存储,一行中有多个字段,字段类型不一样,会导致压缩性能就较差
- 读取比较
读取 select id, time from table;
行式存储:需要遍历每一行,再将id、time拼接出来
列式存储: 只需要读取id、time两列就好
但是对于select * from table
列实存储需要再拼接,所以效率会低一些。
但是在大数据领域下一般不会进行全表扫描,所以大多采用列式存储
为什么我们需要不同的文件存储格式呢?
不同的文件存储格式在存储大小、读取速率、写入速率会有不同的表现。而不同的场景下对这两者的要求是不同的,比如说在数据仓库通常是一次写入,多次读取的,对读取性能有更高的要求。所以需要有不同的文件存储格式满足不同的需求。
常见的行式存储格式:TextFile、SequenceFile、Avro
常见的列式存储格式有:ORC、RC file、parquet
ORC、RC file是结合了行、列存储的数据格式
-
TextFile
常采用csv、json等固定长度的纯文本格式
hive中表数据的默认存储格式,将所有的数据都存储为String类型,不便于数据的解析,却比较通用。不具备随机读写的能力,占用空间较大
-
SequenceFile
按行存储二进制键值对数据,HDFS自带
二进制文件,将<key,value> 序列化到文件中,二进制的可读性就不好
可用于hadoop中小文件的打包存档
支持记录压缩、块压缩
-
Avro
一个序列化系统。基于行存储
序列化:将内存中的对象转为字节序列,便于网络中的传输。
反序列化:将字节序列转为内存中的对象。
用Json格式存储数据定义(表的描述、字段、字段类型),二进制格式存储数据
通用的数据格式
可压缩
可读性就较低
自带RPC
-
Parquet
按照列进行存储,spark sql的默认数据源格式,列式存储的优缺点。即读取某一列的数据较快
-
RC file
先划分行集合,在行集合中存储列式数据,加入轻量级索引,允许跳过行。
-
ORC FIle
RC的优化版本
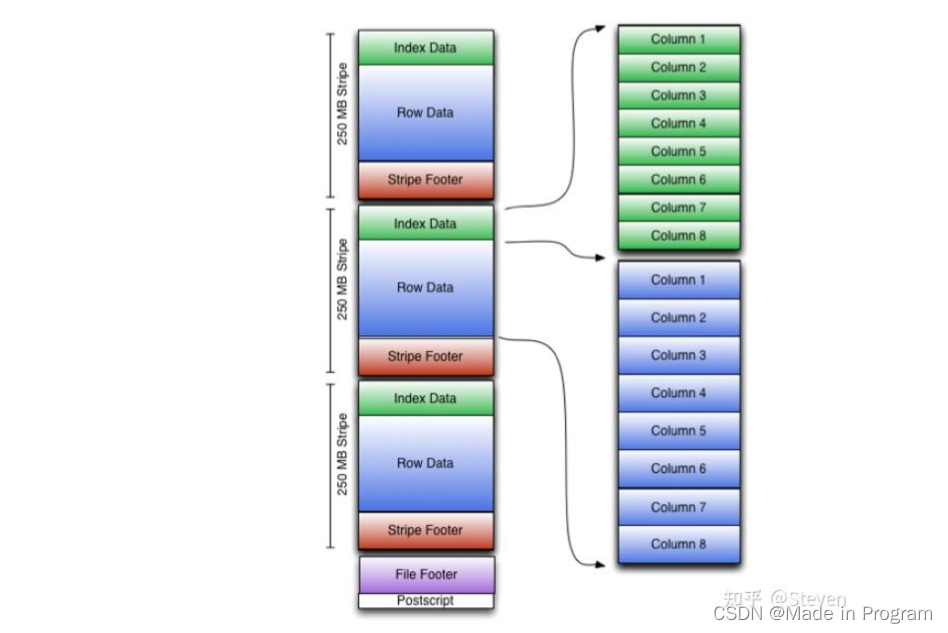
ORC 文件格式将行集合存储在一个文件中,并且在集合中,行数据以列格式存储。
ORC 文件包含称为stripe的行数据组和File footer(文件页脚)中的辅助信息 。默认stripe大小为 250 MB。大stripe大小支持从 HDFS 进行大量、高效的读取。
在Hive中常用的使用方式:一般读入源文件为Avro格式,在Hive中的中间过程可以使用ORC存储,而最后保存也选择Avro格式保存。因为Avro格式比较通用,而ORC格式在很多地方并不能使用。
差异
- 读取(速度从高到低排序)
Avro:查询随时间变化,支持扩展字段
Parquet:适合在宽表上查询少数列
Parquet & ORC:以牺牲性能为代价,优化读取能力
TextFile:可读性最佳,但是文件读取速度慢
- Hive查询(速度从高到低排序)
ORC**(常用):几乎专门为Hive定制的格式,速度很快
Parquet(常用)**
Text
Avro**(常用)**:占地小,节省磁盘空间,也是比较通用的格式
SequenceFile:占地小,节省磁盘空间;本身是为了MR的k、v对设计,而非Hive,所以对于Hive来说速度最慢。
总结:常用的格式是AVRO 、Parquet、ORC;Parquet、ORC是列式存储格式,Avro是行式存储格式。
对比Avro和Parquet:
1.Parquet由于是列式存储格式,所以在读取查询效率比较高。
2.在模式演变方面,Avro比 PARQUET 成熟得多。Parquet 仅支持模式追加,而 Avro支持功能强大的模式演变,即添加或修改列。也就是说在写操作上,Avro表现更好。
3.Avro是ETL操作的理想选择,需要查询所有的列
ORC和Parquet的比较
Parquet更能存储嵌套数据
ORC更能进行谓词下推
ORC支持ACID属性
ORC压缩效率更高
参考文章:
Hadoop文件存储格式(Avro、Parquet、ORC及其他)


















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











