







java常用技巧
// 获取对象的数据类型,是什么对象
String s1 = "1212"
s1.getClass().getSimpleName()
// 比较两个未知对象是否相等,有非空校验。
Objects.equals(s1, s2)
// 操作集合和数组用Stream流
超级好用YYDS
// 获取对象的类的类型
user instanceof Business(判断user对象是否为Business类的,返回值为boolea)
/**
目前最优雅的定位文件方式
getResourceAsStream中的/是直接去src下寻找的文件;
Dom4JHelloWorldDemo1——当前写代码的这个类名;反射原理,舒舒服服
*/
InputStream is = Dom4JHelloWorldDemo1.class.getResourceAsStream("/Contacts.xml");
Document document = saxReader.read(is);
**相对路径的找法:**真的是很烦,一下子在项目工程下面,一下子又在模块下面,尼亚的,这里给出一个通用方法。
// 这个可以获取我们当前class文件代码所在的主路径
System.out.println(System.getProperty("user.dir"));
这样我们就知道,相对路径应该怎么写。一般情况下,相对路径都是相对工程而言的,我们路径里面写模块名+…等等定位文件
Java编程中的[ ]和{ }是表示什么意思?
【1】[ ]有两个用途,
- 一是声明数组时使用,表示数组的长度,例如int a = new int[5],声明了长度为5的数组。
- 二是在正则表达式中,表示一个范围,例如:[a-z]表示取值在小写a到小写z之间copy
【2】{ }是一个语句体,他是一段程序的边界,
-
例如:(1)class A{} 这里的{}表示类实体,凡是在{}中的内容均是类的变量(属性)或方法(函zd数)
-
(2)public void a(){} 这里的{}表示方法体,凡是在{}中的内容均是方法的实体。
-
【注意】我们可以在程序的任何合法语句两侧加{ },例如:{int a = 0;},这个等价于int a = 0; 也就入上所说,他是程序的一个“边界”,并没有实际的运行意义,只是把程序分隔成模块,是一种固定的写法
java对反斜杠很敏感
看正则表达式
Java 与Python的不同点
-
print输出方式
//Python x = torch.tensor([1, 3, 4]) print(f"the tensor: \n {x} \n")//推荐这种输出 print("the tensor:\n", x) print("using {} device".format(device)) //Java int a = 5; System.out.println("a的值是:\n\" + a); -
python的变量不需要new,而java在使用一个变量时,一定要先定义变量的类型。
原因在于,Java的运行方法,有内存、地址的概念。python类似于Matlab,所有的变量都是直接存的数据。
//python name = "quanzhou" myname = name print(myname) //java String name = "quanzhou"; String myname = name; sout(myname); 并且java这里还会报一个警告,“Local variable 'myname' is redundant” 因为字符串是引用类型的变量,存的是地址,现在是两个均指向了一个地址,有一个多余
#ABC
-
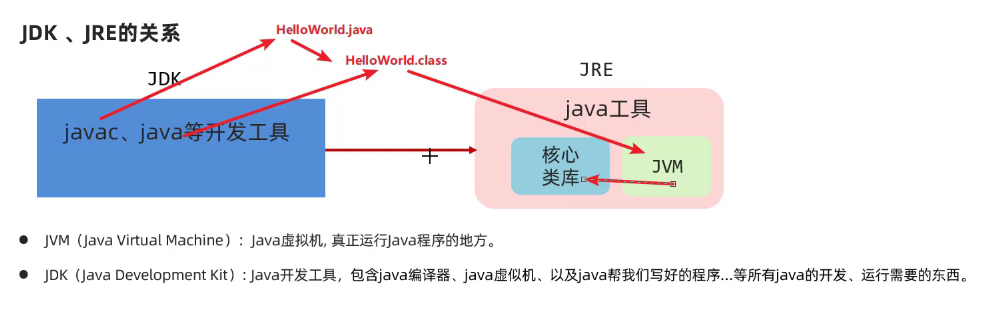
javac——编译工具;java——执行工具。文件名=类名
HelloWorld:javac HelloWorld.java 》》.class文件
java HelloWorld
-
JDK里面包含了JRE;JRE中有相关的库和JVM。
###字面量
即数据在程序中的书写格式。\n------换行;\t-------空格 
###变量
定义格式: double money = 50 或者 double money
注意:定义变量可以无初始值,但使用变量前一定要先有值。
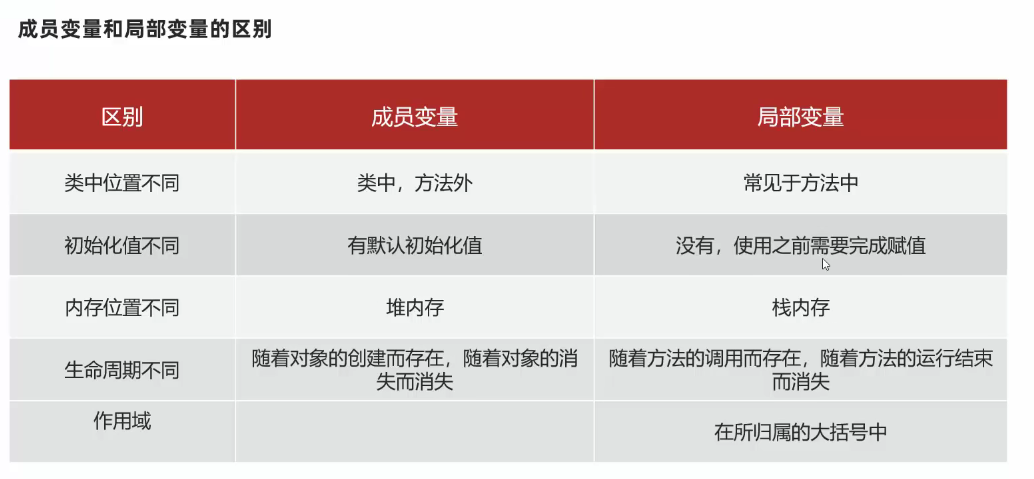
成员变量(类中)与局部变量的区别(重点)
###数据的类型
1字节=8位二进制。计算机中数据的最小组成单位:8个二进制位为一组,来保存数据,叫做一个字节byte。其中,每个二进制位称为一个比特bit,即1byte = 8bit。
引用类型主要指数组、类、接口等,因为他们存储的是地址,而不是具体数据。
基本数据类型:4大类

###AscII编码表
**字符(char类型)**在计算机内的存储是二进制形式;
ASCII编码表就是每个字符的约定二进制编号
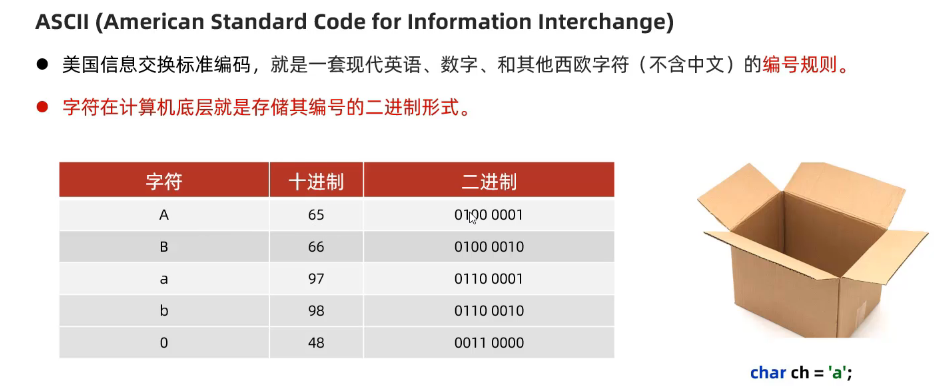
并且其他的数据,例如声音图片视频均是在计算机里面按照二进制方式存储的。
###关键字,标识符
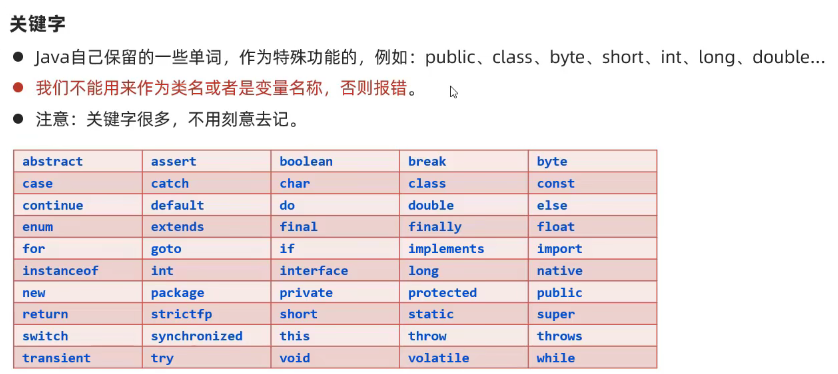
标识符:也就是变量名,类名的命名要求,要以数字,字母,__开头,不能用关键字。
变量名称:驼峰模式,首字母小写,如 int javaNumber = 8;
类名称:驼峰,首字母大写,如 HelloWorld.java
注释
- 单行注释://
- 多行注释:/* */
- 文档注释:/** */
API
Application Programming Interface(应用程序编程接口)
其实就是指:Java写好的程序(功能代码),我们可以直接调用。
IDEA
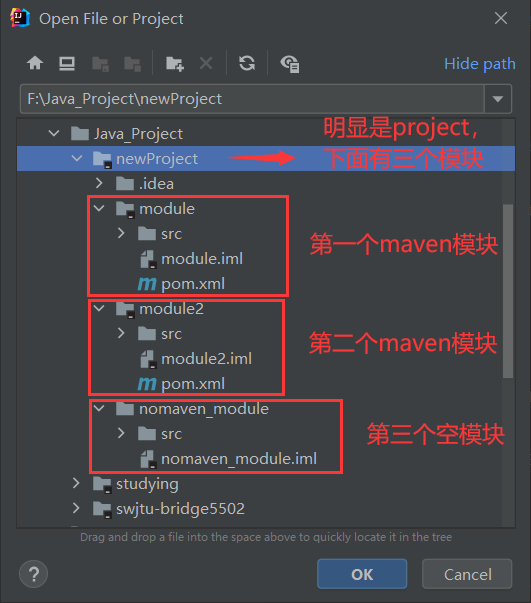
区分Project和Module
-
Project:(用open打开)
有.idea文件,无.iml文件、src文件夹、pom.xml。idea文件夹存放项目的配置信息
-
Module:(用new打开)
有.iml文件(每个模块都有一个自己的)
-
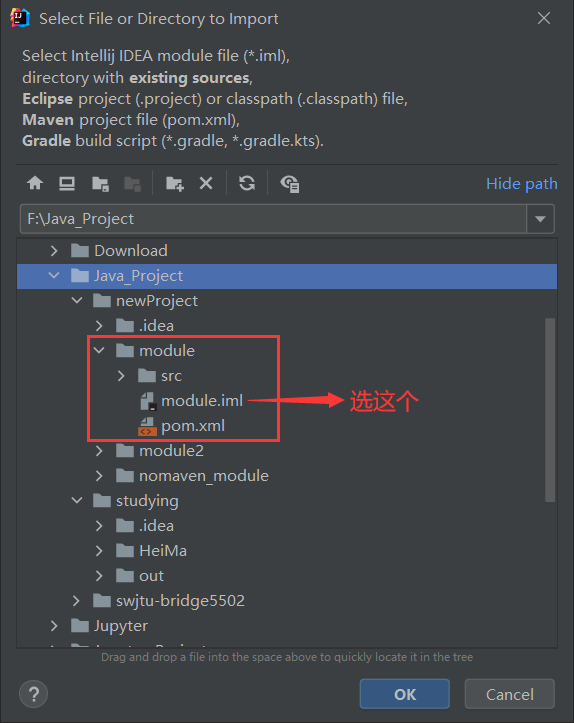
Example
- 使用open打开工程(选工程名文件夹)
2. 使用new导入模块(选.iml文件)(这个简单,只有模块才有.iml文件,直接找到,选中就可以打开)
##快捷语句:
main;sout;
main:
public static void main(String[] args) {
}
sout:
System.out.println();
##快捷键:
- crtl+D——直接复制当行语句到下一行;
- Crtl+ALT+L——格式化;
- ALT+Shift+↑——上下移动当前代码;
- Crtl + ALT +T ——先选取代码部分,然后按住,可以将代码用循环语句包住66666;
- ALT + Enter——快速提示,很多地方用到,异常抛出
- ALT + Insert ——提示插入的东西
- Shift + F6 ——选择所有同名的变量,一起更改
- Ctrl + F12 ——查看实体类内在的成员方法
- Ctrl + H——查看接口的实现类
- Ctrl + O,展示出Object中可以重写的方法!!!
- Ctrl+Alt+V——自动补全代码
- Crtl + R ——搜索替换。类似于windows的Crtl F,但是它增强了一个替换功能,可以用于所有字段
- Alt + 7——查看类中的方法
- ALT + 鼠标左键——可以按照列的方向整列选择,并统一编辑成输入内容
- for 循环的快速操作:arr是我们定义的数组,arr.for i 就可以直接遍历arr数组所有元素。即 " 变量名.for i "
- 增强for——即 " 变量名.for"
- Crtl+Shift+r——全局搜索
一键生成类中的有参构造器和Getter、Setter方法:
- 定义完成员变量后,直接右键generate,选择Constructor ,选择要赋值的成员变量,一键生成有参构造器!
- 定义完成员变量后,直接右键generate,选择Getter and Setter 生成所有成员变量的两个方法!
##编写程度的顺序
第一步:创建工程new project(一定是empty)
第二步:创建模块new module
第三步:创建包new package
第四步:创建类new class
##模块工程操作
-
删除模块操作:module要直接从磁盘里面删除,否则删不干净
-
导入模块操作:
1. 关联导入,找目标模块文件夹下的小黑点**.iml文件**(项目文件里面没有此模块代码)
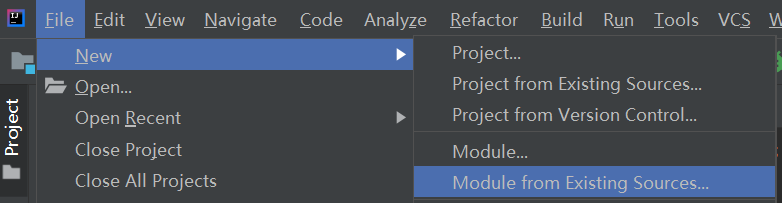
2. 创建导入
即自己先创建模块,然后再复制代码到自己的src下面。
复制的是别人模块src下的代码文件夹,一定注意。
- 打开工程:
open,注意也是找小黑点,是工程文件夹的小黑点
Foundation
混淆点
方法的调用
-
JavaBean里面方法。
对象调用类里面的成员变量,成员方法的方式:对象名 . 属性(方法)
-
有主函数的类里的方法!
这个类里面的方法,直接调用其方法名就行了。
###方法的修饰符问题
-
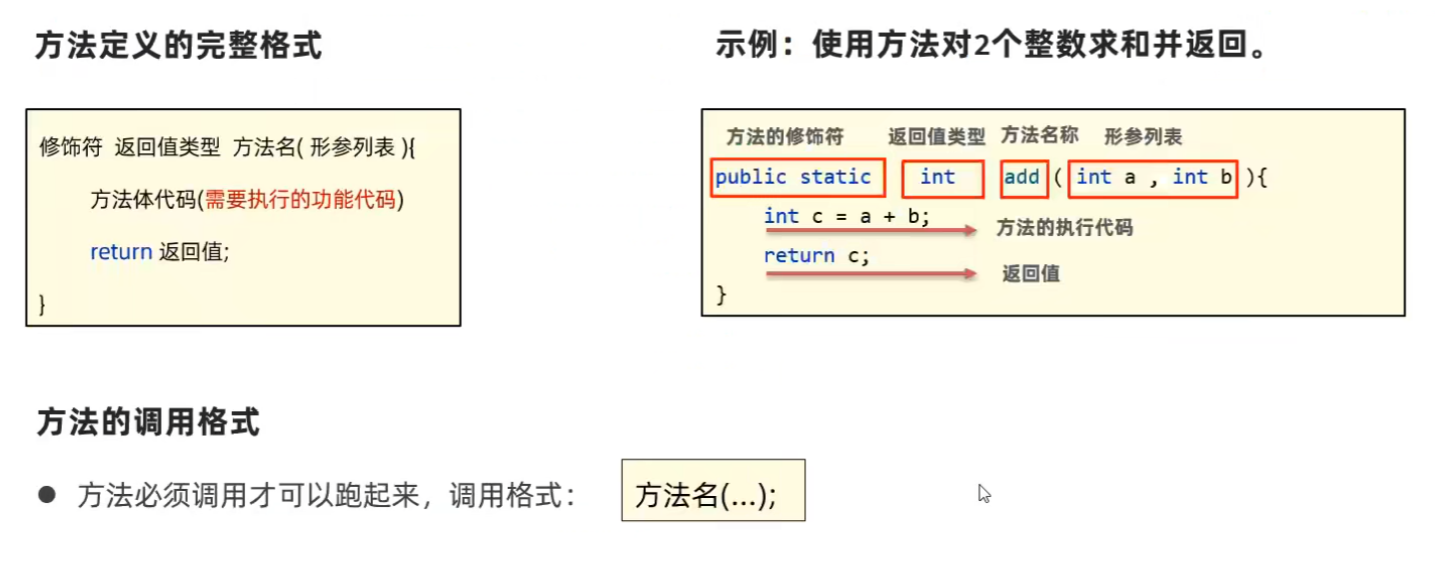
完整的方法定义格式为:
修饰符 返回值类型 方法名 (形参列表){
方法体代码; return返回值;
}
-
然后你会发现在**main函数中调用的方法修饰符必须为 public static ,方法必须为静态;**而在类里面写方法的时候,修饰符为 public 就行了。原因如下:
用static修饰的方法,无须产生类的实例对象就可以调用该方法。没有static修饰的方法,需要产生一个类的实例对象才可以调用该方法。static变量是存储在静态存储区的,不需要实例化。在main函数中调用函数只能调用静态的。如果要调用非静态的,那么必须要先实例化对象,然后通过对象来调用非静态方法。
print写法
使用 + 来连接字符串、数字、变量等输出
int i = 5;
sout("请输入第" + 1 + "个员工名字")//请输入第1个员工名字
sout("请输入第" + i + "个员工名字")
System.out.println(winnumber[i])//输出这个后自动换行
System.out.print(winnumber[i] + "\t")//输出这个后不换行,后面的紧接着输出
//
System.out.printf("%d\t",5);
类型转换
自动类型转换
因为程序中经常存在不同类型的变量赋值给其他类型的变量,所以要进行类型转换。char是2个字节,int是4个字节
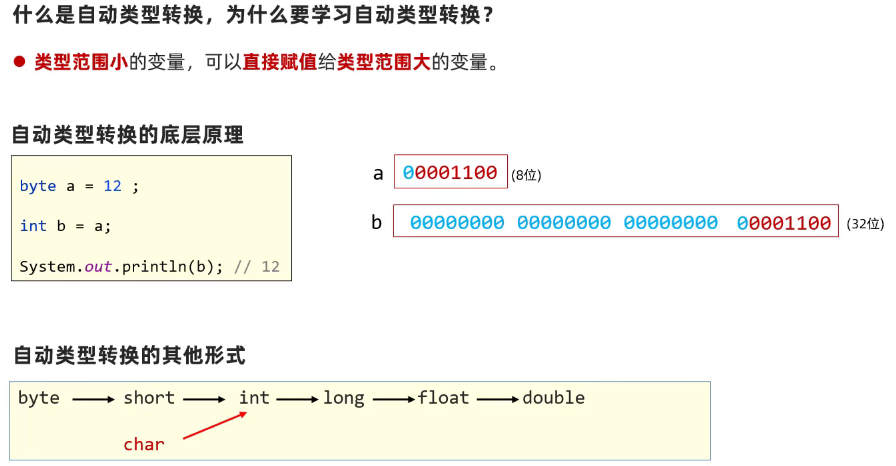
表达式的自动类型转换

byte a = 10;
int b = 20;
double c = 18;
double z = a + b + c;//a+b+c表达式的输出类型为double
System.out.println(z);
//错误情况
byte i = 2;
byte j = 10;
byte k = i + j;//表达式中,byte是先转换成int,再参与运算的
System.out.println(k);
强制类型转换
强行将大范围类型的变量,数据赋值给小范围类型的变量。转换后可能会有数据缺失。浮点类型——整型,直接丢弃小数部分。
int a = 20;
byte b = a;//这样会错误,因为a是大范围,b是小范围
byte b = (byte)a;

运算符
基本运算符
两个整数相除结果还是整数,因为表达式的最终类型,由式子里面最高类型决定==(自动类型转换原理).==
a = 10;
b = 3;
c = a / b;
sout(c)>>>3
sout(a * 1.0 / b)>>>3.333333333
"+"符号 在与字符串运算时作为连接符,结果仍为一个字符串。注意字符与字符串的区别,字符在计算机里面就是一个数字类型,当可以一起算时,字符就变成数字进行运算,不能算时,就还是以字符的形式输出。
口诀:“能算则算,不能算就在一起”
int a =5;
sout("abc" + a);//abc5
sout("abc" + 'a')//abca
sout(a + 'a')//102
sout("abc" + a + 'a')//abc5a
sout(a + "" + 'a')//5a
sout
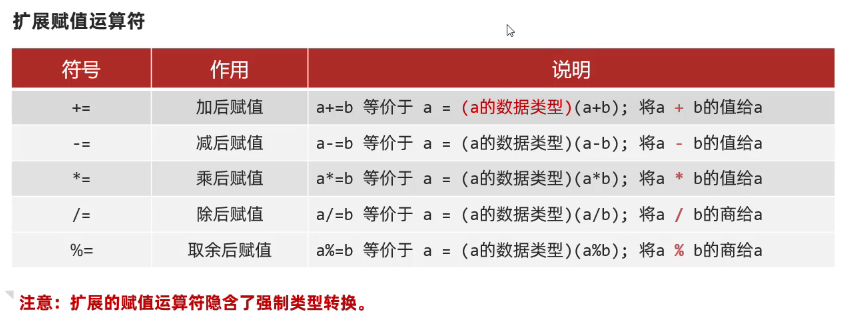
扩展赋值运算符
唯一注意的点就是:**这种运算符隐含了强制类型转换。**这与表达式的自动类型转换有一点区别,例如==/一定记住扩展赋值运算符,输出类型与前面那个数据类型相同==
byte a = 10;
byte b = 20;
int i = a + b;//a + b输出为int类型
a += b;//输出a为byte类型,而不是int。因为他相当于a = (byte)(a + b)
//一定记住扩展赋值运算符,输出类型与前面那个数据类型相同
逻辑运算符
注意:运算完结果是一个布尔类型数据。True / False


三元运算符
格式:条件表达式?值1:值2
if 表达式==True,则返回值1,否则返回值2。
int score = 98;
String rs = score>=60 ? "Pass":"Fail";
键盘录入技术
import java.util.Scanner
Scanner sc = new Scanner(System.in);
int age = sc.nextInt();
String name = sc.next();//输入字符串
流程控制
顺序结构
即按照代码顺序从上往下执行。
分支结构
- if 语句
if(条件表达式){
语句;
}
//python
if 条件表达式:
语句
-
switch
注意事项:
switch()里面的表达式只能是 byte,short, int, char,枚举,String,不支持float,double,long。
case给的值不允许出现重复,而且只能是字面量,不能是变量。即可以是"aa", ’a’,不能说int a = 5;这个a。
记得break,否则出现穿透,把下面case的结果都执行。
//表达式!=条件表达式
switch(表达式/变量){
case 值1 :
执行语句....;
break;
case 值2 :
执行语句....;
break;
default:
执行语句....;
}
循环结构
- for语句
for(int i =0; i< 3; i++){
sout("hello world")
}
//python
for i in range(5):
aaaaa
- while
while(){
}
- do - while
do{
}while();
- 死循环
while(true){
sout("si diao la")
}
break ————立即退出该次循环
###break,continue
break: 跳出并且结束当前循环的执行。
continue:用于跳出当前循环的当次循环,进入下一次循环
Random
import java.util.Random;
Random r = new Random();
int number = r.nextInt(10);//0 ~ 9 的随机数,不包含10.
sout("随机产生了:" + number)
数组
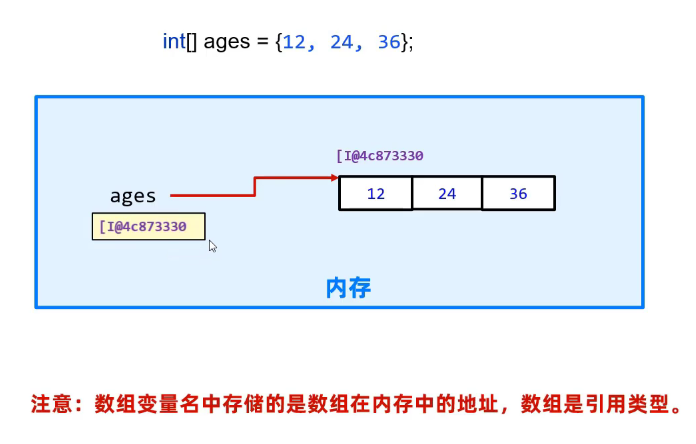
记住:数组变量名称存储的是数组第一个元素的内存地址,所以数组是引用类型。
计算机编号都是从0开始,matlab不是计算机编号。
特点:
- 在内存中申请一块连续的空间
- 数组下标从 0 开始
- 每个数组元素都有默认值,基本类型的默认值为 0、0.0、false,引用类型的默认值为 null
- 数组的类型只能是一个,且固定,在申明时确定
- 数组的长度一经确定,无法改变,即定长。要改变长度,只能重新申明一个。但数组元素内容可以变化。
- 初始化时赋值(静态初始化)
int[] nums1 = new int[3]; //(会有默认值)
int[] nums2 = {1,2,3};
String names[] = {'a', 'b', 'c'};// 等价于String names = new int[]{'a', 'b', 'c'}
sout(names);// [I@7699a589,数组名称存储的是,数组对象第一个数据的内存地址(与c++一样)
sout(names[0]);
int len = arr.length;//数组长度
- 先初始化,后赋值(动态初始化)
int arr[] = new int[3];//也会在内存中,先创建数组对象,和静态是一样的,只不过数据都是初始值。
arr[0] = 100;
sout(arr[0]);
动态初始化时,各类型数组元素的默认值为:

数组的内存图
例子:
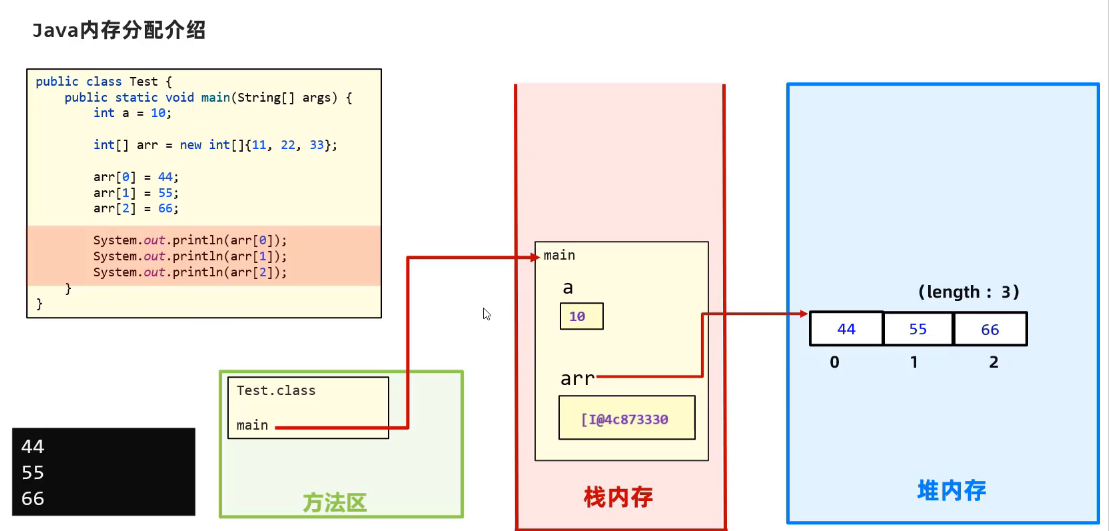
方法区
字节码文件,方法,类,加载时进入的内存
栈
方法运行时所进入的内存变量在这里
堆内存
new出来的东西(对象)会在这块内存中开辟空间,并产生地址
常见问题
- 访问的元素位置超过最大索引。
- 数组变量中没有存储数组的地址,而是null,则访问时会出现NullPointerException
方法
注意:方法与方法之间是平级的, 不能嵌套定义,只能相互调用。
return执行之后,后面的语句均不会再执行。

两种基本的定义
**每个方法都有返回值类型,**voi代表没有返回值, 但并不是说,该方法没有返回值类型。
//第一种
public static void fun1(int a, int b){
int c = a + b;
sout(c);
}
//第二种
public static char getchar(){
return 'a';
}
方法的内存原理
定义的所有方法,包括主方法,还有次方法,运行的时候
-
类文件编译成.class文件
-
所有的方法到方法区里面,
-
按照main()里面顺序按个到栈内存去执行,涉及到了堆内存的就再去堆内存里面;
-
注意当运行完一个方法后,java会自动清除掉该方法。

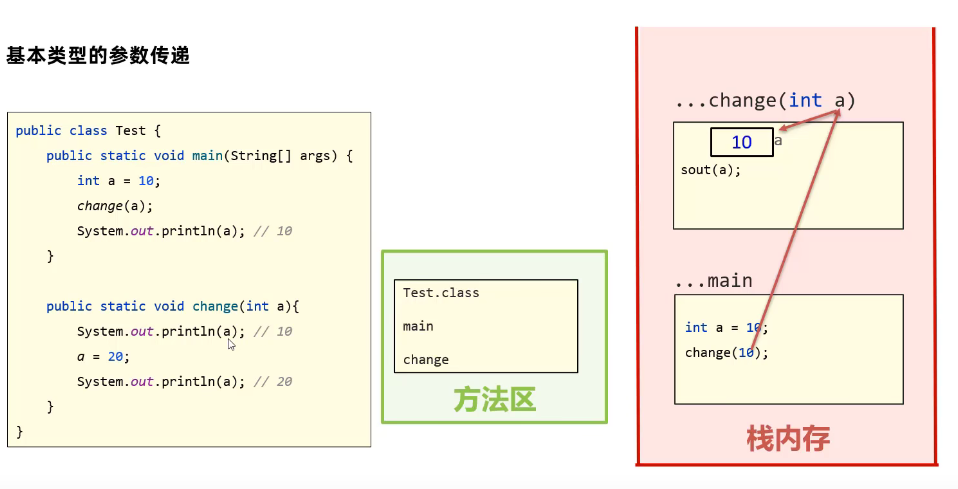
方法的参数传递机制
-
基本类型的参数传递(整数,浮点,字符,布尔)
只涉及到了内存里面的方法区和栈内存,因为他没有new一个对象
关键词:值传递; 原因:定义的基本类型,均是直接存储的是数据。
在传输实参给方法的形参时,传的时实参变量中存储的值,而不是实参本身。
形参的变化不会影响实参。
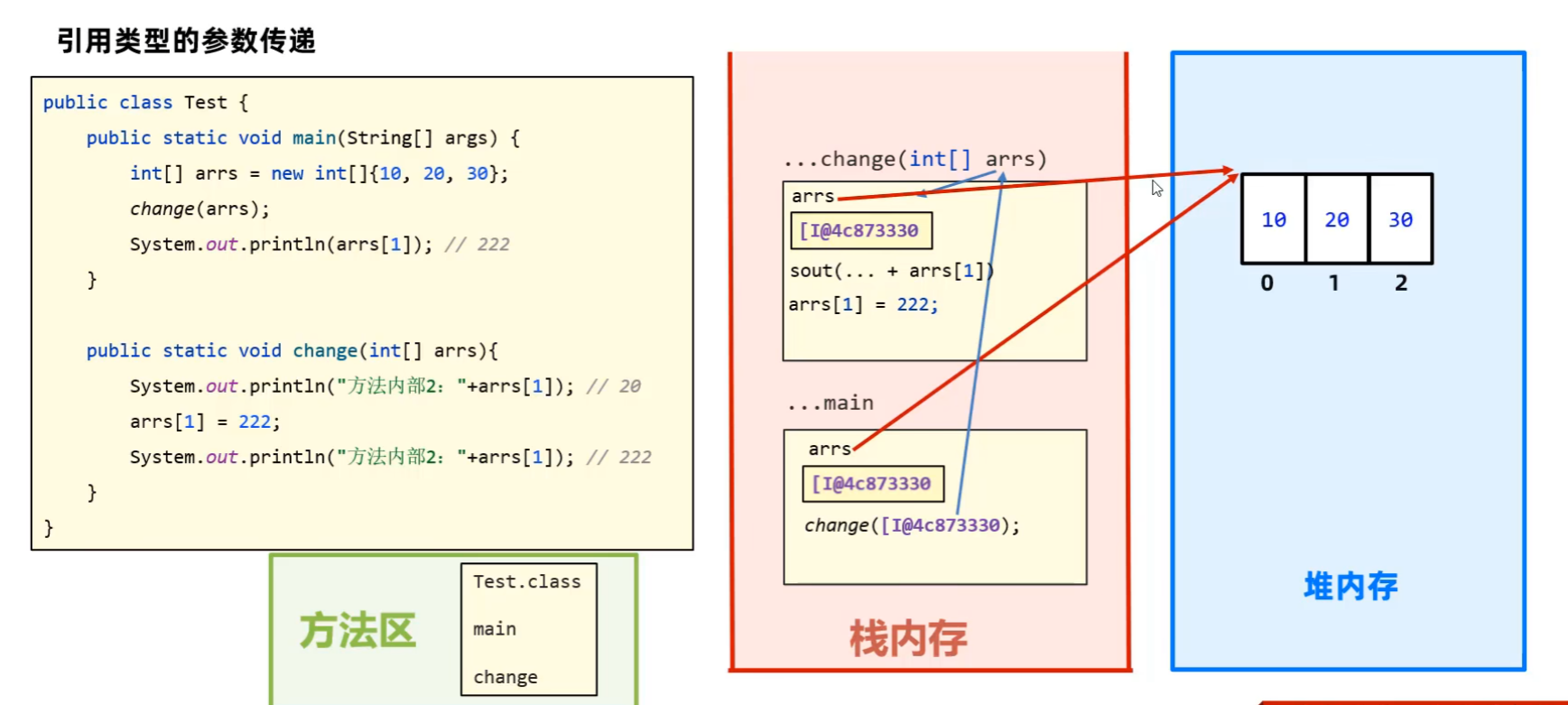
-
引用类型的参数传递(数组,String)
这个涉及到了java里面所有的内存,方法区,栈内存,堆内存。
关键词:值传递
但是形参引起的变化会改变实参,为什么呢?
因为引用类型存储的是堆内存里面对象的地址,传递的时候也是传递的是地址,形参实参均指向一个地址,所有说形参的变换会导致实参里面的变化。因为他们两个都仅仅是指向撒,最终的数据是堆内存里面的。
###方法重载
同一个类中,出现多个方法名称相同,但是形参列表不同,这些方法就是重载方法。(不用管修饰符和返回值类型)
return关键字的单独使用
return;
-------->可以立即跳出并且结束当前方法的执行。return的单独使用可以用在void任何方法中。
面对对象编程
面向:就是拿或者找的意思
对象:就是东西的意思
面对对象编程:拿东西过来编程
设计类并创建对象
必须先设计类,才能获得对象。类:就是设计图纸,对象就是设计出来的实例。
在编程时,新建一个.class文件,然后写完类的内容,再新建一个.class文件,main方法就可以直接使用 这个类去创建对象
public class 类名{
1. 成员变量(代表属性,一般是名词)
2. 成员方法(代表行为,一般是动词)
3. 构造器
4. 代码块
5. 内部类
}
//创建对象与对象数组。
类名 对象名 = new 构造器();
类名[] 对象数组名 = new 构造器[100]//和创建数组类似,类本身也是一个类型。里面存储的是每个对象的堆内存地址,初始值为null。
example:
//定义类:
public class Car{
//属性,成员变量
String name;
double price;
//行为,方法
public void start(){
}
public void run(){
}
}
//获得类的对象:
Car mycar = new Car();
mycar.name = "大蹦";
mycar.price = 1000;
mycar.start();
mycar.run();
//创建对象数组
Car[] Carshop = new Car[100];//Carshop= [null, null, null, .....]

注意事项:
一个java文件中可以定义多个class类,并且只有一个类是public修饰,并且public修饰的类名必须成为代码文件名。实际开发中,建议还是一个文件定义一个class类。
对象的内存图
两个对象的内存图:
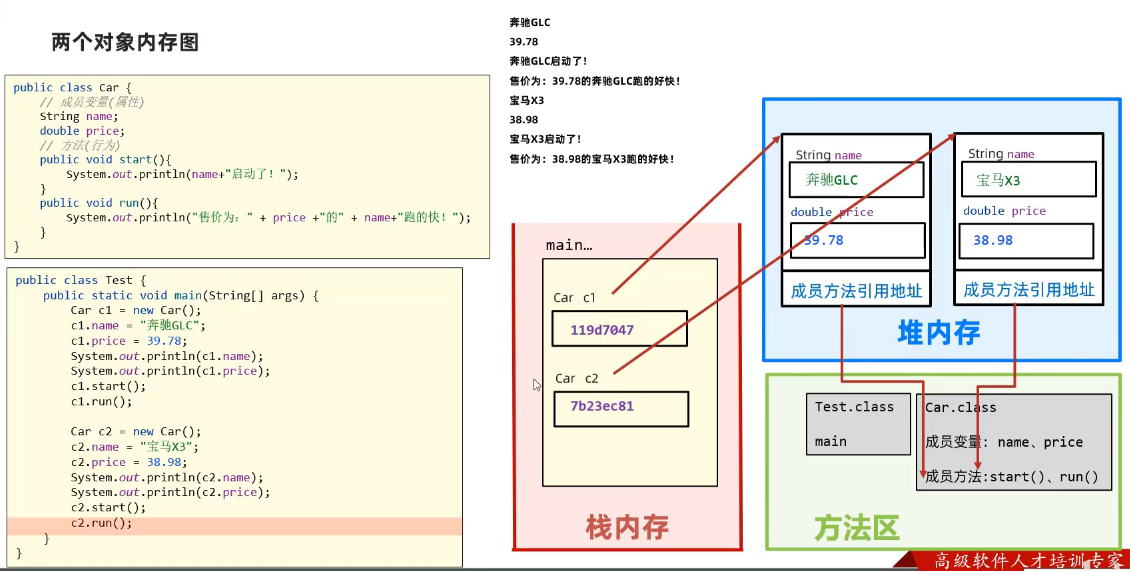
- 对象放在堆内存中。对象里的方法还是放在方法区内。
- Car c = new Car(); c变量名存储的是对象在堆内存中的地址。
两个变量指向同一个对象
即把一个对象S1,直接赋值给另一个相同的对象类型S2.
这个和数组的类似,对象名都是存储的对象的堆内存地址。
构造器
重点了,一定注意!
第一点:前面不是说了,要获得对象,先要创建一个类嘛,然后通过Car mycar = new Car( ); 获得我们的对象mycar,存储堆内存里面的对象数据的地址。但是这个对象是由这个Car()类,创建的吗? 答案是:NO。他是由这个Car()类里面的构造器创建的。啊,那里有构造器啊,我木有写啊,也没有看到相关的代码啊!那是因为在你创建类的时候,java会自动给你创建一个默认的无参数构造器,并且不会显示出来代码! 它有点类似于Python里面的__init__函数,是用来初始化配置的,只不过python里面的是显式的,这个是隐式的,下面会细讲。
构造器的作用
用于初始化一个类的对象,并且返回对象的地址。
前面的这段获得对象的代码Car mycar = new Car(),里面的new的后面是这个类嘛?不,他是类里面的构造器!
- 无参数构造器:默认存在的,初始化对象时,成员变量均采用默认值。
- 有参构造器:自己写,在初始化对象的时候,可以为对象属性赋值。
- 注意:假如你写了有参构造器,那么java默认的这个无参构造器会自动清除!如果需要无参的,就需要自己再去创建了。
//构造器的定义形式
修饰符 类名(形参列表){
...
}
//Example
public class Car(){
...
// 无参数构造器。(默认存在,隐式)
public Car(){
...
}
// 有参数构造器
public Car(String name, String price){
...
}
}
快捷键:定义完成员变量后,直接右键generate,选择Constructor ,选择要赋值的成员变量,一键生成有参构造器!
this关键字
作用:在成员方法和构造器中使用;**代表当前对象的地址,**用于访问当前对象的成员变量,方法。
public class Car(){
String name;
double price;
//构造器与this共同使用
public Car(String name, double price){
this.name = name;
this.price = price;
}
//这样也可以赋值成功,但是很不好看,不专业 !所以出现了this的使用
public Car(String n, double p){
name = n;
price = p;
}
}
面对对象的三大特征
封装
简言之:”合理隐藏,合理暴露“。 很简单,就是在原来类的简单定义上面,将成员变量进行封装(private)一下,然后加两个对象访问成员变量的方法!
作用:**增加程序代码的安全性。**并且适当的封装可以提高效率,让程序更容易理解与维护
封装实现步骤:
- 对成员变量使用 private 关键字修饰进行隐藏,private修饰后该属性就只能在当前类中访问。
- 然后提供public修饰的getter、setter方法暴露其赋值与取值。
举个例子就知道了:
//Define class
public class Car(){
//对属性private
private String name;
private double price;
//提供各个属性的getter、setter方法
//name
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
//price
public void setPrice(double price){
this.price = price;
}
public double getPrice(){
return price;
}
}
快捷键:定义完成员变量后,直接右键generate,选择Getter and Setter 生成所有成员变量的两个方法!
JavaBean
其实就是把前面的类啊,对象啊,构造器,this等 合并上封装全部整合起来,定义了一套标准的实体类的写法,以后所有的类都按照这种写法就行了!
- 成员变量用private修饰;
- 每个成员变量提供对应的Getter、Setter方法;
- 必须提供一个无参构造器;(重点罗)
String类
定义:java.lang.String类代表字符串,String类定义的变量可以用于指向字符串,然后操作该字符串。
Java程序中所有的字符串文字(如“abac”)都是此类的对象!(只是简写了而已,就像基本类型一样,但它还是一个类啊,我们定义的那个叫对象,所以前面一直说字符串是引用类型的变量)。
+ 号用于字符串拼接,拼接前会把与字符串相加的任何类型转成字符串,再拼接成一个新的字符串;
创建字符串对象的两种方式:
- 第一种:直接使用 “ ” 定义。
String name = "heima";
-
第二种:使用类里面的构造器创建
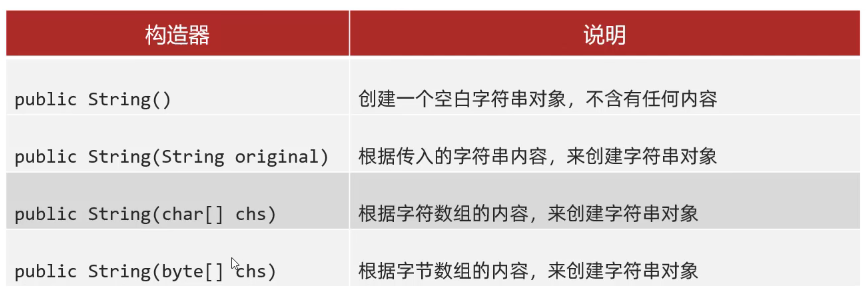
其中byte这里,因为byte类型范围是-128-128,它会把字节数组里面的整数全部转化成相应的字符!
String name = new String();//不用
String name = new String("heima");//不用
//第三种
char[] ch = new char[]{'A','B','c'};
String name = new String(ch);
//第四种
byte[] bt = new byte[]{97,98,99};
String name = new String(bt);
name.sout
>>>abc
这两种定义方式的区别
-
以 “ ” 方式给出的字符串对象,会在字符串常量池里面,并且相同的字符串内容只会存储一份。
-
通过构造器new出来的对象,每new一次会产生一个新的对象,就算是字符串内容相同也会产生新的对象,存储在堆内存里面
String s1 = "abc"; String s2 = "abc"; sout(s1 == s2); //true char[] chs = new char[]{'a', 'b', 'c'}; String s3 = new String(chs); String s4 = new String(chs); sout(s3 == s4); //False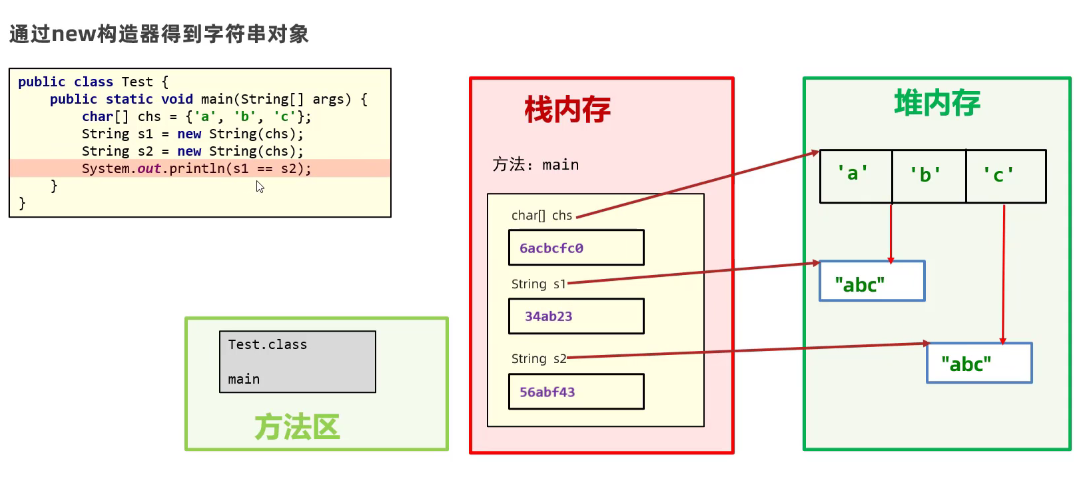
==注意:String是不可变字符串类型,==因为它的对象在创建后不能被更改!因为String变量每次的修改其实都是产生并指向了新的字符串对象,原来的字符串对象没有发生改变。
String对象内存原理
- 以双引号 “ ” 给出的字符串对象,存储在堆内存中的字符串常量池;(看见了 “ ” 的就一定会在常量池里面创建一个对象,不管位置在哪里)
- 其他情况的字符串对象均存储在堆内存中(不在字符串常量池);
- java存在编译优化机制,在程序编译时,“a” + “b” + “c” 会直接转化成 “abc” !(仅限于这种一模一样的)
Example1:
public static void main(Stringp[] args){
String name = "传智";//第一步
name += "教育";// 第二步
name += "中心";// 第三步
}
第一步:传智以 ” ”形式给出,所以放在字符串常量池!name对象存储其地址。
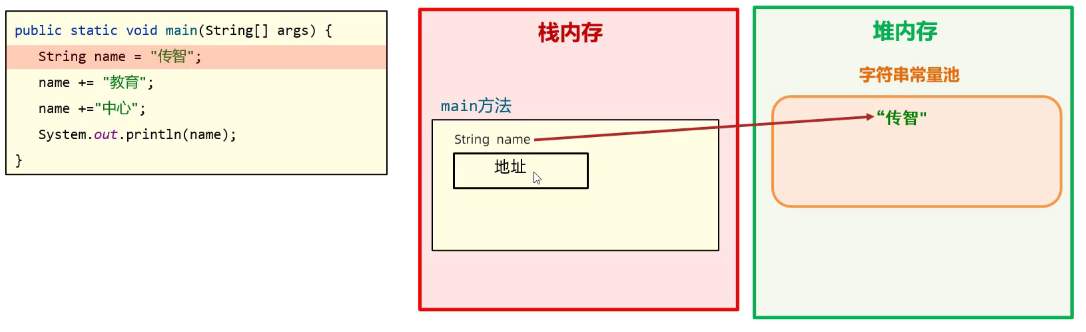
第二步:”教育“也存放在字符串常量池,然后name这边进行了 “+” 的字符串运算,结果放在堆内存里面,然后新的字符串数据的地址,给name存储。这就说明了为什么String类型是不可变字符串,因为他的对象创建后,在堆内存的数据就不会被删除了,只会出现重新指向的情况!
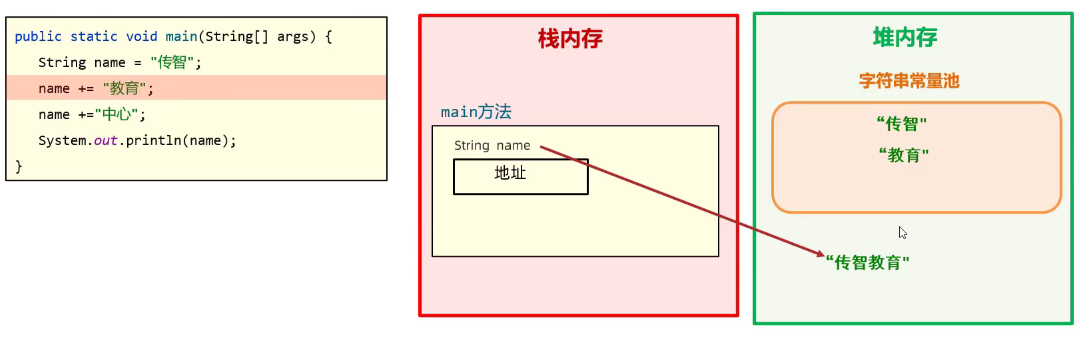
第三步:
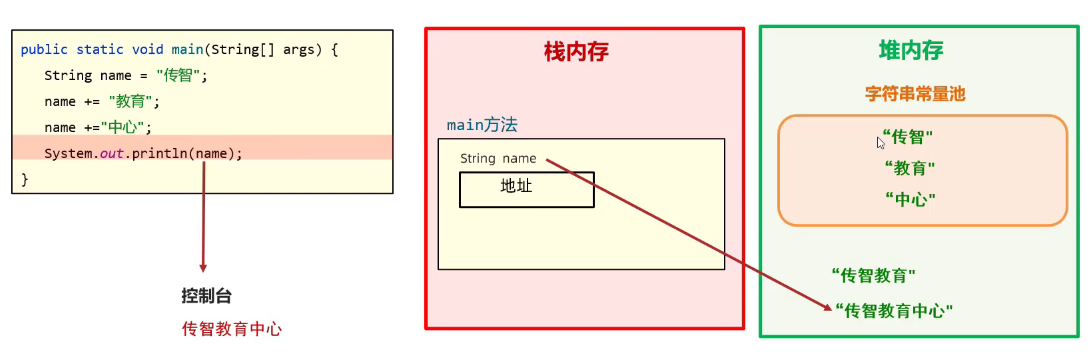
Example2:
这行代码 创建了几个对象?
String s = new String("abc");

