







小小搬运工又来了,五一节即将到来了
UDP:用户数据报协议
1、引言
UDP是面向数据报的传输层协议,即进程的每个输出操作刚好产生一个UDP数据报,并组装成一份待发送的IP数据报。
TCP是面向流字符,即应用程序产生的全体数据与真正发送的单个IP数据报可能没有什么联系。
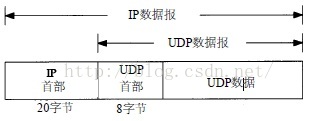
UDP数据报封装成IP数据报的格式如图1所示:
图1 UDP封装
2、UDP首部
UDP首部如图2所示:
图2 UDP首部

端口号表示发送进程和接收进程。(IP数据报根据协议字段值区分是UDP或TCP)
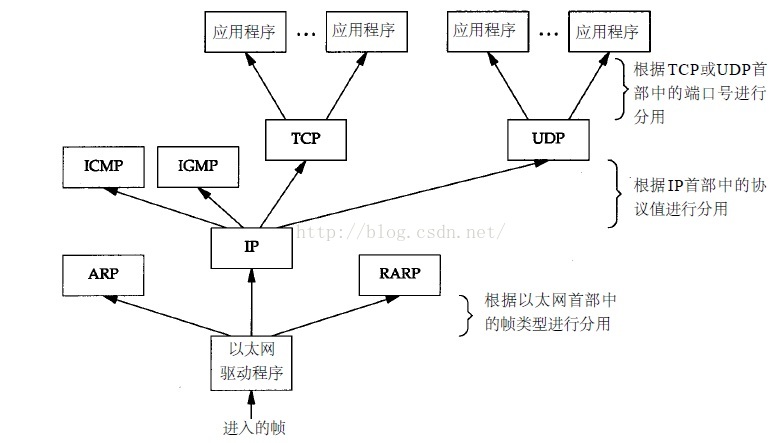
TCP和UDP用目的端口号来分用来自IP层的数据。TCP端口号则由TCP来查看,UDP端口号则由UDP来查看。分用指当目的主机收到一个以太网数据帧时,数据就开始从协议栈中由底向上升,同时去掉各层协议上加的报文首部。每层协议盒都要检查报文首部中的协议标识,以确定接收数据的上层协议,该过程称为分用。分用的整体过程如图3所示。
图3 以太网数据帧的分用过程
UDP长度字段是UDP首部和UDP数据的字节长度。最小值为8,即可以发送一份数据长度为0字节的UDP数据报
3、UDP校验和
UDP校验和覆盖UDP首部和UDP数据。(IP数据报中校验和是首部校验和,不涉及数据)UDP的校验和是可选的,而TCP的校验和是必须的。
UDP校验和的计算方法与IP校验和类似,但不同之处在于:首先,UDP数据报的长度可以为奇数字节,但是校验和算法是将若干个16bit字相加。因此必要时需要在最后填充字节0,但是这部分字节只是为了校验和,因此可能增加的填充字节并不被传送
UDP数据报和TCP段都包含一个12字节长的伪首部,该部分是为了计算检验和而设置的。伪首部是包含了IP首部的一些字段,UDP伪首部如图4所示。加入这些字段的目的是让UDP两次检查数据是否已经正确到达目的地。
图 4 UDP校验和计算过程中使用的各个字段
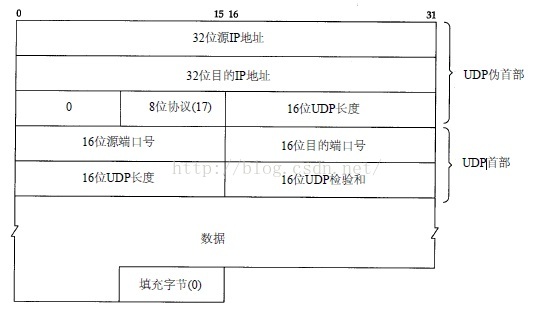
对于图中,UDP是单数字节,因此在计算校验和时需要加上填充字段,若校验和的计算结果为0,则存入值为全1,若传送的校验和为0,表示发送端没有计算校验和。
注:发送端没有计算校验和而接收端检测到校验和有差错,则该UDP数据报会被丢弃,并且不会产生差错报文。
UDP校验和选项在默认条件下是打开的。
4、IP分片
IP把MTU和数据报长度进行比较,如果有需要会进行分片。分片会发生在原始发送端主机上,也有可能发生在中间路由器上。
IP数据报分片之后,只有达到目的地之后才进行组装。重新组装是由目的端的IP层完成,而分片和重组装的过程对于传输层是透明的。
当需要分片,但是数据报设置了“不分片”位,则IP不对数据报分片,同时将该数据报丢弃,并发送一个ICMP差错报文。
在传输数据过程中经常要避免分片,因为当丢失某个分片时,需要重传整个数据文。
关于IP分片,如图5所示
图5 观察UDP数据报分片
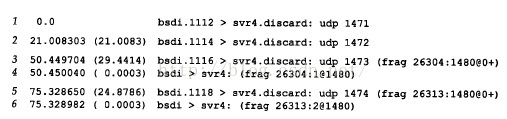
前两行,能直接装入以太网数据帧,没有被分片(以太网数据帧不超过1500字节,其中IP首部20字节,UDP首部8字节)
对于第3行,写入的udp数据是1473个字节,导致数据报1501个字节,需要分片。分片信息中第一片长度(位于:和@之间的数字)1480(包含UDP首部),则其加上IP首部和UDP首部刚好1500个字节,第二个即第4行只剩一个字节的数据。
@后的数字是从数据报开始出计算的片偏移值
+表示IP首部中3bit标志字段中的“更多片”比特,即是不是最后一片?
注意:分片时,除了最后一片外,其他每一片的数据部分(除IP首部外的其余部分)必须是8个字节的整数倍。本例中1480是8的整数倍
注意:除首片之后的所有分片都省略了协议名UDP、源端口号和目的端口号。(UDP首部还有首部校验和和长度信息?为什么4行中长度是1),是不是应该是除首片之外所有的分片都省略了UDP首部。
5、ICMP不可达差错(需要分片)
发生ICMP不可达差错的一种情况是:当路由器收到一份需要分片的数据报,而在IP首部设置了不可分片(DF)的标志比特。
若某个程序需要判断到达目的端的路途中最小MTU是多少---称为路径MTU发现机制。
需要分片但是未分片情况下产生的ICMP不可达差错报文格式如下:
图6 需要分片但是设置不分片标志比特时ICMP不可达差错报文格式
注:如果路由器不提供这种新的ICMP差错报文格式,则下一站的MTU就设为0

