







一、部署
- 环境macbookpro Apple M3
- 创建python3.9或者3.10环境
conda create -n llamafactory python=3.9 -y - 激活环境
conda activate llamafactory - 源码安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple pip install -e ".[torch,metrics]" --no-build-isolation
二、webui
llamafactory-cli webui
- 访问 http://127.0.0.1:7860/
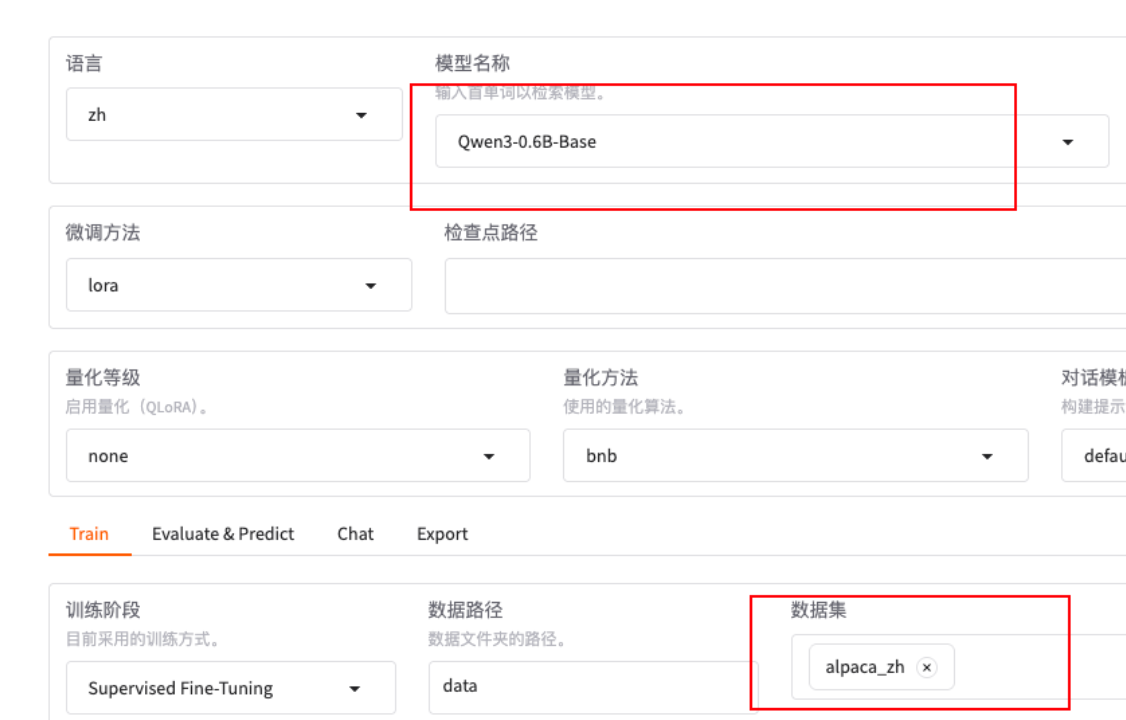
- 模型Qwen3-0.6B-Base
- 数据集alpaca_zh
三、llamafactory-cli train训练
- train
# Use `CUDA_VISIBLE_DEVICES` (GPU) or `ASCEND_RT_VISIBLE_DEVICES` (NPU) to choose computing devices. export CUDA_VISIBLE_DEVICES= export ASCEND_RT_VISIBLE_DEVICES= # 开启 CPU fallback(Mac M 系列可能默认 MPS) export PYTORCH_ENABLE_MPS_FALLBACK=1 export PYTORCH_MPS_HIGH_WATERMARK_RATIO=0.0 export HF_TOKEN=******* # 基础训练 CPU # --flash_attn auto 仅CPU支持 # --fp16 True CPU/MPS 不支持 fp16 llamafactory-cli train \ --stage sft \ --do_train True \ --model_name_or_path Qwen/Qwen3-0.6B \ --finetuning_type lora \ --template default \ --dataset_dir data \ --dataset alpaca_zh \ --cutoff_len 512 \ --learning_rate 5e-05 \ --num_train_epochs 1 \ --max_samples 2000 \ --per_device_train_batch_size 1 \ --gradient_accumulation_steps 2 \ --lr_scheduler_type cosine \ --max_grad_norm 1.0 \ --logging_steps 5 \ --save_steps 200 \ --output_dir ./output/yanlp/Qwen3-0.6B-alpaca-lora \ --gradient_checkpointing False \ --enable_thinking True \ --optim adamw_torch \ --lora_rank 4 \ --lora_alpha 8 \ --lora_dropout 0 \ --lora_target q_proj,v_proj \ --report_to none \ --plot_loss True ls ./output/yanlp/Qwen3-0.6B-alpaca-lora

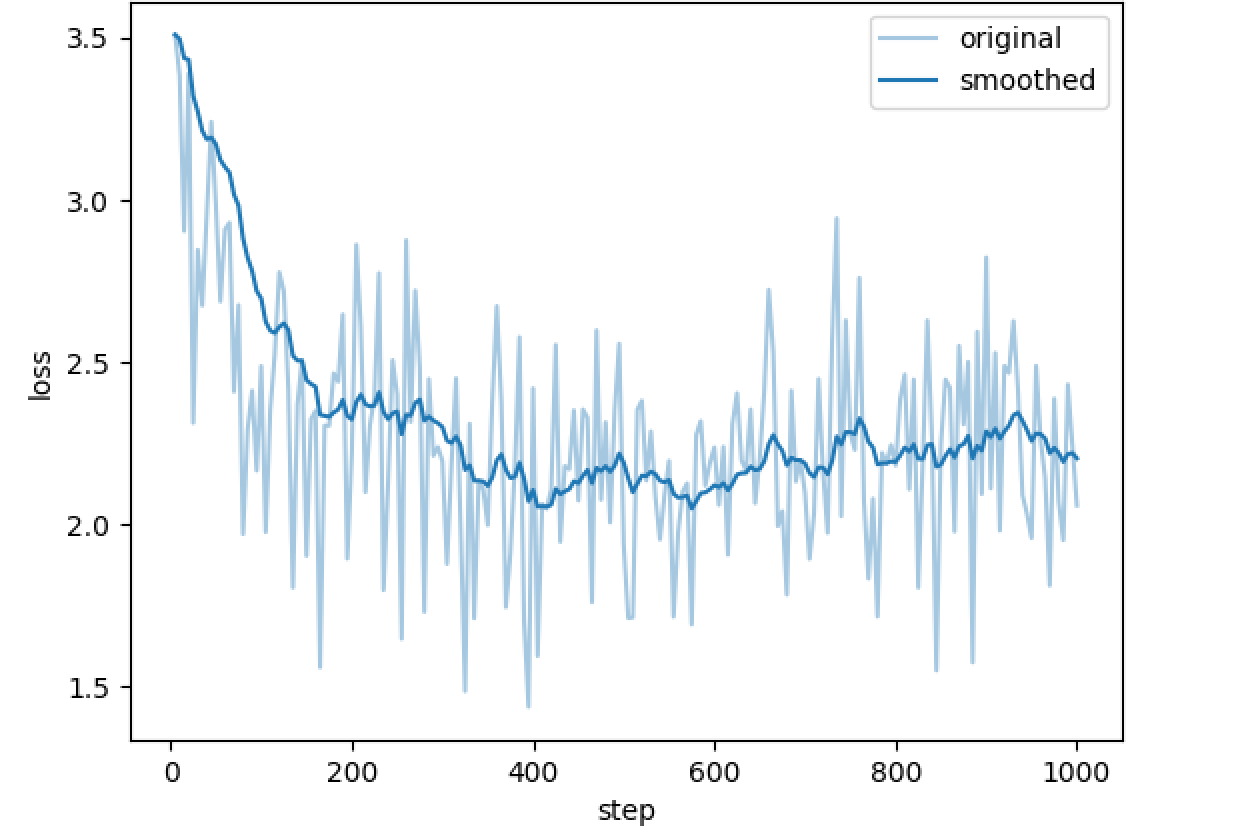
- training_loss.png
- 参数说明
| 参数名 | 含义 | 示例值 / 建议 | 备注 |
|---|---|---|---|
stage | 训练阶段 | sft | Supervised Fine-Tuning(有监督微调)阶段 |
do_train | 是否执行训练 | True | 为 False 时仅执行评估或推理 |
model_name_or_path | 预训练模型路径或 Hugging Face 模型 | Qwen/Qwen3-0.6B | 支持本地路径或远程模型 |
finetuning_type | 微调方式 | lora | LoRA 微调(轻量级高效微调) |
template | Prompt 模板类型 | default | 用于对话、指令类数据 |
dataset_dir | 数据集所在目录 | data | 指定数据集存放路径 |
dataset | 使用的数据集名称 | alpaca_zh | 中文 Alpaca 数据集 |
cutoff_len | 最大文本长度 | 512 | 超过则截断(CPU 建议小一点) |
learning_rate | 学习率 | 5e-05 | 参数更新幅度,建议 1e-5 ~ 5e-5 |
num_train_epochs | 训练轮数 | 1 | 训练的完整遍历次数 |
max_samples | 最大样本数 | 2000 | 控制数据量,方便快速测试 |
per_device_train_batch_size | 每设备 batch size | 1 | CPU 建议较小值,GPU 可适当增大 |
gradient_accumulation_steps | 梯度累积步数 | 2 | 模拟更大的 batch size |
lr_scheduler_type | 学习率调度策略 | cosine | 使用余弦退火策略 |
max_grad_norm | 最大梯度范数 | 1.0 | 防止梯度爆炸(梯度裁剪) |
logging_steps | 日志打印间隔 | 5 | 每 N 步打印一次训练信息 |
save_steps | 模型保存间隔 | 200 | 每 N 步保存模型快照 |
output_dir | 模型输出目录 | ./output/yanlp/... | 训练产物保存位置 |