String类常用API
- 比较字符串内容(boolean)
| 方法名 | 说明 |
|---|---|
| public boolean equals ( String another) | 该字符串对象与指定字符串对象比较,只关心字符串内容是否完完全全一致 |
| public boolean equalsIgnoreCase(String another) | 也是比较内容,但忽略大小写,常用于验证码!! |
为什么不用 == 来比较?因为字符串对象是引用类型,不是直接存储数据,再加上其内存的独特性,完全不能用==比较,根本判断不对!
-
返回字符串长度
public int length() -
获取字符串某个索引位置的字符
public char charAt(int index) -
将当前字符串转换成字符数组返回
public String toCharArray() -
根据开始和结束的索引进行截取,得到新的字符串(左闭右开)
public String substring(int beginIndex, int endIndex) -
从传入的索引处截取,一直截取到末尾处,得到新的字符串
public String substring(int beginIndex) -
将字符串里面的某一段值,用新给的值替换掉,返回新的字符串
public String replace(String target, String replacement) -
切割字符串,得到一个字符串数组并返回(常用 " , " " ; " 等)
public String[] split(String s)//"," ";" -
判断该字符串内容里是否含有传入的字符串内容
public boolean contains(String s) -
判断该字符串是否以输入的字符串内容开始
public boolean startsWith(String s)
ArrayList 集合
快速入门
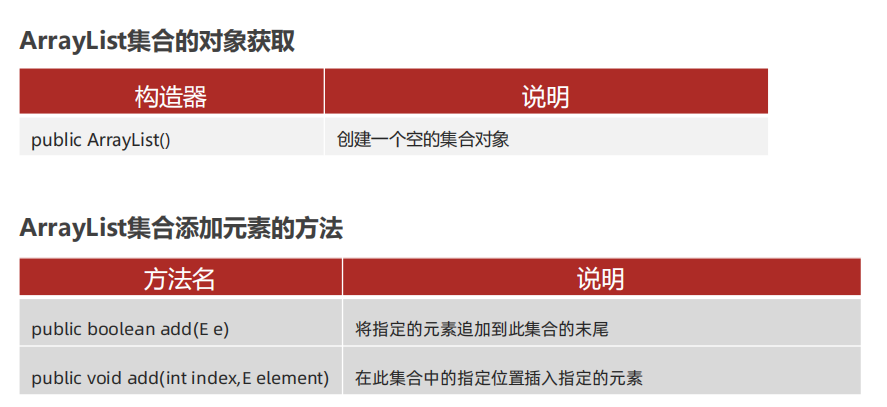
ArrayList list = new ArrayList();
list.add("java");
list.add(17);
list.add(17.5);
list.add(True);
sout(list);
list.add(1,"插入中国");
System.out.println(list);
>>>
[java, 17, 17.5, true]
[java, 插入中国, 17, 17.5, true]
泛型(统一集合内的元素类型)
ArrayList< E>:其实就是一个泛型类,可以在编译阶段约束集合对象只能操作某种数据类型。并不是所有类都支持泛型,要看类的后面有没有这个< E> .
举例:
- ArrayList :此集合只能操作字符串类型的元素。
- ArrayList:此集合只能操作整数类型的元素。int是基本类型不支持,Integer是整数的引用类型。
注意:集合中只能存储引用类型,不支持基本数据类型。
ArrayList<String> list1 = new ArrayList(); //List1内只能添加String类型
ArrayList常用方法
其中E——表示其集合泛型设置的 元素类型。
public E get(int index) 返回指定索引处的元素
public int size() 返回集合中的元素的个数
public E remove(int index) 删除指定索引处的元素,返回被删除的元素
public boolean remove(Object o) 删除指定的元素,返回删除是否成功;有重复的只删除前面那个
public E set(int index,E element) 修改指定索引处的元素,返回被修改的元素
注意:直接用其对象调用方法即可,他会修改到其对象的内容。
ArrayList存储自定义类型(类)
自定义类型是什么? 类就是一种类型啊,String也是一个类啊!类就是一种类型!
其实简单来说,就是用集合去存储我们的多个对象名,方便遍历使用。集合中存储的元素并不是对象本身,而是对象的地址。
Movie 是我们创建的影片类;
movie1是我们创建的第一个对象;
movie2是我们创建的第一个对象;
movie3是我们创建的第一个对象;
ArrayList<Movie> mymovies = new ArrayList<>();
mymovies.add(movie1);
mymovies.add(movie2);
mymovies.add(movie3);
mymovies.add(new Movie("肖生客的救赎",9,"罗冰四")); //简单,没有创建对象名变量
mymovies.add(new Movie("《阿甘正传》", 9.5 , "汤姆.汉克斯"));
//遍历集合中的影片对象并展示出来
for (int i = 0; i < movies.size(); i++) {
Movie movie = movies.get(i);
System.out.println("片名:" + movie.getName());
System.out.println("评分:" + movie.getScore());
System.out.println("主演:" + movie.getActor());
ArrayList遍历删除
因为集合的大小是随着你的每次删除而变化的,每次删除之后,集合内的数据索引会马上发生变化! 索引在后面的元素会直接放到前面来。
假如你要删除98, 77, 66, 89, 79, 50, 100中,小于80的数据,直接从0开始遍历删除的话就会出现只删除了77,79的情况!
解决办法:从集合后面遍历然后删除,可以避免漏掉元素。
ArrayList应用:元素搜索
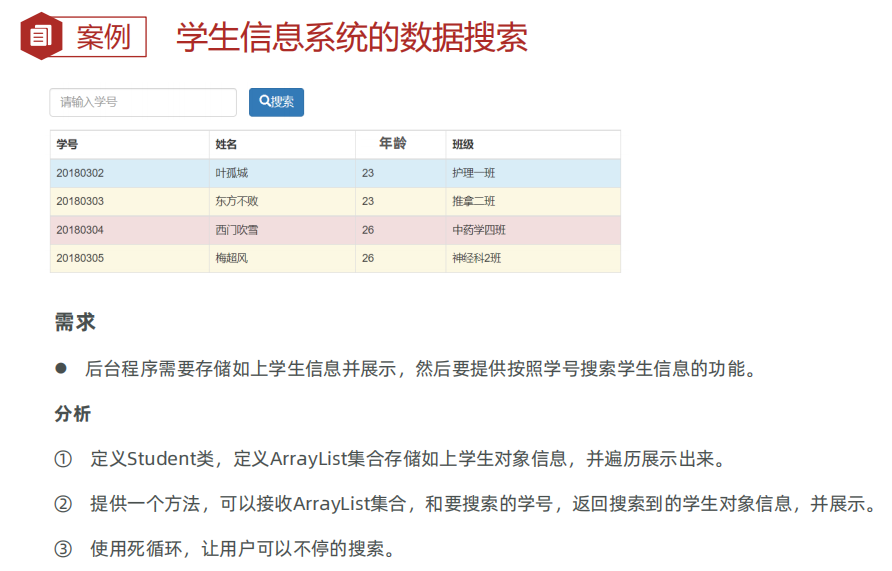
public class Student {
private String studyId;
private String name;
private int age;
private String className;
.....Getter,Setter,Construtor
}
public class ArrayListTest6 {
public static void main(String[] args) {
// 1、定义一个学生类,后期用于创建对象封装学生数据
// 2、定义一个集合对象用于装学生对象
ArrayList<Student> students = new ArrayList<>();
students.add(new Student("20180302","叶孤城",23,"护理一班"));
students.add(new Student("20180303","东方不败",23,"推拿二班"));
students.add(new Student( "20180304","西门吹雪",26,"中药学四班"));
students.add(new Student( "20180305","梅超风",26,"神经科2班"));
System.out.println("学号\t\t名称\t年龄\t\t班级");
// 3、遍历集合中的每个学生对象并展示其数据
for (int i = 0; i < students.size(); i++) {
Student s = students.get(i);
System.out.println(s.getStudyId() +"\t\t" + s.getName()+"\t\t"
+ s.getAge() +"\t\t" + s.getClassName());
}
// 4、让用户不断的输入学号,可以搜索出该学生对象信息并展示出来(独立成方法)
Scanner sc = new Scanner(System.in);
while (true) {
System.out.println("请您输入要查询的学生的学号:");
String id = sc.next();
Student s = getStudentByStudyId(students, id);
// 判断学号是否存在
if(s == null){
System.out.println("查无此人!");
}else {
// 找到了该学生对象了,信息如下
System.out.println(s.getStudyId() +"\t\t" + s.getName()+"\t\t"
+ s.getAge() +"\t\t" + s.getClassName());
}
}
}
/**
根据学号,去集合中找出学生对象并返回。
* @param students
* @param studyId
* @return
*/
public static Student getStudentByStudyId(ArrayList<Student> students, String studyId){
for (int i = 0; i < students.size(); i++) {
Student s = students.get(i);
if(s.getStudyId().equals(studyId)){
return s;
}
}
return null; // 查无此学号!
}
}
static修饰符
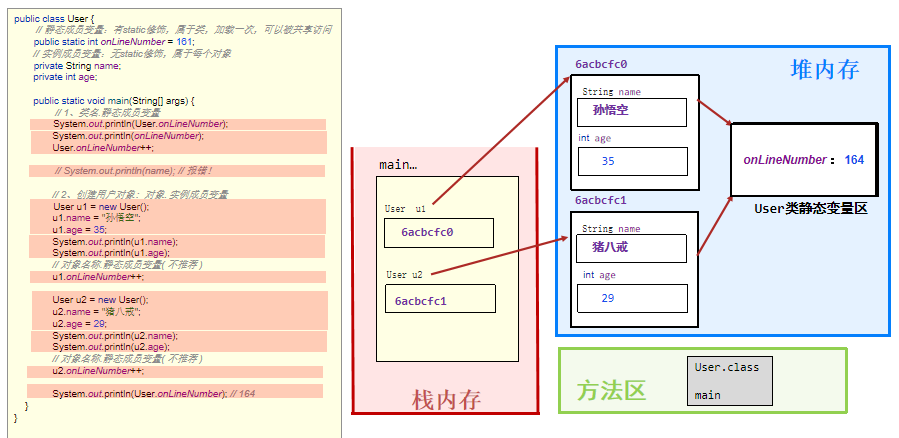
static是静态的意思,可以修饰成员变量和成员方法。静态的东西都是最最最先加载的,在类创建的同时加载,比对象里面的任何东西都早!注意:静态的东西只能处理静态的哦!
静态成员变量
从现在类的成员变量分为两类:
-
静态成员变量:static修饰,属于类的东西,堆内存中只存储一份,随着类的创建同时产生,可以被共享访问、修改。也是可以被对象访问!
调用方式:类名.静态成员变量(仅仅限于在该类的内部使用的时候,可以不加类名);对象.静态成员变量(不要用这种哦,很不专业)
-
实例成员变量:无static修饰,就是我们一般写的那个,属于每个对象的东西(记住,类有多个对象哦)。
静态成员变量用于表示:在线人数等需要被共享的信息。
注意哦:=对象名也是一个变量哦,它也可以作为静态成员变量!还有静态集合哦,这几个才用的多!
内存原理:
-
类编译完,在方法区生成.class的时候,会同时在堆内存创建该类的静态变量区,加载我们的静态成员变量。
-
后面创建的每个类的对象,都会自动指向该静态变量区哦!!
静态成员方法
类的成员方法从现在开始分为两种:
-
静态成员方法(有static修饰,属于类),随着类的创建同时在方法区里面加载,建议用类名访问,也可以用对象访问。
调用:类名.静态成员方法(仅仅限于在该类的内部使用的时候,可以不加类名)
-
实例成员方法(无static修饰,属于对象),只能用对象触发访问。
调用:对象.实例成员方法
静态成员方法用于:以执行一个通用功能为目的,或需要方便访问,可以申明成静态方法
static访问时权限
- 静态方法只能访问静态的成员,不可以直接访问实例成员。
- 实例方法可以访问静态的成员,也可以访问实例成员。
- 静态方法中是不可以出现this关键字的。
只要记住:静态的是属于类的,只能访问属于类的,不能访问对象的;但对象是类的儿子,所以对象可以访问类的。
静态的东西是属于类的,类自己的东西之间肯定可以相互访问,因为类有无数个对象,类区访问实例的成员,方法,我怎么知道它是访问的哪个对象的呢,对不对!;但因为对象是我类的儿子,我不能太狠心,爸爸买的车(变量和方法)也可以借儿子开开,但爸爸并不是很乐意,最好不要找我借车开!this代表的意义是当前最近的对象啊,跟我类里面的东西有什么关系呢。
static的应用
工具类
工具类中定义的都是一些静态方法,每个方法都是以完成一个共用的功能为目的。
-
工具类的好处:
一是调用方便,二是提高了代码复用(一次编写,处处可用)
-
为什么工具类中的方法不用实例方法做?
实例方法需要创建对象调用,此时用对象只是为了调用方法,这样只会浪费内存。
-
工具类的定义注意
建议将工具类的构造器进行私有,工具类无需创建对象。
里面都是静态方法,直接用类名访问即可。
// 静态工具类
public class VerifyTool {
/**
私有构造器
*/
private VerifyTool(){
}
/**
静态方法
*/
public static String createCode(int n){
// 1、使用String开发一个验证码
String chars = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
// 2、定义一个变量用于存储5位随机的字符作为验证码
String code = "";
// 3、循环
Random r = new Random();
for (int i = 0; i < n; i++) {
int index = r.nextInt(chars.length());
// 4、对应索引提取字符
code += chars.charAt(index);
}
return code;
}
}
// 测试类
public class Register {
public static void main(String[] args) {
// 验证码:
System.out.println("验证码:" + VerifyTool.createCode(5));
}
}
静态代码块
-
代码块是类的5大成分之一(成员变量、构造器,成员方法,代码块,内部类),定义在类中方法外。
-
在Java类下,使用 { } 括起来的代码被称为代码块 。
-
代码块分为
静态代码块:
格式:static{ }
特点:static关键字修饰,随着类的加载而加载,并且自动触发、有且仅执行一次(意 思是这个代码里面的内容,只会自动执行一次,后面不能被调用了,与静态成 员变量,方法不同,他们被加载后,可以被无数次调用)
使用场景:类初始化的时候静态数据初始化的操作,以便后续使用。(只能处理静态)构造代码块(了解,用的少):
格式:{ }
特点:每次创建对象,调用构造器执行时,都会执行该代码块中的代码,并且在构造器执行前执行
使用场景:初始化实例资源。
使用范例:
public class TestDemo1 {
public static String schoolName;
static{
System.out.println("==静态代码块被触发执行==");
schoolName = "黑马程序员";
}
public static void main(String[] args) {
System.out.println("=========main方法被执行输出===========");
System.out.println(schoolName);
}
}

public class StaticCodeTest3 {
/**
模拟初始化牌操作
点数: "3","4","5","6","7","8","9","10","J","Q","K","A","2"
花色: "♠", "♥", "♣", "♦"
1、准备一个容器,存储54张牌对象,这个容器建议使用静态的集合。静态的集合只加载一次。
*/
public static ArrayList<String> cards = new ArrayList<>();
/**
2、在游戏启动之前需要准备好54张牌放进去,使用静态代码块进行初始化
*/
static{
// 3、加载54张牌进去。
// 4、准备4种花色:类型确定,个数确定了
String[] colors = {"♠", "♥", "♣", "♦"};
// 5、定义点数
String[] sizes = {"3","4","5","6","7","8","9","10","J","Q","K","A","2"};
// 6、先遍历点数、再组合花色
for (int i = 0; i < sizes.length; i++) {
// sizes[i]
for (int j = 0; j < colors.length; j++) {
cards.add(sizes[i] + colors[j]);
}
}
// 7、添加大小王
cards.add("小🃏");
cards.add("大🃏");
}
public static void main(String[] args) {
System.out.println("新牌:" + cards);
}
}
单例设计模式
-
什么是设计模式(Design pattern)
开发中经常遇到一些问题,一个问题通常有n种解法的,但其中肯定有一种解法是最优的,这个最优的解法被人总结出来了,称之为设计模式。
设计模式有20多种,对应20多种软件开发中会遇到的问题,学设计模式主要是学2点:第一:这种模式用来解决什么问题。第二:遇到这种问题了,该模式是怎么写的,他是如何解决这个问题的。 -
单例模式
可以保证系统中,应用该模式的这个类永远只有一个实例,即一个类永远只能创建一个对象。
例如任务管理器对象我们只需要一个就可以解决问题了,可以节省内存空间。 -
单例的实现方式:
饿汉单例模式。懒汉单例模式。
-
饿汉单例模式
即像要饿死了一样,我希望午饭已经提取给我准备好了,我可以直接吃!,即在用类获取对象的时候,对象已经提前为你创建好了。有一点注意哦,对象名也是一个变量哦
设计步骤:
定义一个类,把构造器私有。
定义一个静态变量存储一个对象。(静态对象)// 饿汉类 public class SingleInstance1 { /** 定义一个静态变量存储一个对象即可 :属于类,与类一起加载一次 */ public static SingleInstance1 instance = new SingleInstance1(); private SingleInstance1(){ } } // 测试类 public class Test { public static void main(String[] args) { SingleInstance1 s1 = SingleInstance1.instance; SingleInstance1 s2 = SingleInstance1.instance; SingleInstance1 s3 = SingleInstance1.instance; System.out.println(s1); System.out.println(s2); System.out.println(s3); System.out.println(s1 == s2); //true } } -
懒汉模式
即我都要饿死了,但我太懒了,菜都洗好了,但不提前区做饭,硬要等到12点了再去做饭;在真正需要该对象的时候,才去创建一个对象(延迟加载对象)。
设计步骤:
定义一个类,把构造器私有。
定义一个静态变量存储一个对象。
提供一个返回单例对象的方法// 懒汉类 public class SingleInstance2 { /** 2、定义一个静态的成员变量用于存储一个对象,一开始不要初始化对象,因为人家是懒汉 */ private static SingleInstance2 instance; private SingleInstance2(){ } /** 3、提供一个方法暴露,真正调用这个方法的时候才创建一个单例对象 */ public static SingleInstance2 getInstance(){ if(instance == null){ // 第一次来拿对象,为他做一个对象 instance = new SingleInstance2(); } return instance; } } // Test class public class Test2 { public static void main(String[] args) { // 得到一个对象 SingleInstance2 s1 = SingleInstance2.getInstance(); SingleInstance2 s2 = SingleInstance2.getInstance(); System.out.println(s1 == s2); } }
继承
-
关键字:extends(两个类之间的关系)子类,父类。所以类都是Object的子类。
-
注意:子类可以继承父类的属性和行为,但是子类不能继承父类的构造器和静态成员。
子类可以继承父类的私有成员,只是说不能访问,就像你爸给你了保险箱,但是没有给密码哦,但也算是你继承下来了呀。父类有两个儿子,一个是对象(多生子,爸爸不喜欢,不想去拿他的东西),一个是子类(比爸爸流批多了的儿子,把爸爸什么东西都学会了,还自学了很多)
-
**有争议的点:**子类是否继承了父类的静态成员?
答案是:没有!是共享关系!
前面说了静态成员是属于这个类自己的,是独特的东西,但是子类可以直接使用父类的静态成员,对象也可以直接用类的静态成员,但不要这么搞哦。
内存原理
子类在创建的时候,会在堆内存里面创建一片区域,然后这片里面会再划分一个父类空间(super)和一个子类空间(this)!
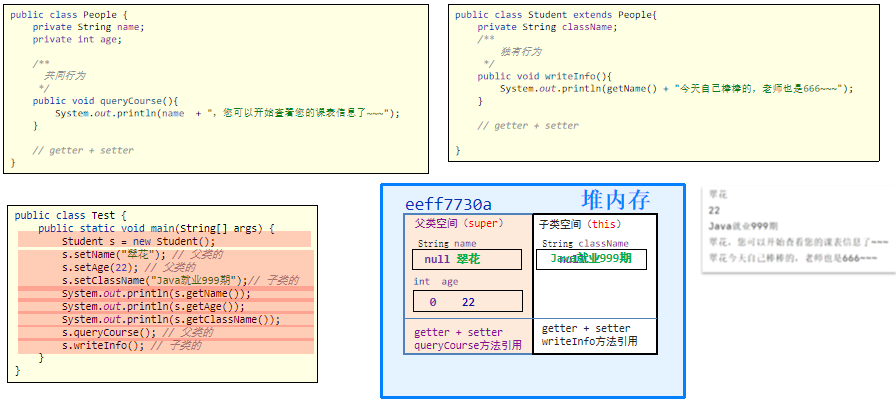
继承后,成员访问的特点
-
就近原则,先找子类里面的,再找父类里面的。
-
super.成员——调用父类的成员;
this.成员——调用子类的成员;
方法重写
子类出现了和父类中一模一样的方法声明,我们就称子类这个方法是重写的方法。(方法名+形参要一模一样);但要是已经继承过来的方法哦!当你有了之后,你再去重新搞一个一模一样的才叫重写。
@Override重写注解
继承后,子类构造器的特点
-
子类中所有的构造器默认都会先访问父类中无参构造器,再执行自己。
-
为什么?
子类在初始化的时候,有可能会使用到父类中的数据,如果父类没有完成初始化,子类将无法使用父类的数据。
子类初始化之前,一定要调用父类构造器先完成父类数据空间的初始化。
子类构造器的第一行语句默认都是:super( ),不写也存在。
当子类想要调用父类的有参构造器时,直接用super.(…)就行,作用是可以初始化继承过来的父类数据。
this 和super
this引用的是本类对象,super引用的是父类对象。代码中最好用this,super来明确标识。专业优雅!
包,权限修饰符
包:
就是import呗,很简单,但建立package的规则要是:公司域名倒写,全部小写。
导包注意:
- 相同包下的类可以直接访问,不同包下的类必须导包,才可以使用!导包格式:import 包名.类名;
- 假如一个类中需要用到不同类,而这个两个类的名称是一样的,那么默认只能导入一个类,另一个类要带包名访问。
权限修饰符
可以修饰成员变量,方法,构造器,内部类。
| 修饰符 | 同一 个类中 | 同一个包中其他类 | 不同包下的子类 | 不同包下的无关类 |
|---|---|---|---|---|
| private | √ | |||
| 缺省 | √ | √ | ||
| protected | √ | √ | √ | |
| public | √ | √ | √ | √ |
final关键字
- final 关键字是最终的意思,可以修饰(方法,变量,类)
- 修饰方法:表明该方法是最终方法,不能被重写。
- 修饰变量:表示该变量第一次赋值后,不能再次被赋值(有且仅能被赋值一次)。
- 修饰类:表明该类是最终类,不能被继承。
final修饰变量的注意
-
final修饰的变量是基本类型:那么变量存储的数据值不能发生改变。
-
final修饰的变量是引用类型:那么变量存储的地址值不能发生改变,但是地址指向的对象内容是可以发生变化的。
常量
-
public static final 修饰的成员变量,必须有初始值。
-
命名规范:英文单词全部大 public static final SCHOOL_NAME= ”西南交大“;
-
在编译阶段会进行“宏替换”,把使用常量的地方全部替换成真实的字面量。
-
用处:做信息标志和分类,但是虽然可以实现可读性,但是入参值不受约束,代码相对不够严谨,所以有了枚举类。
枚举
-
枚举是Java中的一种特殊类型
-
枚举的作用:“是为了做信息的标志和信息的分类”。
入参约束严谨,代码优雅,是最好的信息分类技术!建议使用!
定义枚举类的格式:
修饰符 enum 枚举名称{
第一行都是罗列枚举类实例的名称。
}
enum Season{
SPRING , SUMMER , AUTUMN , WINTER
}
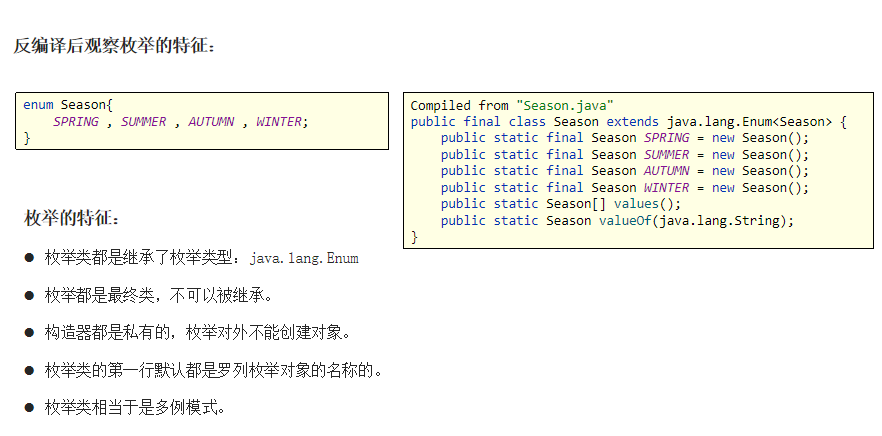
Example:
/**
做信息标志和分类
*/
public enum Orientation {
UP, DOWN, LEFT, RIGHT;
}
// 主类
public class EnumDemo2 {
public static void main(String[] args) {
// 1、创建一个窗口对象(桌子)
JFrame win = new JFrame();
// 2、创建一个面板对象(桌布)
JPanel panel = new JPanel();
// 3、把桌布垫在桌子上
win.add(panel);
// 4、创建四个按钮对象
JButton btn1 = new JButton("上");
JButton btn2 = new JButton("下");
JButton btn3 = new JButton("左");
JButton btn4 = new JButton("右");
// 5、把按钮对象添加到桌布上去
panel.add(btn1);
panel.add(btn2);
panel.add(btn3);
panel.add(btn4);
// 6、显示窗口
win.setLocationRelativeTo(null);
win.setSize(300,400);
win.setVisible(true);
btn1.addActionListener(new AbstractAction() {
@Override
public void actionPerformed(ActionEvent e) {
move(Orientation.UP) ; // 让玛丽往上跳
}
});
btn2.addActionListener(new AbstractAction() {
@Override
public void actionPerformed(ActionEvent e) {
move(Orientation.DOWN) ; // 让玛丽往下跳
}
});
btn3.addActionListener(new AbstractAction() {
@Override
public void actionPerformed(ActionEvent e) {
move(Orientation.LEFT) ; // 让玛丽往左跑
}
});
btn4.addActionListener(new AbstractAction() {
@Override
public void actionPerformed(ActionEvent e) {
move(Orientation.RIGHT) ; // 让玛丽往右跑
}
});
}
public static void move(Orientation o){
// 控制玛丽移动
switch (o) {
case UP:
System.out.println("玛丽往上飞了一下~~");
break;
case DOWN:
System.out.println("玛丽往下蹲一下~~");
break;
case LEFT:
System.out.println("玛丽往左跑~~");
break;
case RIGHT:
System.out.println("玛丽往→跑~~");
break;
}
}
}
抽象类()
在Java中abstract是抽象的意思,如果一个类中的某个方法的具体实现不能确定,就可以申明成abstract修饰的抽象方法(不能写方法体了,即后面不要再加上{ }了)这个类必须用abstract修饰,被称为抽象类。
注意:抽象类不能创建对象,他就是一个充当模板的作用!就是用来被继承的!!
只有抽象类和抽象方法哦,其他的东西不能被abstract修饰。
public abstract class Animal{
public abstract void run();
}
-
抽象类中不一定有抽象方法,有抽象方法的类一定是抽象类
-
一个类如果继承了抽象类,那么这个类必须重写完抽象类的全部抽象方法,否则这个类也必须定义成抽象类。
-
作用:就是用来被子类继承、充当模板的、同时也可以提高代码复用。在一定程度上约束了我这个类的子类必须要有哪几个方法!!!!
Example:

应用:模板方法
在抽象类里面,我们不仅定义了抽象方法,我们还定义模板方法!即我们将一个通用的功能写在里面,并且用final 修饰,子类都要用的。然后我们将模板方法中不能决定的功能定义成抽象方法,让具体子类去实现。
final修饰的原因:模板方法是给子类直接使用的,不是让子类重写的,一旦子类重写了模板方法就失效了。
public abstract class Animal{
public abstract void run();
// 模板方法
public final void login(){
........
}
}
接口(重要)
其实,接口就是抽象类进一步扩展出来的,定义了一个更加规范优雅的形式而已。
接口就和我们的排插插口一样,是一种规范!
定义:
格式:
public interface 接口名 {
// 常量 public static final
// 抽象方法。记住没有方法体哦 public abstract
}
- JDK8之前接口中只能是抽象方法和常量,没有其他成分了。
- 接口不能实例化。
- 接口中的成员都是public修饰的,写不写都是,因为规范的目的是为了公开化。
用法:多实现
接口是用来被类**实现(implements)的,实现接口的类称为实现类。**实现类可以理解成所谓的子类。
修饰符 class 实现类 implements 接口1, 接口2, 接口3 , ... {
.......
}
实现的关键字:implements
注意哦:前面说了接口是进化的抽象类,所以它依然带着抽象类的基本特征,一个类实现接口,必须重写所有的抽象方法。
继承关系:多继承
- 类和类的关系:单继承。
- 类和接口的关系:多实现。
- 接口和接口的关系:多继承,一个接口可以同时继承多个接口。
JDK8新增非抽象方法
- 默认方法
-
类似之前写的普通实例方法:必须用default修饰;
-
需要用接口的实现类的对象来调用
default void run(){ System.out.println("--开始跑--"); }
-
静态方法
默认会public修饰,必须static修饰。接口的静态方法必须用本身的接口名来调用.
static void inAddr(){ System.out.println("我们都在黑马培训中心快乐的学习Java!"); }
我们自己在开发中很少使用,通常是Java源码涉及到的,我们需要理解、识别语法、明白调用关系即可。
注意事项
1、接口不能创建对象
3、一个类继承了父类,同时又实现了接口,父类中和接口中有同名方法,默认用父类的
4、一个类实现了多个接口,多个接口中存在同名的默认方法,不冲突,这个类重写该方法即可。
5、一个接口继承多个接口,是没有问题的,如果多个接口中存在规范冲突则不能多继承。
多态
-
多态的定义:
同类型的对象,执行同一个行为,会表现出不同的行为特征。有点难理解啊!!!
-
注意:
多态这种情况只针对有继承/实现关系的。一定有方法重写。
并不是说,抽象类/接口创建对象了啊!!!这没有创建对象,new的是子类/实现类的对象啊,很容易出问题,千万注意了。
-
使用形式:将子类/实现类的对象地址 赋给父类/接口,来让父类/接口表现出不同的行为。
父类类型 对象名称 = new 子类构造器; 接口 对象名称 = new 实现类构造器; -
成员访问规则
成员方法:取子类/实现类里面的 重写的成员方法;
成员变量:只看父类/接口
其实很好理解,多态的目的就是想让一个类型的对象可以表现出不同的行为,它只注重行为撒,就是将子类或实现类的行为给父类罢了,但父类里面一定要有这个行为,不然你给谁呢,对吧
简单说就是这种情况:
public abstract class Animal{
public abstract void run();//注意无方法体哦
public int age = 5;
}
public class Dog extends Animal{
@Override
public void run(){
sout("我是狗跑的快")
}
public int age = 10;
}
Animal a = new Dog(); //将子类的对象赋给父类
a.run()
sout(a.age)
>>>>>>我是狗跑得快
>>>>>>5
好处:
- 在多态形式下,右边对象可以实现解耦合,便于扩展和维护。
Animal a = new Dog();
a.run(); // 后续业务行为随对象而变,后续代码无需修改
- 定义方法的时候,使用父类型作为参数,该方法就可以接收这父类的一切子类对象,体现出多态的扩展性与便利。
多态下会产生的一个问题:
- 多态下不能使用子类的独有功能
多态下引用数据类型的类型转换(一般不用)
**目的:**解决上面多态下不能使用子类的独有功能的问题。
引用数据类型的类型转换有两种:自动类型转换、强制类型转换。
自动类型转换(从子到父):子类对象赋值给父类类型的变量指向。
强制类型转换(从父到子):
// 自动类型转换
Animal a = new Dog();
a.run();
// a.lookDoor(); // 多态下无法调用子类独有功能
// 注意:多态下直接强制类型转换,可能出现类型转换异常
// Tortoise t1 = (Tortoise) a;
// 建议强制转换前,先判断变量指向对象的真实类型,再强制类型转换。
if(a instanceof Tortoise){
Tortoise t = (Tortoise) a;
t.layEggs();
}else if(a instanceof Dog){
Dog d1 = (Dog) a;
d1.lookDoor();
}
内部类
概述:内部类就是定义在一个类里面的类,作用有很多,例如说我一个汽车对象,汽车里面有发动机,我们就把发动机定义成一个类,放在里面等等。有几种类型,我们不用管,只要掌握匿名内部类就好了。
**局部内部类:放在方法、代码块、构造器等执行体{ }**中。
匿名内部类是局部内部类的一种形式。
匿名内部类
- 本质上是一个没有名字的局部内部类,定义在方法中、代码块中等执行体等。
- 作用:方便创建子类对象,最终目的为了简化代码编写。
- 在多态的基础,引出
Example: 说不清楚,看用法
public class Test {
public static void main(String[] args) {
// 抽象类是不能创建对象的哦,这个也不是创建抽象类对象哦,只是说java省略了中间创建一个子类的过程,因为我们只需要调用里面的方法嘛,创建一个子类有点多余
Animal a = new Animal(){
@Override
public void run() {
System.out.println("老虎跑的块~~~");
}
};
a.run();
}
}
这是一个内部类
//class Tiger extends Animal{
// @Override
// public void run() {
// System.out.println("老虎跑的块~~~");
// }
//}
// 定义一个抽象类(接口也可以)
interface Animal{
public abstract void run();
}
特点总结:
- 匿名内部类是一个没有名字的内部类。
- 匿名内部类写出来就会产生一个匿名内部类的对象。
- 匿名内部类的对象类型相当于是当前new的那个的类型的子类类型。
匿名内部类的使用形式(语法)
具体使用在后面,现在只是看看语法。
**例子:**某个学校需要让老师,学生,运动员一起参加游泳比赛
思路:1. 首先定义一个游泳接口,大家要都会游泳才能参加撒。
- 老师,学生,运动员为实现子类。(匿名内部类就是省略这一步)
- 定义游泳的函数(多态形式,可以传任意实现类对象)
interface Swimming{
void swim();
}
public class Test2 {
public static void go(Swimming s){
System.out.println("开始。。。");
s.swim();
System.out.println("结束。。。");
}
public static void main(String[] args) {
// 匿名内部类学习对象
Swimming s = new Swimming() {
@Override
public void swim() {
System.out.println("学生快乐的自由泳🏊");
}
};
go(s);
// 匿名内部类老师对象
go(new Swimming() {
@Override
public void swim() {
System.out.println("老师泳🏊的贼快~~~~~");
}
});
}
常用API
Object类(所有类的爸爸)
下面Object提供的方法的原因就在于,让子类去重写,本身没有什么意义!
快捷键 Ctrl + O,展示出Object中可以重写的方法!!!
| 方法名 | 说明 |
|---|---|
| public String toString() | 默认是返回当前对象在堆内存中的地址信息: 类的全限名@内存地址 |
| public boolean equals(Object o) | 默认是比较当前对象与另一个对象的地址是否相同,相同返回true,不同返回false |
toString()
直接输出任何引用类型的变量,都会自动调用其toString()方法。
public static void main(String[] args) {
Student s = new Student("周雄", '男', 19);
// String rs = s.toString();
// System.out.println(rs);
System.out.println(s.toString());
// 直接输出对象变量,默认可以省略toString调用不写的
System.out.println(s);
}
>>>>>
com.itheima.d9_api_object.Student@1b6d3586
可见,原本的toString()方法并没有什么卵用,因为我们不需要得到它的地址啊,相比我们开发者希望看到的是对象的内容数据而不是对象的地址信息。
所以我们在子类里面对该方法进行重写。Alt + Insert
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", sex=" + sex +
", age=" + age +
'}';
}
equals()
原方法很垃圾啊,要比较地址我们完全可以用 “ == ”就可以了啊,搞这么复杂。所以说我们开发中,希望比较的是两个对象的成员内容是否相同!!
在子类里面我们对该方法重写。用到了多态和引用类型强转哦 Alt + Insert
但是,我们一般不用这个!!!
原因在于假如s1为null的话,就报错:空指针异常。s1.equals(s2)这个是字符串对象调用里面的equals方法,但是如果s1是null呢,也就是s1不是对象,那他就没有对应的equals方法啊,这个空指针异常的问题经常出现,原因是程序员的技术不行。
@Override
public boolean equals(Object o) {
// 1、判断是否是同一个对象比较,如果是返回true。
if (this == o) return true;
// 2、如果o是null返回false 如果o不是学生类型返回false ...Student != ..Pig
if (o == null || this.getClass() != o.getClass()) return false;
// 3、说明o一定是学生类型而且不为null
Student student = (Student) o;
return this.sex == student.sex && this.age == student.age && Objects.equals(this.name, student.name);
}
HashCode()
返回对象地址对应的哈希值,就没了,没有什么用,需要重写,因为我们想要对象内容对应的哈希值才行。主要用于Set集合体系
Objects类
Objects 类是 final 修饰的类,不可继承,内部方法都是 static 方法,从 jdk1.7 开始才引入了 Objects 类。
这个类与Object还是继承关系。
| 方法名 | 说明 |
|---|---|
| public static boolean equals(Object a, Object b) | 比较两个对象的,底层会先进行非空判断,从而可以避免空指针异常。再进行equals比较 |
| public static boolean isNull(Object obj) | 判断变量是否为null ,为null返回true ,反之 |
equals(s1,s2)
这个方法安全性最高!!!!
因为它验证了s1\s2是否为NUll,做了非空校验。报错:空指针异常,s1.equals(s2)这个是字符串对象调用里面的equals方法,但是如果s1是null呢,也就是s1不是对象,那他就没有对应的equals方法啊,这个空指针异常的问题经常出现,原因是程序员的技术不行。
所以说我们看到官方重写的equals()方法里面用到了这个!
StringBuilder类
StringBuilder是一个可变的字符串类,我们可以把它看成是一个对象容器。
- 作用:提高字符串的操作效率,如拼接、修改等。
- 原因:因为String是不可变字符串,所以我们在使用它的时候,很不方便,在内存中创建的对象无法消除,=所以加入了这个类,我们建立这个类的对象StringBuilder先代替String,在完成拼接,修改等等之后,再把最终结果转成String,这样就不会浪费内存
构造器:
| 名称 | 说明 |
|---|---|
| public StringBuilder() | 创建一个空白的可变的字符串对象,不包含任何内容 |
| public StringBuilder(String str) | 创建一个指定字符串内容的可变字符串对象 |
常用方法:
| 方法名称 | 说明 |
|---|---|
| public StringBuilder append(String类型) | 添加数据并返回StringBuilder对象本身 |
| public StringBuilder reverse() | 将对象的内容反转 |
| public int length() | 返回对象内容长度 |
| public String toString() | 通过toString()就可以实现把StringBuilder转换为String |
public class Test {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder();
sb.append("a");
sb.append("b");
sb.append("c");
System.out.println(sb);
String result = sb.toString();
}
}
System类
System也是一个工具类,代表了当前系统,提供了一些与系统相关的方法。
| 方法名 | 说明 |
|---|---|
| public static void exit(int status) | 终止当前运行的 Java 虚拟机,非零表示异常终止 |
| public static long currentTimeMillis ( ) | 返回当前系统的时间毫秒值形式 |
| public static void arraycopy(数据源数组, 起始索引, 目的地数组, 起始索引, 拷贝个数) | 数组拷贝 |
BigDecimal类
大数据对象 用于解决浮点型运算精度失真的问题

