






 本文介绍了在使用Matlab处理UCI数据集时,尤其是data格式文件的导入问题,通过转换为txt文件并利用readtable函数,以及处理类别列和数据类型的问题,最终实现模糊C均值(FCM)聚类的应用。
本文介绍了在使用Matlab处理UCI数据集时,尤其是data格式文件的导入问题,通过转换为txt文件并利用readtable函数,以及处理类别列和数据类型的问题,最终实现模糊C均值(FCM)聚类的应用。
前言
最近在学习聚类算法的时候需要用到一些数据集,例如使用UCI数据集进行聚类测试。
但是在聚类的时候出现了一个问题:将数据集中后缀为.data格式的文件数据导入到matlab时费了不少功夫,尝试了众多方法如'importdata'、'textread'、'csvread'、'load'等内置函数效果都不太理想。
最终改变思路解决了这个问题,在此做个记录与分享。
一、UCI数据集下载
UCI官网: UCI Machine Learning Repository

可以在官网下载自己所需的数据集,以常见的iris数据集为例,下载解压后文件夹内容如下图所示

其中iris.data文件即为我们所需要的数据文件。
二、数据导入
iris.data文件中可能同时包含数字与字符串,如图所示,这里只展示了部分数据。(如何打开data文件查看其中的内容呢,尤其是在没有安装相对应的软件的情况下,方法也很简单:在“打开方式”中选择“记事本”即可。)

iris数据集共有150个数据,分属三个不同类别。对于每一行元素而言,前4个数据代表4个不同维度的特征,第5个字符串则类别。
对于这种类型的数据文件,常规的导入方法是不太行得通的。
在这里分享一下我的方法:
1.将.data文件转换为后缀为.txt的文本文件。如何转换:新建一个txt文件,这里依旧命名为iris,将.data文件的内容复制至这个txt文件中,如图所示:
2.打开matlab(我的版本是2022b),使用'readtable'函数将新建的txt文件读入到matlab的工作区中,代码如下:
Table = readtable('iris.txt');%初步导入数据集,命名为Table此时,Table是一个包含有iris数据集所有元素的表格,如图所示,这里同样只展示了部分数据。
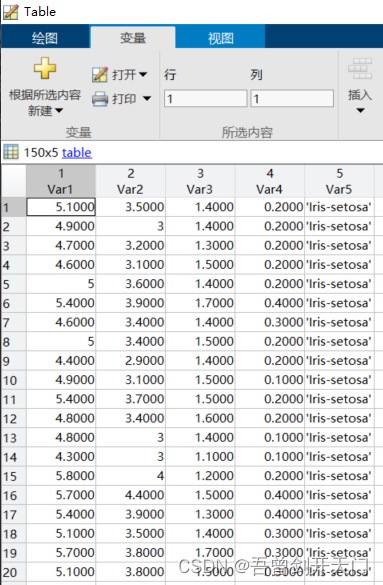
3.初步导入数据集以后又会有新的问题,以Table为例,该表的第5列是数据类别,并不是所需要的数据,并且由于元素类型的不同,并不能直接将该table转换为常见的矩阵。
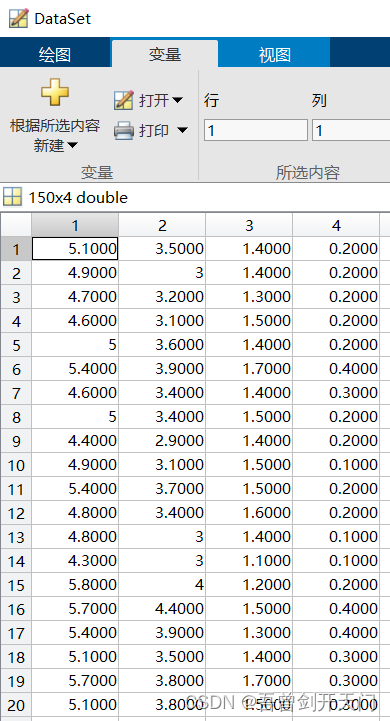
为了方便使用数据以及后续进行指标评价,可以将Table中的类别所在列摘除,使其单独作为一个数组存放数据类别,此时表格中剩余的元素均为相同类型,可以较为简便地将该表格转换为常见的矩阵以进行后续的运算。
代码如下:
Class = Table(:,end);%Class为类别列
Table(:,end) = [];%去掉Table中的类别列
DataSet = table2array(Table);%将此时的Table直接转换为数值矩阵最终的效果如图所示:

三、实例
以模糊C均值算法(FCM)对iris数据集进行聚类为例,代码如下:
%% 加载数据
Table = readtable('iris\iris.txt');
Class = Table(:,end);
Table(:,end) = [];
DataSet = table2array(Table);
X = DataSet;
%% 进行模糊C均值聚类
% 设置幂指数为3,最大迭代次数为20,目标函数的终止容限为1e-6
options=[3,20,1e-6,0];
% 调用fcm函数进行模糊C均值聚类,返回类中心坐标矩阵center,隶属度矩阵U,目标函数值obj_fcn
cn=3; %聚类数
[center,U,obj_fcn]=fcm(X,cn,options);
Jb=obj_fcn(end)
maxU = max(U);
index1 = find(U(1,:) == maxU);
index2 = find(U(2, :) == maxU);
index3 = find(U(3, :) == maxU);该数据集最终被分为了3类,如图所示:

可看出FCM算法对该数据集的聚类结果还是存在一些偏差(原数据集中各类别分别占50个),此时可以对聚类指标进行一些评价,此处省略......。
四、补充
1.数据集文件夹中后缀为.names的文件存放着数据集的具体信息,如图所示。打开方式同.data文件。


2.不同数据集的.data文件的数据存放方式有所不同,导入时要注意灵活变通。如wine数据集中数据类别存放在第一列:

此时在导入数据时应将表格中的第一列摘除,在代码中将
Table(:,end) = [];%去掉Table中的类别列变为
Table(:,1) = [];%去掉Table中的类别列即可导入数据。
总结
这是我琢磨出来的一个将.data数据导入到matlab的一个办法,个人认为比较简便,有更好方法的欢迎进行交流~~~















 2186
2186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