gradient_checkpointing | 是否启用梯度检查点 | False | 开启可节省显存但降低速度 |
enable_thinking | 是否启用“思考模式” | True | 启用中间推理机制(部分模型支持) |
optim | 优化器类型 | adamw_torch | PyTorch 原生 AdamW |
lora_rank | LoRA 低秩矩阵维度 | 4 | 值越小,参数越少,速度越快 |
lora_alpha | LoRA 缩放系数 | 8 | 控制 LoRA 学习率放大比例 |
lora_dropout | LoRA dropout 概率 | 0 | 可防止过拟合,0 为关闭 |
lora_target | LoRA 作用模块 | q_proj,v_proj | 只微调注意力层的 q/v 投影矩阵 |
report_to | 日志上报平台 | none | 禁用 wandb/tensorboard 等 |
plot_loss | 是否绘制损失曲线 | True | 输出 loss 曲线以便可视化训练进展 |
model_name_or_path本地模型目录(需包含 config.json、权重文件、tokenizer 等)例如:
/Users/yanlp/.cache/openmind/hub/models--Qwen--Qwen3-0.6B/snapshots/<hash>
四、llamafactory-cli export合并、导出
- 合并(merge)LoRA 权重 到原始模型;
- 导出(export) 成标准 Hugging Face 格式;
- export
llamafactory-cli export \ --model_name_or_path Qwen/Qwen3-0.6B \ --adapter_name_or_path ./output/yanlp/Qwen3-0.6B-alpaca-lora \ --template default \ --finetuning_type lora \ --export_dir ./merged/yanlp/Qwen3-0.6B-train \ --export_size 2 \ --export_device cpu \ --export_legacy_format False ls ./merged/yanlp/Qwen3-0.6B-train

五、llamafactory-cli train push_to_hub上传
llamafactory-cli train ... --push_to_hub Trueexport HF_TOKEN=*******
六、clone 并查看commit



















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