// 包装浮点型数据成为大数据对象 BigDeciaml(固定写法)
BigDecimal a1 = BigDecimal.valueOf(0.5)
//然后我们再调用这个对象的 加减乘除 方法进行运算
| 方法名 | 说明 |
|---|---|
| public BigDecimal add(BigDecimal b) | 加法 |
| public BigDecimal subtract(BigDecimal b) | 减法 |
| public BigDecimal multiply(BigDecimal b) | 乘法 |
| public BigDecimal divide(BigDecimal b) | 除法 |
| public BigDecimal divide (另一个BigDecimal对象,精确几位,舍入模式) | 除法 |
日期与时间
Date类(日期对象)
需要时间毫秒值的原因:日期对象无法进行运行!!!求出现在往后24小时后的时间,就只能通过时间毫秒值做。
构造器:
| 名称 | 说明 |
|---|---|
| public Date() | 创建一个Date对象,存储的是系统当前此刻日期时间。 |
| public Date(long time) | 把时间毫秒值转换成Date日期对象。 |
Date的常用方法:
| 名称 | 说明 |
|---|---|
| public long getTime() | 返回从1970年1月1日 00:00:00走到此刻的总的毫秒数 |
| public void setTime(long time) | 设置日期对象的时间为当前时间毫秒值对应的时间 |
控制台输出:
-
Date对象:Thu Dec 30 14:55:35 CST 2021
-
时间毫秒值:1640847335012
这谁看的懂啊,所以用下面这个
SimpleDateFormat类
可以去完成日期时间的格式化操作。
通过调用该类的final方法,将Date对象或者时间毫秒值转换成指定格式的字符串。
- 将日期对象和时间毫秒值转换成自定义格式的字符串
| 构造器 | 说明 |
|---|---|
| public SimpleDateFormat(String pattern) | 构造一个SimpleDateFormat,使用指定的格式 |
| 格式化方法 | 说明 |
|---|---|
| public final String format(Date date) | 将日期格式化成日期/时间字符串 |
| public final String format(Object time) | 将时间毫秒值式化成日期/时间字符串 |

// 1、日期对象
Date d = new Date();
System.out.println(d);
// 2、创建simpledateformat对象 (指定最终格式化的形式)
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss EEE a");
// 3、开始格式化日期对象成为喜欢的字符串形式
String rs = sdf.format(d);
System.out.println(rs);
-
解析字符串时间成为日期对象。
因为计算机只能读取Date对象或者时间毫秒值,才能进行运算。
解析方法 说明 public Date parse(String source) 从给定字符串的开始解析文本以生成日期
//注意格式化类的时间设置格式要入输入的一模一样哦,但java还是会报错,直接抛出去就好了
String dateStr = "2021年08月06日 11:11:11";
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
// 调用方法
Date d = sdf.parse(dateStr);
// 往后走2天 14小时 49分 06秒
long time = d.getTime() + (2L*24*60*60 + 14*60*60 + 49*60 + 6) * 1000;
System.out.println(sdf.format(time));
Calendar类
- Calendar代表了系统此刻日期对应的日历对象。
- Calendar是一个抽象类,不能直接创建对象。
Calendar日历类创建日历对象的方法:
| 方法名 | 说明 |
|---|---|
| public static Calendar getInstance( ) | 获取当前日历对象 |
然后现在得到的对象,打印出来是一个很长的看不懂的,所以我们要用他的方法取出我们需要的数据。
| 方法名 | 说明 |
|---|---|
| public int get(int field) | 取日期中的某个字段信息。 |
| public void set(int field,int value) | 修改日历的某个字段信息。 |
| public void add(int field,int amount) | 为某个字段增加/减少指定的值 |
| public final Date getTime() | 拿到此刻日期对象。 |
| public long getTimeInMillis() | 拿到此刻时间毫秒值 |
注意:calendar是可变日期对象,一旦修改后其对象本身表示的时间将产生变化。
Example:
// 1、拿到系统此刻日历对象
Calendar cal = Calendar.getInstance();
System.out.println(cal);
// 2、获取日历的信息:public int get(int field):取日期中的某个字段信息。
int year = cal.get(Calendar.YEAR);
System.out.println(year);
int mm = cal.get(Calendar.MONTH) + 1;
System.out.println(mm);
int days = cal.get(Calendar.DAY_OF_YEAR) ;
System.out.println(days);
JDK8新增日期类
从Java 8开始,java.time包提供了新的日期和时间API,主要涉及的类型有:
- **LocalDate:**本地日期对象。
- **LocalTime:**本地时间对象。
- LocalDateTime:本地日期时间对象,包含了日期及时间。
- **Instant:**代表的是时间戳对象(具体的年月日时分秒)。
- DateTimeFormatter: 用于做最上面三种时间对象的格式化和解析。
- Duration: 用于计算两个 “时间 ”间隔 。
- Period: 用于计算两个 “日期” 间隔。
注意区分: Java中的日期指的是:“年月日”;时间指的是:“时分秒”。
==特点:==新API的类型几乎全部是不变类型(和String的使用类似),可以放心使用不必担心被修改。
本地三种时间对象
LocalDate、LocalTime、LocalDateTime
他们三者构建对象和API都是通用的,并且存在下面转化关系:

LocalDateTime的转换API:
| 方法名 | 说明 |
|---|---|
| public LocalDate toLocalDate( ) | 转换成一个LocalDate对象 |
| public LocalTime toLocalTime( ) | 转换成一个LocalTime对象 |
修改相关的API
LocalDateTime 综合了 LocalDate 和 LocalTime 里面的方法,所以下面只用 LocalDate 和 LocalTime 来举例,可以向当前时间对象,添加几天,减少几天,修改年月日,比较两个时间对象等。
这些方法返回的是一个新的实例引用,因为LocalDateTime 、LocalDate 、LocalTime 都是不可变的。
详细使用看下面代码
LocalDate:
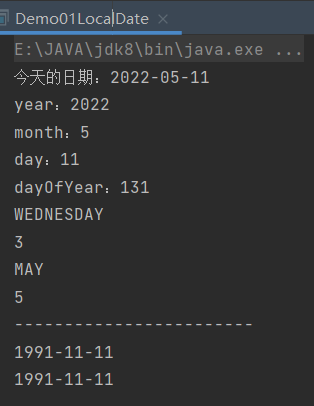
public class Demo01LocalDate {
public static void main(String[] args) {
// 1、获取本地日期对象。(年-月-日)
LocalDate nowDate = LocalDate.now();
System.out.println("今天的日期:" + nowDate);//今天的日期:
int year = nowDate.getYear();
System.out.println("year:" + year);
int month = nowDate.getMonthValue();
System.out.println("month:" + month);
int day = nowDate.getDayOfMonth();
System.out.println("day:" + day);
//当年的第几天
int dayOfYear = nowDate.getDayOfYear();
System.out.println("dayOfYear:" + dayOfYear);
//星期
System.out.println(nowDate.getDayOfWeek());
System.out.println(nowDate.getDayOfWeek().getValue());
//月份
System.out.println(nowDate.getMonth());//AUGUST
System.out.println(nowDate.getMonth().getValue());//8
System.out.println("------------------------");
LocalDate bt = LocalDate.of(1991, 11, 11);
System.out.println(bt);//直接传入对应的年月日
System.out.println(LocalDate.of(1991, Month.NOVEMBER, 11));//相对上面只是把月换成了枚举
}
}
LocalTime:
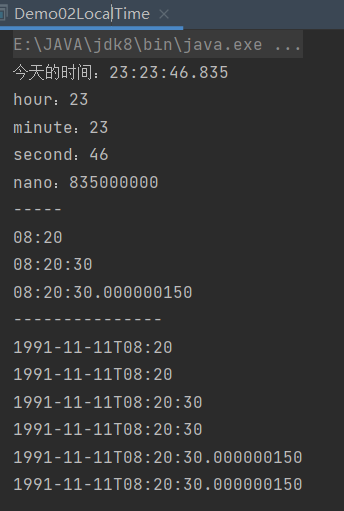
public class Demo02LocalTime {
public static void main(String[] args) {
// 1、获取本地时间对象。(时分秒)
LocalTime nowTime = LocalTime.now();
System.out.println("今天的时间:" + nowTime);//今天的时间:
int hour = nowTime.getHour();//时
System.out.println("hour:" + hour);//hour:
int minute = nowTime.getMinute();//分
System.out.println("minute:" + minute);//minute:
int second = nowTime.getSecond();//秒
System.out.println("second:" + second);//second:
int nano = nowTime.getNano();//纳秒
System.out.println("nano:" + nano);//nano:
System.out.println("-----");
System.out.println(LocalTime.of(8, 20));//时分
System.out.println(LocalTime.of(8, 20, 30));//时分秒
System.out.println(LocalTime.of(8, 20, 30, 150));//时分秒纳秒
LocalTime mTime = LocalTime.of(8, 20, 30, 150);
System.out.println("---------------");
System.out.println(LocalDateTime.of(1991, 11, 11, 8, 20));
System.out.println(LocalDateTime.of(1991, Month.NOVEMBER, 11, 8, 20));
System.out.println(LocalDateTime.of(1991, 11, 11, 8, 20, 30));
System.out.println(LocalDateTime.of(1991, Month.NOVEMBER, 11, 8, 20, 30));
System.out.println(LocalDateTime.of(1991, 11, 11, 8, 20, 30, 150));
System.out.println(LocalDateTime.of(1991, Month.NOVEMBER, 11, 8, 20, 30, 150));
}
}
LocalDateTime:
public class Demo03LocalDateTime {
public static void main(String[] args) {
// 日期 时间
LocalDateTime nowDateTime = LocalDateTime.now();
System.out.println("今天是:" + nowDateTime);//今天是:
System.out.println(nowDateTime.getYear());//年
System.out.println(nowDateTime.getMonthValue());//月
System.out.println(nowDateTime.getDayOfMonth());//日
System.out.println(nowDateTime.getHour());//时
System.out.println(nowDateTime.getMinute());//分
System.out.println(nowDateTime.getSecond());//秒
System.out.println(nowDateTime.getNano());//纳秒
//日:当年的第几天
System.out.println("dayOfYear:" + nowDateTime.getDayOfYear());//dayOfYear:249
//星期
System.out.println(nowDateTime.getDayOfWeek());//THURSDAY
System.out.println(nowDateTime.getDayOfWeek().getValue());//4
//月份
System.out.println(nowDateTime.getMonth());//SEPTEMBER
System.out.println(nowDateTime.getMonth().getValue());//9
LocalDate ld = nowDateTime.toLocalDate();
System.out.println(ld);
LocalTime lt = nowDateTime.toLocalTime();
System.out.println(lt.getHour());
System.out.println(lt.getMinute());
System.out.println(lt.getSecond());
}
}
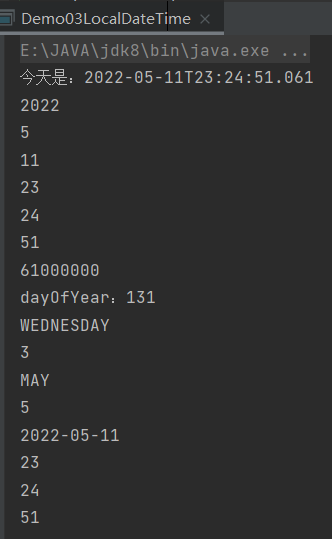
UpdateTime:
public class Demo04UpdateTime {
public static void main(String[] args) {
LocalTime nowTime = LocalTime.now();
System.out.println(nowTime);//当前时间
System.out.println(nowTime.minusHours(1));//一小时前
System.out.println(nowTime.minusMinutes(1));//一分钟前
System.out.println(nowTime.minusSeconds(1));//一秒前
System.out.println(nowTime.minusNanos(1));//一纳秒前
System.out.println("----------------");
System.out.println(nowTime.plusHours(1));//一小时后
System.out.println(nowTime.plusMinutes(1));//一分钟后
System.out.println(nowTime.plusSeconds(1));//一秒后
System.out.println(nowTime.plusNanos(1));//一纳秒后
System.out.println("------------------");
// 不可变对象,每次修改产生新对象!
System.out.println(nowTime);
System.out.println("---------------");
LocalDate myDate = LocalDate.of(2018, 9, 5);
LocalDate nowDate = LocalDate.now();
System.out.println("今天是2018-09-06吗? " + nowDate.equals(myDate));//今天是2018-09-06吗? false
System.out.println(myDate + "是否在" + nowDate + "之前? " + myDate.isBefore(nowDate));//2018-09-05是否在2018-09-06之前? true
System.out.println(myDate + "是否在" + nowDate + "之后? " + myDate.isAfter(nowDate));//2018-09-05是否在2018-09-06之后? false
System.out.println("---------------------------");
// 判断今天是否是你的生日
LocalDate birDate = LocalDate.of(1996, 8, 5);
LocalDate nowDate1 = LocalDate.now();
// MonthDay: 月日对象(几月几日)
MonthDay birMd = MonthDay.of(birDate.getMonthValue(), birDate.getDayOfMonth());
MonthDay nowMd = MonthDay.from(nowDate1);
System.out.println("今天是你的生日吗? " + birMd.equals(nowMd));//今天是你的生日吗? false
}
}
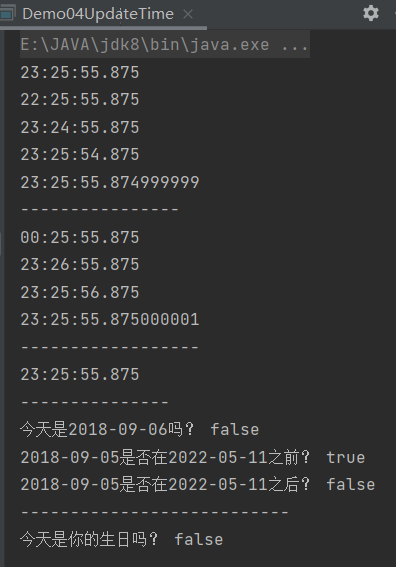
Instant
时间戳对象。包含时间与日期,指的是具体的某一时刻(年月日时分秒)。与java.util.Date很类似,事实上Instant就是类似JDK8 以前的Date。并且Instant和Date这两个类可以进行转换。
public class Demo05Instant {
public static void main(String[] args) {
// 1、得到一个Instant时间戳对象
// 这个获取的是世界标准时间
Instant instant = Instant.now();
System.out.println(instant);
// 2、系统此刻的时间戳怎么办?
// 目前所在地区的时间戳
Instant instant1 = Instant.now();
System.out.println(instant1.atZone(ZoneId.systemDefault()));
// 3、如何去返回Date对象
Date date = Date.from(instant);
System.out.println(date);
Instant i2 = date.toInstant();
System.out.println(i2);
}
}
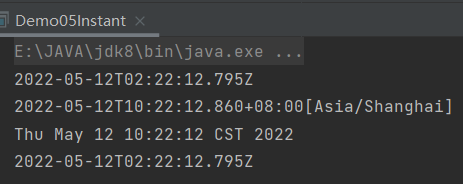
DateTimeFormatter
在JDK8中,引入了一个全新的日期与时间格式器DateTimeFormatter。超级好用。三种本地时间对象都可以解析。
public class Demo06DateTimeFormat {
public static void main(String[] args) {
// 本地此刻 日期时间对象
LocalDateTime ldt = LocalDateTime.now();
System.out.println(ldt);
// 解析/格式化器
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss EEE a");
// 正向格式化
System.out.println(dtf.format(ldt));
// 逆向格式化
System.out.println(ldt.format(dtf));
// 解析字符串时间
DateTimeFormatter dtf1 = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// 解析当前字符串时间成为本地日期时间对象
LocalDateTime ldt1 = LocalDateTime.parse("2019-11-11 11:11:11" , dtf1);
System.out.println(ldt1);
System.out.println(ldt1.getDayOfYear());
}
}
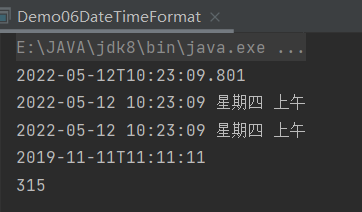
Period
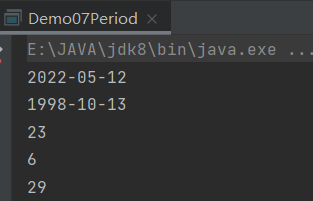
计算两个本地日期对象的日期间隔,是一个日期间隔对象。只能用于 LocalDate 之间的比较。
public class Demo07Period {
public static void main(String[] args) {
// 当前本地 年月日
LocalDate today = LocalDate.now();
System.out.println(today);//
// 生日的 年月日
LocalDate birthDate = LocalDate.of(1998, 10, 13);
System.out.println(birthDate);
Period period = Period.between(birthDate, today);//第二个参数减第一个参数
System.out.println(period.getYears());
System.out.println(period.getMonths());
System.out.println(period.getDays());
}
}
Duration
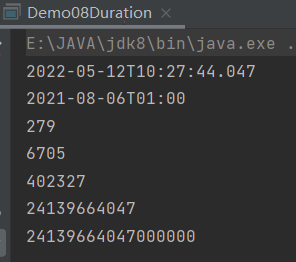
计算两个本地时间对象的时间间隔,是一个时间间隔对象。可以用于 LocalDateTime 和 Instant 之间的比较。
public class Demo08Duration {
public static void main(String[] args) {
// 本地日期时间对象。
LocalDateTime today = LocalDateTime.now();
System.out.println(today);
// 出生的日期时间对象
LocalDateTime birthDate = LocalDateTime.of(2021,8
,06,01,00,00);
System.out.println(birthDate);
Duration duration = Duration.between( today , birthDate);//第二个参数减第一个参数
System.out.println(duration.toDays());//两个时间差的天数
System.out.println(duration.toHours());//两个时间差的小时数
System.out.println(duration.toMinutes());//两个时间差的分钟数
System.out.println(duration.toMillis());//两个时间差的毫秒数
System.out.println(duration.toNanos());//两个时间差的纳秒数
}
}
ChronoUnit
ChronoUnit类可用于在单个时间单位内测量一段时间,这个工具类是最全的了,可以用于比较所有的时间单位
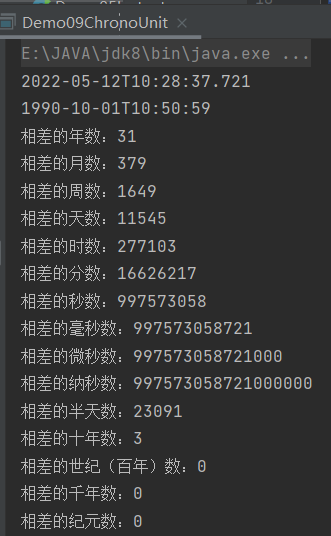
public class Demo09ChronoUnit {
public static void main(String[] args) {
// 本地日期时间对象:此刻的
LocalDateTime today = LocalDateTime.now();
System.out.println(today);
// 生日时间
LocalDateTime birthDate = LocalDateTime.of(1990,10,1,
10,50,59);
System.out.println(birthDate);
System.out.println("相差的年数:" + ChronoUnit.YEARS.between(birthDate, today));
System.out.println("相差的月数:" + ChronoUnit.MONTHS.between(birthDate, today));
System.out.println("相差的周数:" + ChronoUnit.WEEKS.between(birthDate, today));
System.out.println("相差的天数:" + ChronoUnit.DAYS.between(birthDate, today));
System.out.println("相差的时数:" + ChronoUnit.HOURS.between(birthDate, today));
System.out.println("相差的分数:" + ChronoUnit.MINUTES.between(birthDate, today));
System.out.println("相差的秒数:" + ChronoUnit.SECONDS.between(birthDate, today));
System.out.println("相差的毫秒数:" + ChronoUnit.MILLIS.between(birthDate, today));
System.out.println("相差的微秒数:" + ChronoUnit.MICROS.between(birthDate, today));
System.out.println("相差的纳秒数:" + ChronoUnit.NANOS.between(birthDate, today));
System.out.println("相差的半天数:" + ChronoUnit.HALF_DAYS.between(birthDate, today));
System.out.println("相差的十年数:" + ChronoUnit.DECADES.between(birthDate, today));
System.out.println("相差的世纪(百年)数:" + ChronoUnit.CENTURIES.between(birthDate, today));
System.out.println("相差的千年数:" + ChronoUnit.MILLENNIA.between(birthDate, today));
System.out.println("相差的纪元数:" + ChronoUnit.ERAS.between(birthDate, today));
}
}
其他一些操作
import java.time.*;
import java.time.format.DateTimeFormatter;
import java.time.temporal.ChronoUnit;
import java.time.temporal.TemporalAdjusters;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* 操作时间工具类
*
* @author LiSanWei
*/
public class DataTimeUtils {
public static final DateTimeFormatter FORMATTER_FULL = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss").withZone(ZoneId.of("+8"));
public static final DateTimeFormatter DATE_STR = DateTimeFormatter.ofPattern("yyyy-MM-dd").withZone(ZoneId.of("+8"));
public static void main(String[] args) {
// 1. java8获取当前时间
LocalDateTime now = LocalDateTime.now();
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss").withZone(ZoneId.of("+8"));
// 2.将获取当前时间转化成特定格式
System.out.println("dateTimeFormatter = " + now.format(dateTimeFormatter));
// 3.字符串转成特定时间
String strDateTime = "2016-04-04 11:50:53";
LocalDateTime parse = LocalDateTime.parse(strDateTime, dateTimeFormatter);
// 4.一天的开始/一天的结束
LocalDateTime start = LocalDateTime.of(LocalDate.now(), LocalTime.MIN);
LocalDateTime end = LocalDateTime.of(LocalDate.now(), LocalTime.MAX);
String startDay = start.format(dateTimeFormatter);
String endDay = end.format(dateTimeFormatter);
System.out.println("startDay = " + startDay + "endDay = " + endDay);
// 5.获取当前月的第一天
LocalDate currentMonthFirstDay = LocalDate.now().minusMonths(0).with(TemporalAdjusters.firstDayOfMonth());
System.out.println("with = " + currentMonthFirstDay);
// 6.获取周几
DayOfWeek dayOfWeek = currentMonthFirstDay.getDayOfWeek();
System.out.println("dayOfWeek = " + dayOfWeek);
int value = dayOfWeek.getValue();
System.out.println("value = " + value);
// 7.获取一个月多少 //当月的天数
int i = LocalDate.now().lengthOfMonth();
// 8.获取当前月的最后一天
LocalDate currentMonthEndDay = LocalDate.now().minusMonths(0).with(TemporalAdjusters.lastDayOfMonth());
System.out.println("withEnd = " + currentMonthEndDay);
// 9.一个月之前,一个月之后
LocalDate currentNow = LocalDate.now();
LocalDate minus = currentNow.minus(1, ChronoUnit.MONTHS);
LocalDate plus = currentNow.plus(1, ChronoUnit.MONTHS);
System.out.println("with = " + minus + plus);
// 10.获取几天/几天后的日期
LocalDate minus1 = currentNow.minus(1, ChronoUnit.DAYS);
LocalDate plus1 = currentNow.plus(1, ChronoUnit.DAYS);
System.out.println("minus1 = " + minus1);
System.out.println("plus1 = " + plus1);
// 11.java8指定年月日
LocalDate of = LocalDate.of(2021, 11, 18);
System.out.println("of = " + of);
}
/**
* 将字符串 转成 LocalDateTime 示例:"2016-04-04 11:50:53"
*
* @param dateTime 时间
* @return LocalDateTime
*/
public static LocalDateTime strTimeToLocalDateTime(String dateTime) {
return LocalDateTime.parse(dateTime, FORMATTER_FULL);
}
/**
* date 转成 LocalDateTime
*
* @param date 日期
*/
public static LocalDateTime dateToLocalDateTime(Date date) {
Instant instant = date.toInstant();
ZoneId zone = ZoneId.systemDefault();
return LocalDateTime.ofInstant(instant, zone);
}
/**
* date 转成 LocalDate
*
* @param date 日期
*/
public static LocalDate dateToLocalDate(Date date) {
Instant instant = date.toInstant();
ZoneId zone = ZoneId.systemDefault();
LocalDateTime localDateTime = LocalDateTime.ofInstant(instant, zone);
return localDateTime.toLocalDate();
}
/**
* date 转成 LocalTime
*
* @param date 日期
*/
public static LocalTime dateToLocalTime(Date date) {
Instant instant = date.toInstant();
ZoneId zone = ZoneId.systemDefault();
LocalDateTime localDateTime = LocalDateTime.ofInstant(instant, zone);
return localDateTime.toLocalTime();
}
/**
* LocalDateTime 转成 Date
*
* @param localDateTime 时间
* @return 结果集
*/
public static Date localDateTimeToDate(LocalDateTime localDateTime) {
ZoneId zone = ZoneId.systemDefault();
Instant instant = localDateTime.atZone(zone).toInstant();
return Date.from(instant);
}
/**
* localDate 转成 Date
*
* @param localDate 结果集
*/
public static Date localDateToDate(LocalDate localDate) {
ZoneId zone = ZoneId.systemDefault();
Instant instant = localDate.atStartOfDay().atZone(zone).toInstant();
return Date.from(instant);
}
/**
* LocalTime 转成 Date
*
* @param localTime 本地时间
* @param localDate 时间
*/
public static Date localTimeToDate(LocalTime localTime, LocalDate localDate) {
LocalDateTime localDateTime = LocalDateTime.of(localDate, localTime);
ZoneId zone = ZoneId.systemDefault();
Instant instant = localDateTime.atZone(zone).toInstant();
return Date.from(instant);
}
/**
* 获取前一个月的第一天的时间
*
* @return 几号
*/
public Integer getLastMonthEndDay() {
LocalDate with = LocalDate.now().plusMonths(-1).with(TemporalAdjusters.firstDayOfMonth());
return with.with(TemporalAdjusters.lastDayOfMonth()).getDayOfMonth();
}
/**
* 获取后一个月的第一天的时间
*
* @return 几号
*/
public static Integer getNextMonthEndDay() {
LocalDate with = LocalDate.now().plusMonths(1).with(TemporalAdjusters.firstDayOfMonth());
return with.with(TemporalAdjusters.lastDayOfMonth()).getDayOfMonth();
}
/**
* 获取日历表
*
* @param index -1表示上月 0表示当月 1表示下月
* @return 结果集
*/
public static List<DataCalendarDTO> getCalendarTable(Integer index) {
// 根据输入确定月份
LocalDate months = LocalDate.now().plusMonths(index);
// 获取当前月的第一天
LocalDate currentMonthFirstDay = months.with(TemporalAdjusters.firstDayOfMonth());
// 获取当前月的最后一天
LocalDate currentMonthEndDay = months.with(TemporalAdjusters.lastDayOfMonth());
// 获取一个月多少 //当月的天数
int days = LocalDate.now().lengthOfMonth();
// 获取周几
int dayOfWeek = currentMonthFirstDay.getDayOfWeek().getValue();
// 获取日历第一天
LocalDate calendarFirstDay = months.minus(dayOfWeek - 1, ChronoUnit.DAYS);
// 获取日历最后一天
LocalDate calendarEndDay = currentMonthEndDay.plus(42 - days - (dayOfWeek - 1), ChronoUnit.DAYS);
List<DataCalendarDTO> localDateList = new ArrayList<>();
long length = calendarEndDay.toEpochDay() - calendarFirstDay.toEpochDay();
DataCalendarDTO dataCalendarDTO;
for (long i = length; i >= 0; i--) {
dataCalendarDTO = new DataCalendarDTO();
// 当前日期
LocalDate localDate = calendarEndDay.minusDays(i);
dataCalendarDTO.setDate(localDate.format(DATE_STR));
// 周几
dataCalendarDTO.setWeek(localDate.getDayOfWeek().getValue());
localDateList.add(dataCalendarDTO);
}
return localDateList;
}
/**
* @param begin 开始日期
* @param end 结束日期
* @return 开始与结束之间的所以日期,包括起止
*/
public static List<LocalDate> getMiddleAllDate(LocalDate begin, LocalDate end) {
List<LocalDate> localDateList = new ArrayList<>();
long length = end.toEpochDay() - begin.toEpochDay();
for (long i = length; i >= 0; i--) {
localDateList.add(end.minusDays(i));
}
return localDateList;
}
/**
* 获取前几天或者后几天的时间
*
* @param offSet 负数代表前几天
* @param timeFormat 时间格式化类型
* @return 格式化后的结果
*/
public static String getYesterdayByFormat(Integer offSet, String timeFormat) {
return LocalDateTime.now().plusDays(offSet).format(DateTimeFormatter.ofPattern(timeFormat));
}
}
包装类
其实就是8种基本数据类型对应的引用类型!!!因为很多地方都无法使用基本数据类型。
| 基本数据类型 | 引用数据类型 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| char | Character |
| float | Float |
| double | Double |
| boolean | Boolean |
- Java为了实现一切皆对象,为8种基本类型提供了对应的引用类型。
- 后面的集合和泛型其实也只能支持包装类型,不支持基本数据类型。
为了方便,java提供了很便利的东西,**基本类型的数据变量与引用类型的变量可以直接相互赋值,**如下:
int a = 10;
Integer a1 = 20;
//
int b = a1;
Integer b1 = a;
包装类的特有功能:
-
包装类的变量的默认值可以是null,容错率更高。
-
可以把字符串类型的数值转换成真实的数据类型(真的很有用),就是下面两个静态方法,一个Integer的一个Double的
Integer: public static int parseInt( “字符串类型的整数” )
Double: public static double parseDouble( “字符串类型的小数” )。
String number = "23";
//转换成整数
int age = Integer.parseInt(number);
String number1 = "99.9";
//转换成小数
double score = Double.parseDouble(number1);
包装类的重要API
| 方法 | 说明 |
|---|---|
| public static 包装类 valueOf( ) | 基本所有的包装类都有这个API,可以把例如字符串转换成返回的包装类的类型 |
//Example
integer id = Integer.valueOf("1106");
//等价于== new Integer(Integer.parseInt(s))
String flag = String.valueOf(true);
正则表达式regex
提供的匹配规则,必须一模一样,不能改!!!
**注意:**java对反斜杠特别特别敏感,\ ,也叫转义字符。特别是我们在使用正则表达式的时候,假如我们直接在正则表达式里面写"\d",则无法识别,他会把\d看出是一个整体,懂吧。解决办法就是,**在前面再加一个\,**用来告诉java,我这个\后面的\就是一个\,不是什么其他的。
qqnumber.matches("\d") //不识别\d
qqnumber.matches("\\d") // OK
"123.abc".matches("\\d{3,10}.[a-z]") //错误,这里的.被当成了任意字符
"123.abc".matches("\\d{3,10}\\.[a-z]")
-
字符类(默认匹配一个字符)
[abc] 只能是a, b, 或c [^abc] 除了a, b, c之外的任何字符 [a-zA-Z] a到z A到Z,包括(范围) [a-d[m-p]] a到d,或m通过p:([a-dm-p]联合) [a-z&&[def]] d, e, 或f(交集) [a-z&&[^bc]] a到z,除了b和c:([ad-z]减法) [a-z&&[^m-p]] a到z,除了m到p:([a-lq-z]减法) [0-9] 0-9 1[3-9]\d{9} 首位为1,第二位3-9,后面9位随便 -
预定义的字符类(默认匹配一个字符)(为了便利,给我们提供的,不然按照上面写死)
. 任何字符(\\.) \d 一个数字: [0-9] \D 非数字: [^0-9] \s 一个空白字符: [ \t\n\x0B\f\r] \S 非空白字符: [^\s] \w [a-zA-Z_0-9] 数字、字母、下划线 \W [^\w] 一个非单词字符 -
贪婪的量词(配合匹配多个字符)
X? X , 一次或根本不 X* X,零次或多次 X+ X , 一次或多次 X {n} X,正好n次 X {n, } X,至少n次 X {n,m} X,至少n但不超过m次
字符串对象
字符串对象提供了匹配正则表达式的方法。
String类的方法:
public boolean matches (String regex)
:判断是否匹配正则表达式,匹配返回true,不匹配返回false。
Example:
// 判断输入的字符串是否为数字,且6-20位
String qq = "12233434";
String ww = "sasasa1212";
System.out.println(qq.matches("\\d{6, 20}"));
System.out.println(qq.matches("\\d{6, }")); //至少6位
// 只能是 a b c
System.out.println("z".matches("[abc]")); // false
// 不能出现a b c
System.out.println("z".matches("[^abc]")); // true
System.out.println("a".matches("\\d")); // false
System.out.println("333".matches("\\d")); // false
System.out.println("z".matches("\\w")); // true
System.out.println("2".matches("\\w")); // true
System.out.println("21".matches("\\w")); // false
System.out.println("你".matches("\\w")); //false
System.out.println("你".matches("\\W")); // true
System.out.println("---------------------------------");
// 以上正则匹配只能校验单个字符。
// 校验密码
// 必须是数字 字母 下划线 至少 6位
System.out.println("2442fsfsf".matches("\\w{6,}"));
System.out.println("244f".matches("\\w{6,}"));
// 验证码 必须是数字和字符 必须是4位
System.out.println("23dF".matches("[a-zA-Z0-9]{4}"));
System.out.println("23_F".matches("[a-zA-Z0-9]{4}"));
System.out.println("23dF".matches("[\\w&&[^_]]{4}"));
System.out.println("23_F".matches("[\\w&&[^_]]{4}"));
// 校验手机号。首位为1,第二位3-9,后面9位随便
phone.matches("1[3-9]\\d{9}")
// 校验邮箱格式
// 3268847dsda878@163.com
// 3268847dsda878@pci.com.cn
email.matches("\\w{1,30}@[a-zA-Z0-9]{2,20}(\\.[a-zA-Z0-9]{2,20}){1,2}")
// 判断座机号码格式是否正确 027-3572457 0273572457
tel.matches("0\\d{2,6}-?\\d{5,20}")
正则表达式在字符串方法中的使用:
| 方法名 | 说明 |
|---|---|
| public String replaceAll(String regex, String newStr) | 对正则表达式匹配到的内容进行替换 |
| public String[ ] split(String regex) | 将正则表达式匹配到的内容作为分割字符串,反回一个字符串数组。 |
String names = "小路dhdfhdf342蓉儿43fdffdfbjdfaf小何";
// 匹配到的内容当作分隔符,
String[] arrs = names.split("\\w+");
for (int i = 0; i < arrs.length; i++) {
System.out.println(arrs[i]);
}
String names2 = names.replaceAll("\\w+", " ");
System.out.println(names2);
正则表达式支持爬取信息
regex中 | 代表或的意思。
String rs = "来黑马程序学习Java,电话020-43422424,或者联系邮箱" +
"itcast@itcast.cn,电话18762832633,0203232323" +
"邮箱bozai@itcast.cn,400-100-3233 ,4001003232";
// 需求:从上面的内容中爬取出 电话号码、座机和邮箱。
// 1、定义爬取规则,字符串形式
String regex = "(\\w{1,30}@[a-zA-Z0-9]{2,20}(\\.[a-zA-Z0-9]{2,20}){1,2})|"
+ "(1[3-9]\\d{9})|"
+ "(0\\d{2,6}-?\\d{5,20})|"
+ "(400-?\\d{3,9}-?\\d{3,9})";
// 2、把这个爬取规则编译成匹配对象。
Pattern pattern = Pattern.compile(regex);
// 3、得到一个内容匹配器对象
Matcher matcher = pattern.matcher(rs);
// 4、开始找了
while (matcher.find()) {
String rs1 = matcher.group();
System.out.println(rs1);
}
Arrays类(数组)
数组操作工具类,专门用于操作数组元素的。可以是普通数组也可以是对象数组哦。
集合的排序,用Collections工具类。
Arrays类的常用API:
| 方法名 | 说明 |
|---|---|
| public static String toString(类型[] a) | 返回数组的内容(字符串形式) |
| public static void sort(类型[] a) | 对数组进行默认升序排序 |
| public static void sort(类型[] a, Comparator<? super T> c) | **(引用类型)**使用比较器对象自定义排序 |
| public static int binarySearch(int[] a, int key) | 前提:数组已经排序。二分搜索数组中的数据,存在返回索引,不存在返回-1 |
int[] arr = {10, 2, 55, 23, 24, 100};
//
String rs = Arrays.toString(arr);
//
Arrays.sort(arr); //数组对象传递的是!!!!地址
//
int index = Arrays.binarySearch(arr, 55);
- 注意注意
Arrays.toString()用于普通数组的时候,例如in[],String[],直接返回的是其数组的内容,但是当是一个对象数组的时候,打印的是地址。原因在于toString的源码是:拿到我这个数组的地址后,取该数组的每一个值出来a[i]然后加上”,”后再append下一个a[i+1].学会看源码。
Comparator比较器
重要API:自定义排序, 只能为引用类型!!因为他觉得如果你是基本类型,那么按照官网的就已经给你排序好了,一般需要自己排序的都是对象,即引用类型的数据。Comparator比较器是一个函数式接口!!!!可以用Lambda表达式
按照下面这个官方的规则,则会按照升序排序。

