







 GraphSAGE是一种归纳式图神经网络框架,能够在不预先知道所有节点的情况下,有效地为新节点生成embedding。它通过采样和聚合邻居节点信息进行前向传播,适合大规模图数据。论文中探讨了不同类型的聚合器,如均值聚合器、LSTM聚合器和Pooling聚合器,并在多个数据集上进行了实验,展示了其在效率和性能上的优势。
GraphSAGE是一种归纳式图神经网络框架,能够在不预先知道所有节点的情况下,有效地为新节点生成embedding。它通过采样和聚合邻居节点信息进行前向传播,适合大规模图数据。论文中探讨了不同类型的聚合器,如均值聚合器、LSTM聚合器和Pooling聚合器,并在多个数据集上进行了实验,展示了其在效率和性能上的优势。
论文: Inductive Representation Learning on Large Graphs
1 Motivation
大多数graph embedding框架是transductive(直推式的), 只能对一个固定的图生成embedding。这种transductive的方法不能对图中没有的新节点生成embedding。相对的,GraphSAGE是一个inductive(归纳式)框架,能够高效地利用节点的属性信息对新节点生成embedding。
( 这里的transductive和inductive用的很精髓,统计机器学习可以分成两种: transductive learning, inductive learning.
transductive learning: To specific (test) cases, 指的是测试集是特定的(固定的样本);
inductive learning: 测试集不是特定的。
一般我们的目的是做 inductive learning。)
GNN中经典的DeepWalk, GCN方法都是transductive learning。
2 前向传播
论文中提出的方法称为graphSAGE, SAGE指的是 SAmple and aggreGat。 sample和aggregate就是主要的两步。
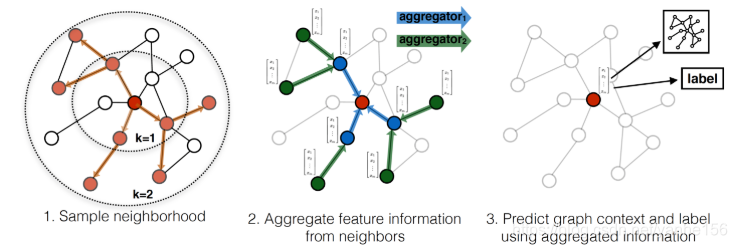
上面是为红色的目标节点生成embedding的过程。k表示距离目标节点的搜索深度,k=1就是目标节点的相邻节点,k=2表示目标节点相邻节点的相邻节点。
对于上图中的例子,
第一步是采样,k=1采样了3个节点,对k=2采用了5个节点;
第二步是聚合邻居节点的信息,获得目标节点的embedding;
第三步是使用聚合得到的信息,也就是目标节点的embedding,来预测图中想预测的信息;

伪代码中2到7行的两层循环,for k = 1 … K k=1 \ldots K k=1…K 表示深度从1到最大值K,for v ∈ V v \in \mathcal{V} v∈V 表示对图中的每个节点。
N ( v ) \mathcal{N}(v) N(v) 表示节点v的邻居,伪代码中也说明了 N \mathcal{N} N 表示neighborhood function。
第4行里, { h u k − 1 , ∀ u ∈ N ( v ) } \left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\} {
huk−1,∀u∈N(v)} 表示节点 v v v的任意相邻节点的聚合信息的集合, h N ( v ) k \mathbf{h}_{\mathcal{N}(v)}^{k} hN(v)k 是一个向量,表示从节点 v v v的相邻节点获取的信息。AGGREGATE k _{k} k 表示可微分的聚合函数,这篇文章后面尝试了多种方法。注意 k − 1 k-1 k−1不表示相邻,表示相邻的是 N ( v ) \mathcal{N}(v) N(v)。
第5行,将从相邻节点获取的信息 h N ( v ) k \mathbf{h}_{\mathcal{N}(v)}^{k} hN(v)k , 和这个节点自身的信息 h v k \mathbf{h}_{v}^k hvk拼接。
每个节点用特征来初始化得到一个初始表示 h v 0 h_v^0 hv0。当 k = 1 k=1 k=1时,跑完 for v ∈ V v \in \mathcal{V} v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