6、用Traceroute确定路径MTU
利用Traceroute程序发送分组,并设置“不分片”标志比特,发送的第一个分组的长度正好与出口MTU相等,每次收到ICMP“不能分片”差错时就减少分组的长度。若路由发送的ICMP差错报文是新格式,则包含出口的MTU,则利用该MTU值来发送新的报文,否则就用下一个最小的MTU值来发送。
7、采用UDP路径MTU发现
8、UDP和ARP之间的交互作用
对于UDP需要分组的情况,由于IP能够很快的产生n个数据报片,所以每个数据片都会引发一个ARP请求。理论上产生的分片数据报,应该只有第一个(片偏移为零)的数据报引发ARP请求。这种情况为ARP洪泛(即以高速率重复发送到同一个IP地址的ARP请求),在这种情况下,在等待一个ARP应答时,只将最后一个报文发送给特定目的主机。
在第一个数据报出现时,IP层需要启动一个定时器。此处第一个表示第一个接收到的报文,并非片偏移为0的数据报。正常的定时器值为30秒或60秒,如果定时器超时而该数据报的所有数据报片未能全部到达,则这些数据报会被丢弃。
对于大多数Berkeley派生的实现从不产生ICMP 组装差错。这些实现会设置定时器,也会在定时器溢出时将数据报片丢弃,但是不生成ICMP差错。且,并未接收到包含UDP首部的偏移量为0的第一个数据报片。除非收到第一个数据报片,否则并不要求任何实现产生ICMP差错。
ARP输入是后进先出。
9、最大UDP数据报长度
10、ICMP源站抑制差错理论上IP数据报长度为65535字节,除掉20个IP首部和8个字节的UDP首部,UDP数据报中用户数据的最长长度为65507字节。但是,大多数实现所提供的长度比这个最大值要小。
当一个系统(路由器或主机)接收数据报的速度比其处理速度要快时,可能产生源一直差错。
ICMP源站抑制差错报文格式如图7所示:
图7: ICMP源站抑制差错报文格式

11、UDP服务器的设计
大多数UDP服务器是交互服务器。通常程序使用的每个UDP端口都与一个有限大小的输入队列相联系。即来自不同客户的差不多同时到达的请求都有UDP自动排队。排队溢出会造成内核中的UDP模块丢弃数据报的可能性存在。
应用程序并不知道队列何时溢出。只是由UDP对超出数据报进行丢弃处理。UDP输出队列是FIFO(先进先出)。















 38万+
38万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