当结果>0时,把把左右两边更换位置,其他情况不变
-
有一点看不懂原理,其实没有关系,只要记住一个道理:
但是注意一定返回的是整数才可以哦,如果遇到double类型,就使用
return o1 - o2; // 升序
return o2 - o1; // 降序
return Double.compare(o1, o2) //double类型
Comparator比较器对象简介:
// API
public static <T> void sort(类型[] a, Comparator<? super T> c)
// Comparator比较器对象。
int[] ages = {34, 12, 42, 23};
Arrays.sort(ages);
System.out.println(Arrays.toString(ages));
Integer[] ages1 = {34, 12, 42, 23};
Arrays.sort(ages1, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1; // 降序
}
});
//Lambda简化函数式接口
Arrays.sort(ages1,(o1, o2) -> o2-o1);
System.out.println(Arrays.toString(ages1));
对象数组进行排序:
// 对象数组排序
Student[] students = new Student[3];
students[0] = new Student("吴磊",23 , 175.5);
students[1] = new Student("谢鑫",18 , 185.5);
students[2] = new Student("王亮",20 , 195.5);
System.out.println(Arrays.toString(students));//记得在Students里面重写toString,否则打印的是地址
Arrays.sort(students, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return Double.compare(o2.getHeight(), o1.getHeight());
}
});
System.out.println(Arrays.toString(students));
//lambda化简,前提是函数式接口
Arrays.sort(students, (o1, o2) -> Double.compare(o1.getHeight(),o2.getHeight()));
Lambda表达式(函数式接口)
Lambda表达式是JDK 8开始后的一种新语法形式。
- 作用:简化匿名内部类的代码写法。
Lambda表达式的简化格式:参数类型可省略不写
(匿名内部类被重写方法的形参列表) -> {
被重写方法的方法体代码。
}
注:-> 是语法形式,无实际含义。
注意:Lambda表达式只能简化函数式接口的匿名内部类的写法形式
函数式接口: 首先必须是接口、其次接口中有且仅有一个抽象方法的形式
//一般简化形式,就是看不懂!
go(() -> {
System.out.println("学生游泳很开心~~~")
});
@FunctionalInterface // 一旦加上这个注解必须是函数式接口,里面只能有一个抽象方法
interface Swimming{
void swim();
}
//静态方法
public static void go(Swimming s){
System.out.println("开始。。。");
s.swim();
System.out.println("结束。。。");
}
//main
public static void main(String[] args) {
//正常匿名内部类写法
Swimming s1 = new Swimming() {
@Override
public void swim() {
System.out.println("老师游泳贼溜~~~~~");
}
};
//Lambda简化后写法
Swimming s1 = () -> {
System.out.println("老师游泳贼溜~~~~~")
};
go(s1);
go(() -> {
System.out.println("学生游泳很开心~~~")
});
}
终极简化规则
-
如果只有一个参数,( )也可以省略。
lists.forEach(s->{ ......... }) -
如果方法体代码只有一行代码。可以省略大括号不写,同时要省略分号!如果这行代码还是一个return语句,则必须扔掉return,否则bug。
lists.stream().filter(s -> s.startsWith("张"));
集合
特点:大小不固定、可以动态增删、类型也不确定。是一个容器。大小动态变化
**只能存储对象数据啊!!!!!**即引用类型。(基本类型就是换成包装类)
支持泛型
内存原理
集合也是一个对象!!大哥啊。这里关系有三层
- 第一层:集合变量存储的是,一个对象的地址(类似于像数组,但又不是)
- 第二层:这个类似数组的对象里面存储的是,每一条我Movie对象的地址
- 第三层:最后每一条Movie对象的地址指向真正的对象内容
所以说,假如均没有重写tostring的话,
打印集合对象变量————输出23afc5;就因为一些实现类的集合已经重写了tostring,所以说我们每次打印出来的是,集合存储的每个对象地址,3aab2c, 2aab2c, 1aab2c。然后如果这个存储的对象,已经重写了tostring,那么我们在打印它的地址的时候,就会输出内容了!
这就是为什么,当我们自己写Javabean的集合时候,直接打印集合对象变量时,输出的是,每个自定义类型的地址。
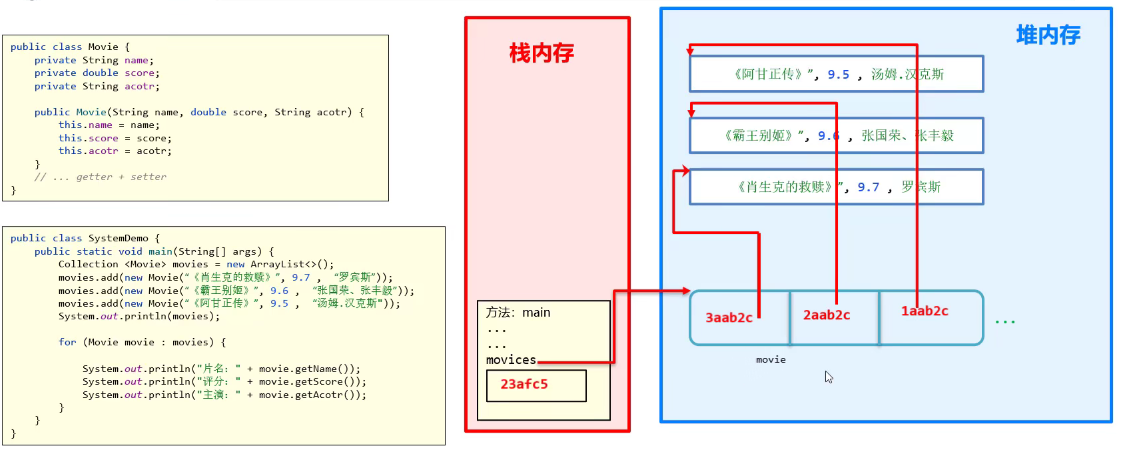
集合类体系结构
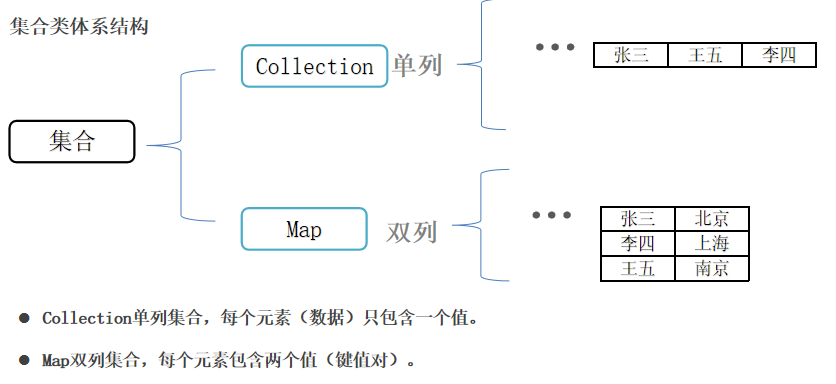
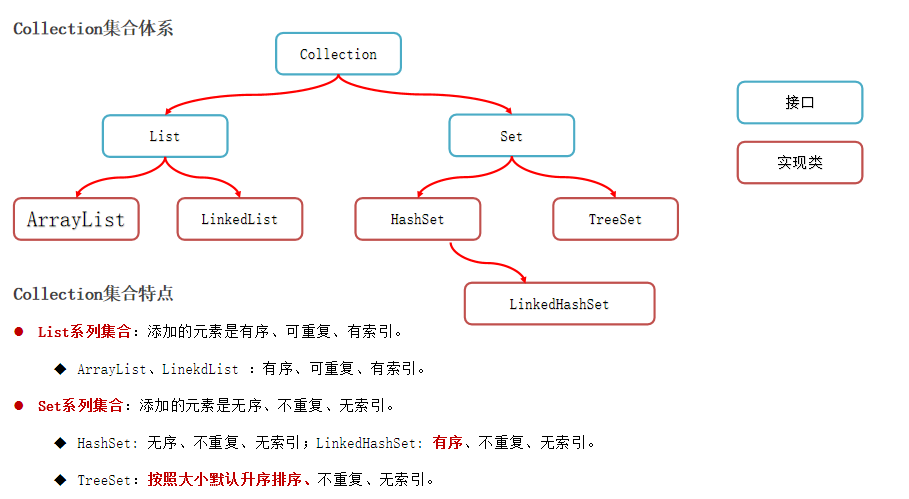
前期先掌握Collection集合体系
// 泛型
Collection<String> list = new ArrayList<>(); // 涉及多态
// 无泛型,随便放什么类型
Collection list = new ArrayList();
集合的并发删除异常问题
当我们从集合中找出某个元素并删除的时候可能出现一种并发修改异常问题。原因在于因为集合的大小是随着你的每次删除而变化的,每次删除之后,集合内的数据索引会马上发生变化! 索引在后面的元素会直接放到前面来。
哪些遍历存在问题?
- 迭代器 遍历集合且 直接用集合删除元素的时候可能出现。
- 增强for 循环遍历集合且 直接用集合删除元素的时候可能出现。
- Lambda表达式遍历,其底层原理就是forEach嘛
解决办法
-
迭代器 遍历集合 但是用迭代器自己的删除方法操作可以解决。
it.remove ( ) 删除当前迭代器取到的元素,并且让迭代器不后移。
//迭代器 Iterator<String> it = list.iterator(); while(it.hasNext()){ String ele = it.next(); if (Objects.equals(ele,"Java")){ it.remove(); } } -
forEach 无法解决这个问题!!!
-
对于List集合,因为可以使用for循环,所以可以采用for循环,倒着删除的办法解决
Collection集合体系
Collection的常用API
首先,前面不是说了接口的特点嘛,只有抽象方法和常量,这怎么会有API呢。原因在于JDK8在接口里面加了非抽象方法,分别是默认方法default(实现类调用)和静态方法static(接口调用)。
为什么学习这个最大的接口的API呢? 因为Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的。也就是说,学会它的方法后,它下面的所有实现类都可以直接用!!!!
常用API如下:(注意public是抽象方法哦,)
| 方法名称 | 说明 |
|---|---|
| public boolean add (E e) | 把给定的对象添加到当前集合中 |
| public void clear( ) | 清空集合中所有的元素 |
| public boolean remove (E e) | 把给定的对象在当前集合中删除 |
| public boolean contains (Object obj) | 判断当前集合中是否包含给定的对象 |
| public boolean isEmpty ( ) | 判断当前集合是否为空 |
| public int size( ) | 返回集合中元素的个数。 |
| public Object[ ] toArray ( ) | 把集合中的元素,存储到数组中 |
| boolean addAll(Collection<? extends E> c); | 将另外一个集合的元素全部拷贝过来 |
-
remove (E e)
只删除第一个相同的集合元素
遍历方式
注意哦:遍历是将集合里面的值拷贝给另外一个变量,变量的值发生改变了和集合内部元素无关系啊!
方式一:迭代器
迭代器在Java中的代表是Iterator,迭代器是集合的专用遍历方式。
-
获取迭代器
collection的方法名称 说明 Iteratoriterator() 返回集合中的迭代器对象,该迭代器对象默认指向当前集合的0索引
Collection<String> list = new ArrayList<>();
Iterator<String> it = list.iterator();
| Iterator常用方法名称 | 说明 |
|---|---|
| boolean hasNext ( ) | 询问当前位置是否有元素存在,存在返回true ,不存在返回false |
| E next() | 获取当前位置的元素,并同时将迭代器对象移向下一个位置,注意防止取出越界。 |
Iterator<String> it = lists.iterator();
while(it.hasNext()){
String ele = it.next();
System.out.println(ele);
}
方式二:增强for循环ForEach
既可以遍历集合也可以遍历数组!!!!!!
JDK5后面出现的,内部原理相对于一个迭代器,遍历集合相对于是迭代器的简化写法。
-
格式:
for(元素数据类型 变量名 : 数组或者Collection集合) { //在此处使用变量名即可,该变量名就是元素 }Collection<String> list = new ArrayList<>(); ... for(String ele : list) { System.out.println(ele); } -
**注意:**修改ele的值不会影响到集合中的元素
方式三:lambda表达式
JDK8开始的,更简单,更直接的遍历集合!!!底层也是forEach
- Collection结合Lambda遍历的API
| 方法名称 | 说明 |
|---|---|
| default void forEach(Consumer<? super T> action): | 结合lambda遍历集合 |
Collection<String> lists = new ArrayList<>();
...
// 直接使用这个API
lists.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
// 加上lambda表达式后
list.forEach( s -> sout(s));
存储自定义类型的对象
即我们自己创建的对象。
Collection集合没有重写tostring,但是ArrayList里面重写了toString,注意任何类都是有tostring方法的。
public class Movie{
private String name;
private double score;
private String acotr;
// ........
}
// Collection集合
Collection <Movie> movies = new ArrayList<>();
movies.add(new Movie(“《肖生克的救赎》”, 9.7 , “罗宾斯”));
System.out.println(movies);//打印的集合里面元素地址。
for (Movie movie : movies) {
System.out.println("片名:" + movie.getName());
System.out.println("评分:" + movie.getScore());
System.out.println("主演:" + movie.getAcotr());
}
使用场景总结
-
如果希望元素可以重复,又有索引,索引查询要快?
用ArrayList集合,基于数组的。(用的最多)
-
如果希望元素可以重复,又有索引,增删首尾操作快?
用LinkedList集合,基于链表的。 -
如果希望增删改查都快,但是元素不重复、无序、无索引。
用HashSet集合,基于哈希表的。 -
如果希望增删改查都快,但是元素不重复、有序、无索引。
用LinkedHashSet集合,基于哈希表和双链表。 -
如果要对对象进行排序。
用TreeSet集合,基于红黑树。后续也可以用List集合实现排序。
常见数据结构(略过)
- 数据结构是计算机底层存储、组织数据的方式。是指数据相互之间是以什么方式排列在一起的。
- 通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率
**常见的数据结构:**栈 队列 数组 链表 二叉树 二叉查找树 平衡二叉树 红黑树
-
栈
先进后出
-
队列
先进先出
-
数组
查询速度快:查询数据通过地址值和索引定位,查询任意数据耗时相同。(元素在 内存中是连续存储的)
删除效率低:(非动态变化)要将原始数据删除,同时后面每个数据前移。
添加效率极低:(非动态变化)添加位置后的每个数据后移,再添加元素。
-
链表
链表中的元素是在内存中不连续存储的,每个元素节点包含数据值和下一个元素的地址。
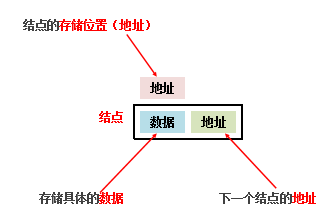
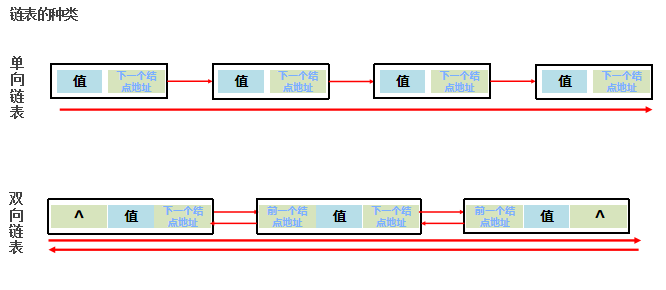
链表查询慢——无论查询哪个数据都要从头开始找。
链表增删相对快
-
二叉树
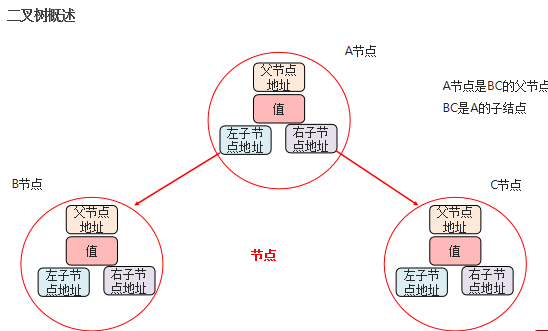
-
二叉查找树
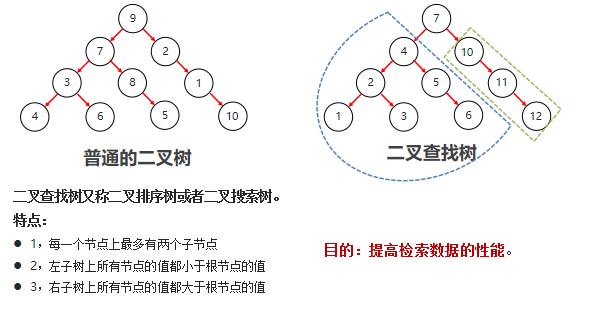
-
平衡二叉树
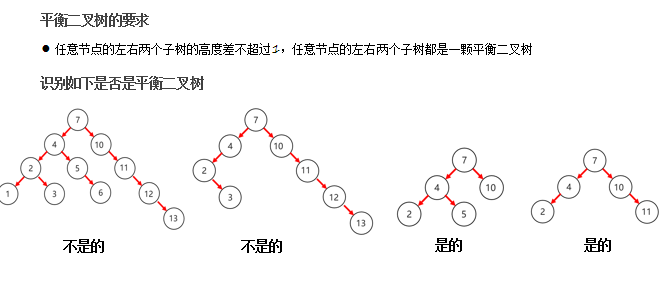
-
红黑树
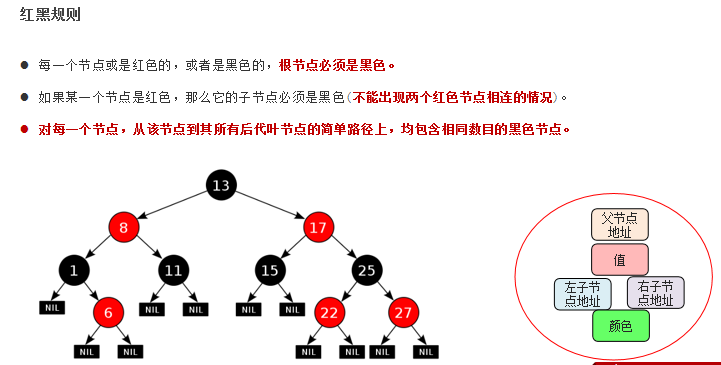
红黑树是一种自平衡的二叉查找树,是计算机科学中用到的一种数据结构。
每一个节点可以是红或者黑;红黑树不是通过高度平衡的,它的平衡是通过“红黑规则”进行实现的。
List系列集合
都按照下面这种多态的写法,不要问为什么,这就是Java!Bro!我们只要掌握Collection的API,然后掌握LIst的API,Set的API就行了。
List<String> list = new ArrayList<>();
List<String> list = new LinkedList<>();
List集合API
List集合因为支持索引,所以多了很多索引操作的独特api,其他Collection的功能List也都继承了。
| 方法名称 | 说明 |
|---|---|
| void add(int index,E element) | 在此集合中的指定索引插入指定的元素 |
| E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| E set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| E get(int index) | 返回指定索引处的元素 |
| List subList(int fromIndex, int toIndex); | 按照索引范围截取集合元素 |
- List的实现类的底层原理
ArrayList底层是基于数组实现的,根据查询元素快,增删相对慢。
LinkedList底层基于双链表实现的,查询元素慢,增删首尾元素是非常快的
Example:
List<String> list = new ArrayList<>();
循环方式
迭代器
增强for循环
Lambda表达式
for循环(因为List集合存在索引)
for (int i = 0; i < lists.size(); i++) {
System.out.println(lists.get(i));
}
ArraysList
基本使用在前面讲过了,这里只说一下集合的底层原理。
-
ArrayList底层是基于数组实现的:根据索引定位元素快,增删需要做元素的移位操作。(已经自动帮你做了这个工作,但对于数组而言是没有做这个工作的,所以说LIst增删麻烦)
-
第一次创建集合并添加第一个元素的时候,在底层创建一个默认长度为10的数组。
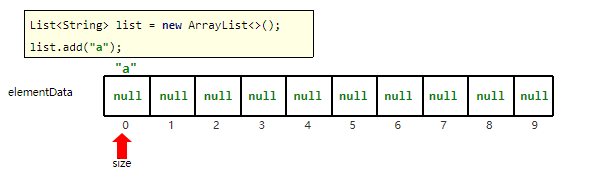
当你往集合里面添加元素后,例如加了一个a,然后集合长度就会发生变化,知道了吧。那问题来了,假如插入的元素超过10怎么办,java已经给我们想好了,当超过的时候,会直接扩容到1.5倍数。
LinkedList
底层数据结构是双链表,查询慢,首尾操作的速度是极快的,所以多了很多首尾操作的特有API。
LinkedList集合的特有功能:
| 方法名称 | 说明 |
|---|---|
| public void addFirst(E e) | 在该列表开头插入指定的元素Push() |
| public void addLast(E e) | 将指定的元素追加到此列表的末尾 |
| public E getFirst() | 返回此列表中的第一个元素 |
| public E getLast() | 返回此列表中的最后一个元素 |
| public E removeFirst() | 从此列表中删除并返回第一个元素pop() |
| public E removeLast() | 从此列表中删除并返回最后一个元素 |
Set系列集合
Set集合的功能上基本上与Collection的API一致
Set系列集合的底层就是Map实现的
Set<String> set = new HashSet<>();
Set<String> set = new TreeSet<>();
无序:存取顺序不按照你写的顺序
**不重复:**当添加了相同的元素时,会自动过滤,不添加
**无索引:**没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引来获取元素。
HashSet
- HashSet集合底层采取哈希表存储的数据。
- 哈希表是一种对于增删改查数据性能都较好的结构。
- JDK8开始后,哈希表采用数组+链表+红黑树组成。
哈希值:
是JDK根据对象的地址,按照某种规则算出来的int类型的数值。
Object类已经给我们写好了获取方法 public int hashCode():返回对象的哈希值。
JDK7原理:

**如果存放的时候有位置冲突时:**就会形成链表

JDK8的改进
- 底层结构:哈希表(数组、
- 链表、红黑树的结合体)当挂在元素下面的数据过多时,查询性能降低,从JDK8开始后,当链表长度超过8的时候,自动转换为红黑树。
-
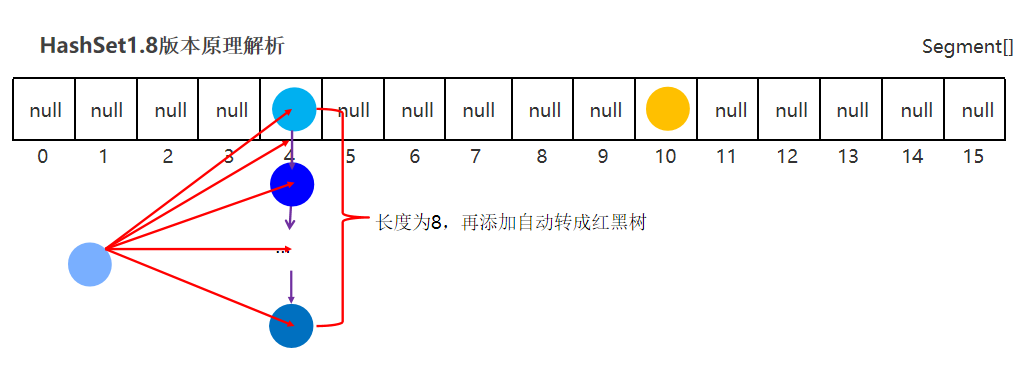
HashSet去重复原理
前面我们看到了,HashSet去重复是根据地址值得到哈希值,然后相同位置,再调用equals方法进行判断这种。
那这就很没有实际价值。因为我随便创建两个内容一样的对象,他们的地址值肯定不一样啊,得到的哈希值大概率不一样,这不就重复了吗。所以说,我们要重写HashCode方法才行,就想Object里面的tostring一样。
重写HashCode 和 equals
Set<Student> sets = new HashSet<>();
Student s1 = new Student("无恙", 20, '男');
Student s2 = new Student("无恙", 20, '男');
Student s3 = new Student("周雄", 21, '男');
sets.add(s1);
sets.add(s2);
sets.add(s3);
//如果Student类没有重写的话,输出的就是三个人的信息,前两个一模一样
System.out.println(sets);
LinkedHashSet
是HashSet的子类呀,对于HashSet改变了一个东西,有序指的是保证存储和取出的元素顺序一致
TreeSet
- 不重复、无索引、可排序
- 可排序:按照元素的大小默认升序(有小到大)排序。
- TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都较好。
- 注意:TreeSet集合是一定要排序的,可以将元素按照指定的规则进行排序。
排序规则:
- 对于数值类型:Integer , Double,官方默认按照大小进行升序
- 对于字符串类型:默认按照首字符的编号升序排序。
- 对于自定义类型如Student对象,TreeSet无法直接排序。TreeSet自带有参数构造器,可以设置Comparator接口对应的比较器对象,来定制比较规则。
Set<Student> set = new TreeSet<>((o1, o2) -> o1.getAge()- o2.getAge());
Collections集合工具类
- java.utils.Collections:是集合工具类
- 作用:Collections并不属于集合,是用来操作集合的工具类。
API:
| 方法名称 | 说明 |
|---|---|
| public static boolean addAll(Collection<? super T> c, T… elements) | 给集合对象批量添加元素 |
| public static void shuffle(List<?> list) | 打乱List集合元素的顺序 |
| public static void sort(List list) | 将集合中元素按照默认规则排序 |
| public static void sort(List list,Comparator<? super T> c) | 将集合中元素按照指定规则排序 |
//
List<String> names = new ArrayList<>();
//names.add("楚留香");
//names.add("胡铁花");
//names.add("张无忌");
//names.add("陆小凤");
Collections.addAll(names, "楚留香","胡铁花", "张无忌","陆小凤");
Collections.shuffle(names);
//排序
public static void main(String[] args) {
List<Apple> apples = new ArrayList<>(); // 可以重复!
apples.add(new Apple("红富士", "红色", 9.9, 500));
apples.add(new Apple("青苹果", "绿色", 15.9, 300));
apples.add(new Apple("绿苹果", "青色", 29.9, 400));
apples.add(new Apple("黄苹果", "黄色", 9.8, 500));
// sort方法自带比较器对象
Collections.sort(apples, new Comparator<Apple>() {
@Override
public int compare(Apple o1, Apple o2) {
return Double.compare(o1.getPrice() , o2.getPrice());
}
});
// Lamdba表达式
Collections.sort(apples, (o1, o2)->Double.compare(o1.getPrice(), o2.getPrice()));
System.out.println(apples);
}
Collection体系的综合案例

补充:泛型深入
泛型概述:
- 泛型:是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。
- 泛型的格式:<数据类型>; 注意:泛型只能支持引用数据类型。
- 集合体系的全部接口和实现类都是支持泛型的使用的。
泛型可以在很多地方进行定义:
类后面 ———— 泛型类;
方法声明上 ———— 泛型方法;
接口后面 ———— 泛型接口;
自定义泛型类
- 定义类时同时定义了泛型的类就是泛型类。
- 泛型类的格式:修饰符 class 类名<泛型变量>{ }
范例:public class MyArrayList<T> {
......
}
//此处泛型变量T可以随便写为任意标识,常见的如E、T、K、V等。
//在后续操作中把出现泛型变量的地方全部替换成传输的真实数据类型。
- 作用:编译阶段可以指定数据类型,类似于集合的作用。
Example:
// 泛型类 模仿ArrayList集合类
public class MyArrayList<E> {
public void add(E e){
}
public void remove(E e){
}
}
public class Test {
public static void main(String[] args) {
// 需求:模拟ArrayList定义一个MyArrayList ,关注泛型设计
MyArrayList<String> list = new MyArrayList<>();
list.add("Java");
list.add("Java");
list.add("MySQL");
list.remove("MySQL");
System.out.println(list);
MyArrayList<Integer> list2 = new MyArrayList<>();
list2.add(23);
list2.add(24);
list2.add(25);
list2.remove(25);
System.out.println(list2);
}
}
自定义泛型方法
-
定义方法时同时定义了泛型的方法就是泛型方法。
-
泛型方法的格式:修饰符 <泛型变量> 方法返回值 方法名称(形参列表) { }
范例: public <T> void show(T t){
......
}
//此处泛型变量T可以随便写为任意标识,常见的如E、T、K、V等。
//在后续操作中把出现泛型变量的地方全部替换成传输的真实数据类型。
作用:方法中可以使用泛型接收一切实际类型的参数,方法更具备通用性。
Example:
给你任何一个类型的数组,都能返回它的内容。也就是实现Arrays.toString(数组)的功能!
public class demo2 {
//泛型方法 无返回值
public static <T> void MYToString(T[] t){
System.out.println(Arrays.toString(t));
}
//泛型方法 返回值
public static <T> T[] MYToString(T[] t){
return Arrays.toString(t);
}
public static void main(String[] args) {
String[] s = {"java","asasa"};
MYToString(s);
}
}
自定义泛型接口
-
使用了泛型定义的接口就是泛型接口。
-
泛型接口的格式:修饰符 interface 接口名称<泛型变量>{}
范例: public interface Data<E>{ ..... }作用:泛型接口可以让实现类选择当前功能需要操作的数据类型
Example:
教务系统,提供一个接口可约束一定要完成数据(学生,老师)的增删改查操作
public interface Data<E> { void add(E e); void delete(int id); void update(E e); E queryById(int id); }
泛型通配符、上下限
通配符:?——表示可以在“使用泛型”的时候代表一切类型。
泛型的上下限:
-
? extends Car: 问号必须是Car或者其子类 泛型上限
-
? super Car : 必须是Car或者其父类 泛型下限
例子:开发一个极品飞车的游戏,所有的汽车都能一起参与比赛。
- 虽然BMW和BENZ都继承了Car但是ArrayList和ArrayList与ArrayList没有关系的!!
public class GenericDemo {
class Dog{
}
class BENZ extends Car{
}
class BMW extends Car{
}
// 父类
class Car{
}
/**
所有车比赛
*/
//第一种情况,大家都不能比赛
public static void go(ArrayList<Car> cars){
}
//第二种情况,只有宝马可以参加
public static void go(ArrayList<BMW> cars){
}
//第三种情况,狗和汽车都可以参加
public static void go(ArrayList<?> cars){
}
//第四种情况,只有汽车都可以参加
public static void go(ArrayList<? extends Car> cars){
}
public static void main(String[] args) {
ArrayList<BMW> bmws = new ArrayList<>();
bmws.add(new BMW());
bmws.add(new BMW());
go(bmws);
ArrayList<BENZ> benzs = new ArrayList<>();
benzs.add(new BENZ());
benzs.add(new BENZ());
go(benzs);
ArrayList<Dog> dogs = new ArrayList<>();
dogs.add(new Dog());
dogs.add(new Dog());
// go(dogs);
}
}
补充:可变参数
可变参数:
-
可变参数用在形参中可以接收多个数据。
-
可变参数的格式:数据类型…参数名称
//格式 public static void sum(int...nums){ } // 例子 public class MethodDemo { public static void main(String[] args) { sum(); // 1、不传参数 sum(10); // 2、可以传输一个参数 sum(10, 20, 30); // 3、可以传输多个参数 sum(new int[]{10, 20, 30, 40, 50}); // 4、可以传输一个数组 } public static void sum(int...nums){ // 注意:可变参数在方法内部其实就是一个数组。 nums System.out.println("元素个数:" + nums.length); System.out.println("元素内容:" + Arrays.toString(nums)); } }
可变参数的作用
- 传输参数非常灵活方便。可以不传输参数,可以传输1个或者多个,也可以传输一个数组。
- 可变参数在方法内部本质上就是一个数组
注意事项:
- 一个形参列表中可变参数只能有一个
- 可变参数必须放在形参列表的最后面
Map集合体系
Map里面存储的数据类型是???,无定义,知道不,根本就不是什么类型。后面Map是单独再弄了一个键值对对象,也就是键值对类型了。
- Map集合是一种双列集合,每个元素包含两个数据。
- Map集合的每个元素的格式:key=value(键值对元素)。
- Map集合也被称为**“键值对集合”。**
**格式:**collection集合重写的tostring用的是【】
Collection集合的格式: [元素1,元素2,元素3…]
Map集合的完整格式:{key1=value1 , key2=value2 , key3=value3 , …}
特点
-
Map集合的特点都是由键决定的。
-
Map集合的键是无序, 不重复,无索引,值不做要求(可以重复)。
-
Map集合后面重复的键对应的值会覆盖前面键的值。
-
Map集合的键值对都可以为null。
- 使用最多的Map集合是HashMap。
- 重点掌握HashMap , LinkedHashMap , TreeMap。其他的后续理解。与LIst集合很相似
HashMap: 元素按照键是无序,不重复,无索引,值不做要求。(与Map体系一致)
LinkedHashMap: 元素按照键是有序,不重复,无索引,值不做要求。
**TreeMap:**元素按照建是排序,不重复,无索引的,值不做要求。
声明方式
//键——String,值——Integer
Map<String, Integer> map = new HashMap<>();
Map的API
public interface Map<K,V>
K——键的泛型;V——值的泛型
| 方法名称 | 说明 |
|---|---|
| V put(K key,V value) | 添加元素 |
| V remove(Object key) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
| V get(Object key); | 根据键获取值 |
| Set keySet(); | 获取Map集合里面的键的集合,返回Set集合 |
| Collection values(); | 获取Map集合里面的值的集合,返回Collection集合 |
|---|---|
| void putAll(Map<? extends K, ? extends V> m); | 将其他集合并到现在这个集合 |
遍历方式
方式一:键找值
-
先获取Map集合的全部键的Set集合。
-
再遍历键的Set集合,然后通过键提取对应值。
用到两个API: keySet ( )和 get(Object key)
方式二:键值对类型
- 先把Map集合转换成Set集合,Set集合中每个元素都是键值对实体类了。其实就是说,Java给我们定一个类,这个类用来存储Map元素的键和值,然后把这个类的每个对象放到Set集合里面去。这个类名字是 Map.Entry<K,V>——键值对类型
- 遍历Set集合,然后提取键以及提取值。
用到API:
| 方法名称 | 说明 |
|---|---|
| Set<Map.Entry<K,V>> entrySet() | 获取所有键值对对象的集合 |
| K getKey() | 获得键值对对象的键 |
| V getValue() | 获取键值对对象的值 |
Map<String,Integer> map = new HashMap<>();
map.put("周杰伦",10);
map.put("刘德华",12);
map.put("林宥嘉",1231);
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
for (Map.Entry<String, Integer> stringIntegerEntry : entrySet) {
System.out.println(stringIntegerEntry.getKey());
System.out.println(stringIntegerEntry.getValue());
}
方式三:Lambda
得益于JDK 8开始的新技术Lambda表达式,提供了一种更简单、更直接的遍历集合的方式。
底层原理是:键值对类型
Map结合Lambda遍历的API:也是forEach
| 方法名称 | 说明 |
|---|---|
| default void forEach(BiConsumer<? super K, ? super V> action) | 结合lambda遍历Map集合 |
maps.forEach((k , v) -> {
System.out.println(k +"----->" + v);
});
HashMap
- 特点都是由键决定的:无序、不重复、无索引
HashMap跟HashSet底层原理是一模一样的,都是哈希表结构,只是HashMap的每个元素包含两个值而已。
实际上:Set系列集合的底层就是Map实现的,只是Set集合中的元素只要键数据,不要值数据而已。
去重复原理
这里仅仅对键进行了去重复撒。原理和前面的HashSet一样的,均依赖于两个东西,重写的hashCode和equals。我们现在直接用的hashMap集合,还有等等,都是早就重写了的。
但是重点注意**:自定义的对象,一定要重写hashCode和equals方法**,不然用HashMap来存储多个对象,就失效了
LinkedHashMap
**原理:**底层数据结构是依然哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序。
对HashMap进行了修改,由键决定:有序、不重复、无索引。
有序指的是保证存储和取出的元素顺序一致
TreeMap
-
由键决定特性:不重复、无索引、一定要排序
-
可排序:按照键数据的大小默认升序(有小到大)排序。只能对键排序
-
注意:TreeMap集合是一定要排序的,可以默认排序,也可以将键按照指定的规则进行排序
-
TreeMap跟TreeSet一样底层原理是一样的。
排序规则:
他写了一个带有Comparator比较器对象的有参构造器,可以在创建对象的时候重写比较规则。
Map<String,Integer> map1 = new TreeMap<>((o1, o2) -> o1.getage()-o2.getage())
补充:集合嵌套
简单说:就是我一个Map不是有键和值吗,我的键是唯一的,只能是一个数据;但是有可能我这个键对应了有很多个值啊,那怎么办呢,我们就可以将这很多个值放到一起变成一个List集合,然后这个List集合作为该键的值。
// 集合嵌套
Map<String, List<String>> data =new HashMap<>();
List<String> s1 = new ArrayList<>();
Collections.addAll(s1,"A","C","D");
data.put("周权",s1);
System.out.println(data);
不可变集合(JDK9)
- 不可变集合,就是不可被修改的集合。不能添加,不能删除,不能修改
- 集合的数据项在创建的时候提供,并且在整个生命周期中都不可改变。否则报错。
创建方式
在List、Set、Map接口中,都存在of方法,可以创建一个不可变的集合。
| 方法名称 | 说明 |
|---|---|
| static List of(E…elements) | 创建一个具有指定元素的List集合对象 |
| static Set of(E…elements) | 创建一个具有指定元素的Set集合对象 |
| static <K , V> Map<K,V> of(E…elements) | 创建一个具有指定元素的Map集合对象 |
Stream流
在Java 8中,得益于Lambda所带来的函数式编程, 引入了一个全新的Stream流概念。
目的:用于简化集合和数组操作的API。
在Stream流中无法直接修改集合、数组中的数据。
Stream流的三类方法
-
获取Stream流方法
创建一条流水线,并把数据放到流水线上准备进行操作
-
中间方法
流水线上的操作。一次操作完毕之后,还可以继续进行其他操作。
-
终结方法
一个Stream流只能有一个终结方法,是流水线上的最后一个操作
获取Stream流
Collection获取Stream流
别人已经给我们写好了接口,直接调用Collection接口中的默认方法stream()就可以
| Collection方法名称 | 说明 |
|---|---|
| default Stream stream ( ) | 获取当前集合对象的Stream流 |
支持链式编程,超级好用哦。下面是快速入门。
// 找出lists集合里面姓张的,并且三个字的人
List<String> lists = new ArrayList<>();
Collections.addAll(lists,"张三丰","张无忌","周只能","张强");
//filter----过滤条件,支持Lambda
List<String> list4 = new ArrayList<>();
lists.stream()
.filter(s -> s.startsWith("张"))
.filter(s -> s.length()==3)
.forEach(s -> list4.add(s));
System.out.println(list4);
Map合获取Stream流
Map集合里面存储的是什么呢?没有明确的定义,这不是个什么类型,对不对。所以不能直接拿到Stream流。
我们可以分别拿到 键流 和 值流。或者说直接拿键值对流。
Map<String, Integer> map = new HashMap<>();
//键流
Stream<String> keyStream = map.keySet().stream();
//值流
Stream<Integer> valueStream = map.values().stream();
//键值对流
Stream<Map.Entry<String, Integer>> keyvalueStream = map.entrySet().stream();
数组获取Stream流的方式
借用数组工具类——Arrays。
| 获取方法名称 | 说明 |
|---|---|
| public static Stream stream(T[] array) | 获取当前数组的Stream流 |
| public static Stream of(T… values) | 获取当前数组/可变数据的Stream流 |
String[] name = {"张三丰","张无忌","周只能","张强"};
Stream<String> stream = Arrays.stream(name);
Stream流API
也叫做是:中间方法。
| 名称 | 说明 |
|---|---|
| Stream filter(Predicate<? super T> predicate) | 用于对流中的数据进行过滤。 |
| Stream limit(long maxSize) | 获取前几个元素 |
| Stream skip(long n) | 跳过前几个元素 |
| Stream distinct() | 去除流中重复的元素。依赖(hashCode和equals方法) |
| static Stream concat(Stream a, Stream b) | 合并a和b两个流为一个流 |
| long count(); | 返回当前stream里面的元素个数 |
| void forEach(Consumer<? super T> action); | 对当前Stream流里面的元素进行遍历。 |
| Stream map(Function<? super T, ? extends R> mapper); | Map加工方法,对每个元素进行操作,看下面的使用 |
| Object[ ] toArray(); | 将stream流编程一个对象数组,返回Object数组 |
List<String> lists = new ArrayList<>();
Collections.addAll(lists,"张三丰","张无忌","周只能","张强");
//filter原理,当返回的是false时表示舍弃该数据,一般我们写的是lambda表达式,所以注意一点,里面那行代码的返回值要是boolean类型
lists.stream().filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return s.startsWith("张");
}
});
lists.stream().filter(s -> s.startsWith("张")).forEach(s -> System.out.println(s));
//map加工方法,给每个元素前面加一个黑马字符串
lists.stream().map(s -> "黑马"+s).forEach(s -> System.out.println(s));
Stream终结方法
| 名称 | 说明 |
|---|---|
| void forEach(Consumer action) | 对此流的每个元素执行遍历操作 |
| long count() | 返回此流中的元素数 |
注意:终结操作方法,调用完成后流就无法继续使用了,原因是不会返回Stream了。
综合案例
课程里面
收集Stream流
前面不是说了,我们Stream流里面的数据,是从集合或数组里面拷贝过来的嘛,就有一个弊端,原始的集合内容不会被修改,其实这是一个普遍现象,包括for循环里面也是一样的,都是拷贝原理。所以这里提出了收集Stream流,真的不错,这就舒服了。
- 收集Stream流的含义:就是把Stream流操作后的结果数据转回到集合或者数组中去
Stream流:方便操作集合/数组的手段。
集合/数组:才是开发中的目的。
stream流里面提供了收集方法:
| 名称 | 说明 |
|---|---|
| R collect(Collector collector) | 开始收集Stream流,指定收集器 |
这里Collectors是一个工具类,提供了具体的收集方式!!!返回值值Collector
| 名称 | 说明 |
|---|---|
| public static Collector toList() | 把元素收集到List集合中 |
| public static Collector toSet() | 把元素收集到Set集合中 |
| public static Collector toMap(Function keyMapper , Function valueMapper) | 把元素收集到Map集合中 |
List<String> lists = new ArrayList<>();
Collections.addAll(lists,"张三丰","张无忌","周只能","张强","张三丰");
//找出姓张的人,
Stream<String> sss = lists.stream().filter(s -> s.startsWith("张"));
// 将现在的Stream流收集到List集合
List<String> newList = sss.collect(Collectors.toList());
异常处理
异常:程序在“编译”或者“执行”的过程中可能出现的问题。
注意:语法错误不算在异常体系中。 比如:数组索引越界、空指针异常、 日期格式化异常,等…
异常体系:
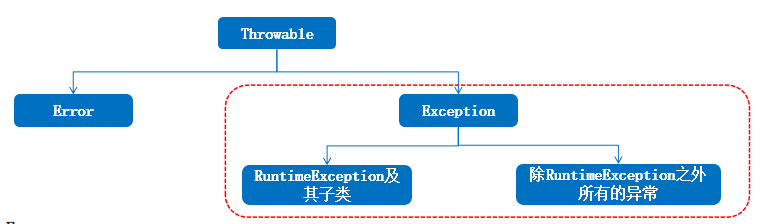
Error:
系统级别问题、JVM退出等,代码无法控制。
**Exception:**java.lang包下,称为异常类,它表示程序本身可以处理的问题
-
RuntimeException及其子类:运行时异常,编译阶段不会报错。 (空指针异常,数组索引越界异常)
-
除RuntimeException之外所有的异常:编译时异常,编译期必须处理的,否则程序不能通过编译。 (日期格式化异常)
运行时异常
RuntimeException及其子类,编译不报错,运行时报错。
常见例子:
-
数组索引越界异常: ArrayIndexOutOfBoundsException
-
空指针异常 : NullPointerException,直接输出没有问题,但是调用空指针的变量的功能就会报错。
-
数学操作异常:ArithmeticException
-
类型转换异常:ClassCastException
-
数字转换异常: NumberFormatException
运行时异常:一般是程序员业务没有考虑好或者是编程逻辑不严谨引起的程序错误,
自己的水平有问题!
编译时异常
这个很简单,就是我们写了代码,让java自动编译语句,仅仅仅仅只看了语法格式有没有问题,其他的检查不出来。
Java默认异常处理机制
-
默认会在出现异常的代码那里自动的创建一个异常对象:ArithmeticException。
-
异常会从方法中出现的点这里抛出给调用者(main方法),最终抛出给JVM虚拟机。
-
虚拟机接收到异常对象后,先在控制台直接输出异常栈信息数据。
-
直接从当前执行的异常点干掉当前程序。
坏处:后续代码没有机会执行了,因为程序已经死亡。
编译异常处理机制
编译时异常是编译阶段就出错的,所以必须处理,否则代码根本无法通过。
**注意注意:**在方法里面,仅仅只会抛出一个异常,当里面的某行代码运行出现异常时,这个方法会立即抛出该异常,并且终止该方法里后续代码的执行!!!
编译时异常的处理形式有三种:
-
出现异常直接抛出去给调用者,调用者也继续抛出去。
-
出现异常自己捕获处理,不麻烦别人。
-
前两者结合,出现异常直接抛出去给调用者,调用者捕获处理
方式一:throws
出现异常直接抛出去给调用者,调用者也继续抛出去。最终抛给了虚拟机,
**适用范围:**方法,可以将方法内部出现的异常抛出去给本方法的调用者处理。
**评价:**这种方式并不好,发生异常的方法自己不处理异常,然后就会一层层往外抛,异常最终抛出去给虚拟机,,,将引起程序死亡。没有啥用的垃圾,就是仅仅让我们的编译通过,该有的问题还是有,该死机还是死机!!!
**格式:**Alt + Enter
// 这样会规定具体是抛出什么类型异常
方法 throws 异常1 ,异常2 ,异常3 ..{
}
//代表可以抛出一切异常,
方法 throws Exception{
}
方式二:try…catch…
出现异常自己捕获处理,不麻烦别人。
适用范围:方法内部;
**评价:**还可以,发生异常的话,会让方法自己去处理,try后续的代码可以往下执行。但注意里面的代码就不执行了哦。但是我调用者,即main方法就无法知道我里面使用的方法有没有发生异常撒,你都自己处理了
try{
// 可能出现异常的代码!
}catch (Exception e){
e.printStackTrace(); // 直接打印异常栈信息
}
Exception可以捕获处理一切异常类型!
方式三:前两者结合
方法直接将异通过throws抛出去给调用者; 调用者收到异常后直接捕获处理。
**评价:**最好,底层的异常抛出去给最外层,最外层集中捕获处理。如果只用第二个,那每个方法都写一个try catch不要写死啊!
简单说:我写的方法均采用throws来把里面的异常抛出来,这个时候就抛给了调用者,即main方法;然后在main方法里面,我们用try…catch…将其调用该方法的代码包起来。晓得了吧。一方面,main方法可以知道是哪个小兔崽子方法写出bug了,其次也不会直接抛给虚拟机,导致死机现象。
Example:
public static void main(String[] args) {
System.out.println("程序开始。。。。");
try {
parseTime("2011-11-11 11:11:11");
System.out.println("功能操作成功~~~");
} catch (Exception e) {
e.printStackTrace();
System.out.println("功能操作失败~~~");
}
System.out.println("程序结束。。。。");
}
public static void parseTime(String date) throws Exception {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy、MM-dd HH:mm:ss");
Date d = sdf.parse(date);
System.out.println(d);
InputStream is = new FileInputStream("D:/meinv.jpg");
}
运行时异常处理机制
这种没有什么办法处理。因为他是运行时异常,但编译阶段不会出错,是运行时才可能出错的,所以编译阶段不处理也可以。
按照规范建议还是:建议在最外层调用处集中捕获处理即可。但我们不确定哪种方法可能出现异常对不对,讲实话,一般不用管这个的。
自定义异常
- 自定义异常的必要?
Java无法为这个世界上全部的问题提供异常类。
如果企业想通过异常的方式来管理自己的某个业务问题,就需要自定义异常类了。
- 自定义异常的好处
可以使用异常的机制管理业务问题,如提醒程序员注意。
同时一旦出现bug,可以用异常的形式清晰的指出出错的地方。
定义方法
- 自定义编译时异常
-
定义一个异常类继承Exception.
-
重写构造器。一个无参,一个message的有参
-
在出现异常的地方用throw new 自定义对象抛出,
**作用:**编译时异常是编译阶段就报错,提醒更加强烈,一定需要处理!!!当我们想要强调某个地方一定需要某种格式或参数的情况下,即我一写,java马上就会给我标红,提醒我写的参数有问题;而不会等到我跑起来才出问题。
这里出现了一个新的关键字,throw;他与throws的区别如下:
| throw与throws | 适用范围 |
|---|---|
| throws | 用于方法的声明上,和方法参数写在一行,可以抛出方法内部的异常 |
| throw | 在方法内部直接创建一个异常对象,并从此点抛出。一般用于自定义异常 |
Example:
// 自定义一个异常类
public class MyException extends Exception{
public MyException() {
}
public MyException(String message) {
super(message);
}
}
// 测试类
public class Test {
public static void main(String[] args) {
try {
checkAge(9090);
} catch (MyException e) {
e.printStackTrace();
}
}
public static void checkAge(int age) throws MyException {
if (age<0 ||age >200){
throw new MyException(age +"is 非法的兄弟");
}else {
System.out.println("GOOD");
}
}
}
- 自定义运行时异常
-
定义一个异常类继承RuntimeException.
-
重写构造器。与前面一样。
-
在出现异常的地方用throw new 自定义对象抛出!
**作用:**提醒不强烈,编译阶段不报错!!运行时才可能出现!!!一般不写这个,用处比较小。
日志框架
作用:系统在开发阶段或者上线后,一旦业务出现问题,需要有信息去定位,如何记录程序的运行信息?那个时候是没有控制台的。
| 输出语句 | 日志技术 | |
|---|---|---|
| 输出位置 | 只能是控制台 | 可以将日志信息写入到文件或者数据库中 |
| 取消日志 | 需要修改代码,灵活性比较差 | 不需要修改代码,灵活性比较好 |
| 多线程 | 性能较差 | 性能较好 |
日志技术体系
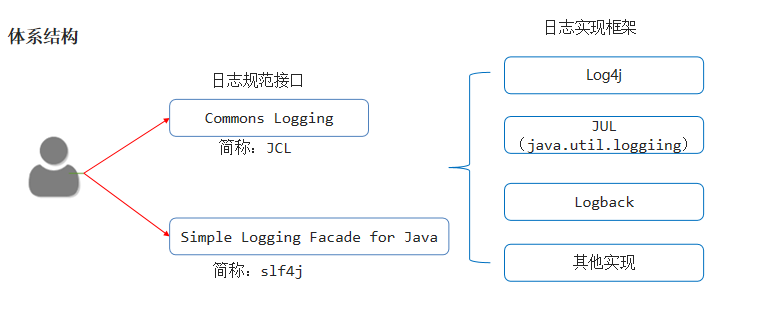
-
**日志规范:**一些接口,提供给日志的实现框架设计的标准。
-
**日志框架:**牛人或者第三方公司已经做好的日志记录实现代码,后来者直接可以拿去使用。
因为对Commons Logging的接口不满意,有人就搞了SLF4J。因为对Log4j的性能不满意,有人就搞了Logback。重点学习这个。
Logback
Logback是由log4j创始人设计的另一个开源日志组件,性能比log4j要好,也是实现的slf4j接口的功能。
Logback主要分为三个技术模块:
-
logback-core: logback-core 模块为其他两个模块奠定了基础,必须有。
-
logback-classic:它是log4j的一个改良版本,同时它完整实现了slf4j API。
-
logback-access 模块与 Tomcat 和 Jetty 等 Servlet 容器集成,以提供 HTTP 访问日志功能
使用Logback需要使用哪几个模块,各自的作用是什么。
slf4j-api:日志规范
logback-core:基础模块。
logback-classic:它是log4j的一个改良版本,同时它完整实现了slf4j
快速入门
需求:导入Logback日志技术到项目中,用于纪录系统的日志信息
分析:
①:在项目下新建文件夹lib,导入Logback的相关jar包到该文件夹下,然后右键——add as Library添加到项目依赖库中去,他可不会自己进去啊。

②:将Logback的核心配置文件logback.xml直接拷贝到src目录下(必须是src下)。
③:在代码中获取日志的对象、
public static final Logger LOGGER = LoggerFactory.getLogger("类对象");
④:使用日志对象LOGGER调用其方法输出不能的日志信息
public class Test {
//
public static final Logger LOOGER = LoggerFactory.getLogger("Test.class");
public static void main(String[] args) {
try {
LOOGER.debug("main方法开始执行了");
LOOGER.info("sdasdhuysagdayu");
int a = 10;
int b = 0;
LOOGER.trace("a="+a);
LOOGER.trace("b="+b);
System.out.println("a/b=" + a/b);
System.out.println("main方法全部执行完毕");
} catch (Exception e) {
e.printStackTrace();
LOOGER.error("出现异常"+ e);
}
}
}
配置详解
1. 日志输出位置、格式设置:< appender>
-
通过logback.xml 中的**< appender>标签**可以设置输出位置和日志信息的详细格式。
-
通常可以设置2个日志输出位置:一个是控制台、一个是系统文件中
输出到控制台的配置标志
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
输出到系统文件的配置标志
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
2. 日志级别设置: < root>
可以通过设置日志的输出级别来控制哪些日志信息输出或者不输出。
级别程度依次是:TRACE < DEBUG < INFO < WARN < ERROR ; 默认级别是debug(忽略大小写),对应其方法。
作用:用于控制系统中哪些日志级别是可以输出的,只输出级别不低于设定级别的日志信息。
ALL 和 OFF分别是打印全部级别的全部日志信息,及关闭全部日志信息。
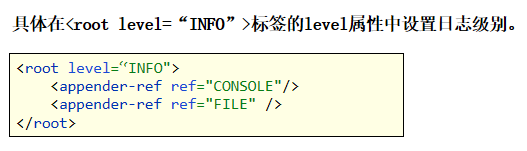
范例:
依赖:
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.9</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.9</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.32</version>
</dependency>
配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--
CONSOLE :表示当前的日志信息是可以输出到控制台的。
-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--输出流对象 默认 System.out 改为 System.err-->
<target>System.out</target>
<encoder>
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度
%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%-5level] %c [%thread] : %msg%n</pattern>
</encoder>
</appender>
<!--
File是输出的方向通向文件的
-->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<!--日志输出路径-->
<file>C:/code/itheima-data.log</file>
<!--指定日志文件拆分和压缩规则-->
<rollingPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--通过指定压缩文件名称,来确定分割文件方式-->
<fileNamePattern>C:/code/itheima-data2-%d{yyyy-MMdd}.log%i.gz</fileNamePattern>
<!--文件拆分大小-->
<maxFileSize>1MB</maxFileSize>
</rollingPolicy>
</appender>
<!--
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF
, 默认debug
<root>可以包含零个或多个<appender-ref>元素,标识这个输出位置将会被本日志级别控制。
-->
<root level="ALL">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE" />
</root>
</configuration>
File、IO流(TODO)
前面做系统的时候,我们用集合存储数据,都是在内存里面,数据都是临时的,所以,我们希望把数据存储到磁盘里面,这样可以一直保存。
计算机的最小存储单位为字节byte,由8个二进制位组成,也叫8个bit
方法:
1、先要定位文件
File类可以定位文件:进行删除、获取文本本身信息等操作。但是不能读写文件内容。
2、读写文件数据
IO流技术可以对硬盘中的文件进行读写
先学会使用File类定位文件以及操作文件本身,然后学习IO流读写文件数据。
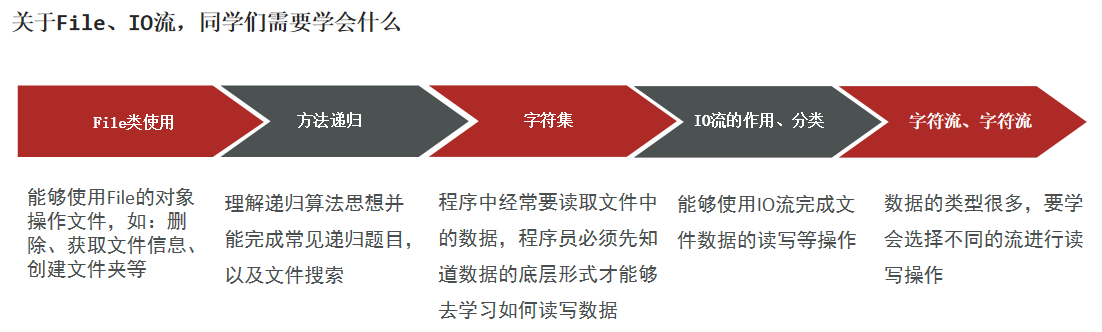
File类
- File类在 包java.io.File下、代表操作系统的文件对象(文件、文件夹)。
- File类提供了:定位文件,获取文件本身的信息、删除文件、创建文件(文件夹)等功能
创建File对象
| 构造器名称 | 说明 |
|---|---|
| public File(String pathname) | 根据文件路径创建文件对象 |
| public File(String parent, String child) | 从父路径和子路径创建文件对象 |
| public File(File parent, String child) | 根据父路径文件对象和子路径创建文件对象 |
注意:File对象可以是文件或者文件夹
File封装的对象仅仅是一个路径名,这个路径可以是存在的,也可以是不存在的。
Java的相对路径,默认直接到当前工程下的目录寻找文件。 是相对于工程而言的,而不是模块,当你使用相对路径时,会直接从该模块的上级工程开始往下找。工程相对于酒店,模块相对于房间。

// 相对路径
File f = new File("C:\\Users\\Joker_Monster\\Desktop\\个人\\租房信息.jpg");
long size = f.length();//文件字节大小
// 相对路径
File f3 = new File("File-IO/resource/校车表.png");
System.out.println(f3.length());
// 这个可以获取我们当前class文件代码所在的主路径
System.out.println(System.getProperty("user.dir"));
File类API
- File类的判断文件类型、获取文件信息功能
| 方法名称 | 说明 |
|---|---|
| public boolean isDirectory() | 测试此文件对象表示的File是否为文件夹 |
| public boolean isFile() | 测试此文件对象表示的File是否为文件 |
| public boolean exists() | 测试此文件对象表示的File是否存在 |
| public String getAbsolutePath() | 返回此文件对象的 绝对路径名字符串 |
| public String getPath() | 返回此文件对象定义时使用的路径 |
| public String getName() | 返回由此文件对象表示的文件或文件夹的名称 |
| public long lastModified() | 返回文件最后修改的时间毫秒值 |
| public long length( ) | 返回此文件对象的真实字节大小(文件夹没有意义) |
Example:
long time = f.lastModified();
System.out.println("该文件最后的修改时间为:"+new SimpleDateFormat("yyyy/MM/dd HH:mm:ss").format(time));
- File类创建文件的功能
| 方法名称 | 说明 |
|---|---|
| public boolean createNewFile( ) | 创建一个新的空的文件 |
| public boolean mkdir( ) | 只能创建一级文件夹 |
| public boolean mkdirs( ) | 可以创建多级文件夹 |
- File类删除文件的功能
| 方法名称 | 说明 |
|---|---|
| public boolean delete( ) | 删除由此抽象路径名表示的文件或空文件夹 |
delete方法默认只能删除文件和空文件夹并且不走回收站
- 遍历File
| 方法名称 | 说明 |
|---|---|
| public String[ ] list() | 返回一个字符串数组,获取当前目录下所有的"一级文件名称" |
| public File[ ] listFiles() | 返回一个文件对象数组,获取当前目录下所有的"一级文件对象" |
listFiles方法注意事项:
-
当调用者不存在时,返回null
-
当调用者是一个文件时,返回null
-
当调用者是一个空文件夹时,返回一个长度为0的数组
-
当调用者是一个有内容的文件夹时,将里面所有文件和文件夹的路径放在文件对象数组中返回
-
当调用者是一个有隐藏文件的文件夹时,将里面所有文件和文件夹的路径放在File数组中返回,包含隐藏内容
-
当调用者是一个需要权限才能进入的文件夹时,返回null
方法递归
- 方法直接调用自己或者间接调用自己的形式称为方法递归( recursion)
- 递归做为一种算法在程序设计语言中广泛应用。
文件搜索问题
需求:文件搜索、从C:盘中,搜索出某个文件名称并输出绝对路径。
西南交通大学学术期刊分级目录.pdf
public class FIleSearch {
public static void main(String[] args) {
searchFile(new File("F:/"), "covid.test.csv");
}
/**
* 搜索某个文件夹下的全部文件,找到我们想要的文件。
* @param dir
* @param fileName
*/
public static void searchFile(File dir,String fileName){
// 判断dir不是空对象,且是一个文件夹
if (dir!=null && dir.isDirectory()){
// 获取当前文件夹内所有一级文件对象
File[] files = dir.listFiles();
// 判断dir不是一个需要权限进行的文件夹,且不是空文件夹
if (files!=null && files.length>0){
//这个时候,开始遍历dir下的一个文件对象
for (File file : files) {
// 当子对象为文件时
if (file.isFile()){
boolean a = file.getName().contains(fileName);
if (a){
System.out.println("您需要查找文件在:"+file.getAbsolutePath());
return;
}
}
// 当子对象为文件夹时
else {
searchFile(file,fileName);
}
}
}
}else{
System.out.println("你当前搜索的不是文件夹!!!");
return;
}
}
}
啤酒问题
需求:啤酒2元1瓶,4个盖子可以换一瓶,2个空瓶可以换一瓶,请问10元钱可以喝多少瓶酒,剩余多少空瓶和盖子。
答案:15瓶 3盖子 1瓶子
核心思想:将手里拿到的盖子和空瓶换算成钱。
public class RecursionDemo06 {
// 定义一个静态的成员变量用于存储可以买的酒数量
public static int totalNumber; // 总数量
public static int lastBottleNumber; // 记录每次剩余的瓶子个数
public static int lastCoverNumber; // 记录每次剩余的盖子个数
public static void main(String[] args) {
// 1、拿钱买酒
buy(10);
System.out.println("总数:" + totalNumber);
System.out.println("剩余盖子数:" + lastCoverNumber);
System.out.println("剩余瓶子数:" + lastBottleNumber);
}
public static void buy(int money){
// 2、看可以立马买多少瓶
int buyNumber = money / 2; // 5
totalNumber += buyNumber;
// 3、把盖子 和瓶子换算成钱
// 统计本轮总的盖子数 和 瓶子数
int coverNumber = lastCoverNumber + buyNumber;
int bottleNumber = lastBottleNumber + buyNumber;
// 统计可以换算的钱
int allMoney = 0;
if(coverNumber >= 4){
allMoney += (coverNumber / 4) * 2;
}
lastCoverNumber = coverNumber % 4;
if(bottleNumber >= 2){
allMoney += (bottleNumber / 2) * 2;
}
lastBottleNumber = bottleNumber % 2;
if(allMoney >= 2){
buy(allMoney);
}
Integer[] arr2 = new Integer[]{11, 22, 33};
Arrays.sort(arr2);
}
}
字符集
字符集基础知识:
-
字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。在java里面专门有一个数据类型表示字符——char
-
计算机底层不可以直接存储字符(char)的。计算机中底层只能存储二进制(0、1)
-
二进制与十进制是可以相互转换的

结论:计算机底层可以表示十进制编号。
计算机可以给人类字符进行编号存储,这套编号规则就是字符集。什么意思呢,解释一下:也就是我们是将各种字符进行十进制编号,然后发给计算机,计算机把他从十进制转换成二进制然后存储下来。这套十进制的字符编号规则叫做字符集。为什么以十进制为标准呢,这也是在于我们人类的认知习惯,因为这个字符集都是人为定制的。
所以说:这几种写法都是表示某一个字符,
char c = 'a';//c变量代表a字符
常见字符集介绍
byte与char:
-
byte—字节,是基本数据类型中的一个,表示十进制整数,范围是【-128—127】。对应计算机底层是8个二进制位,规定这是计算机的最小存储单位,可以说是8个二进制位,也可以说是字节(byte)
所有的其他的数据类型,都是以byte为基础的。
-
char—字符,例如a,b, #,我,10,…。英文数字符号各国文字
计算机底层无法存储这些东西,只能存储二进制的数字,所以我们人为设置每一个字符对应一个十进制整数,然后计算机在存储时呢会先拿到字符,他就会根据设置的字符集找到十进制整数,然后把他转换成二进制存储。
然后!!!这个十进制数不可能说我们有10万个字符,我们就把这10万个字符对应0-100000数字吧,然后计算机再直接底层转换,可以是可以,但是这显得多捞哦,我们计算机的存储单元是啥呢???是个位数吗,大哥们,这个0-100000是我们现实世界的规则啊,十进制的。我们现在是在讨论计算机的世界啊,他最小只认字节啊,字节字节字节!!!!我们应该说10万个字符要用多少个字节存储,具体几个字节可以表示多少个字符,通过二进制计算,一个字节,8个二进制位,2^8=256个(这样看出,字节与十进制有着千丝万缕的联系),人为规定表示十进制范围【-128-127】,即一个字节可以表示256个字符,若该字符是由一个字节表示,则他对应的编码在【-128-127】中一个。若一个字符由两个字节表示,则是两个【-128-127】中的数字组成的数组。
例如:
'a'——97 //一个字节 '我'——[-26, -120, -111] //三个字节
// 这三个都是表示字符a,byte这里表示a的字符集编码
char a = 'a';
byte b = 'a'; //有类型转换
byte c = '98';

**ASCII字符集:**一个字符:一个字节
- ASCII(American Standard Code for Information Interchange,美国信息交换标准代码):包括了英文、数字、符号(没有中文哦)。
- ASCII使用1个字节存储一个字符,一个字节是8位(-128—127),总共可以表示128个字符信息**(英文数字都只取正数,其他字符集也是一样的)**用一个字节的原因在于英文数字符号,用一个字节完全够了!!!

GBK:
- window系统默认的码表。兼容ASCII码表,也包含了几万个汉字,并支持繁体汉字以及部分日韩文字。
- 英文、数字、符号还是按照ASCII的编码规则,一个字符一个字节,这只是对ASCII的一个补充。
- 注意:GBK是中国的码表,一个中文以两个字节表示的形式存储,并且均为负数编码,一个汉字对应两个十进制负数。但不包含世界上所有国家的文字。(16位)(一起可以表示65536/2=32768个中文,其实已经差不多够了)
- 我们打印出来看到的都是十进制撒,他只在计算机的底层为二进制表示,而底层我们是看不到的。
Unicode码表: GOOD
- unicode(又称统一码、万国码、单一码)是计算机科学领域里的一项业界字符编码标准。
- 容纳世界上大多数国家的所有常见文字和符号。
- 由于Unicode会先通过UTF-8,UTF-16,以及 UTF-32的编码成二进制后再存储到计算机,其中最为常见的就是UTF-8。
注意:
- Unicode是万国码,以UTF-8编码后一个中文一般以三个字节的形式存储。(完全够了,表示中国所有的汉字)
- UTF-8也要兼容ASCII编码表,统一规范撒,都是对ASCII的扩充。
- 技术人员都应该使用UTF-8的字符集编码。
- 编码前和编码后的字符集需要一致,否则会出现中文乱码。
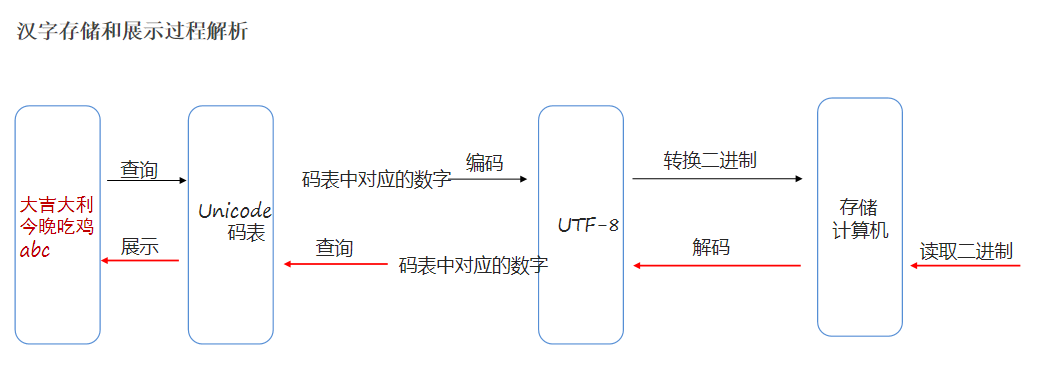
字符集的编码、解码操作
String编码
| 方法名称 | 说明 |
|---|---|
| byte[ ] getBytes( ) | 使用平台的默认字符集将该 String编码为一系列字节,将结果存储到新的字节数组中 |
| byte[ ] getBytes(String charsetName) | 使用指定的字符集将该 String编码为一系列字节,将结果存储到新的字节数组中 |
String解码
| 构造器 | 说明 |
|---|---|
| String(byte[ ] bytes) | 通过使用平台的默认字符集解码指定的字节数组来构造新的 String |
| String(byte[ ] bytes, String charsetName) | 通过指定的字符集解码指定的字节数组来构造新的 String |
String s = new String("我");
// 编码
byte[] bytes = s.getBytes(StandardCharsets.UTF_8);
System.out.println(Arrays.toString(bytes));
//解码
System.out.println(new String(bytes));
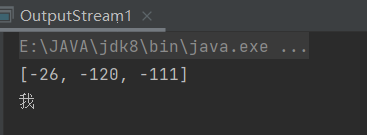
IO流
相对于内存而言的输入、输出流,就是用来读写数据的。
- I表示intput,是数据从硬盘文件读入到内存的过程,称之输入,负责读。
- O表示output,是内存程序的数据从内存到写出到硬盘文件的过程,称之输出,负责写。

IO流的分类体系
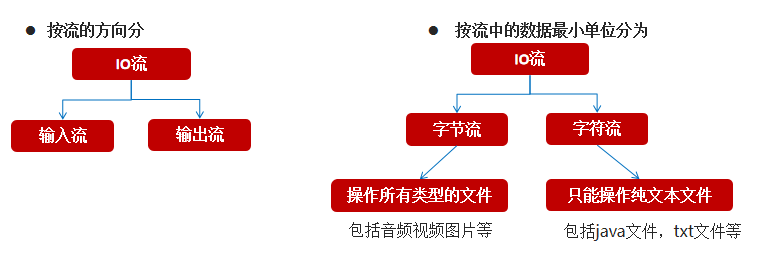
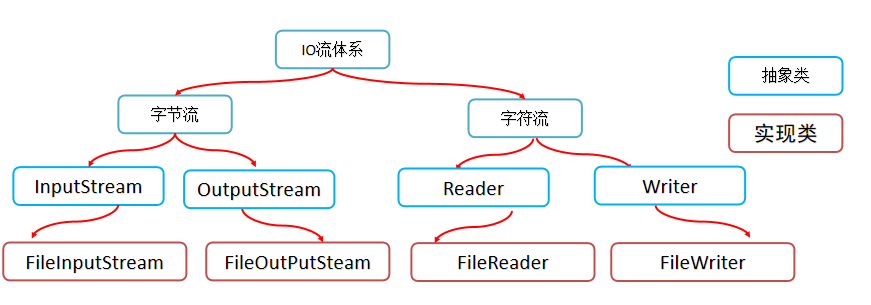
字节流
文件字节输入流FileInputStream
是InputStream的实现类
以内存为基准,把磁盘文件中的数据以字节的形式读取到内存中去。计算机的最小存储单位为字节byte,由8个二进制位组成,也叫8个bit
| 构造器 | 说明 |
|---|---|
| public FileInputStream(File file) | 参数:文件对象。创建字节输入流管道,使与源文件对象接通 |
| public FileInputStream(String pathName) | 参数:文件的绝对路径或相对路径。创建字节输入流管道,使与源文件路径接通 |
| 方法名称 | 说明 |
|---|---|
| public int read() | 读取一个字节并返回,如果字节已经没有可读的返回-1 |
| public int read(byte[ ] buffer) | 读取一个字节数组返回,如果字节已经没有可读的返回-1 |
每次读取一个字节
第一个方法public int read()

read方法也叫做水滴模型,一次只读一个字节数据返回. 他就只能正确读取英文数字和符号哦,对于中文无法正确读取!!!
-
性能较慢
-
读取中文字符输出无法避免乱码问题。
// abc.txt文本内容为 ab12我
public class FIleInputStream {
public static void main(String[] args) throws IOException {
InputStream inputStream = new FileInputStream("File-IO\\resource\\abc.txt");
// 读取一个字节返回(每次读取一滴水)
int b1 = inputStream.read();
System.out.println(b1 +""+(char) b1);
int b2 = inputStream.read();
System.out.println(b2 +""+(char) b2);
int b3 = inputStream.read();
System.out.println(b3 +""+(char) b3);
int b4 = inputStream.read();
System.out.println(b4 +""+(char) b4);
int b5 = inputStream.read();
System.out.println(b5 +""+(char) b5);
}
}
}
每次读取一个字节数组
第二个方法public int read(byte[ ] buffer)
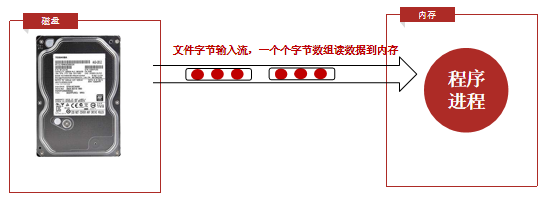
这个方法叫做水桶模型,不再是一滴滴去接
参数是一个字节数组,输入流会按照字节数组的大小去读取相应个数的字节,然后保存到这个数组里面,返回值为读取了的字节个数。
下面是一次读取三个字节。按照默认的字符集进行编码解码。buffer的原理在于,不断向这个数组里面替换读取的新的字节,把前一次的按照顺序替换。例如下面这个,第一次buffer读取的是abc—[97, 98, 99],第二次读取的就是,一个汉字爱—[-25, -120, -79],第三次读取的时候,只剩下两个字节cd,但buffer就会读取后为[99, 100, -79],只替换了前两个字节信息,第三个还在这里,就导致下面输出了一个乱码。
文件内容: abc爱cd
public class FileInputStream2 {
public static void main(String[] args) throws Exception {
InputStream inputStream = new FileInputStream("File-IO\\resource\\abc.txt");
byte[] buffer = new byte[3];//1kb--1024byte
int len = inputStream.read(buffer);
System.out.println("读取的字节个数:"+len);
System.out.print(Arrays.toString(buffer));
System.out.println(new String(buffer));
int len1 = inputStream.read(buffer);
System.out.println("读取的字节个数:"+len1);
System.out.print(Arrays.toString(buffer));
System.out.println(new String(buffer));
int len2 = inputStream.read(buffer);
System.out.println("读取的字节个数:"+len2);
System.out.print(Arrays.toString(buffer));
System.out.println(new String(buffer));
}
}
一次读完全部字节
1、如何使用字节输入流读取中文内容输出不乱码呢?
定义一个与文件一样大的字节数组,一次性读取完文件的全部字节。
2、直接把文件数据全部读取到一个字节数组可以避免乱码,是否存在问题?
如果文件过大,字节数组可能引起内存溢出。
官方为字节输入流InputStream提供了如下API可以直接把文件的全部数据读取到一个字节数组中。
| 方法名称 | 说明 |
|---|---|
| public byte[ ] readAllBytes() throws IOException | 直接将当前字节输入流对应的文件对象的字节数据装到一个字节数组返回 |
问题
无论怎么搞,用字节流读取文本数据,肯定会出现乱码问题,特别是对于中文字符,如果要完美解决乱码,就又会引起内存溢出的隐患。所以我们不用字节流进行文本数据的传输。
字节输出流FileOuputStream
是OutputStream的实现类。
以内存为基准,把内存中的数据以字节的形式写出到磁盘文件中去的流。
管道在进行数据的写出时,存在一个缓存区,所有的即将写入磁盘的数据会先进入这个缓存区。

| 构造器 | 说明 |
|---|---|
| public FileOutputStream(File file) | 创建字节输出流管道与源文件对象接通 |
| public FileOutputStream(File file,boolean append) | 创建字节输出流管道与源文件对象接通,可追加数据 |
| public FileOutputStream(String filepath) | 创建字节输出流管道与源文件路径接通,默认清空原文件数据 |
| public FileOutputStream(String filepath,boolean append) | 创建字节输出流管道,与源文件路径接通,true表示追加数据(即不清空源文件内容) |
写数据出去的API
| 写数据出去的方法名称 | 说明 |
|---|---|
| public void write( int a ) | 写一个字节出去 |
| public void write( byte[ ] buffer ) | 写一个字节数组出去 |
| public void write( byte[ ] buffer , int pos , int len ) | 写一个字节数组的一部分出去。这个是读多少倒多少的关键 |
流的关闭与刷新
| 方法 | 说明 |
|---|---|
| flush() | 刷新流,还可以继续写数据。在写完数据后一要刷新哦 |
| close() | 关闭流,释放内存资源,但是在关闭之前会先刷新流。一旦关闭,就不能再写数据 |
刷新的作用:将缓存区的所有数据全部写入到磁盘里面,一定要在写完之后调用这个方法,他会在应用进程结束前,先跑完之后刷新。
字节输出流实现写出去的数据能换行
os.write(“\r\n”.getBytes())
public class OutputStream1 {
public static void main(String[] args) throws Exception {
//1.创建时,会先清空之前的数据, append=true参数表示不清空原来数据,直接在后面追加
// OutputStream os = new FileOutputStream("File-IO\\resource\\abc.txt");
OutputStream os = new FileOutputStream("File-IO\\resource\\abc.txt",true);
//2.写一个字节出去
os.write('a');
os.write(98);
os.write("\r\n".getBytes(StandardCharsets.UTF_8));
//3.写一个字节数组出去
byte[] buffer = {'a','b',99};
byte[] buffer2 = "我是中国人".getBytes(StandardCharsets.UTF_8);
os.write(buffer);
os.write(buffer2);
os.write("\r\n".getBytes(StandardCharsets.UTF_8));
//4.写一个字节数组的一部分出去
byte[] buffer3 = {'a','b',99};
os.write(buffer3,0,2);
os.write("\r\n".getBytes(StandardCharsets.UTF_8));
os.close();
}
}
文件拷贝
字节流适合做一切文件数据的拷贝,因为任何文件的底层都是字节,拷贝是一字不漏的转移字节,只要前后文件格式、编码一致没有任何问题。
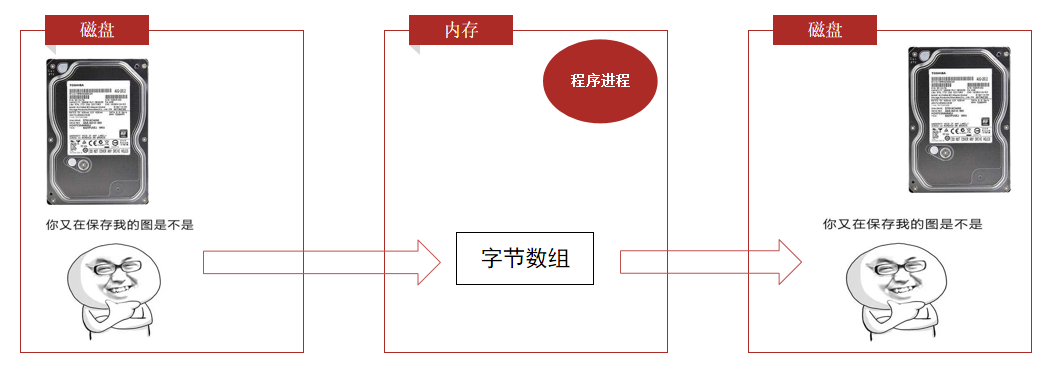
需求:把某个视频复制到其他目录下的“b.avi”
public class CopyFile {
public static void main(String[] args) throws Exception {
//1.输入流
InputStream is = new FileInputStream("C:\\Users\\Joker_Monster\\Desktop\\AlertRecord接口参数.md");
//2.输出流
OutputStream os = new FileOutputStream("File-IO\\resource\\copy.md");
//3.开始copy
byte[] buffer = new byte[1024];//1kb
int len;//记录每次读取的字节数
while((len = is.read(buffer))!=-1){
os.write(buffer,0,len);
}
System.out.println("复制完成");
//4. 关闭释放内存资源
is.close();
os.close();
}
}
资源释放的方式
try-catch-finally
finally:在异常处理时提供finally块来执行所有清除操作,比如说IO流中的释放资源
特点:被finally控制的语句最终一定会执行,除非JVM退出
异常处理标准格式:try….catch…finally
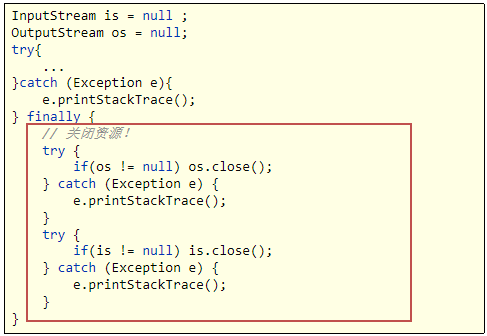
几个细节强调一下:
- finally代码块内部是无法访问is、os的,所以定义在前面
- finally块里面需要判断is、os不为空,再进行关闭。因为怕我的try块里面还没有来得及给is、os赋值,就出现了异常,那完美对is、os的关闭就会出bug
try-with-resource
- finally虽然可以用于释放资源,但是释放资源的代码过于繁琐?
- 有没有办法简化?

一般我们还是用JDK7的方案,好理解逻辑性强
public class TryCatchResouceDemo2 {
public static void main(String[] args) {
try (
// 这里面只能放置资源对象,用完会自动关闭:自动调用资源对象的close方法关闭资源(即使出现异常也会做关闭操作)
// 1、创建一个字节输入流管道与原视频接通
InputStream is = new FileInputStream("file-io-app/src/out04.txt");
// 2、创建一个字节输出流管道与目标文件接通
OutputStream os = new FileOutputStream("file-io-app/src/out05.txt");
// int age = 23; // 这里只能放资源
MyConnection connection = new MyConnection();
// 最终会自动调用资源的close方法
) {
// 3、定义一个字节数组转移数据
byte[] buffer = new byte[1024];
int len; // 记录每次读取的字节数。
while ((len = is.read(buffer)) != -1){
os.write(buffer, 0 , len);
}
System.out.println("复制完成了!");
} catch (Exception e){
e.printStackTrace();
}
}
}
class MyConnection implements AutoCloseable{
@Override
public void close() throws IOException {
System.out.println("连接资源被成功释放了!");
}
}

字符流
-
字节流读取中文输出会存在什么问题?
会乱码。或者内存溢出。
-
读取中文输出,哪个流更合适,为什么?
字符流更合适,最小单位是按照单个字符读取的。
文件字符输入流
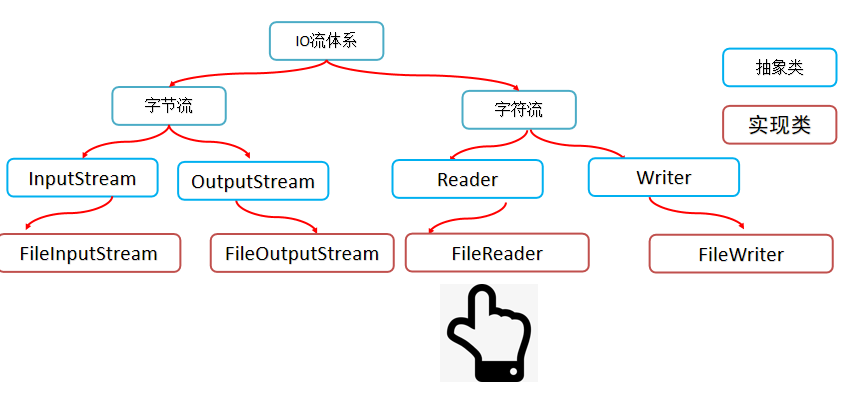
以内存为基准,把磁盘文件中的数据以字符的形式读取到内存中去。
| 构造器 | 说明 |
|---|---|
| public FileReader(File file) | 创建字符输入流管道与源文件对象接通 |
| public FileReader(String pathname) | 创建字符输入流管道与源文件路径接通 |
| 方法名称 | 说明 |
|---|---|
| public int read() | 每次读取一个字符返回,如果字符已经没有可读的返回-1 |
| public int read(char[] buffer) | 每次读取一个字符数组,返回读取的字符个数,如果字符已经没有可读的返回-1 |
每次读取一个字符
| 方法名称 | 说明 |
|---|---|
| public int read() | 每次读取一个字符返回,如果字符已经没有可读的返回-1 |
public class FileReaderdemo1 {
public static void main(String[] args) throws Exception {
//1.
Reader fr = new FileReader("F:\\Java_Project\\JavaSE\\File-IO\\resource\\abc.txt");
//2.
int code;
while ((code=fr.read())!=-1){
System.out.print((char) code);
}
}
}
这里注意:不要输出的时候换行!!!因为文本内容存在换行了,我们直接输出就行了
每次读取一个字符组
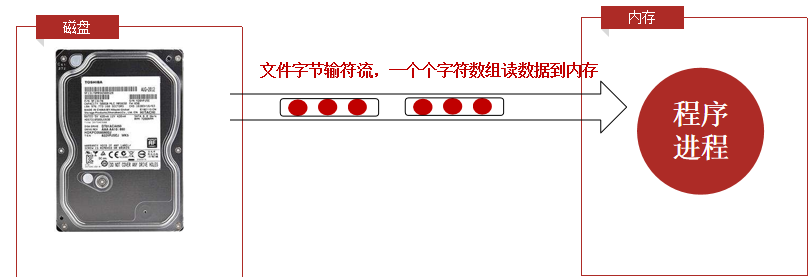
| 方法名称 | 说明 |
|---|---|
| public int read(char[] buffer) | 每次读取一个字符数组,返回读取的字符数,如果字符已经没有可读的返回-1 |
这个水桶的更新和前面的字节输入流的原理是一样的,我们在进行输出时一定要遵循读多少倒多少的原则,否则就乱套了。
public class FileReaderdemo1 {
public static void main(String[] args) throws Exception {
//1.
Reader fr = new FileReader("F:\\Java_Project\\JavaSE\\File-IO\\resource\\abc.txt");
//2.准备水桶
char[] buffer = new char[10];
int len;
while ((len = fr.read(buffer))!=-1){
// 读多少倒多少
String s = new String(buffer, 0, len);
System.out.print(s);
}
}
}
文件字符输出流
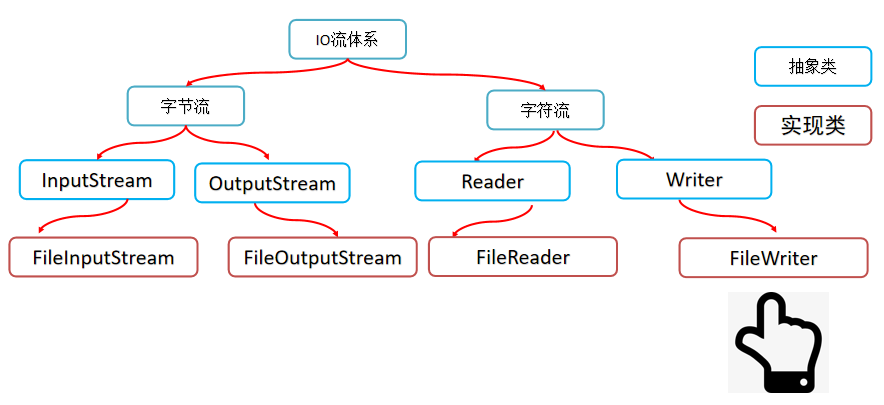
以内存为基准,把内存中的数据以字符的形式写出到磁盘文件中去的流。
| 构造器 | 说明 |
|---|---|
| public FileWriter(File file) | 创建字符输出流管道与源文件对象接通 |
| public FileWriter(File file,boolean append) | 创建字符输出流管道与源文件对象接通,可追加数据 |
| public FileWriter(String filepath) | 创建字符输出流管道与源文件路径接通 |
| public FileWriter(String filepath,boolean append) | 创建字符输出流管道与源文件路径接通,可追加数据 |
文件字符输出流(FileWriter)写数据出去的API
| 方法名称 | 说明 |
|---|---|
| void write(int c) | 写一个字符 |
| void write(char[] cbuf) | 写入一个字符数组 |
| void write(char[] cbuf, int off, int len) | 写入字符数组的一部分 |
| void write(String str) | 写一个字符串 |
| void write(String str, int off, int len) | 写一个字符串的一部分 |
| void write(int c) | 写一个字符 |
流的关闭与刷新
| 方法 | 说明 |
|---|---|
| flush() | 刷新流,还可以继续写数据 |
| close() | 关闭流,释放资源,但是在关闭之前会先刷新流。一旦关闭,就不能再写数据 |
字符输出流实现写出去的数据能换行
fw.write(“\r\n”);
public class FileWriterdemo1 {
public static void main(String[] args) throws IOException {
Writer fw = new FileWriter("F:\\Java_Project\\JavaSE\\File-IO\\resource\\abc.txt");
fw.write(98);
fw.write("\r\n");
fw.write("abcdefgh");
fw.write("\r\n");
fw.write(new char[]{'我','是'});
fw.write("\r\n");
fw.close();
}
}
IO流进阶

缓冲流
缓冲流也称为高效流、或者高级流。之前学习的字节流可以称为原始流。
作用:缓冲流自带缓冲区、可以提高原始字节流、字符流读写数据的性能
他们之间的效率对比如下:我们程序中读取的数据都是从内存里面,而不是磁盘,要明白内存的读取速度远远大于磁盘。


缓冲流的体系如下,就是在前面的原始流的基础上进行增强!!!都是对同一个接口进行实现。
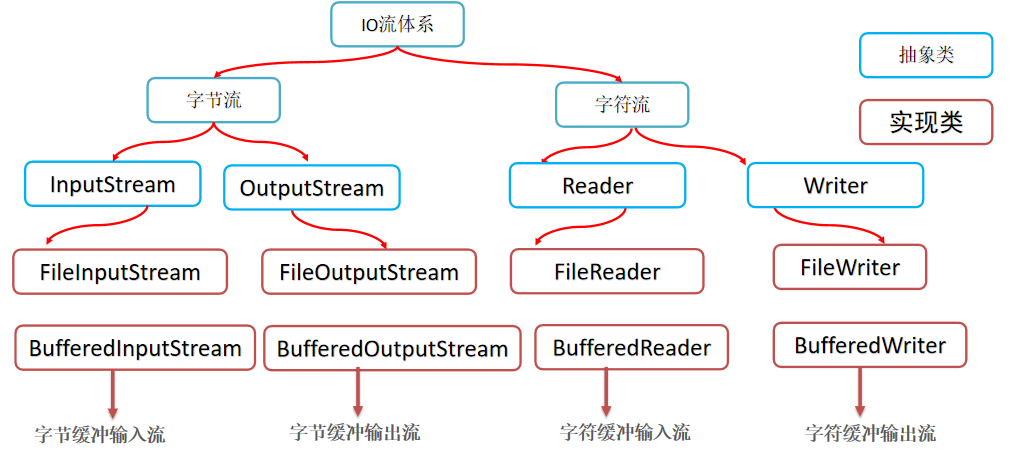
字节缓冲流
字节缓冲流性能优化原理:
- 字节缓冲输入流、输出流均自带了默认8KB缓冲池,以后我们直接从缓冲池读取数据,以及直接写数据到缓冲池,所以性能较好。这个8kb的缓冲池类似于我们之前写的一个这个水桶,字节数组!!!
字节缓冲输入流:BufferedInputStream,字节缓冲输出流:BufferedOutputStream,
都只是提高字节输出流读取数据的性能,读写功能上并无变化,因为和前面的原始流都是实现的同一个接口。
注意需要先定义出来原始流,然后再将他包装一下成为高级流
| 构造器 | 说明 |
|---|---|
| public BufferedInputStream ( InputStream is ) | 可以把低级的字节输入流包装成一个高级的缓冲字节输入流管道,从而提高字节输入流读数据的性能 |
| public BufferedOutputStream ( OutputStream os ) | 可以把低级的字节输出流包装成一个高级的缓冲字节输出流,从而提高写数据的性能 |
这里采用了JDK7关闭管道资源的写法,不用手动关闭。
//1.包装缓冲输入流
InputStream is = new FileInputStream("C:\\Users\\Joker_Monster\\Desktop\\AlertRecord接口参数.md");
InputStream bufferIs = new BufferedInputStream(is);
//2.包装缓冲输出流
OutputStream os = new FileOutputStream("File-IO\\resource\\copy.md");
OutputStream bufferos = new BufferedOutputStream(os);
重写文件复制的例子:
public class BufferDemo {
public static void main(String[] args) throws Exception {
try (
//1.包装缓冲输入流
InputStream is = new FileInputStream("C:\\Users\\Joker_Monster\\Desktop\\AlertRecord接口参数.md");
InputStream bufferIs = new BufferedInputStream(is);
//2.包装缓冲输出流
OutputStream os = new FileOutputStream("File-IO\\resource\\copy.md");
OutputStream bufferos = new BufferedOutputStream(os);
) {
//3.开始copy
byte[] buffer = new byte[1024];//1kb
int len;//记录每次读取的字节数
while ((len = bufferIs.read(buffer)) != -1) {
bufferos.write(buffer, 0, len);
}
System.out.println("复制完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}
字节缓冲流的性能分析
建议使用字节缓冲输入流、字节缓冲输出流,结合字节数组的方式,目前来看是性能最优的组合。
我们通过一个例子观察性能情况:分别使用低级字节流和高级字节缓冲流拷贝大视频,记录耗时。
采用四种方式完成复制:
- 使用低级的字节流按照一个一个字节的形式复制文件。
- 使用低级的字节流按照一个一个字节数组的形式复制文件。
- 使用高级的缓冲字节流按照一个一个字节的形式复制文件。
- 使用高级的缓冲字节流按照一个一个字节数组的形式复制文件。
public class BufferTimeDemo {
private static final String SRC_FILE = "F:\\视频剪辑\\3.mp4";
private static final String TARGET_FILE = "File-IO\\resource\\";
public static void main(String[] args) {
// copy();//224s
// bufferCopy();//0.319s
// copy2();//0.296s
// bufferCopy2();//0.062s
}
/**
* 原始流一个个字节复制
*/
public static void copy(){
long startTime = System.currentTimeMillis();
try(
InputStream is = new FileInputStream(SRC_FILE);
OutputStream os = new FileOutputStream(TARGET_FILE+"copy.mp4");
){
int read;
while ((read = is.read())!=-1){
os.write(read);
}
}catch (Exception e){
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println("copy花费了:"+(startTime-endTime)/1000+"s");
}
/**
* 缓冲流一个个字节复制
*/
public static void bufferCopy(){
long startTime = System.currentTimeMillis();
try (
InputStream is = new FileInputStream(SRC_FILE);
InputStream bufferIs = new BufferedInputStream(is);
OutputStream os = new FileOutputStream(TARGET_FILE+"bufferCopy.mp4");
OutputStream bufferOS = new BufferedOutputStream(os);
){
int read;
while ((read = bufferIs.read())!=-1){
bufferOS.write(read);
}
}catch (Exception e){
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println("bufferCopy花费了:"+(startTime-endTime)/1000.0+"s");
}
/**
* 原始流按字节数组复制
*/
public static void copy2(){
long startTime = System.currentTimeMillis();
try (
InputStream is = new FileInputStream(SRC_FILE);
OutputStream os = new FileOutputStream(TARGET_FILE+"copy2.mp4");
){
byte[] buffer = new byte[1024];
int len;
while ((len = is.read(buffer))!=-1){
os.write(buffer,0,len);
}
}catch (Exception e){
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println("copy2花费了:"+(startTime-endTime)/1000.0+"s");
}
/**
* 高级流按字节数组复制
*/
public static void bufferCopy2(){
long startTime = System.currentTimeMillis();
try (
InputStream is = new FileInputStream(SRC_FILE);
InputStream bufferIs = new BufferedInputStream(is);
OutputStream os = new FileOutputStream(TARGET_FILE+"bufferCopy2.mp4");
OutputStream bufferOS = new BufferedOutputStream(os);
){
byte[] buffer = new byte[1024];
int len;
while ((len = bufferIs.read(buffer))!=-1){
bufferOS.write(buffer,0,len);
}
}catch (Exception e){
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println("bufferCopy2花费了:"+(startTime-endTime)/1000.0+"s");
}
}
字符缓冲流
与前面的字节缓冲流是一样的用法,先要构建出原始流,然后进行包装。
BufferedReader
字符缓冲输入流:BufferedReader。
作用:提高字符输入流读取数据的性能,除此之外多了按照行读取数据的功能。
注意哦,因为BufferedReader实现类多了一个新的功能,所以说不能用多态的写法!!
| 构造器 | 说明 |
|---|---|
| public BufferedReader(Reader r) | 可以把低级的字符输入流包装成一个高级的缓冲字符输入流管道,从而提高字符输入流读数据的性能 |
字符缓冲输入流新增功能
| 方法 | 说明 |
|---|---|
| public String readLine( ) | 读取一行数据返回,如果读取没有完毕,无行可读返回null |
注意这里是返回的一个字符串,并不会读取到换行符,所以我们需要自己换行。
public class BufferReaderDemo {
public static void main(String[] args) {
try (
Reader fr = new FileReader("F:\\Java_Project\\JavaSE\\File-IO\\resource\\abc.txt");
BufferedReader bufferReader = new BufferedReader(fr);
){
String line;
while (( line= bufferReader.readLine())!=null){
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
####BufferedWriter
字符缓冲输出流:BufferedWriter。
作用:提高字符输出流写取数据的性能,除此之外多了换行功能。
注意哦,因为BufferedWriter实现类多了一个新的功能,所以说不能用多态的写法!!
| 构造器 | 说明 |
|---|---|
| public BufferedWriter(Writer w) | 可以把低级的字符输出流包装成一个高级的缓冲字符输出流管道,从而提高字符输出流写数据的性能 |
字符缓冲输出流新增换行功能
| 方法 | 说明 |
|---|---|
| public void newLine() | 换行操作 |
public class BufferedWriterDemo {
public static void main(String[] args) {
try (
Writer fw = new FileWriter("File-IO\\resource\\abc.txt");
BufferedWriter bufferedWriter = new BufferedWriter(fw);
) {
bufferedWriter.write(98);
bufferedWriter.newLine();
bufferedWriter.write("iuwekhasdjah");
bufferedWriter.newLine();
bufferedWriter.write(new char[]{'我', '是'});
} catch (IOException e) {
e.printStackTrace();
}
}
}
案例(比较器的灵活使用)
把《出师表》的文章顺序进行恢复到一个新文件中。
原来顺序:

public class BufferedCharTest {
public static void main(String[] args) {
try (
BufferedReader br = new BufferedReader(new FileReader("F:\\Java_Project\\JavaSE\\File-IO\\resource\\csb.txt"));
BufferedWriter bw = new BufferedWriter(new FileWriter("F:\\Java_Project\\JavaSE\\File-IO\\resource\\new.txt"));
) {
//1.定义存放每一行文字的集合
List<String> data = new ArrayList<>();
//2.按照行读取,存放到集合中
String line;
while ((line = br.readLine())!=null){
data.add(line);
}
//3.自定义排序规则
List<String> sizes = new ArrayList<>();
Collections.addAll(sizes, "一","二","三","四","五","陆","柒","八","九","十","十一");
// 其中每个索引在集合中的位置代表了他的大小!!
Collections.sort(data, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return sizes.indexOf(o1.substring(0,o1.indexOf(".")))
-sizes.indexOf(o2.substring(0,o2.indexOf(".")));
}
});
System.out.println(data);
for (String datum : data) {
bw.write(datum);
bw.newLine();
}
} catch (Exception e) {
e.printStackTrace();
}
转换流
前面讲过:字符流直接读取文本内容,文件编码和读取的编码必须一致才不会乱码!!!
我们的代码基本上都是UTF-8的,但文本内容就不一定,也可能是其他编码,这样直接采用Reader流进行读取就有问题。
转换流就是用来解决这个问题的,在代码字符集与文本字符集不一致时,正确读取文本内容到内存
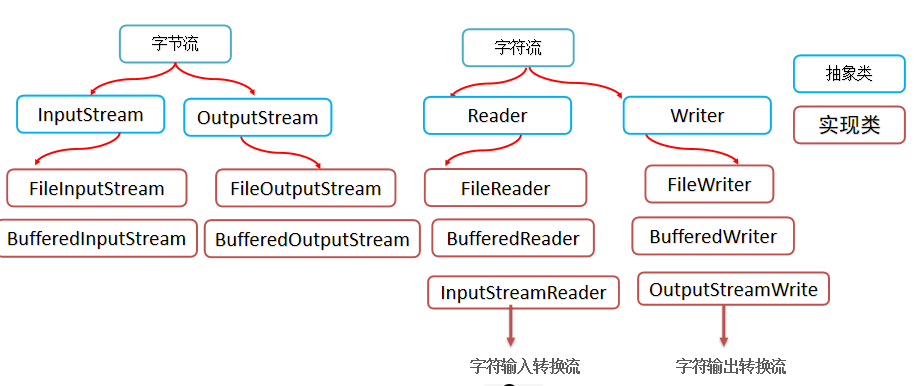
字符输入转换流
字符输入转换流:InputStreamReader,可以把原始的字节流按照指定编码转换成字符输入流。
| 构造器 | 说明 |
|---|---|
| public InputStreamReader(InputStream is) | 可以把原始的字节流按照代码默认编码转换成字符输入流。几乎不用,与默认的FileReader一样。 |
| public InputStreamReader(InputStream is ,String charset) | 可以把原始的字节流按照指定编码转换成字符输入流,这样字符流中的字符就不乱码了 |
注意哦:这个字符输入转换流的参数是字节输入流
首先这个原始字节流大家都是一样的,不管什么编码什么玩意的,同一个文件读取进来就是相同的。然后情形是这样的,我有一个GBK编码的文本文件txt,我需要把他读进来,而IDEA默认字符集是UTF-8的。我们先拿到文件的原始字节流InputStream,然后用InputStreamReader指定编码格式为GBK,他就会以指定的GBK编码转换成字符输入流 。
这样我们读取到内存中的数据就没有乱码,对不对!!!记住一句话,只要读取进来不乱码,后面怎么折腾都不会乱码!!,虽然我们按照GBK读取的,但我们后面使用IDEA进行输出啊什么的,都是用UTF-8,没有任何问题。
public class BufferReaderDemo {
public static void main(String[] args) {
try (
InputStream is = new FileInputStream("C:\\Users\\Joker_Monster\\Desktop\\学习资料\\JavaSE资料\\day20、IO流二\\代码\\io-app2\\src\\csb.txt");
Reader reader = new InputStreamReader(is,"GBK");
BufferedReader bufferReader = new BufferedReader(reader);
){
String line;
while (( line= bufferReader.readLine())!=null){
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
字符输出转换流
解决问题:将写出去的字符按照指定编码格式。
前面说过一种方式:把字符以指定编码获取字节后再使用字节输出流写出去:“我爱你中国”.getBytes(编码),太麻烦不好用!
OutputStreamWriter,可以把字节输出流按照指定编码转换成字符输出流
| 构造器 | 说明 |
|---|---|
| public OutputStreamWriter(OutputStream os) | 可以把原始的字节输出流按照代码默认编码转换成字符输出流。几乎不用。 |
| public OutputStreamWriter**(OutputStream os,String charset)** | 可以把原始的字节输出流按照指定编码转换成字符输出流(重点) |
注意哦:这个字符输出转换流的参数是字节输出流
public class OutputStreamWriterd {
public static void main(String[] args) {
try (
OutputStream os = new FileOutputStream("File-IO\\resource\\abc.txt");
Writer osw = new OutputStreamWriter(os, "GBK");
BufferedWriter bw = new BufferedWriter(osw);
) {
bw.write("我是中国人!!!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
序列化对象
序列化对象:实现了序列化接口的对象
public class Student implements Serializable {
// 申明序列化的版本号码
// 序列化的版本号与反序列化的版本号必须一致才不会出错!
private static final long serialVersionUID = 1;
private String name;
private String loginName;
// transient修饰的成员变量不参与序列化,用于敏感信息,因为写入文件的东西有被盗风险
private transient String passWord;
private int age;
.............
}
接下来的两个流用到的两个实现类如下,都是字节流下的
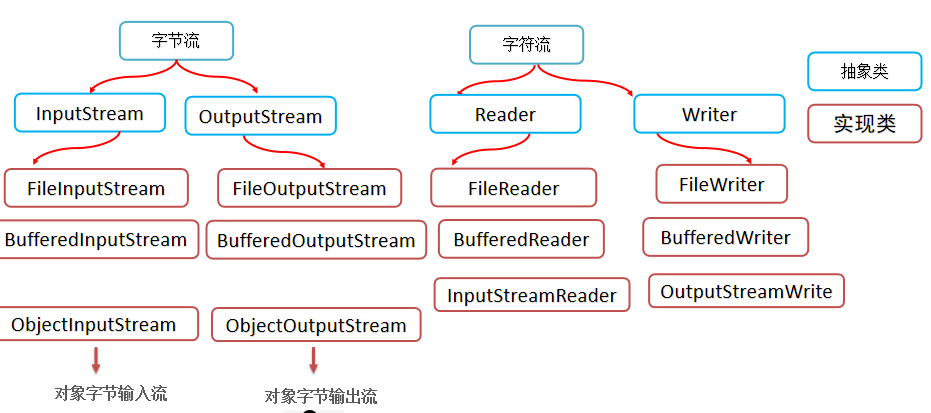
对象序列化
作用:以内存为基准,把内存中的对象存储到磁盘文件中去,称为对象序列化。
使用到的流是对象字节输出流:ObjectOutputStream

| 构造器 | 说明 |
|---|---|
| public ObjectOutputStream(OutputStream out) | 把低级字节输出流包装成高级的对象字节输出流 |
| 方法名称 | 说明 |
|---|---|
| public final void writeObject(Object obj) | 把对象写出去到对象序列化流的文件中去 |
而这个可以被写出的对象必须实现序列化接口——这种对象被称为序列化对象
public class Serializable {
public static void main(String[] args) {
try (
//2.
ObjectOutputStream objectOutputStream =
new ObjectOutputStream(new FileOutputStream("File-IO\\resource\\abc.txt"));
) {
//1.
Student student = new Student("陈磊", "chenlei", "123", 22);
//3.
objectOutputStream.writeObject(student);
} catch (IOException e) {
e.printStackTrace();
}
}
}
然后我们打开文件,发现好像是乱码???

其实不是乱码,你看我们自己写的文字都显示出来了,而是这个写出的内容不是给我们看的,是给计算机的,方便以后可以从里面拿取序列化对象数据。
对象反序列化
ObjectInputStream,以内存为基准,把存储到磁盘文件中去的对象数据恢复成内存中的对象,称为对象反序列化。
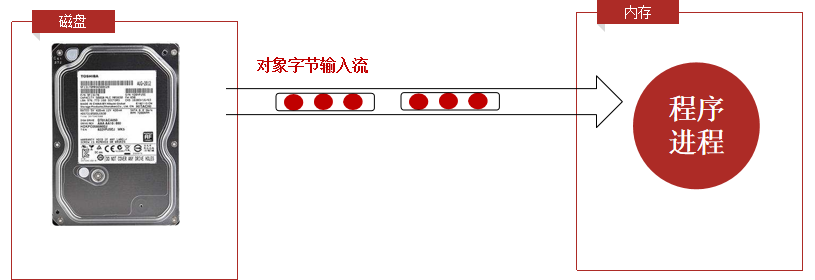
| 构造器 | 说明 |
|---|---|
| public ObjectInputStream(InputStream out) | 把低级字节输如流包装成高级的对象字节输入流 |
| 方法名称 | 说明 |
|---|---|
| public Object readObject( ) | 把存储到磁盘文件中去的对象数据恢复成内存中的对象返回。 |
public class Serializable {
public static void main(String[] args) {
try (
ObjectInputStream objectInputStream =
new ObjectInputStream(new FileInputStream("File-IO\\resource\\abc.txt"))
) {
Student s = (Student) objectInputStream.readObject();
System.out.println(s);
} catch (Exception e) {
e.printStackTrace();
}
}
}
打印流
作用:打印流可以实现方便、高效的打印数据到文件中去。打印流一般是指:PrintStream,PrintWriter两个类。
可以实现打印什么数据就是什么数据,例如打印整数97写出去就是97,打印boolean的true,写出去就是true。
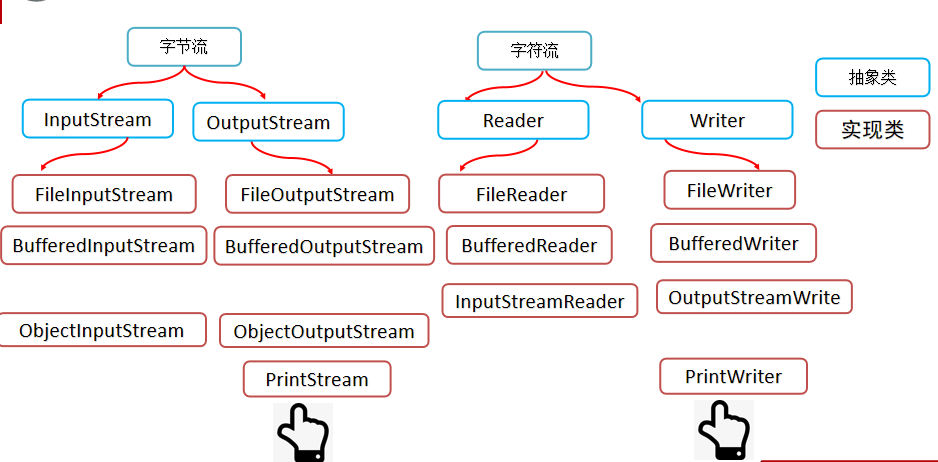
PrintStream和PrintWriter的区别:
- 打印数据功能上是一模一样的,都是使用方便,性能高效(核心优势)
- PrintStream继承自字节输出流OutputStream,支持写字节数据write()的方法。基本不用,
- PrintWriter继承自字符输出流Writer,支持写字符数据write()出去。基本不用
PrintStream
超级多的构造器,满足你的一切打印需求。还有很多在参考文档里面。但没有设置追加的构造器,如果要实现追加,需要对低级流进行包装即可
PrintStream ps = new PrintStream(new FileOutputStream("File-IO\\resource\\abc.txt",true));
| 构造器 | 说明 |
|---|---|
| public PrintStream(OutputStream os) | 打印流直接通向字节输出流管道 |
| public PrintStream(File f) | 打印流直接通向文件对象 |
| public PrintStream**(String fileName, Charset charset)** | 打印流直接通向文件路径,可以指定编码格式 |
| 方法 | 说明 |
|---|---|
| public void print(Xxx xx) | 打印任意类型的数据出去 |
public class PrintStreamdemo {
public static void main(String[] args) {
try(
PrintStream ps = new PrintStream("File-IO\\resource\\abc.txt");
// 实现追加数据
PrintStream ps = new PrintStream(new FileOutputStream("File-IO\\resource\\abc.txt",true));
) {
ps.println(9898);
ps.println("我是中国人");
ps.println(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
PrintWriter
超级多的构造器,满足你的一切打印需求。还有很多在参考文档里面。但没有设置追加的构造器,如果要实现追加,需要对低级流进行包装即可
| 构造器 | 说明 |
|---|---|
| public PrintWriter(OutputStream os) | 打印流直接通向字节输出流管道 |
| public PrintWriter (Writer w) | 打印流直接通向字符输出流管道 |
| public PrintWriter (File f) | 打印流直接通向文件对象 |
| public PrintWriter (String filepath) | 打印流直接通向文件路径 |
| 方法 | 说明 |
|---|---|
| public void print(Xxx xx) | 打印任意类型的数据出去 |
输出语句重新定向
属于打印流的一种应用,可以把输出语句的打印位置从控制台改到文件。
卧槽,原来我们之间写的System.out.println();一直都是打印流,只是系统打印流打印的东西默认放在控制台,并且我们可以人为改变输出位置。6666666
public class PrintDemo2 {
public static void main(String[] args) throws Exception {
System.out.println("锦瑟无端五十弦");
System.out.println("一弦一柱思华年");
// 改变输出语句的位置(重定向)
PrintStream ps = new PrintStream("io-app2/src/log.txt");
System.setOut(ps); // 把系统打印流改成我们自己的打印流
System.out.println("庄生晓梦迷蝴蝶");
System.out.println("望帝春心托杜鹃");
}
}
补充知识:Properties
不属于IO流的东西,但需要结合IO流。他是一个MAP集合,omg。但注意key:value都是字符串。
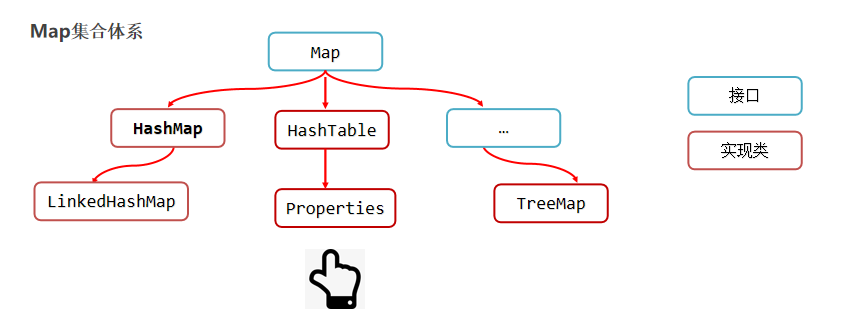 、
、
Properties属性集对象
- 其实就是一个Map集合,但是我们一般不会当集合使用,因为HashMap更好用。
Properties核心作用:
- Properties代表的是一个属性文件,可以把自己对象中的键值对信息存入到一个属性文件中去。
- 属性文件:后缀是.properties结尾的文件,里面的内容都是 key=value,后续做系统配置信息的。
大家在后期学的很多大型框架技术中,属性文件都是很重要的系统配置文件。
我们需要掌握的两点就是:一、如何往配置文件里面写数据;二、如何从配置文件中读取数据。
Properties和IO流结合的方法:
| 方法 | 说明 |
|---|---|
| void load(InputStream inStream) | 从输入字节流读取属性列表(键和元素对) |
| void load(Reader reader) | 从输入字符流读取属性列表(键和元素对) |
| void store(OutputStream out, String comments) | 将此属性列表(键和元素对)写入此 Properties表中,以适合于使用 load(InputStream)方法的格式写入输出字节流 |
| void store(Writer writer, String comments) | 将此属性列表(键和元素对)写入此 Properties表中,以适合使用 load(Reader)方法的格式写入输出字符流 |
| public Object setProperty(String key, String value) | 保存键值对(put) |
| public String getProperty(String key) | 使用此属性列表中指定的键搜索属性值 (get) |
| public Set stringPropertyNames() | 所有键的名称的集合 (keySet()) |
public class PropertiesDemo01 {
public static void main(String[] args) throws Exception {
// 需求:使用Properties把键值对信息存入到属性文件中去。
Properties properties = new Properties();
properties.setProperty("admin", "123456");
properties.setProperty("dlei", "003197");
properties.setProperty("heima", "itcast");
System.out.println(properties);
/**
参数一:保存管道 字符输出流管道
参数二:保存心得
*/
properties.store(new FileWriter("io-app2/src/users.properties"), "this is users!! i am very happy!");
}
}
public class PropertiesDemo02 {
public static void main(String[] args) throws Exception {
// 需求:Properties读取属性文件中的键值对信息。(读取)
Properties properties = new Properties();
System.out.println(properties);
// 加载属性文件中的键值对数据到属性对象properties中去
properties.load(new FileReader("io-app2/src/users.properties"));
System.out.println(properties);
String rs = properties.getProperty("dlei");
System.out.println(rs);
String rs1 = properties.getProperty("admin");
System.out.println(rs1);
}
}
补充知识:IO框架
- commons-io是apache开源基金组织提供的一组有关IO操作的类库,可以提高IO功能开发的效率。
- commons-io工具包提供了很多有关io操作的类。有两个主要的类FileUtils, IOUtils
FileUtils主要有如下方法:
| 方法名 | 说明 |
|---|---|
| String readFileToString(File file, String encoding) | 读取文件中的数据, 返回字符串 |
| void copyFile(File srcFile, File destFile) | 复制文件。 |
| void copyDirectoryToDirectory(File srcDir, File destDir) | 复制文件夹。 |
线程
概述
- 线程(thread)是一个程序内部的一条执行路径。
- 我们之前启动程序执行后,main方法的执行其实就是一条单独的执行路径
public static void main(String[] args) {
// 代码…
for (int i = 0; i < 10; i++) {
System.out.println(i);
}
// 代码...
}
- 程序中如果只有一条执行路径,那么这个程序就是单线程的程序。

多线程创建
Thread类
-
Java是通过java.lang.Thread 类来代表线程的。
-
按照面向对象的思想,Thread类应该提供了实现多线程的方式。
方式一:继承Thread类
-
定义一个子类MyThread继承线程类java.lang.Thread,重写run()方法
-
创建MyThread类的对象
-
调用线程对象的start( )方法启动线程(启动后会执行run方法的)要放在主线程之前哦
**优点:**编码简单
**缺点:**线程类已经继承Thread,无法继承其他类,不利于扩展,无返回值。void方法
public class demo1 {
public static void main(String[] args) {
//2. 创建线程的对象
Thread mythread = new Mythread();
//3. 调用启动该线程的方法
mythread.start();
for (int i = 0; i < 5; i++) {
System.out.println("主线程在输出");
}
}
}
/**
1. 定义线程类,一般单独起一个类,这里为了方便就算了
*/
class Mythread extends Thread{
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println("子线程在输出");
}
}
}
1、为什么不直接调用了run方法,而是调用start启动线程。
直接调用run方法会当成普通方法执行,此时相当于还是单线程执行。只有调用start方法才是启动一个新的线程执行。
2、把主线程任务放在子线程之前了。
这样主线程一直是先跑完的,相当于是一个单线程的效果了。
方式二:Runnable任务对象
函数式接口
- 定义一个线程任务类MyRunnable实现Runnable接口,重写run()方法
- 创建MyRunnable任务对象
- 把MyRunnable任务对象交给Thread处理。
- 调用线程对象的start()方法启动线程
**优点:**线程任务类只是实现接口,可以继续继承类和实现接口,扩展性强。
**缺点:**编程多一层对象包装,如果线程有执行结果不可以直接返回的。是void方法
Thread创建方式
| 构造器 | 说明 |
|---|---|
| public Thread(String name) | 可以为当前线程指定名称 |
| public Thread(Runnable target) | 封装Runnable对象成为线程对象 |
| public Thread(Runnable target ,String name ) | 封装Runnable对象成为线程对象,并指定线程名称 |
public class demo2 {
public static void main(String[] args) {
Runnable myRunnable = new MyRunnable();
Thread t = new Thread(myRunnable, "新的线程名字");
t.start();
for (int i = 0; i < 5; i++) {
System.out.println("=======主线程");
}
}
}
class MyRunnable implements Runnable{
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println("子线程=====");
}
}
}
/**
* Lambada 化简上面代码
*/
public class demo3 {
public static void main(String[] args) {
// 1. 子线程
// Lamba化简一
Runnable Myrun1 = () ->{
for (int i = 0; i < 5; i++) {
System.out.println("子线程=====");
}
};
Thread t1 = new Thread(Myrun1, "新的线程名字");
t1.start();
// Lamba化简二
Thread t2 = new Thread(()->{
for (int i = 0; i < 5; i++) {
System.out.println("子线程=====");
}
}, "新的线程名字");
t2.start();
// 2. 主线程
for (int i = 0; i < 5; i++) {
System.out.println("=======主线程");
}
}
}
方式三:Callable任务对象
解决了前面两种无法得到返回值的问题,即我们是需要得到线程执行完之后的结果的。
Callable——泛型的函数式接口;FutureTask——泛型接口,他实现了记住要声明返回值的类型哦
-
得到任务对象
-
新定义一个类 实现Callable接口,重写call方法,封装要做的事情。
-
用FutureTask把Callable对象封装成FutureTask对象。
-
-
把线程任务对象交给Thread处理。
-
调用Thread的start方法启动线程,执行任务
-
线程执行完毕后、通过FutureTask的get方法去获取任务执行的结果。
FutureTask 的 API
| 方法名称 | 说明 |
|---|---|
| public FutureTask<>(Callable call) | 把Callable对象封装成FutureTask对象。 |
| public V get() throws Exception | 获取线程执行call方法返回的结果。 |
public class demo4 {
public static void main(String[] args) {
//3. 创建callable的任务对象
Callable<String> mycall = new MyCall(10);
//4. 把callable任务对象交给 FutureTask对象
// FutureTask对象的作用1: 是Runnable的对象(实现了Runnable接口),可以交给Thread了
// FutureTask对象的作用2: 可以在线程执行完毕之后通过调用其get方法得到线程执行完成的结果
FutureTask<String> f1 = new FutureTask<>(mycall);
// 5. 交给线程处理
Thread t1 = new Thread(f1);
t1.start();
// 6. 用FutureTask拿去线程执行完毕的结果
try {
String result = f1.get();
System.out.println(result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
/**
* 1. 定义一个任务类,实现Callable接口,并且声明返回值的类型哦
*/
class MyCall implements Callable<String>{
private int n;
public Mythread4(int n) {
this.n = n;
}
// 2. 重写call()方法
@Override
public String call() throws Exception {
int sum=0;
for (int i = 0; i < n; i++) {
sum = sum+i;
}
return "子线程的结果:"+sum;
}
}
Thread-API
| 方法名称 | 说明 |
|---|---|
| String getName() | 获取当前线程的名称,默认线程名称是Thread-索引 |
| void setName(String name) | 将此线程的名称更改为指定的名称,通过构造器也可以设置线程名称 |
| public static Thread currentThread() | 返回对当前正在执行的线程对象的引用 |
| public static void sleep(long time) | 让当前线程休眠指定的时间后再继续执行,单位为毫秒。 |
| public void run() | 线程任务方法(被重写的方法) |
| public void start() | 线程启动方法 |
对于第三个方法:
- 此方法是Thread类的静态方法,可以直接使用Thread类调用。
- 这个方法是在哪个线程执行中调用的,就会得到哪个线程对象。
| 构造器方法名称 | 说明 |
|---|---|
| public Thread(String name) | 可以为当前线程指定名称 |
| public Thread(Runnable target) | 封装Runnable对象成为线程对象 |
| public Thread(Runnable target ,String name ) | 封装Runnable对象成为线程对象,并指定线程名称 |
线程安全
多个线程同时操作同一个共享资源的时候可能会出现业务安全问题,称为线程安全问题。
举例:
需求:小明和小红是一对夫妻,他们有一个共同的账户,余额是10万元。
如果小明和小红同时来取钱,而且2人都要取钱10万元,可能出现什么问题呢?
同时操作的话,银行可能被取走20万!!!
线程安全的原因:
-
存在多线程并发
-
同时访问共享资源
-
存在修改共享资源
为了解决当前线程安全问题,引出了下面的线程同步办法。
线程同步
让多个线程实现先后依次访问共享资源,这样就解决了安全问题。但注意这不是单线程哦,他是这样的,多个线程还是同步在运行,只是在最后我们访问到共享资源的时候才开始排队。就像两个人一起从家里去上厕所,两个人可以分别前往厕所,但是到了厕所门口需要排队。
线程同步的核心思想:
-
加锁:创建一个锁对象,把共享资源进行上锁,每次只能一个线程进入访问完毕以后解锁,然后其他线程才能进来。
方式一:同步代码块
原理:每次只能一个线程进入,执行完毕后自动解锁,其他线程才可以进来执行。把出现线程安全问题的核心代码给上锁。
**同步锁对象的要求:**对于当前同时执行的线程来说是同一个对象即可
-
规范上:建议使用共享资源作为锁对象。(不能随便取哦,否则会影响其他无关线程的进行)
-
对于实例方法建议使用this作为锁对象。
-
对于静态方法建议使用**字节码(类名.class)**对象作为锁对象
synchronized(同步锁对象) {
操作共享资源的代码(核心代码)
}
public void drawMoney( double money){
String name = Thread.currentThread().getName();
synchronized (this) {
if (this.money>0){
System.out.println(name+"来取钱成功,吐出"+money);
this.money -=money;
System.out.println("余额剩余:"+ this.money);
}else{
System.out.println(name+"来取钱成功余额不足了哦");
}
}
}
同步方式二:同步方法
作用:把出现线程安全问题的核心方法给上锁。
原理:每次只能一个线程进入,执行完毕以后自动解锁,其他线程才可以进来执行。
修饰符 synchronized 返回值类型 方法名称(形参列表) {
操作共享资源的代码
}
同步方法底层原理:
- 同步方法其实底层也是有隐式锁对象的,只是锁的范围是整个方法代码。
- 如果方法是实例方法:同步方法默认用this作为的锁对象。但是代码要高度面向对象!
- 如果方法是静态方法:同步方法默认用类名.class作为的锁对象。会锁住所有调用该方法的进程。范围更大
对比两种方法,锁住代码块效果更好,但是写法要复杂一点,其实一般开发还是同步方法比较好,实用。
方式三:Lock锁接口
-
为了更清晰的表达如何加锁和释放锁,JDK5以后提供了一个新的锁对象Lock,更加灵活、方便,是自己实现上锁与解锁操作
-
Lock实现提供比使用synchronized方法和语句可以获得更广泛的锁定操作。
-
Lock是接口不能直接实例化,这里采用它的实现类ReentrantLock来构建Lock锁对象。
public ReentrantLock() 获得Lock锁的实现类对象 //Example: Lock lock = new ReentrantLock();
Lock—API
| 方法名称 | 说明 |
|---|---|
| void lock( ) | 上锁 |
| void unlock () | 解锁,这个必须配合try…finally…使用 |
public void drawMoney( double money){
String name = Thread.currentThread().getName();
// 上锁
lock.lock();
try {
if (this.money>0){
System.out.println(name+"来取钱成功,吐出"+money);
this.money -=money;
System.out.println("余额剩余:"+ this.money);
}else{
System.out.println(name+"来取钱成功余额不足了哦");
}
} finally {
// 解锁
lock.unlock();
}
}
线程池
线程池就是一个可以复用线程的技术。如果用户每发起一个请求,后台就创建一个新线程来处理,下次新任务来了又要创建新线程,而创建新线程的开销是很大的,这样会严重影响系统的性能。
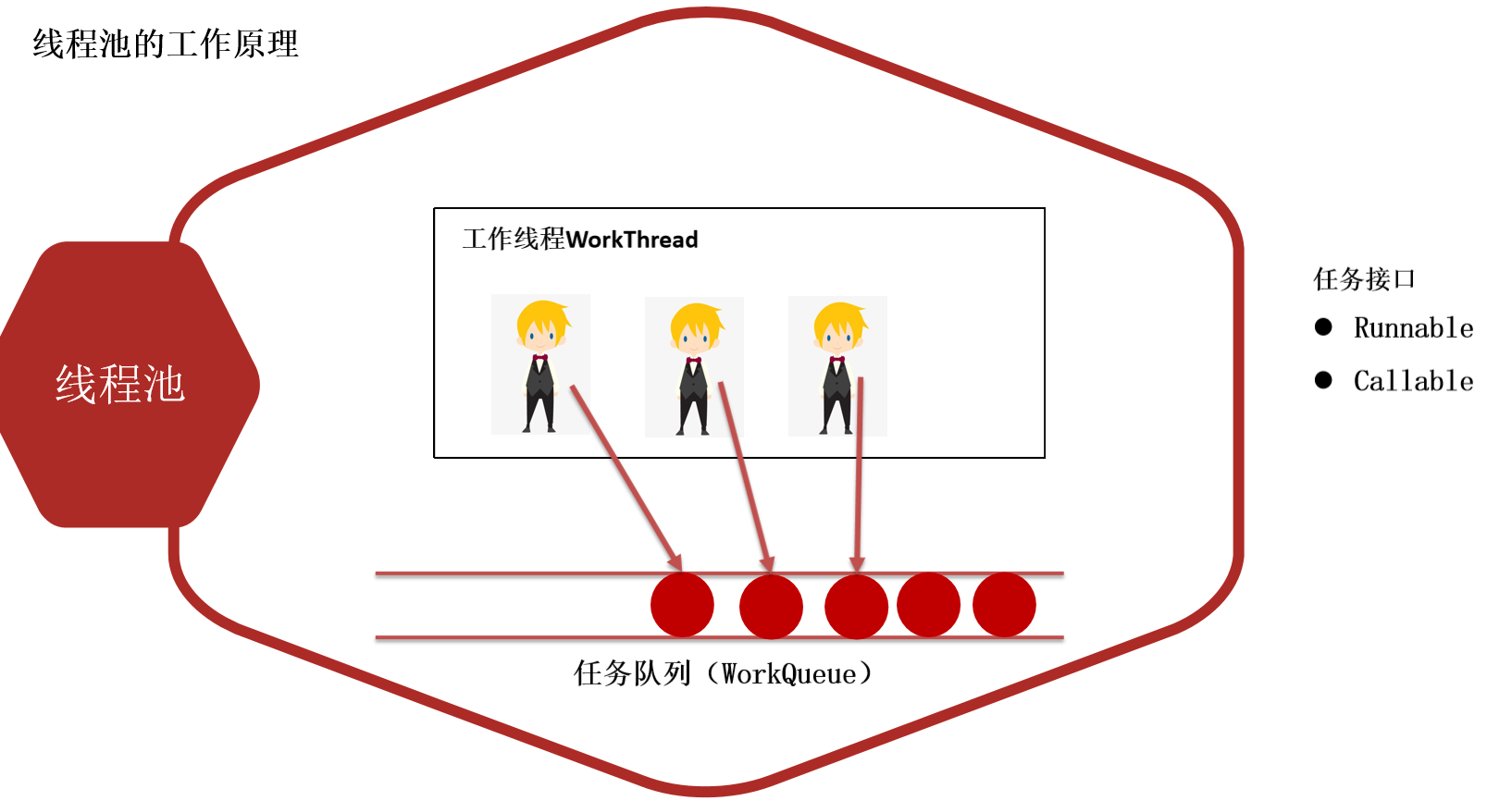
简单解释:首先,工作线程是我系统里面设置的三个固定线程,所有的任务由这三个来执行;任务队列就是我们系统接受到的所有任务,他们按照前后进来的顺序在排队;然后这三个人依次处理下面的任务。
线程池实现API
java里面代表线程池的东西:
JDK 5.0起提供了代表线程池的接口:ExecutorService
但注意这只是一个接口撒,基本东西不要忘记,所以我们是不是只能通过他的实现类来得到线程池对象啊!
得到线程对象的方法:
-
方式一:使用ExecutorService的实现类ThreadPoolExecutor自创建一个线程池对象

-
方式二:使用Executors(线程池的工具类)调用方法返回不同特点的线程池对象
方式一:ThreadPoolExecutor
-
ThreadPoolExecutor构造器的参数说明
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
详细解释一下各个参数:以饭店为例子。
系统相当于是一个五星级大饭店;
1. 核心线程——就是我们饭店的长期服务员,绝对不会跑路的,不然我饭店不就垮了嘛
2. 临时线程——就是我们饭店的临时工,是不是,当我们饭店到了旺季,几个长期员工肯定忙不过来啊,这个时候就需要找一些临时工过来帮忙。临时线程数=最大线程数-核心线程数
3. 最大线程数——就是我们饭店,最多能招的服务员的个数(也就是店里面所有的餐桌数,一个服务员只能招待一个桌子),长期工和临时工都算在里面,因为饭店资金肯定有限啊,不可能招无数个员工吧,对不对。系统硬件条件越好,招的人就越多。
4. 临时线程最大存活时间——指的就是临时线程最大的空闲时间,超过了的话就结束这个。我们招的临时工,从他开始休息开始计时,经过这么长时间后,还是没有客人需要接待的话,我们饭店就把他辞了。不然让他在这里不干活,还拿工资那不是亏死洛对不对。
5. 存活时间单位——指临时线程最大存活时间的时间单位,例如分,天等
6. 任务队列——就是我们饭店外面摆的排队的椅子,当店里面位置全部坐满了后(一个位置对于一个服务员专门接待,跟海底捞似的),新来的客人就需要等待,等某一桌的人走了,就会马上空出来一个服务员,现在再去招待在外面排队的客人。
7. 线程工厂——就是饭店的人力资源部门撒,负责去招聘服务员,店里面的服务员都是他招聘的。其实就是封装了前面的三个方法。
8. 拒绝经理——饭店门口负责招待客人的经理(不是服务员哦),他负责管理监视着店里面的位置和外面排队的椅子。首先在内外全部都坐满了,然后先来又来了新的客人,拒绝经理就出动了,去指导新来的客人,因为现在没有位置给他坐,会让他走吧,或者提出其他建议,去别的地方啥的。
注意要点:
-
临时线程什么时候创建啊?
新任务提交时发现核心线程都在忙,任务队列也满了,并且还可以创建临时线程,此时才会创建临时线程。
(饭店有十个桌子,五个排队椅,现在三个长期工都在招待客人,并且五个排队椅都坐满了,现在饭店才会招聘临时工。很聪明做法,这样可以尽量减少招聘临时工的数量,并且一次只找一个临时工,太尼玛聪明了)
-
什么时候会开始拒绝任务?
核心线程和临时线程都在忙,任务队列也满了,新的任务过来的时候才会开始任务拒绝。
(饭店已经招了7个临时工,店里面全部坐满了,外面五个椅子也肯定是满的。即一起饭店内外有十五个客人,假如现在再来一个客人,就会放出拒绝经理)
**Example:**最后面两个参数是java做好的,我们就用这个就行
ExecutorService pools = new ThreadPoolExecutor(3, 5, 8 ,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(6), Executors.defaultThreadFactory() ,
new ThreadPoolExecutor.AbortPolicy());
处理Runnable任务
| ExecutorServic方法名称 | 说明 |
|---|---|
| void execute(Runnable command) | 执行任务/命令,没有返回值,一般用来执行 Runnable 任务 |
| Future submit(Callable task) | 执行任务,返回未来任务对象获取线程结果,一般拿来执行 Callable 任务 |
| void shutdown() | 等任务执行完毕后关闭线程池 |
| List shutdownNow() | 立刻关闭,停止正在执行的任务,并返回队列中未执行的任务 |
新任务拒绝策略:
| 策略 | 详解 |
|---|---|
| ThreadPoolExecutor.AbortPolicy | 丢弃任务并抛出RejectedExecutionException异常。是默认的策略 |
| ThreadPoolExecutor.DiscardPolicy: | 丢弃任务,但是不抛出异常 这是不推荐的做法 |
| ThreadPoolExecutor.DiscardOldestPolicy | 抛弃队列中等待最久的任务 然后把当前任务加入队列中 |
| ThreadPoolExecutor.CallerRunsPolicy | 由主线程负责调用任务的run()方法从而绕过线程池直接执行 |
处理Callable任务
- ExecutorService的API
| 方法名称 | 说明 |
|---|---|
| void execute(Runnable command) | 执行任务/命令,没有返回值,一般用来执行 Runnable 任务 |
| Future submit(Callable task) | 执行Callable任务,返回未来任务对象获取线程结果 |
| void shutdown() | 等任务执行完毕后关闭线程池 |
| List shutdownNow() | 立刻关闭,停止正在执行的任务,并返回队列中未执行的任务 |
方式二:Executors工具类
下面是创建线程池的方法,如何执行看前面的ThreadPoolExecutord的API。
| 方法名称 | 说明 |
|---|---|
| public static ExecutorService newCachedThreadPool() | 线程数量随着任务增加而增加,如果线程任务执行完毕且空闲了一段时间则会被回收掉。 |
| public static ExecutorService newFixedThreadPool(int nThreads) | 创建固定线程数量的线程池,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程替代它。 |
| public static ExecutorService newSingleThreadExecutor () | 创建只有一个线程的线程池对象,如果该线程出现异常而结束,那么线程池会补充一个新线程。 |
| public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) | 创建一个线程池,可以实现在给定的延迟后运行任务,或者定期执行任务。 |
**注意:**Executors的底层其实也是基于线程池的实现类ThreadPoolExecutor创建线程池对象的。
该方法的缺陷:大型并发系统环境中使用Executors如果不注意可能会出现系统风险。
| 方法名称 | 存在问题 |
|---|---|
| public static ExecutorService newFixedThreadPool(int nThreads) | 允许请求的任务队列长度是Integer.MAX_VALUE,可能出现OOM错误( java.lang.OutOfMemoryError ) |
| public static ExecutorService newSingleThreadExecutor() | 允许请求的任务队列长度是Integer.MAX_VALUE,可能出现OOM错误( java.lang.OutOfMemoryError ) |
| public static ExecutorService newCachedThreadPool() | 创建的线程数量最大上限是Integer.MAX_VALUE,线程数可能会随着任务1:1增长,也可能出现OOM错误( java.lang.OutOfMemoryError ) |
| public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) | 创建的线程数量最大上限是Integer.MAX_VALUE,线程数可能会随着任务1:1增长,也可能出现OOM错误( java.lang.OutOfMemoryError ) |

定时器
-
定时器是一种控制任务延时调用,或者周期调用的技术。
-
作用:闹钟、定时邮件发送。
定时器的实现方式:
-
方式一:Timer
-
方式二: ScheduledExecutorService
Timer定时器
| 构造器 | 说明 |
|---|---|
| public Timer() | 创建Timer定时器对象 |
| 方法 | 说明 |
|---|---|
| public void schedule(TimerTask task, long delay, long period) | 开启一个定时器,按照计划重复处理TimerTask任务。delay——延迟…ms后处理任务,period——延迟…ms后再次执行该TimerTask任务) |
| public void schedule(TimerTask task, long delay) | 开启一个定时器,按照计划重复处理TimerTask任务。delay——延迟…ms后处理任务,不重复,只跑一次,上面那个不停就一直跑) |
Timer定时器的特点和存在的问题
1、Timer是单线程,处理多个任务按照顺序执行,存在延时与设置定时器的时间有出入。
2、可能因为其中的某个任务的异常使Timer线程死掉,从而影响后续任务执行。
ScheduledExecutorService
ScheduledExecutorService是 jdk1.5中引入了并发包,目的是为了弥补Timer的缺陷, ScheduledExecutorService内部为线程池。
ScheduledExecutorService的优点
- 基于线程池,某个任务的执行情况不会影响其他定时任务的执行。
| Executors的方法 | 说明 |
|---|---|
| public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) | 得到线程池对象 |
| ScheduledExecutorService的方法 | 说明 |
|---|---|
| public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit) | 周期调度方法 |
并发、并行
- 正在运行的程序(软件)就是一个独立的进程, 线程是属于进程的这个区域的,多个线程其实是并发与并行同时进行的。
并发的理解:
-
CPU同时处理线程的数量有限。一个CPU的核只能处理一个进程
-
CPU的每个核会轮流为系统的每个线程服务,由于CPU切换的速度很快,给我们的感觉这些线程在同时执行,这就是并发。
并行的理解:
- 在同一个时刻上,同时有多个线程在被CPU的多个核心处理并执行。8核CPU就可以并行处理8个进程
简单说说并发和并行的含义
-
并发:CPU分时轮询的执行线程。
-
并行:同一个时刻同时在执行。
线程的生命周期
线程的状态:
- 线程的状态:也就是线程从生到死的过程,以及中间经历的各种状态及状态转换。
- 理解线程的状态有利于提升并发编程的理解能力。
Java线程的状态:
-
Java总共定义了6种状态
-
6种状态都定义在Thread类的内部枚举类中。
public class Thread{
...
public enum State {
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;
}
...
}
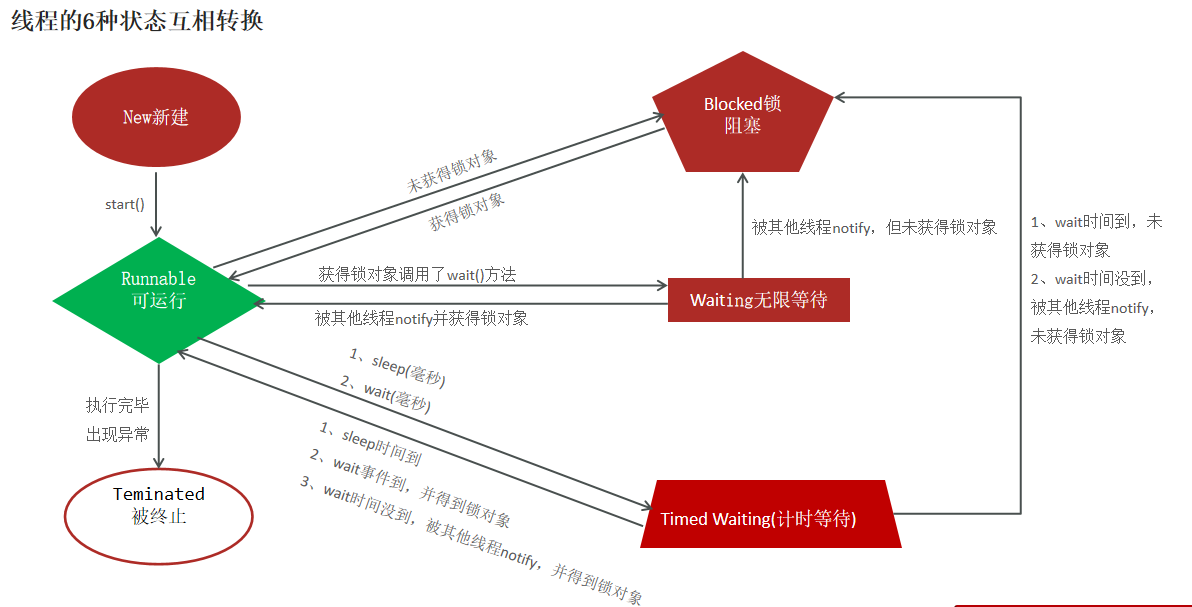
| 线程状态 | 描述 |
|---|---|
| NEW(新建) | 线程刚被创建,但是并未启动。 |
| Runnable(可运行) | 线程已经调用了start()等待CPU调度 |
| Blocked(锁阻塞) | 线程在执行的时候未竞争到锁对象,则该线程进入Blocked状态;。 |
| Waiting(无限等待) | 一个线程进入Waiting状态,另一个线程调用notify或者notifyAll方法才能够唤醒 |
| Timed Waiting(计时等待) | 同waiting状态,有几个方法有超时参数,调用他们将进入Timed Waiting状态。带有超时参数的常用方法有Thread.sleep 、Object.wait。 |
| Teminated(被终止) | 因为run方法正常退出而死亡,或者因为没有捕获的异常终止了run方法而死亡。 |
网络编程
什么是网络编程?
- 网络编程可以让程序与网络上的其他设备中的程序进行数据交互。
网络通信基本模式
- 常见的通信模式有如下2种形式:Client-Server(CS) 、 Browser/Server(BS)
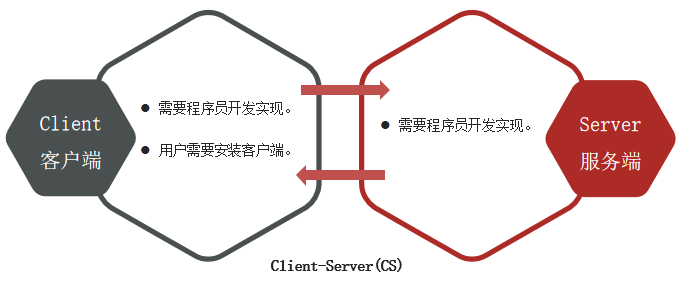
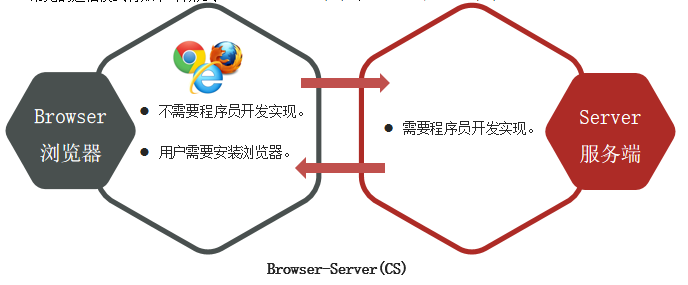
网络编程学习要点:

三要素
**IP地址:**设备在网络中的地址,是唯一的标识。
**端口:**应用程序在设备中唯一的标识。
协议: 数据在网络中传输的规则,常见的协议有UDP协议和TCP协议
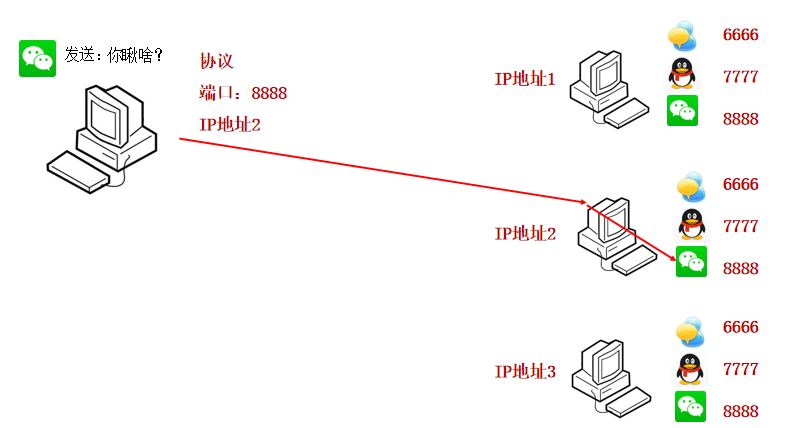
IP地址
IP(Internet Protocol):全称”互联网协议地址”,是分配给上网设备的唯一标志。
常见的IP分类为:IPv4和IPv6
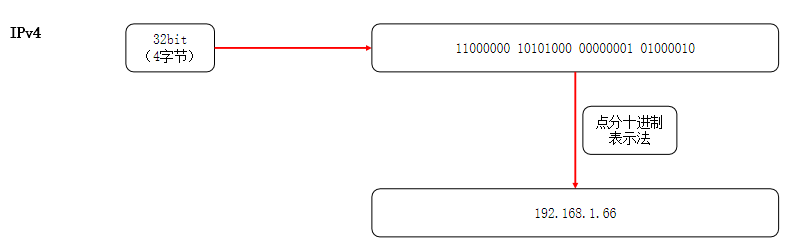
**IPv6:**128位(16个字节),号称可以为地球每一粒沙子编号。
IPv6分成8个整数,每个整数用四个十六进制位表示, 数之间用冒号(:)分开

IP地址基本寻路:
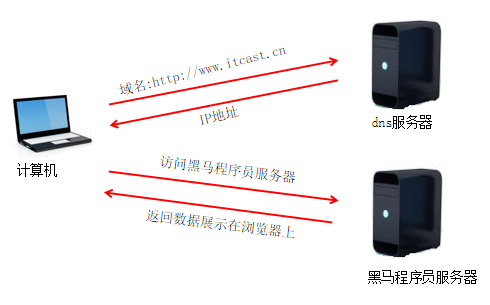
IP地址形式:
- 公网地址、和私有地址(局域网使用)。
- 192.168. 开头的就是常见的局域网地址,范围即为192.168.0.0–192.168.255.255,专门为组织机构内部使用。
IP常用命令:
- ipconfig:查看本机IP地址
- ping IP地址:检查网络是否连通
特殊IP地址:
- 本机IP: 127.0.0.1或者localhost:称为回送地址也可称本地回环地址,只会寻找当前所在本机
IP地址操作类-InetAddress
此类表示Internet协议(IP)地址。
| 方法名称 | 说明 |
|---|---|
| public static InetAddress getLocalHost() | 返回本主机的地址对象 |
| public static InetAddress getByName(String host) | 得到指定主机的IP地址对象,参数是域名或者IP地址 |
| public String getHostName() | 获取此IP地址的主机名 |
| public String getHostAddress() | 返回IP地址字符串 |
| public boolean isReachable(int timeout) | 在指定毫秒内连通该IP地址对应的主机,连通返回true |
端口号
**端口号:**准确标识出正在计算机设备上运行的进程(程序),规定为一个 16 位的二进制,范围是 0~65535。
端口类型:
- 周知端口:0~1023,被预先定义的知名应用占用(如:HTTP占用 80,FTP占用21)
- **注册端口:**1024~49151,分配给用户进程或某些应用程序。(如:Tomcat占 用8080,MySQL占用3306)
- 动态端口:49152到65535,之所以称为动态端口,是因为它 一般不固定分配某种进程,而是动态分配。

协议
连接和通信数据的规则被称为网络通信协议

网络通信协议有两套参考模型
OSI参考模型:世界互联协议标准,全球通信规范,由于此模型过于理想化,未能在因特网上进行广泛推广。
TCP/IP参考模型(或TCP/IP协议):事实上的国际标准。

传输层的2个常见协议:
- TCP(Transmission Control Protocol) :传输控制协议
- UDP(User Datagram Protocol):用户数据报协议
TCP
TCP协议特点:
- 使用TCP协议,必须双方先建立连接,它是一种面向连接的可靠通信协议。
- 传输前,采用“三次握手”方式建立连接,所以是可靠的 。
- 在连接中可进行大数据量的传输 。
- 连接、发送数据都需要确认,且传输完毕后,还需释放已建立的连接,通信效率较低。
TCP协议通信场景:
- 对信息安全要求较高的场景,例如:文件下载、金融等数据通信。


快速入门:一发一收
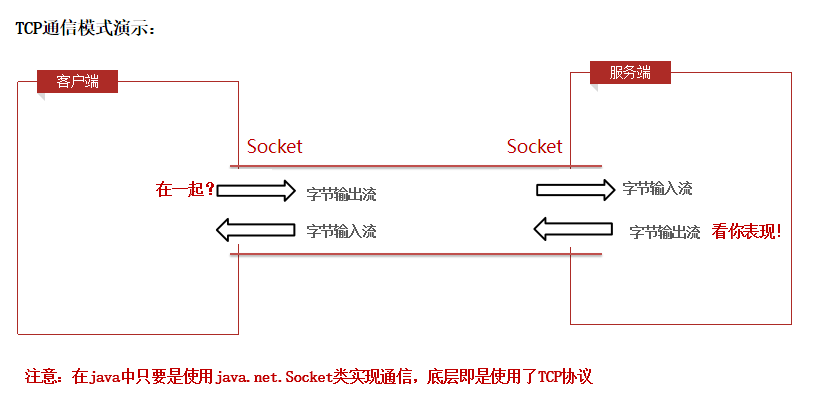
一.客户端:代表类—Socket
| 构造器 | 说明 |
|---|---|
| public Socket(String host , int port) | 创建发送端的Socket对象与服务端连接,参数为服务端程序的ip和端口。 |
| 方法 | 说明 |
|---|---|
| OutputStream getOutputStream() | 获得字节输出流对象 |
| InputStream getInputStream() | 获得字节输入流对象 |
客户端实现步骤
- 创建客户端的Socket对象,请求与服务端的连接。
- 使用socket对象调用getOutputStream()方法得到字节输出流。
- 使用字节输出流完成数据的发送。
- 释放资源:关闭socket管道。
/**
目标:完成Socket网络编程入门案例的客户端开发,实现1发1收。
*/
public class ClientDemo1 {
public static void main(String[] args) {
try {
System.out.println("====客户端启动===");
// 1、创建Socket通信管道请求有服务端的连接
Socket socket = new Socket("127.0.0.1", 7777);
// 2、从socket通信管道中得到一个字节输出流 负责发送数据
OutputStream os = socket.getOutputStream();
// 3、把低级的字节流包装成打印流
PrintStream ps = new PrintStream(os);
// 4、发送消息
ps.println("我是TCP的客户端,我已经与你对接,并发出邀请:约吗?");
ps.flush();
// 关闭资源。
// socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
注意:关闭资源不能这样启动的原因在于,TCP通信是非常严格的,建立与关闭双方都需要相互确认,发送消息。如果按照上面那样,可能出现我消息还没有完全发出去,客户端就发送了关闭的请求,出BUG。就像QQ聊天,我们都是在手动点击了X后才关闭,关闭一般都是让用户去点击,才触发。
还有使用println的原因在于与下面的服务端对应。
二.服务端:代表类—ServerSocket
| 构造器 | 说明 |
|---|---|
| public ServerSocket(int port) | 注册服务端端口 |
| 方法 | 说明 |
|---|---|
| public Socket accept() | 等待接收客户端的Socket通信连接,连接成功返回Socket对象,与客户端建立端到端通信 |
服务端实现步骤
- 创建ServerSocket对象,注册服务端端口。
- 调用ServerSocket对象的accept()方法,等待客户端的连接,并得到Socket管道对象。
- 通过Socket对象调用getInputStream()方法得到字节输入流、完成数据的接收。
- 释放资源:关闭socket管道
/**
目标:开发Socket网络编程入门代码的服务端,实现接收消息
*/
public class ServerDemo2 {
public static void main(String[] args) {
try {
System.out.println("===服务端启动成功===");
// 1、注册端口
ServerSocket serverSocket = new ServerSocket(7777);
// 2、必须调用accept方法:等待接收客户端的Socket连接请求,建立Socket通信管道
Socket socket = serverSocket.accept();
// 3、从socket通信管道中得到一个字节输入流
InputStream is = socket.getInputStream();
// 4、把字节输入流包装成缓冲字符输入流进行消息的接收
BufferedReader br = new BufferedReader(new InputStreamReader(is));
// 5、按照行读取消息
String msg;
if ((msg = br.readLine()) != null){
System.out.println(socket.getRemoteSocketAddress() + "说了:: " + msg);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
注意:第五步用 if 的原因,因为我们是一发一收,没有弄其他的,假如用while的话,就会一直等,客户端代码写的是跑完了就会结束,所以这里就会报出链接重置的错误,服务端失效。
还有一点,这里读取数据是写的,按行读取,所以对于客户端要按行去发送,也就是为什么用的是println方法。
总结TCP通信的基本原理:
- 客户端怎么发,服务端就应该怎么收。
- 客户端如果没有消息,服务端会进入阻塞等待。
- Socket一方关闭或者出现异常、对方Socket也会失效或者出错
多发多收
使用TCP通信方式实现:多发多收消息。意思是,可以客户端不断发送,服务端不断接收
具体思路:
- 可以使用死循环控制服务端收完消息继续等待接收下一个消息。
- 客户端也可以使用死循环等待用户不断输入消息。
- 客户端一旦输入了exit,则关闭客户端程序,并释放资源。
很简单的,就是在前面的一发一收里面加循环。但注意现在都是一个客户端,一个服务端。
/**
目标:完成Socket网络编程入门案例的客户端开发,实现多发多收。
*/
public class ClientDemo1 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
try {
System.out.println("====客户端启动===");
// 1、创建Socket通信管道请求有服务端的连接
// public Socket(String host, int port)
// 参数一:服务端的IP地址
// 参数二:服务端的端口
Socket socket = new Socket("127.0.0.1", 7777);
// 2、从socket通信管道中得到一个字节输出流 负责发送数据
OutputStream os = socket.getOutputStream();
// 3、把低级的字节流包装成打印流
PrintStream ps = new PrintStream(os);
while(true){
System.out.println("请说");
String msg = sc.nextLine();
if (msg.equals("exit")){
return;
}
// 4、发送消息
ps.println(msg);
ps.flush();
}
// 关闭资源。
// socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
目标:开发Socket网络编程入门代码的服务端,实现接收消息
*/
public class ServerDemo2 {
public static void main(String[] args) {
try {
System.out.println("===服务端启动成功===");
// 1、注册端口
ServerSocket serverSocket = new ServerSocket(7777);
// 2、必须调用accept方法:等待接收客户端的Socket连接请求,建立Socket通信管道
Socket socket = serverSocket.accept();
// 3、从socket通信管道中得到一个字节输入流
InputStream is = socket.getInputStream();
// 4、把字节输入流包装成缓冲字符输入流进行消息的接收
BufferedReader br = new BufferedReader(new InputStreamReader(is));
// 5、按照行读取消息
String msg;
while ((msg = br.readLine()) != null){
System.out.println(socket.getRemoteSocketAddress() + "说了:: " + msg);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
问题:本案例实现了多发多收,那么是否可以同时接收多个客户端的消息?
不可以的。因为服务端现在只有一个线程,只能与一个客户端进行通信。
同时接受多个客户端消息[重点]
1、之前我们的通信是否可以同时与多个客户端通信,为什么?
不可以的
单线程每次只能处理一个客户端的Socket通信
2、如何才可以让服务端可以处理多个客户端的通信需求?
引入多线程。
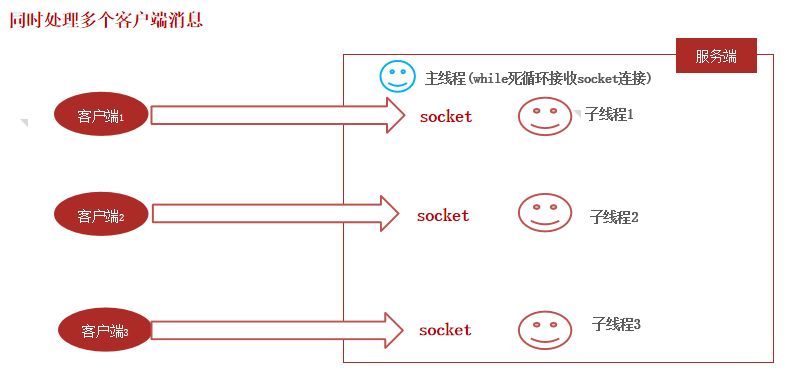
在前一个的基础上,客户端不用动撒,只改服务端,这次没有使用线程池,用的是线程。
/**
目标:实现服务端可以同时处理多个客户端的消息。
*/
public class ClientDemo1 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
try {
System.out.println("====客户端启动===");
// 1、创建Socket通信管道请求有服务端的连接
// public Socket(String host, int port)
// 参数一:服务端的IP地址
// 参数二:服务端的端口
Socket socket = new Socket("127.0.0.1", 7777);
// 2、从socket通信管道中得到一个字节输出流 负责发送数据
OutputStream os = socket.getOutputStream();
// 3、把低级的字节流包装成打印流
PrintStream ps = new PrintStream(os);
while(true){
System.out.println("请说");
String msg = sc.nextLine();
if (msg.equals("exit")){
return;
}
// 4、发送消息
ps.println(msg);
ps.flush();
}
// 关闭资源。
// socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
目标:实现服务端可以同时处理多个客户端的消息。
*/
public class ServerDemo2 {
public static void main(String[] args) {
try {
System.out.println("===服务端启动成功===");
// 1、注册端口
ServerSocket serverSocket = new ServerSocket(7777);
// a.定义一个死循环由主线程负责不断的接收客户端的Socket管道连接。
while (true) {
// 2、每接收到一个客户端的Socket管道,交给一个独立的子线程负责读取消息
Socket socket = serverSocket.accept();
System.out.println(socket.getRemoteSocketAddress()+ "它来了,上线了!");
// 3、开始创建独立线程处理socket
new ServerReaderThread(socket).start();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
public class ServerReaderThread extends Thread{
private Socket socket;
public ServerReaderThread(Socket socket){
this.socket = socket;
}
@Override
public void run() {
try {
// 3、从socket通信管道中得到一个字节输入流
InputStream is = socket.getInputStream();
// 4、把字节输入流包装成缓冲字符输入流进行消息的接收
BufferedReader br = new BufferedReader(new InputStreamReader(is));
// 5、按照行读取消息
String msg;
while ((msg = br.readLine()) != null){
System.out.println(socket.getRemoteSocketAddress() + "说了:: " + msg);
}
} catch (Exception e) {
System.out.println(socket.getRemoteSocketAddress() + "下线了!!!");
}
}
}
使用线程池优化上面案例
客户端不用动,服务端变,新建一个类实现Runnable,做为我们的任务对象,将需要执行的代码放进去;服务端代码内新建一个线程池。
/**
目标:实现服务端可以同时处理多个客户端的消息。
*/
public class ClientDemo1 {
public static void main(String[] args) {
try {
System.out.println("====客户端启动===");
// 1、创建Socket通信管道请求有服务端的连接
// public Socket(String host, int port)
// 参数一:服务端的IP地址
// 参数二:服务端的端口
Socket socket = new Socket("127.0.0.1", 7777);
// 2、从socket通信管道中得到一个字节输出流 负责发送数据
OutputStream os = socket.getOutputStream();
// 3、把低级的字节流包装成打印流
PrintStream ps = new PrintStream(os);
Scanner sc = new Scanner(System.in);
while (true) {
System.out.println("请说:");
String msg = sc.nextLine();
// 4、发送消息
ps.println(msg);
ps.flush();
}
// 关闭资源。
// socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
目标:实现服务端可以同时处理多个客户端的消息。
*/
public class ServerDemo2 {
//3.新建一个线程池,只有一个哦,所以我们放在前面,可以定义成static finally
public static final ThreadPoolExecutor pool = new ThreadPoolExecutor(2, 4, 5, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(2),
Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy());
public static void main(String[] args) {
try {
System.out.println("===服务端启动成功===");
// 1、注册端口
ServerSocket serverSocket = new ServerSocket(7777);
// a.定义一个死循环由主线程负责不断的接收客户端的Socket管道连接。
while (true) {
// 2、每接收到一个客户端的Socket管道,交给一个独立的子线程负责读取消息
Socket socket = serverSocket.accept();
System.out.println(socket.getRemoteSocketAddress()+ "它来了,上线了!");
//4.将socket管道以及后续的执行代码包装成一个Runnable任务对象。
MyRunnable myRunnable = new MyRunnable(socket);
//5. 线程池执行Runnable对象
pool.execute(myRunnable);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
public class MyRunnable implements Runnable{
// 5. 将前面的socket传过来,并自己写构造器
private Socket socket;
public MyRunnable(Socket socket){
this.socket = socket;
}
@Override
public void run() {
/**
* 拿到管道后,读取管道信息
*/
try {
// 1.从socket通信管道中得到一个字节输入流
InputStream is = socket.getInputStream();
// 2.把字节输入流包装成缓冲字符输入流进行消息的接收
BufferedReader br = new BufferedReader(new InputStreamReader(is));
// 3. 按照行读取消息
String msg;
while ((msg = br.readLine()) != null){
System.out.println(socket.getRemoteSocketAddress() + "说了:: " + msg + "\t"+"由该线程执行"+ Thread.currentThread());
}
} catch (IOException e) {
// e.printStackTrace();
System.out.println(socket.getRemoteSocketAddress()+"下线了哦");
}
}
}
综合案例:即时通信
即时通信是什么含义,要实现怎么样的设计?
- 即时通信,是指一个客户端的消息发出去,其他客户端可以接收到
- 即时通信需要进行端口转发的设计思想。
- 服务端需要把在线的Socket管道存储起来
- 一旦收到一个消息要推送给其他管道
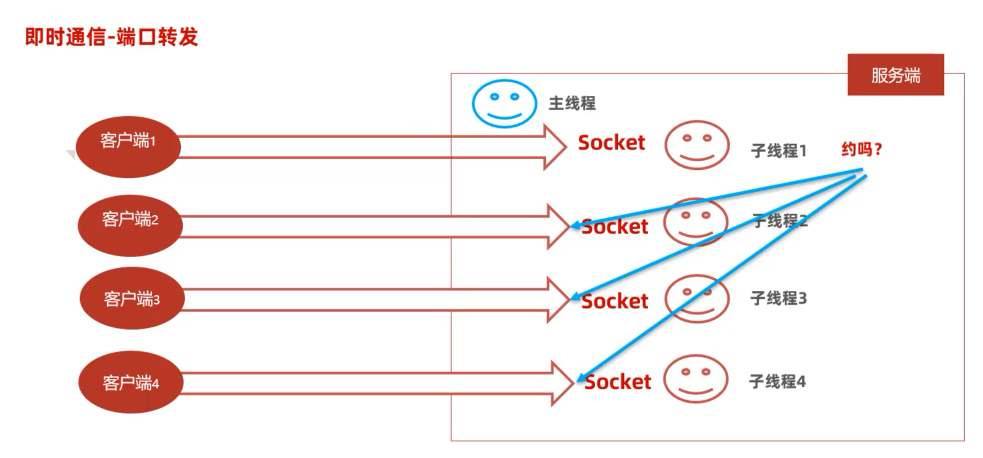
**思路:**客户首先发消息到服务端,服务端拿到了需要转发给其他的客户端。这里服务端是不是需要先存储所有建立的管道啊,不然他怎么知道要转发给谁呢,所以服务端需要定义一个集合来存储我们的Socket管道;而客户端需要在发消息的基础上面,加一个收消息。
**客户端:**客户端是while循环,一直在等待发消息,对不对,所以说我们需要再新建一个线程来专门收消息啊。
/**
目标:实现即时通信
1. 客户端发送
2. 客户端收(新建一个线程实现)
*/
public class ClientDemo1 {
public static void main(String[] args) {
try {
System.out.println("====客户端启动===");
// 1、创建Socket通信管道请求有服务端的连接
// public Socket(String host, int port)
// 参数一:服务端的IP地址
// 参数二:服务端的端口
Socket socket = new Socket("127.0.0.1", 7777);
/**
创建一个独立的线程专门负责这个客户端的读消息
*/
new ClientReaderThread(socket).start();
// 2、从socket通信管道中得到一个字节输出流 负责发送数据
OutputStream os = socket.getOutputStream();
// 3、把低级的字节流包装成打印流
PrintStream ps = new PrintStream(os);
Scanner sc = new Scanner(System.in);
while (true) {
System.out.println("请说:");
String msg = sc.nextLine();
// 4、发送消息
ps.println(msg);
ps.flush();
}
// 关闭资源。
// socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
新建一个线程来 处理客户端读服务端发送来的消息
*/
class ClientReaderThread extends Thread{
private Socket socket;
public ClientReaderThread(Socket socket){
this.socket = socket;
}
@Override
public void run() {
try {
// 1、从socket通信管道中得到一个字节输入流
InputStream is = socket.getInputStream();
// 2、把字节输入流包装成缓冲字符输入流进行消息的接收
BufferedReader br = new BufferedReader(new InputStreamReader(is));
// 3、按照行读取消息
String msg;
while ((msg = br.readLine()) != null){
System.out.println("收到消息 " + msg);
}
} catch (Exception e) {
System.out.println("服务端把你踢出去了。。。。");
}
}
}
/**
目标:实现服务端即时通信
*/
public class ServerDemo2 {
/**
* 定义一个静态的List集合存储全部在线的Socket管道.不需要键值对的形式
*/
public static List<Socket> allOnlineSockets = new ArrayList<>();
public static void main(String[] args) {
try {
System.out.println("===服务端启动成功===");
// 1、注册端口
ServerSocket serverSocket = new ServerSocket(7777);
// a.定义一个死循环由主线程负责不断的接收客户端的Socket管道连接。
while (true) {
// 2、每接收到一个客户端的Socket管道,交给一个独立的子线程负责读取消息
Socket socket = serverSocket.accept();
// 客户端上线,添加集合
allOnlineSockets.add(socket);
System.out.println(socket.getRemoteSocketAddress()+ "它来了,上线了!");
//
// 3、开始创建独立线程处理socket
new ServerReaderThread(socket).start();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
class ServerReaderThread extends Thread{
private Socket socket;
public ServerReaderThread(Socket socket){
this.socket = socket;
}
@Override
public void run() {
try {
// 3、从socket通信管道中得到一个字节输入流
InputStream is = socket.getInputStream();
// 4、把字节输入流包装成缓冲字符输入流进行消息的接收
BufferedReader br = new BufferedReader(new InputStreamReader(is));
// 5、按照行读取消息
String msg;
while ((msg = br.readLine()) != null){
System.out.println(socket.getRemoteSocketAddress() + "说了:: " + msg);
//功能:把收到的这个消息发给所以在线的人
sendMsgToAll(msg);
}
} catch (Exception e) {
System.out.println(socket.getRemoteSocketAddress() + "下线了!!!");
//客户端下线,移除集合内容
ServerDemo2.allOnlineSockets.remove(socket);
}
}
private void sendMsgToAll(String msg) {
for (Socket socket : ServerDemo2.allOnlineSockets) {
try {
PrintStream ps = new PrintStream(socket.getOutputStream());
ps.println(msg);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
综合案例:模拟BS系统
1、之前的客户端都是什么样的
其实就是CS架构,客户端实需要我们自己开发实现的。
2、BS结构是什么样的,需要开发客户端吗?
浏览器访问服务端,不需要开发客户端。
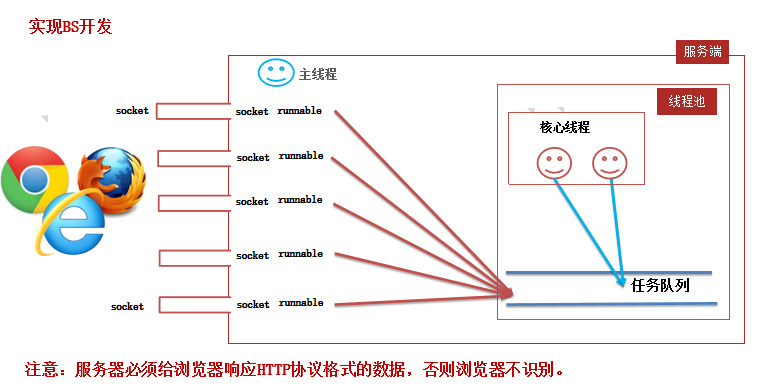
超级牛逼哦,下面的代码,woc
/**
客户端:浏览器。(无需开发)
服务端:自己开发。
需求:在浏览器中请求本程序,响应一个网页文字给浏览器显示
*/
public class BSServer {
// 使用静态变量记住一个线程池对象
public static ExecutorService pool = new ThreadPoolExecutor(2,4,5, TimeUnit.SECONDS
,new ArrayBlockingQueue<>(2), Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());
public static void main(String[] args) {
try {
//1. 注册端口
ServerSocket serverSocket = new ServerSocket(8000);
//2. 创建一个循环接收多个客户端的请求
Socket socket = serverSocket.accept();
// 3.交给一个独立的线程来处理!
pool.execute(new ServerReaderRunnable(socket));
} catch (IOException e) {
e.printStackTrace();
}
}
}
class ServerReaderRunnable implements Runnable{
private Socket socket;
public ServerReaderRunnable(Socket socket){
this.socket = socket;
}
@Override
public void run() {
try {
// 浏览器 已经与本线程建立了Socket管道
// 响应消息给浏览器显示
PrintStream ps = new PrintStream(socket.getOutputStream());
// 必须响应HTTP协议格式数据,否则浏览器不认识消息
ps.println("HTTP/1.1 200 OK"); // 协议类型和版本 响应成功的消息!
ps.println("Content-Type:text/html;charset=UTF-8"); // 响应的数据类型:文本/网页
ps.println(); // 必须发送一个空行
// 才可以响应数据回去给浏览器
ps.println("<span style='color:red;font-size:90px'>《最牛的149期》 </span>");
ps.close();
} catch (Exception e) {
System.out.println(socket.getRemoteSocketAddress() + "下线了!!!");
}
}
}
UCP
UDP协议:
- UDP是一种无连接、不可靠传输的协议。
- 将数据源IP、目的地IP和端口封装成数据包,不需要建立连接
- 每个数据包的大小限制在64KB内
- 发送不管对方是否准备好,接收方收到也不确认,故是不可靠的
- 可以广播发送 ,发送数据结束时无需释放资源,开销小,速度快。
UDP协议通信场景
- 语音通话,视频会话等。
快速入门

一:数据包的建立
DatagramPacket:数据包对象(韭菜盘子)
| 构造器 | 说明 |
|---|---|
| public DatagramPacket(byte[] buf, int length, InetAddress address, int port) | 创建发送端数据包对象buf:要发送的内容,字节数组length:要发送内容的字节长度address:接收端的IP地址对象port:接收端的端口号 |
| public DatagramPacket(byte[] buf, int length) | 创建接收端的数据包对象buf:用来存储接收的内容length:能够接收内容的长度 |
| public synchronized int getPort() | 获得当前数据包的地址(IP+端口号) |
| public synchronized int getPort() | 获得当前数据包的(端口号) |
String类里面字符串转换成字节数组的方法:
public byte[] getBytes( )
DatagramPacket常用方法:
| 方法 | 说明 |
|---|---|
| public int getLength() | 获得实际接收到的字节个数 |
二:发送接收端的建立
DatagramSocket:发送端和接收端对象(人)
| 构造器 | 说明 |
|---|---|
| public DatagramSocket() | 创建发送端的Socket对象,系统会随机分配一个端口号。 |
| public DatagramSocket(int port) | 创建接收端的Socket对象并指定端口号 |
DatagramSocket类成员方法
| 方法 | 说明 |
|---|---|
| public void send(DatagramPacket dp) | 发送数据包 |
| public void receive(DatagramPacket p) | 接收数据包 |
| public void close( ) | 关闭当前发送接收端 |
Example:
/**
发送端 一发 一收
*/
public class ClientDemo1 {
public static void main(String[] args) throws Exception {
System.out.println("=====客户端启动======");
// 1、创建发送端对象:发送端自带默认的端口号(人)
DatagramSocket socket = new DatagramSocket(6666);
// 2、创建一个数据包对象封装数据(韭菜盘子)
/**
public DatagramPacket(byte buf[], int length,
InetAddress address, int port)
参数一:封装要发送的数据(韭菜)
参数二:发送数据的大小
参数三:服务端的主机IP地址
参数四:服务端的端口
*/
byte[] buffer = "我是一颗快乐的韭菜,你愿意吃吗?".getBytes();
DatagramPacket packet = new DatagramPacket( buffer, buffer.length,
InetAddress.getLocalHost() , 8888);
// 3、发送数据出去
socket.send(packet);
socket.close();
}
}
/**
接收端
*/
public class ServerDemo2 {
public static void main(String[] args) throws Exception {
System.out.println("=====服务端启动======");
// 1、创建接收端对象:注册端口(人)
DatagramSocket socket = new DatagramSocket(8888);
// 2、创建一个数据包对象接收数据(韭菜盘子)
byte[] buffer = new byte[1024 * 64];
DatagramPacket packet = new DatagramPacket(buffer, buffer.length);
// 3、等待接收数据。
socket.receive(packet);
// 4、取出数据即可
// 读取多少倒出多少
int len = packet.getLength();
String rs = new String(buffer,0, len);
System.out.println("收到了:" + rs);
// 获取发送端的ip和端口
String ip =packet.getSocketAddress().toString();
System.out.println("对方地址:" + ip);
int port = packet.getPort();
System.out.println("对方端口:" + port);
socket.close();
}
}
广播、组播
UDP的三种通信方式
- 单播:单台主机与单台主机之间的通信。
- 广播:当前主机与所在网络中的所有主机通信。
- 组播:当前主机与选定的一组主机的通信。
即,UDP可以实现多个客户端,给一个服务端发消息。
单元测试
**概述:**单元测试就是针对最小的功能单元编写测试代码,Java程序最小的功能单元是方法,因此,单元测试就是针对Java方法的测试,进而检查方法的正确性。

Junit单元测试框架
- JUnit是使用Java语言实现的单元测试框架,它是开源的,Java开发者都应当学习并使用JUnit编写单元测试。
- 此外,几乎所有的IDE工具都集成了JUnit,这样我们就可以直接在IDE中编写并运行JUnit测试,JUnit目前最新版本是5。
JUnit优点
- JUnit可以灵活的选择执行哪些测试方法,可以一键执行全部测试方法。
- Junit可以生成全部方法的测试报告。
- 单元测试中的某个方法测试失败了,不会影响其他测试方法的测试。
快速入门
分析:
-
将JUnit的jar包导入到项目中
-
IDEA通常整合好了Junit框架,一般不需要导入。
-
如果IDEA没有整合好,需要自己手工导入如下2个JUnit的jar包到模块

-
编写测试方法:该测试方法必须是公共的无参数无返回值的非静态方法。
-
在测试方法上使用@Test注解:标注该方法是一个测试方法
-
在测试方法中完成被测试方法的预期正确性测试。
-
选中测试方法,选择“JUnit运行” ,如果测试良好则是绿色;如果测试失败,则是红色
/**
业务方法
*/
public class UserService {
public String loginName(String loginName , String passWord){
if("admin".equals(loginName) && "123456".equals(passWord)){
return "登录成功";
}else {
return "用户名或者密码有问题";
}
}
public void selectNames(){
System.out.println(10/0);
System.out.println("查询全部用户名称成功~~");
}
}
public class TestUserServer {
@Test
public void testLoginName(){
UserService userService = new UserService();
String rs = userService.loginName("admin", "123456");
//进行预期结果的准确性测试:断言。
Assert.assertEquals(rs,"登录成功","您的业务功能出现BUG");
}
@Test
public void testSelcetNames(){
UserService userService = new UserService();
userService.selectNames();
}
}
Junit常用注解
| 注解 | 说明 |
|---|---|
| @Test | 测试方法 |
| @BeforeEach | 用来修饰实例方法,该方法会在每一个测试方法执行之前执行一次。 |
| @AfterEach | 用来修饰实例方法,该方法会在每一个测试方法执行之后执行一次。 |
| @BeforeAll | 用来静态修饰方法,该方法会在所有测试方法之前只执行一次。 |
| @AfterAll | 用来静态修饰方法,该方法会在所有测试方法之后只执行一次。 |
- 开始执行的方法:初始化资源。
- 执行完之后的方法:释放资源。
反射
反射概述
- 反射是指对于任何一个Class类,在"运行的时候"都可以直接得到这个类全部成分。
- 在运行时,可以直接得到这个类的构造器对象:Constructor
- 在运行时,可以直接得到这个类的成员变量对象:Field
- 在运行时,可以直接得到这个类的成员方法对象:Method
- 这种运行时,动态获取类信息以及动态调用类中成分的能力称为Java语言的反射机制。
反射的关键:
反射的第一步都是先得到编译后的Class类对象,然后就可以得到Class的全部成分。

反射获取类对象
首先,整理一些,Java文件的整个生命周期,即执行过程。首先是javac将 .java 编译成Class文件,如何这个文件会运到内存中,创建Class类对象。最后java的运行是java执行工具跑。


内存中的Class类对象结构如下: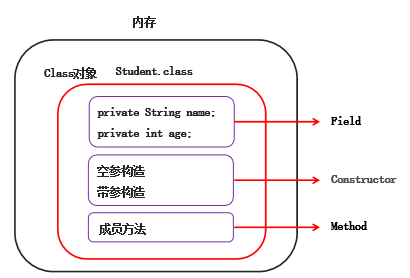
所以说我们反射是需要得到——Class类对象,可以从三个过程中获取,如下:
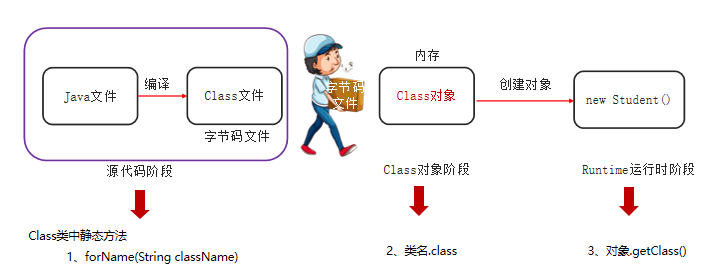
反射的第一步是什么?
- 获取Class类对象,如此才可以解析类的全部成分
获取Class类的对象的三种方式
- 方式一:Class c1 = Class.forName(“全类名”);
- 方式二:Class c2 = 类名.class
- 方式三:Class c3 = 对象.getClass( );
public class reflect1 {
public static void main(String[] args) throws ClassNotFoundException {
//1. Class类对象的一个静态方法:forName(全限名:包名+类名)
Class<?> c = Class.forName("com.CCooky.Student");
System.out.println(c);
//2. 类名.class
Class<Student> c1 = Student.class;
System.out.println(c1);
//3. 对象.getClass() 获取该对象对应的Class类对象
Student s = new Student();
Class<? extends Student> c2 = s.getClass();
System.out.println(c2);
}
}
Class的API
| Class的方法 | 说明 |
|---|---|
| Constructor<?>[] getConstructors() | 返回public构造器对象的数组 |
| String getName() | 返回此Class对象表示的实体的名称。 |
| String getSimpleName() | 返回源代码中给出的基础类的简单名称。 |
反射类成分共有的API
构造器、成员变量、成员方法等。。。API有特别多,基本上你能想到的都有,不能想到的也有,下面只是几个例子
| API | 说明 |
|---|---|
| public String getName() | 获得当前成分的名字(成员变量名,方法名等) |
| public int getParameterCount() | 获得当前成分的形参总数(构造器、方法) |
反射获取构造器对象
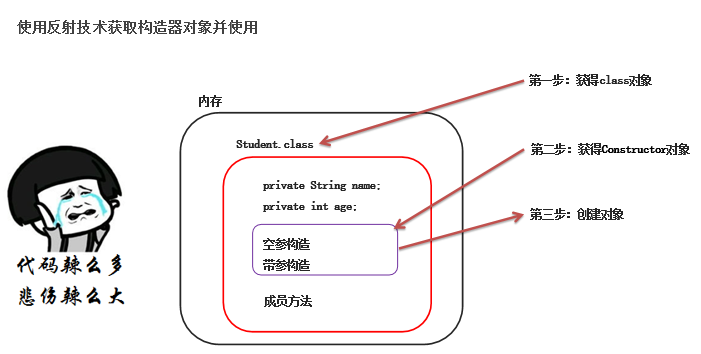
反射的第一步是先得到类对象,然后从类对象中获取类的成分对象。
Class类中用于获取构造器的方法
| Class的方法 | 说明 |
|---|---|
| Constructor<?>[] getConstructors() | 返回public构造器对象的数组 |
| Constructor<?>[] getDeclaredConstructors() | 返回所有构造器对象的数组 |
| Constructor getConstructor(Class<?>… parameterTypes) | 返回public单个构造器对象(按照类中构造器的声明顺序的第一个) |
| Constructor getDeclaredConstructor(Class<?>… parameterTypes) | 返回单个构造器对象 |
// getConstructor(Class... parameterTypes)
// 获取某个特定特定的构造器
@Test
public void getDeclaredConstructor() throws Exception {
// a.第一步:获取类对象
Class c = Student.class;
// b.定位单个构造器对象 (按照参数定位无参数构造器)
Constructor cons = c.getDeclaredConstructor();
System.out.println(cons.getName() + "===>" + cons.getParameterCount());
// c.定位某个有参构造器
Constructor cons1 = c.getDeclaredConstructor(String.class, int.class);
System.out.println(cons1.getName() + "===>" + cons1.getParameterCount());
}
获取构造器的作用依然是初始化一个对象返回
| Constructor类中用于创建对象的方法 | 说明 |
|---|---|
| T newInstance(Object… initargs) | 根据指定的构造器创建对象 |
| public void setAccessible(boolean flag) | 设置为true,表示取消访问检查,进行暴力反射,表明,反射可以破坏封装性 |
@Test
public void getDeclaredConstructor() throws Exception {
// a.第一步:获取类对象
Class c = Student.class;
// b.定位单个构造器对象 (按照参数定位无参数构造器)
Constructor cons = c.getDeclaredConstructor();
System.out.println(cons.getName() + "===>" + cons.getParameterCount());
// 如果遇到了私有的构造器,可以暴力反射
cons.setAccessible(true); // 权限被打开
Student s = (Student) cons.newInstance();
System.out.println(s);
System.out.println("-------------------");
// c.定位某个有参构造器
Constructor cons1 = c.getDeclaredConstructor(String.class, int.class);
System.out.println(cons1.getName() + "===>" + cons1.getParameterCount());
Student s1 = (Student) cons1.newInstance("孙悟空", 1000);
System.out.println(s1);
}
反射获取成员变量对象
有暴力拆解
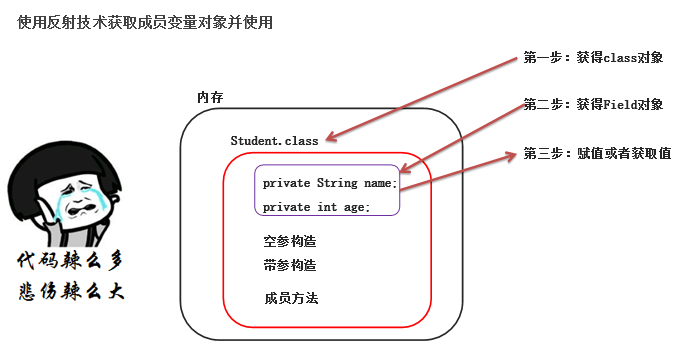
反射的第一步是先得到类对象,然后从类对象中获取类的成分对象。
| Class类中用于获取成员变量的方法 | 说明 |
|---|---|
| Field[] getFields() | 返回所有public成员变量对象的数组 |
| Field[] getDeclaredFields() | 返回所有成员变量对象的数组 |
| Field getField(String name) | 返回public的单个成员变量对象(参数是类中成员变量的具体名字) |
| Field getDeclaredField(String name) | 返回单个成员变量对象,存在就能拿到 |
@Test
public void getDeclaredFileds(){
Class<Student> s = Student.class;
Field[] fileds = s.getDeclaredFields();
for (Field filed : fileds) {
System.out.println(filed.getName()+"===>>>"+filed.getType());
}
try {
Field age = s.getField("age");
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
}
获取成员变量的作用依然是在某个对象中取值、赋值
| Field类中用于取值、赋值的方法 | 说明 |
|---|---|
| void set(Object obj, Object value): | 赋值(第一个参数是对象,需要我们自己去创建,第二个是该Filed的设置的值) |
| Object get(Object obj) | 获取值。 |
@Test
public void setFiled() throws Exception{
Class<Student> s = Student.class;
Field age = s.getDeclaredField("age");
// 因为成员变量都是私有,所以这里需要暴力拆解的
age.setAccessible(true);
Student student = new Student();
age.set(student,22);
}
反射获取成员方法对象
有暴力拆解
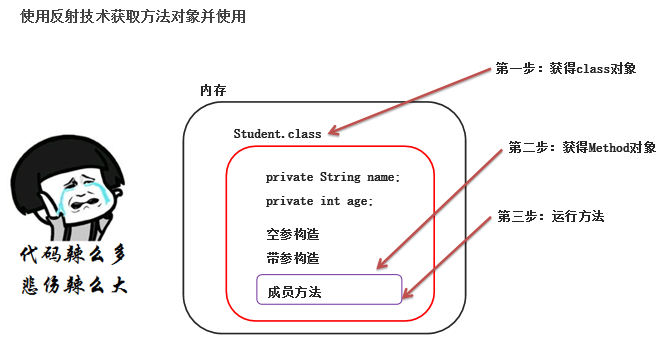
反射的第一步是先得到类对象,然后从类对象中获取类的成分对象。
| Class类中用于获取成员方法的方法 | 说明 |
|---|---|
| Method[] getMethods() | 返回所有public成员方法的对象数组 |
| Method[] getDeclaredMethods() | 返回所有成员方法对象的数组 |
| Method getMethod(String name, Class<?>… parameterTypes) | 返回public单个成员方法对象 |
| Method getDeclaredMethod(String name, Class<?>… parameterTypes) | 返回单个成员方法对象,存在就能拿到 |
@Test
public void testString() throws NoSuchMethodException {
Class<Student> studentClass = Student.class;
Method method = studentClass.getMethod("toString",null);
System.out.println(method.getName()+" 返回值类型:"+method.getReturnType()+" 参数个数:"+method.getParameterCount());
}
获取成员方法的作用依然是在某个对象中进行执行此方法
| Method类中用于触发执行的方法 | 说明 |
|---|---|
| Object invoke(Object obj, Object… args) | 参数一:用obj对象调用该方法;参数二:调用方法的传递的参数(如果没有就不写);返回值:方法的返回值(如果没有就不写) |
@Test
public void testString() throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
Class<Student> studentClass = Student.class;
Method method = studentClass.getMethod("toString",null);
System.out.println(method.getName()+" 返回值类型:"+method.getReturnType()+" 参数个数:"+method.getParameterCount());
// 调用方法
Student student = new Student("zq",12);
System.out.println(method.invoke(student, null));
}
反射作用一
反射的作用一:绕过编译阶段为集合添加数据
**解释:**反射是作用在运行时的技术,反射是作用在运行时的技术,此时集合的泛型将不能产生约束了,此时是可以为集合存入其他任意类型的元素的。

泛型只是在编译阶段可以约束集合只能操作某种数据类型,在编译成Class文件进入运行阶段的时候,其真实类型都是ArrayList了,泛型相当于被擦除了。
public class reflect2 {
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
ArrayList<String> list1 = new ArrayList<>();
ArrayList<Integer> list2 = new ArrayList<>();
System.out.println(list1.getClass());
System.out.println(list2.getClass());
System.out.println(list1.getClass()==list2.getClass());
System.out.println("==============");
list1.add("java");
list1.add("python");
Class c = list1.getClass();
Method add = c.getMethod("add", Object.class);
add.invoke(list1,12345);
}
}
//发现这样使用其实是有点麻烦的,其实可以采用下面这种方法.采用多个对象指向一个地址的方法
ArrayList list3 = list1;
list3.add(123);
list3.add(456);
sout(list1)
反射作用二
反射作用二:通用框架的底层原理
需求:给你任意一个对象,在不清楚对象字段的情况可以,可以把对象的字段名称和对应值存储到文件中去。

思路:
- 定义一个方法,可以接收任意类的对象。
- 每次收到一个对象后,需要解析这个对象的全部成员变量名称。
- 使用反射获取对象的Class类对象,然后获取全部成员变量信息。
- 遍历成员变量信息,然后提取本成员变量在对象中的具体值
- 存入成员变量名称和值到文件中去即可。
public class MybatisUtil {
/**
保存任意类型的对象
* @param ob
*/
public static void save(Object ob){
try {
PrintStream ps = new PrintStream(new FileOutputStream("F:\\Java_Project\\studying\\Reflect\\src\\com\\CCooky\\data.txt"),true);
Class<?> c = ob.getClass();
ps.println("======="+c.getSimpleName()+"===========");
Field[] fileds = c.getDeclaredFields();
for (Field filed : fileds) {
String name = filed.getName();
filed.setAccessible(true);
String value = filed.get(ob)+"";
ps.println(name+"="+value);
}
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
注解
概述:
Java 注解(Annotation)又称 Java 标注,是 JDK5.0 引入的一种注释机制。
Java 语言中的类、构造器、方法、成员变量、参数等都可以被注解进行标注。
作用:
对Java中类、方法、成员变量做标记,然后进行特殊处理,至于到底做何种处理由业务需求来决定。
例如:JUnit框架中,标记了注解@Test的方法就可以被当成测试方法执行,而没有标记的就不能当成测试方法执行。
自定义注解
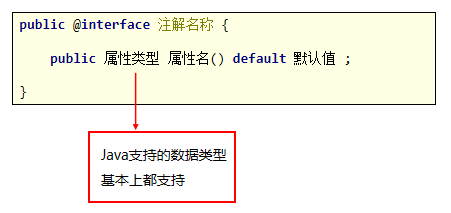
public @interface Mybook {
public String name();
String[] authors();
double price();
}
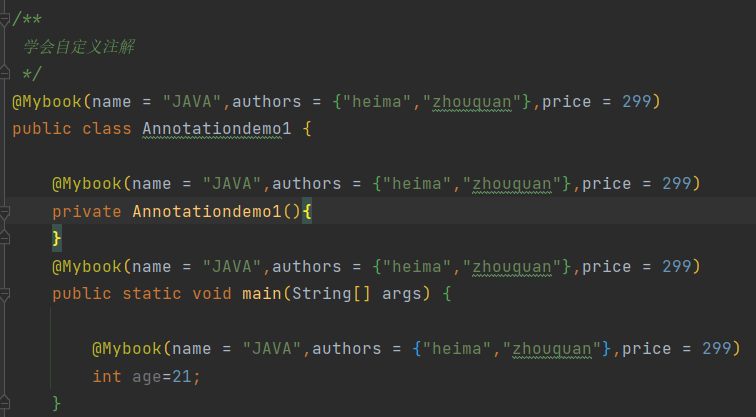
注解可以标记几乎任何地方哦。除此之外,注解有一个特殊的属性,如下:
- value属性,如果只有一个value属性的情况下,使用value属性的时候可以省略value名称不写!!
- 但是如果有多个属性, 且多个属性没有默认值,那么value名称是不能省略的。
// 只有一个value属性
public @interface Book {
String value();
}
// 在使用的时候,就不需要加这个属性名——value
@Book("/delete")
public class Annotationdemo1 {
@Mybook(name = "JAVA",authors = {"heima","zhouquan"},price = 299)
private Annotationdemo1(){
}
public static void main(String[] args) {
}
}
元注解
元注解:就是注解注解的注解。
元注解有两个:
- @Target: 约束自定义注解只能在哪些地方使用,
- @Retention:申明注解的生命周期
@Target中可使用的值定义在ElementType枚举类中,常用值如下:
- TYPE,类,接口
- FIELD, 成员变量
- METHOD, 成员方法
- PARAMETER, 方法参数
- CONSTRUCTOR, 构造器
- LOCAL_VARIABLE, 局部变量
//元注解,只能注解方法和成员变量
@Target({ElementType.METHOD,ElementType.FIELD})
public @interface MyTest {
}
@Retention中可使用的值定义在RetentionPolicy枚举类中,常用值如下
- SOURCE: 注解只作用在源码阶段,生成的字节码文件中不存在
- CLASS: 注解作用在源码阶段,字节码文件阶段,运行阶段不存在,默认值.
- RUNTIME:注解作用在源码阶段,字节码文件阶段,运行阶段(开发常用)
//元注解,只能注解方法和成员变量
@Target({ElementType.METHOD,ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyTest {
}
注解解析
注解的解析:
注解的操作中经常需要进行解析,注解的解析就是判断是否存在注解,存在注解就解析出内容。
与注解解析相关的接口:
Annotation: 注解的顶级接口,注解都是Annotation类型的对象
AnnotatedElement: 该接口定义了与注解解析相关的解析方法
| AnnotatedElement解析方法 | 说明 |
|---|---|
| Annotation[] getDeclaredAnnotations() | 获得当前对象上使用的所有注解,返回注解数组。 |
| T getDeclaredAnnotation(Class annotationClass) | 根据注解类型获得对应注解对象 |
| boolean isAnnotationPresent(Class annotationClass) | 判断当前对象是否使用了指定的注解,如果使用了则返回true,否则false |
注意注意哦:所有的类成分Class, Method , Field , Constructor,都实现了AnnotatedElement接口,所以他们都拥有解析注解的能力:
解析注解的技巧
- 注解在哪个成分上,我们就先拿哪个成分对象。
- 比如注解作用成员方法,则要获得该成员方法对应的Method对象,再来拿上面的注解
- 比如注解作用在类上,则要该类的Class对象,再来拿上面的注解
- 比如注解作用在成员变量上,则要获得该成员变量对应的Field对象,再来拿上面的注解
案例

// 定义注解
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface BOOkk {
String value();
double price();
String[] authors();
}
// 新建一个类,写上注解
@BOOkk(value = "倚天屠龙记",price = 200,authors = {"琼瑶","吴磊"})
class BookStore{
@BOOkk(value = "三少爷的键",price = 600,authors = {"刘德华","周杰伦"})
public void Test(){
}
}
public class Annotation3 {
@Test
public void parseClass() throws NoSuchMethodException {
//1. 获得类对象
Class<BookStore> c = BookStore.class;
//2. 获得类方法
Method method = c.getDeclaredMethod("Test");
//3. 从类对象中解析出来注解内容
//a. 首先判断该类对象上面有没有这个注解
if (c.isAnnotationPresent(BOOkk.class)) {
//b. 直接获取该注解对象
BOOkk book = c.getDeclaredAnnotation(BOOkk.class);
System.out.println(book.value());
System.out.println(book.price());
System.out.println(Arrays.toString(book.authors()));
}
//4. 从类方法中解析出注解内容
if (method.isAnnotationPresent(BOOkk.class)) {
BOOkk book = method.getDeclaredAnnotation(BOOkk.class);
System.out.println(book.value());
System.out.println(book.price());
System.out.println(Arrays.toString(book.authors()));
}
}
}
模拟Junit

@Target({ElementType.METHOD,ElementType.FIELD}) //元注解,只能注解方法和成员变量
@Retention(RetentionPolicy.RUNTIME)
public @interface MyTest {
}
public class Annotationdemo4 {
@MyTest
public void test1(){
System.out.println("====test1=====");
}
public void test2(){
System.out.println("====test2=====");
}
@MyTest
public void test3(){
System.out.println("====test3=====");
}
/**
* 启动菜单
* @param args
*/
public static void main(String[] args) throws Exception{
Annotationdemo4 t = new Annotationdemo4();
//1. 获取类对象
Class<Annotationdemo4> c = Annotationdemo4.class;
//2.
Method[] methods = c.getDeclaredMethods();
//3.
for (Method method : methods) {
if (method.isAnnotationPresent(MyTest.class)) {
method.invoke(t);
}
}
}
}
动态代理Proxy
概述
代理就是被代理者没有能力或者不愿意去完成某件事情,需要找个人代替自己去完成这件事,动态代理就是用来对业务功能(方法)进行代理的。例如我要出国,但我不想去弄很多的证明,所以我出钱要别人给我弄,我只用做飞机就行了。其实他出现的原因是在于:想让程序员在业务实现层仅仅保留你的逻辑代码就好了,一些其他的冗余,重复,没有技术的东西让代理去做,这样代码很整洁,方便查看。
关键步骤
-
必须有接口,实现类要实现接口(代理通常是基于接口实现的)。
-
创建一个实现类的对象,该对象为业务对象,紧接着为业务对象做一个代理对象。
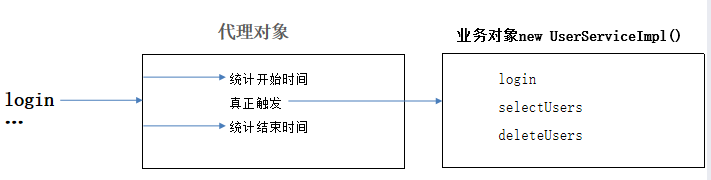
举个案例说明好处与基本使用:

这里我们会发现,这个统计耗时的工作是明显重复的,并且让我们的业务实现层变得很复杂,代码看着不优雅!!
UserService:
/**
模拟用户业务功能
*/
public interface UserService {
String login(String loginName , String passWord) ;
void selectUsers();
boolean deleteUsers();
void updateUsers();
}
UserServiceImpl:
public class UserServiceImpl implements UserService{
@Override
public String login(String loginName, String passWord) {
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
if("admin".equals(loginName) && "1234".equals(passWord)) {
return "success";
}
return "登录名和密码可能有毛病";
}
@Override
public void selectUsers() {
System.out.println("查询了100个用户数据!");
try {
Thread.sleep(2000);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public boolean deleteUsers() {
try {
System.out.println("删除100个用户数据!");
Thread.sleep(500);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
@Override
public void updateUsers() {
try {
System.out.println("修改100个用户数据!");
Thread.sleep(2500);
} catch (Exception e) {
e.printStackTrace();
}
}
}
代理对象:ProxyUtil(写成了一个工具类)
这里写的是泛型,表明可以接收任意类型,为任意业务进行耗时统计。
/**
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)
参数一:类加载器,负责加载代理类到内存中使用。
参数二:获取被代理对象实现的全部接口。代理要为全部接口的全部方法进行代理
参数三:代理的核心处理逻辑
*/
public class ProxyUtil {
/**
生成业务对象的代理对象。
* @param obj
* @return
*/
public static <T> T getProxy(T obj) {
// 返回了一个代理对象了
return (T)Proxy.newProxyInstance(obj.getClass().getClassLoader(),
obj.getClass().getInterfaces(),
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 参数一:代理对象本身。一般不管
// 参数二:正在被代理的方法
// 参数三:被代理方法,应该传入的参数
long startTimer = System .currentTimeMillis();
// 马上触发方法的真正执行。(触发真正的业务功能)
Object result = method.invoke(obj, args);
long endTimer = System.currentTimeMillis();
System.out.println(method.getName() + "方法耗时:" + (endTimer - startTimer) / 1000.0 + "s");
// 把业务功能方法执行的结果返回给调用者
return result;
}
});
}
}
测试类
public class Controller {
public static void main(String[] args) {
UserService1 userService1 = ProxyUtil1.getProxy(new UserServiceImpl1());
System.out.println(userService1.login("admin", "123456"));
userService1.selectUsers();
System.out.println(userService1.deleteUsers());
System.out.println(userService1.updateUsers());
}
}
动态代理的优点
- 非常的灵活,支持任意接口类型的实现类对象做代理,也可以直接为接本身做代理。
- 可以为被代理对象的所有方法做代理。
- 可以在不改变方法源码的情况下,实现对方法功能的增强。
- 不仅简化了编程工作、提高了软件系统的可扩展性,同时也提高了开发效率。
XML

XML概述
XML是可扩展标记语言(eXtensible Markup Language)的缩写,它是**是一种数据表示格式,**可以描述非常复杂的数据结构,常用于传输和存储数据。可以用于自定义数据格式。
<?xml version="1.0" encoding="UTF-8"?>
<data>
<sender>张三</sender>
<receiver>李四</receiver>
<src>
<addr>北京</addr>
<date>2022-11-11 11:11:11</date>
</src>
<current>武汉</current>
<dest>广州</dest>
</data>
XML的几个特点和使用场景
- 一是纯文本,默认使用UTF-8编码;二是可嵌套;
- 如果把XML内容存为文件,那么它就是一个XML文件。
XML的使用场景:XML内容经常被当成消息进行网络传输,或者作为配置文件用于存储系统的信息。
XML语法规则
- XML文件的后缀名为:xml
- 文档声明必须是第一行,让别人识别这是xml文件
//一行文档声明
<?xml version="1.0" encoding="UTF-8" ?>
version:XML默认的版本号码、该属性是必须存在的
encoding:本XML文件的编码
XML的标签(元素)规则
- 标签由一对尖括号和合法标识符组成: < name>< /name>,必须存在一个根标签,有且只能有一个。
- 标签必须成对出现,有开始,有结束: < name>< /name>
- 特殊的标签可以不成对,但是必须有结束标记,如:< br/>
- 标签中可以定义属性,属性和标签名空格隔开, 属性值必须用引号引起来<student id = “1">
- 标签需要正确的嵌套
XML的其他组成
-
XML文件中可以定义注释信息:
-
XML文件中可以存在以下特殊字符

-
XML文件中可以存在CDATA区: < ![CDATA[ …内容… ]]>。代表数据区
因为第二点太麻烦了,所以有这个东西,里面就不用管其他的东西,可以写任意内容。
快捷写法:CD
<?xml version="1.0" encoding="UTF-8" ?>
<student>
<name>妞儿国外</name>
<sex>女</sex>
<hobby>唐僧,追唐僧</hobby>
<sql>
select * from user where age < 18;
</sql>
<![CDATA[
select * from user where age < 18;
]]>
</student>
XML文档约束方式

文档约束的分类:
-
DTD
-
schema
DTD约束
需要先手动编写一个DTD文档约束,来约束我们xml的写法
需求:利用DTD文档约束,约束一个XML文件的编写。
分析:
①:编写DTD约束文档,后缀必须是.dtd
<!ELEMENT 书架 (书+)>
<!ELEMENT 书 (书名,作者,售价)>
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>
②:在需要编写的XML文件中导入该DTD约束文档
<!DOCTYPE 书架 SYSTEM "data.dtd">
③:按照约束的规定编写XML文件的内容。
缺点:
- 不能约束具体的数据类型。
schema约束
-
schema可以约束具体的数据类型,约束能力上更强大。
-
schema本身也是一个xml文件,本身也受到其他约束文件的要求,所以编写的更加严谨
需求:利用schema文档约束,约束一个XML文件的编写。
分析:
①:编写schema约束文档,后缀必须是.xsd,具体的形式到代码中观看。
②:在需要编写的XML文件中导入该schema约束文档
③:按照约束内容编写XML文件的标签。
schema文档:
<?xml version="1.0" encoding="UTF-8" ?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itcast.cn"
elementFormDefault="qualified" >
<!-- targetNamespace:申明约束文档的地址(命名空间)-->
<element name='书架'>
<!-- 写子元素 -->
<complexType>
<!-- maxOccurs='unbounded': 书架下的子元素可以有任意多个!-->
<sequence maxOccurs='unbounded'>
<element name='书'>
<!-- 写子元素 -->
<complexType>
<sequence>
<element name='书名' type='string'/>
<element name='作者' type='string'/>
<element name='售价' type='double'/>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
自己写xml:
<?xml version="1.0" encoding="UTF-8" ?>
<书架 xmlns="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn data.xsd">
<!-- xmlns="http://www.itcast.cn" 基本位置
xsi:schemaLocation="http://www.itcast.cn books02.xsd" 具体的位置 -->
<书>
<书名>神雕侠侣</书名>
<作者>金庸</作者>
<售价>399.9</售价>
</书>
<书>
<书名>神雕侠侣</书名>
<作者>金庸</作者>
<售价>19.5</售价>
</书>
</书架>
XML解析技术
XML是为了区存储数据、做配置信息、进行数据传输。
并且最终需要被程序进行读取,解析里面的信息。所以需要解析技术。
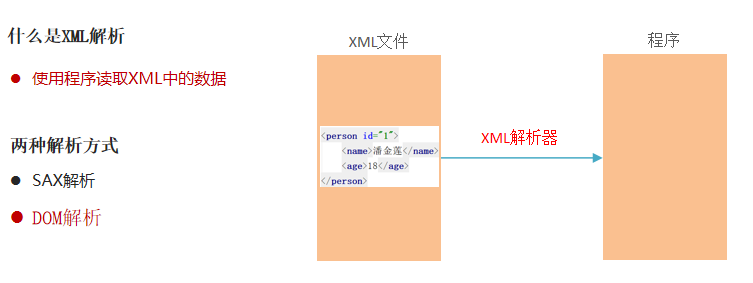
| Dom常见的解析框架 | 说明 |
|---|---|
| JAXP | SUN公司提供的一套XML的解析的API |
| JDOM | JDOM是一个开源项目,它基于树型结构,利用纯JAVA的技术对XML文档实现解析、生成、序列化以及多种操作。 |
| dom4j | 是JDOM的升级品,用来读写XML文件的。具有性能优异、功能强大和极其易使用的特点,它的性能超过sun公司官方的dom 技术,同时它也是一个开放源代码的软件,Hibernate也用它来读写配置文件。 |
| jsoup | 功能强大DOM方式的XML解析开发包,尤其对HTML解析更加方便 |
主要掌握DOM解析技术
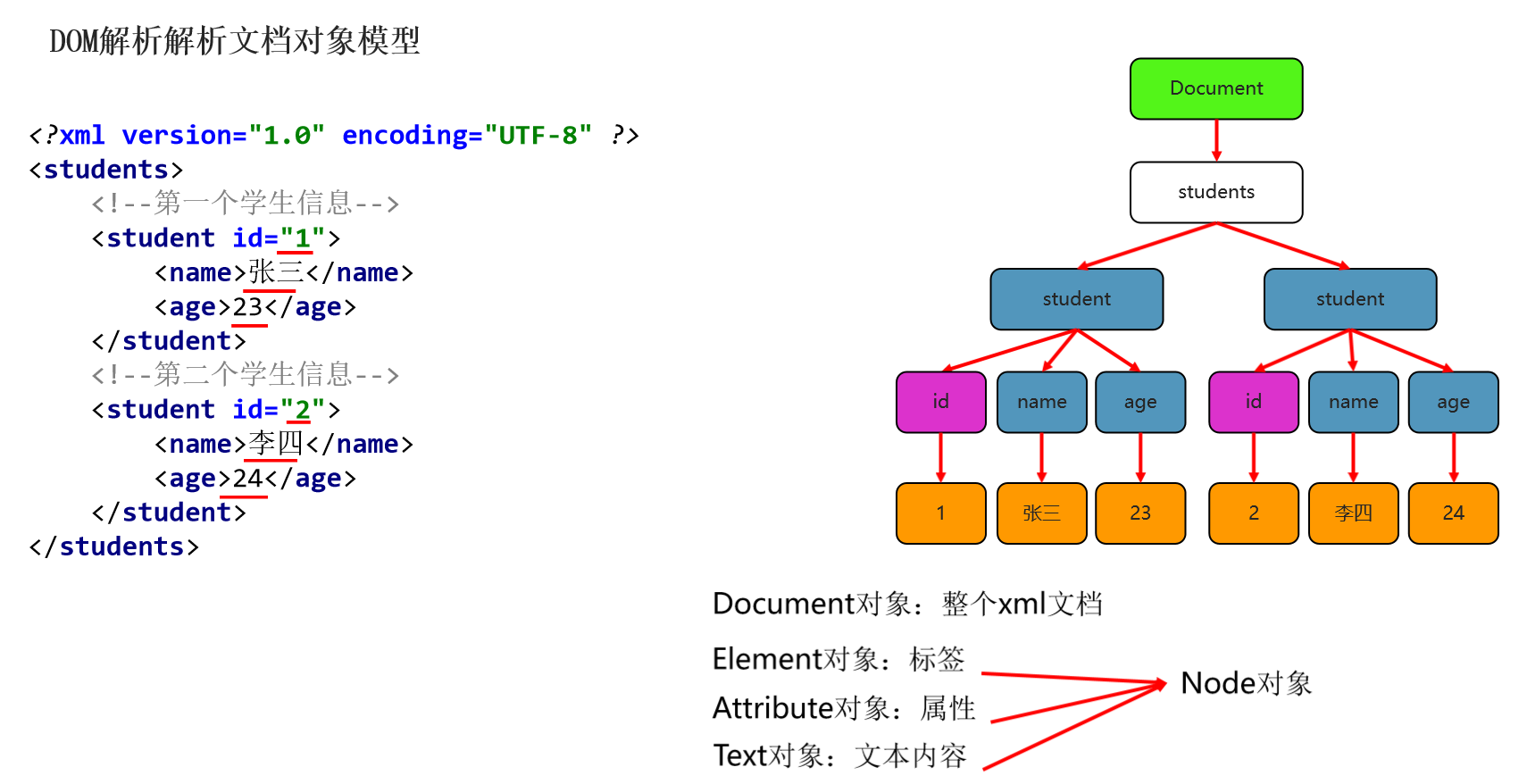
Element对象:students、student等标签;
Attribute对象:id、name、age;
Text对象:id、name、age对应的内容;
以上三个均实现了Node接口,都为节点类型
Dom4j
使用Dom4J解析出XML文件:
-
下载Dom4j框架,官网下载。

-
在项目中创建一个文件夹:lib
-
将dom4j-2.1.1.jar文件复制到 lib 文件夹
-
在jar文件上点右键,选择 Add as Library -> 点击OK
-
在类中导包使用
一.得到Document对象


二.获取xml里面所有的属性,文本…各个节点
API太多了,不用刻意去记,用到就查查
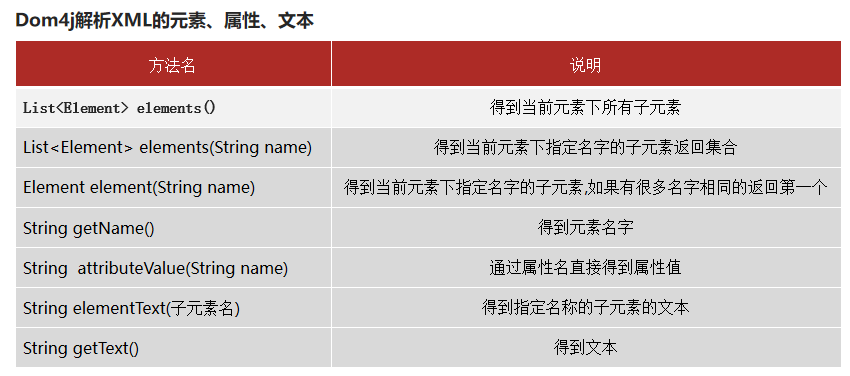
public class Dom4JHelloWorldDemo1 {
@Test
public void parseXMLData() throws Exception {
// 1、创建一个Dom4j的解析器对象,代表了整个dom4j框架
SAXReader saxReader = new SAXReader();
// 2、把XML文件加载到内存中成为一个Document文档对象
// Document document = saxReader.read(new File("xml-app\\src\\Contacts.xml")); // 需要通过模块名去定位
// Document document = saxReader.read(new FileInputStream("xml-app\\src\\Contacts.xml"));
// 注意: getResourceAsStream中的/是直接去src下寻找的文件
InputStream is = Dom4JHelloWorldDemo1.class.getResourceAsStream("/Contacts.xml");
Document document = saxReader.read(is);
// 3、获取根元素对象
Element root = document.getRootElement();
System.out.println(root.getName());
// 4、拿根元素下的全部子元素对象(一级)
// List<Element> sonEles = root.elements();
List<Element> sonEles = root.elements("contact");
for (Element sonEle : sonEles) {
System.out.println(sonEle.getName());
}
// 拿某个子元素
Element userEle = root.element("user");
System.out.println(userEle.getName());
// 默认提取第一个子元素对象 (Java语言。)
Element contact = root.element("contact");
// 获取子元素文本
System.out.println(contact.elementText("name"));
// 去掉前后空格
System.out.println(contact.elementTextTrim("name"));
// 获取当前元素下的子元素对象
Element email = contact.element("email");
System.out.println(email.getText());
// 去掉前后空格
System.out.println(email.getTextTrim());
// 根据元素获取属性值
Attribute idAttr = contact.attribute("id");
System.out.println(idAttr.getName() + "-->" + idAttr.getValue());
// 直接提取属性值
System.out.println(contact.attributeValue("id"));
System.out.println(contact.attributeValue("vip"));
}
}
XML检索技术:Xpath
当我们需要拿出或者寻找xml文件中的某个数据的时候,采用dom4j就显得很无力,因为他很麻烦,首先需要解析整个xml文件,然后再找到各个节点,解析出来,第二步找到各个节点的过程很麻烦。
于是,有了Xpath技术,他适合对xml文件进行快速的信息检索工作。但他不是单独的哦,他是基于dom4j进行开发来的。
XPath介绍:
XPath在解析XML文档方面提供了一独树一帜的路径思想,更加优雅,高效
XPath使用路径表达式来定位XML文档中的元素节点或属性节点。
- 示例
- /元素/子元素/孙元素
- //子元素//孙元素
快速入门:
- 导入jar包(dom4j和jaxen-1.1.2.jar),Xpath技术依赖Dom4j技术
- 通过dom4j的SAXReader获取Document对象
- 利用XPath提供的API, 结合XPath的语法完成选取XML文档元素节点进行解析操作。
- Document中与Xpath相关的API如下:
| 方法名 | 说明 |
|---|---|
| Node selectSingleNode( “路径表达式” ) | 获取符合表达式的唯一元素 |
| List selectNodes( “路径表达式” ) | 获取符合表达式的元素集合 |
其中,这个路径表达式,具体该怎么写,Xpath给我们提供了四种书写方式:
- 绝对路径
- 相对路径
- 全文检索
- 属性查找
一:绝对路径
获取从根节点开始逐层的查找节点列表并打印信息。第一个正斜杠代表了这个文档。
| 路径表达式语法 | 说明 |
|---|---|
| /根元素/子元素/孙元素 | 从根元素开始,一级一级向下查找,不能跨级 |
List<Node> nameEles = document.selectNodes("/contactList/contact/name");
//Example
@Test
public void parse01() throws Exception{
//a.
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(XpathDemo.class.getResourceAsStream("/xmldata/Contacts2.xml"));
//b.
List<Node> nameNodes = document.selectNodes("/contactList/contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element)nameNode;
System.out.println(nameEle.getTextTrim());
}
}
二:相对路径(有点鸡肋)
-
先得到根节点contactList
-
再采用相对路径获取下一级contact 节点的name子节点并打印信息
| 路径表达式写法 | 说明 |
|---|---|
| ./子元素/孙元素 | 从当前元素开始,一级一级向下查找,不能跨级 |
List<Node> nameNodes = rootElement.selectNodes("./contact/name");
//Example
@Test
public void parse02() throws Exception{
//a.
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(XpathDemo.class.getResourceAsStream("/xmldata/Contacts2.xml"));
//b.
Element rootElement = document.getRootElement();
//c.
List<Node> nameNodes = rootElement.selectNodes("./contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element)nameNode;
System.out.println(nameEle.getTextTrim());
}
}
三:全文检索(666)
直接全文搜索所有的name元素并打印;不用管路径,嵌套,多深都可以找到。
| 路劲表达式语法 | 说明 |
|---|---|
| //contact | 找contact元素,无论元素在哪里 |
| //contact/name | 找出所有contact元素下的一级name元素 |
| //contact//name | 找出所有contact元素下的所有级的name元素 |
List<Node> nameNodes = document.selectNodes("//name");
//Example
@Test
public void parse03() throws Exception{
//a.
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(XpathDemo.class.getResourceAsStream("/xmldata/Contacts2.xml"));
//b.
List<Node> nameNodes = document.selectNodes("//name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element)nameNode;
System.out.println(nameEle.getTextTrim());
}
}
四:属性搜索
在全文中搜索属性,或者带属性的元素。
| 路径表达式语法 | 说明 |
|---|---|
| //@属性名 | 全文查找带有该属性对象的所有属性对象 |
| //元素[@属性名] | 全文查找带有指定元素名和属性名的所有元素对象 |
| //元素//[@属性名=‘值’] | 全文查找指定元素名和属性名,并且属性值相等的所有元素对象 |
注意哦:前面三个查找都是什么对象啊?是Element对哦,而属性是另外一个Attribute对象哦,这里很容易搞错。
List<Node> nodes = document.selectNodes("//@id");//查出的是Attribute哦
List<Node> nodes = document.selectNodes("//contact[@id]");//这是Element哦
//Example
@Test
public void parse04() throws Exception{
//a.
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(XpathDemo.class.getResourceAsStream("/xmldata/Contacts2.xml"));
//b.
List<Node> nodes = document.selectNodes("//@id");
for (Node node : nodes) {
Attribute nameEle = (Attribute)node;
System.out.println(nameEle.getName()+"===>"+nameEle.getValue());
}
}
设计模式
plexType>
**自己写xml:**
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<书架 xmlns="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn data.xsd">
<!-- xmlns="http://www.itcast.cn" 基本位置
xsi:schemaLocation="http://www.itcast.cn books02.xsd" 具体的位置 -->
<书>
<书名>神雕侠侣</书名>
<作者>金庸</作者>
<售价>399.9</售价>
</书>
<书>
<书名>神雕侠侣</书名>
<作者>金庸</作者>
<售价>19.5</售价>
</书>
</书架>
XML解析技术
XML是为了区存储数据、做配置信息、进行数据传输。
并且最终需要被程序进行读取,解析里面的信息。所以需要解析技术。
| Dom常见的解析框架 | 说明 |
|---|---|
| JAXP | SUN公司提供的一套XML的解析的API |
| JDOM | JDOM是一个开源项目,它基于树型结构,利用纯JAVA的技术对XML文档实现解析、生成、序列化以及多种操作。 |
| dom4j | 是JDOM的升级品,用来读写XML文件的。具有性能优异、功能强大和极其易使用的特点,它的性能超过sun公司官方的dom 技术,同时它也是一个开放源代码的软件,Hibernate也用它来读写配置文件。 |
| jsoup | 功能强大DOM方式的XML解析开发包,尤其对HTML解析更加方便 |
主要掌握DOM解析技术
Element对象:students、student等标签;
Attribute对象:id、name、age;
Text对象:id、name、age对应的内容;
以上三个均实现了Node接口,都为节点类型
Dom4j
使用Dom4J解析出XML文件:
-
下载Dom4j框架,官网下载。
-
在项目中创建一个文件夹:lib
-
将dom4j-2.1.1.jar文件复制到 lib 文件夹
-
在jar文件上点右键,选择 Add as Library -> 点击OK
-
在类中导包使用
一.得到Document对象
二.获取xml里面所有的属性,文本…各个节点
API太多了,不用刻意去记,用到就查查
public class Dom4JHelloWorldDemo1 {
@Test
public void parseXMLData() throws Exception {
// 1、创建一个Dom4j的解析器对象,代表了整个dom4j框架
SAXReader saxReader = new SAXReader();
// 2、把XML文件加载到内存中成为一个Document文档对象
// Document document = saxReader.read(new File("xml-app\\src\\Contacts.xml")); // 需要通过模块名去定位
// Document document = saxReader.read(new FileInputStream("xml-app\\src\\Contacts.xml"));
// 注意: getResourceAsStream中的/是直接去src下寻找的文件
InputStream is = Dom4JHelloWorldDemo1.class.getResourceAsStream("/Contacts.xml");
Document document = saxReader.read(is);
// 3、获取根元素对象
Element root = document.getRootElement();
System.out.println(root.getName());
// 4、拿根元素下的全部子元素对象(一级)
// List<Element> sonEles = root.elements();
List<Element> sonEles = root.elements("contact");
for (Element sonEle : sonEles) {
System.out.println(sonEle.getName());
}
// 拿某个子元素
Element userEle = root.element("user");
System.out.println(userEle.getName());
// 默认提取第一个子元素对象 (Java语言。)
Element contact = root.element("contact");
// 获取子元素文本
System.out.println(contact.elementText("name"));
// 去掉前后空格
System.out.println(contact.elementTextTrim("name"));
// 获取当前元素下的子元素对象
Element email = contact.element("email");
System.out.println(email.getText());
// 去掉前后空格
System.out.println(email.getTextTrim());
// 根据元素获取属性值
Attribute idAttr = contact.attribute("id");
System.out.println(idAttr.getName() + "-->" + idAttr.getValue());
// 直接提取属性值
System.out.println(contact.attributeValue("id"));
System.out.println(contact.attributeValue("vip"));
}
}
XML检索技术:Xpath
当我们需要拿出或者寻找xml文件中的某个数据的时候,采用dom4j就显得很无力,因为他很麻烦,首先需要解析整个xml文件,然后再找到各个节点,解析出来,第二步找到各个节点的过程很麻烦。
于是,有了Xpath技术,他适合对xml文件进行快速的信息检索工作。但他不是单独的哦,他是基于dom4j进行开发来的。
XPath介绍:
XPath在解析XML文档方面提供了一独树一帜的路径思想,更加优雅,高效
XPath使用路径表达式来定位XML文档中的元素节点或属性节点。
- 示例
- /元素/子元素/孙元素
- //子元素//孙元素
快速入门:
- 导入jar包(dom4j和jaxen-1.1.2.jar),Xpath技术依赖Dom4j技术
- 通过dom4j的SAXReader获取Document对象
- 利用XPath提供的API, 结合XPath的语法完成选取XML文档元素节点进行解析操作。
- Document中与Xpath相关的API如下:
| 方法名 | 说明 |
|---|---|
| Node selectSingleNode( “路径表达式” ) | 获取符合表达式的唯一元素 |
| List selectNodes( “路径表达式” ) | 获取符合表达式的元素集合 |
其中,这个路径表达式,具体该怎么写,Xpath给我们提供了四种书写方式:
- 绝对路径
- 相对路径
- 全文检索
- 属性查找
一:绝对路径
获取从根节点开始逐层的查找节点列表并打印信息。第一个正斜杠代表了这个文档。
| 路径表达式语法 | 说明 |
|---|---|
| /根元素/子元素/孙元素 | 从根元素开始,一级一级向下查找,不能跨级 |
List<Node> nameEles = document.selectNodes("/contactList/contact/name");
//Example
@Test
public void parse01() throws Exception{
//a.
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(XpathDemo.class.getResourceAsStream("/xmldata/Contacts2.xml"));
//b.
List<Node> nameNodes = document.selectNodes("/contactList/contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element)nameNode;
System.out.println(nameEle.getTextTrim());
}
}
二:相对路径(有点鸡肋)
-
先得到根节点contactList
-
再采用相对路径获取下一级contact 节点的name子节点并打印信息
| 路径表达式写法 | 说明 |
|---|---|
| ./子元素/孙元素 | 从当前元素开始,一级一级向下查找,不能跨级 |
List<Node> nameNodes = rootElement.selectNodes("./contact/name");
//Example
@Test
public void parse02() throws Exception{
//a.
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(XpathDemo.class.getResourceAsStream("/xmldata/Contacts2.xml"));
//b.
Element rootElement = document.getRootElement();
//c.
List<Node> nameNodes = rootElement.selectNodes("./contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element)nameNode;
System.out.println(nameEle.getTextTrim());
}
}
三:全文检索(666)
直接全文搜索所有的name元素并打印;不用管路径,嵌套,多深都可以找到。
| 路劲表达式语法 | 说明 |
|---|---|
| //contact | 找contact元素,无论元素在哪里 |
| //contact/name | 找出所有contact元素下的一级name元素 |
| //contact//name | 找出所有contact元素下的所有级的name元素 |
List<Node> nameNodes = document.selectNodes("//name");
//Example
@Test
public void parse03() throws Exception{
//a.
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(XpathDemo.class.getResourceAsStream("/xmldata/Contacts2.xml"));
//b.
List<Node> nameNodes = document.selectNodes("//name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element)nameNode;
System.out.println(nameEle.getTextTrim());
}
}
四:属性搜索
在全文中搜索属性,或者带属性的元素。
| 路径表达式语法 | 说明 |
|---|---|
| //@属性名 | 全文查找带有该属性对象的所有属性对象 |
| //元素[@属性名] | 全文查找带有指定元素名和属性名的所有元素对象 |
| //元素//[@属性名=‘值’] | 全文查找指定元素名和属性名,并且属性值相等的所有元素对象 |
注意哦:前面三个查找都是什么对象啊?是Element对哦,而属性是另外一个Attribute对象哦,这里很容易搞错。
List<Node> nodes = document.selectNodes("//@id");//查出的是Attribute哦
List<Node> nodes = document.selectNodes("//contact[@id]");//这是Element哦
//Example
@Test
public void parse04() throws Exception{
//a.
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(XpathDemo.class.getResourceAsStream("/xmldata/Contacts2.xml"));
//b.
List<Node> nodes = document.selectNodes("//@id");
for (Node node : nodes) {
Attribute nameEle = (Attribute)node;
System.out.println(nameEle.getName()+"===>"+nameEle.getValue());
}
}















 1760
1760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









